[논문리뷰] CLIP: Learning Transferable Visual Models From Natural Lanugage Supervision
Multi-Modal 논문 리뷰
https://arxiv.org/abs/2103.00020
이 논문은 2021년에 OpenAI로부터 발표된 Multi Modal 관련 논문이다. 앞으로 이 벨로그에서는 Multi Modal의 초기 모델부터 최신 모델까지 리뷰와 스크래치 구현을 할 예정이다.
[ Abstract ]
2021년 당시 컴퓨터 비전은 미리 정해진 객체 범주의 고정된 집합을 예측하도록 훈련하였다. 예를 들어, 강아지 사진(객체 범주)을 보고 강아지(고정된 집합)라고 명칭하는 것이다. 하지만 이러한 형태로 학습한 비전 모델은 특정 분야에만 국한된 모델이 되기 쉽다. 그래서 이미지에 대한 디테일한 텍스트에 대해서 직접 학습하는 것은 훨씬 더 광범위한 모델로 발전시킬 수 있다. 이를 OpenAI에서는 어떤 이미지에 어떤 캡션(디테일한 텍스트)과 함께 사용되는지 예측하는 4억 쌍의 데이터를 수집하여 학습하였다. 그 후, 자연어처리 모델에 학습된 시각적 개념을 참조하거나 새로운 개념을 설명하는데 사용하여, 멀티 모달 모델을 개발하였다. 이 방법론을 적용한 모델은 다양한 테스크에서 좋은 성능을 낸다. 즉, 추가적인 데이터셋을 활용하여 모델을 튜닝시키지 않아도 추가적인 특정 테스크의 데이터셋으로 학습한 모델들과 견줄만한 성능이 나온다는 것이다.
[ Introduction and Motivating Work ]
(Autoregressive)
(Masked language modeling)

기존의 Raw text로부터 바로 사전학습하는 방식은 NLP분야에서 지난 몇년간 혁신을 보여줘왔다. 예를 들어, Corpus Dataset으로 Autoregressive와 Masked language modeling와 같은 Task와 관계없는 사전학습방식을 수행하는 방법이다. 이로 인해 zero-shot transfer이 가능하게 되었다. 대표적인 예로, GPT-3이 존재한다. 하지만 자연어 분야 외에는 기존의 라벨링된 데이터셋에서 사전학습하는 것이 표준방식이었다.
기존 멀티모달 분야의 연구들 역시도 이미지, 자연어 모델이 발달함에 따라 같이 발전해왔다. 예를 들어, Low level 이미지와 Text tag features를 이용하여 멀티모달 Deep Boltzmann Machines을 학습함으로써 Deep Representation Learning을 연구한 논문이 있다. 하지만, 2021년 기준 많은 멀티모달에 연구에도 불구하고 아직 자연어를 이미지 Representation Learning에 사용하는 것은 측정된 성능이 다른 대안들보다 훨씬 낮기 때문에 여전히 드물다.
반면 OpenAI에서 제안한 CLIP은 기존의 Task-specific supervised model들과 성능이 비슷할뿐만 아니라 몇몇의 경우에서는 뛰어넘는 성능을 보여주었다.
[ Approach ]
(1) Natural Language Supervision
Natural Language Supervision은 자연어에 내포된 정보를 활용해 데이터를 직접 레이블링하지 않고도 모델을 학습시키는 방식이다. 이는 Semi Supervised Learning이나 UnSupervised Learning과 비교했을 때, 단순히 표현을 학습하는 것을 넘어 그 표현을 언어와 연결시키는 데 있어 유연한 제로샷 전이(zero-shot transfer)를 가능하게 한다고 한다.
(2) Creating a Sufficiently Large Dataset
기존 이미지-Text 데이터셋은 규모가 적거나 품질이 좋지 않은 경우가 있어서 OpenAI에서는 WIT(WebImageText)를 새로 만들어서 학습시켰다. 이 데이터셋은 인터넷에서 공개된 다양한 출처로부터 4억 개의 (이미지, 텍스트) 쌍을 수집한 것이다.
(3) Selecting an Efficient Pre-Training Method
이 문단에서는 컴퓨터 비전에서 자연어를 효율적으로 확장하기 위한 방법을 설명한다.
기존 최첨단 모델들은 매우 많은 GPU/TPU 자원이 필요했지만, 제한된 ImageNet 클래스만 예측할 수 있었다. 자연어를 사용한 시각적 개념 학습은 훨씬 복잡한 작업이다. 기존 연구에서는 이미지 CNN과 텍스트 변환기를 결합해 캡션을 예측하려 했으나, 텍스트의 다양한 표현으로 인해 학습 효율이 낮았다.
그래서 대조 학습(Contrastive Learning)을 사용하려고 하였다. 텍스트의 정확한 단어를 예측하는 대신, 이미지와 텍스트가 짝을 이루는지를 예측하는 대조 학습 방식으로 전환했다. 더 쉽게 말하면, 한 단어가 아닌 텍스트 전체로 짝지어지도록 학습시켰다. 이를 통해 학습 효율성이 4배 향상되었다.
CLIP 모델은 이미지와 텍스트 인코더를 함께 학습해 이미지와 텍스트 임베딩의 유사도를 계산하는 방식으로, 대규모 데이터에서도 효율적으로 학습할 수 있다.
(Contrastive Learning)
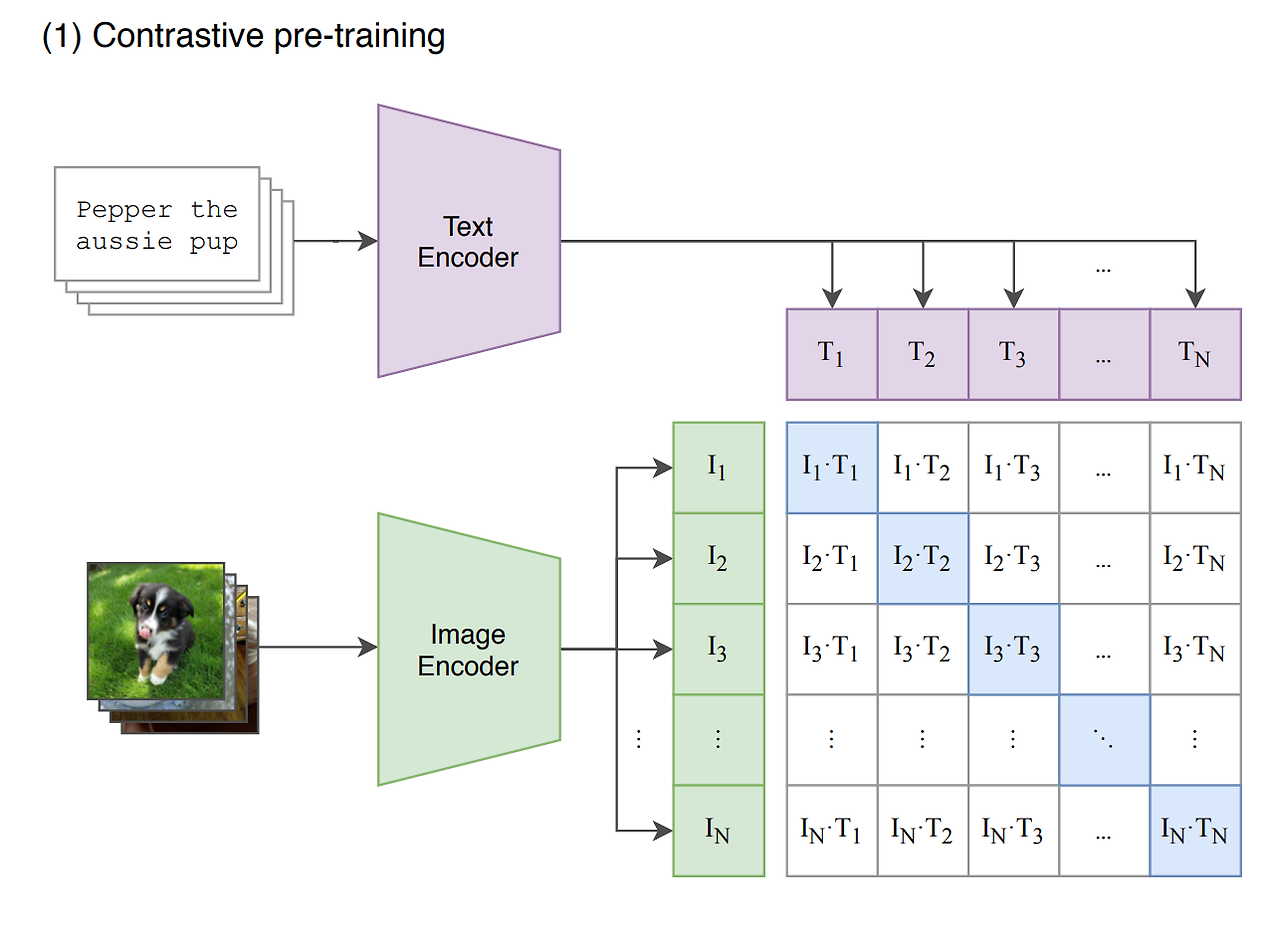
위의 그림처럼 N개의 (이미지, 텍스트) 쌍의 배치가 주어졌을 때, CLIP은 NXN개의 가능한 (이미지, 텍스트) 쌍을 예측하도록 학습된다. 이를 위해, CLIP은 N개의 실제 쌍의 이미지 임베딩과 텍스트 임베딩의 코사인 유사도를 최대화하고 잘못된 쌍의 코사인 유사도는 최소화하도록 이미지 인코더와 텍스트 인코더를 같이 학습함으로써 multi-modal 임베딩 공간을 학습한다. 위의 그림을 예시로 들자면, "Pepper the aussie pup"이라는 문장과 강아지 사진을 입력하면, CLIP은 이 둘이 맞는 쌍인지 판단하는 것이다.
(4) Choosing and Scaling a Model
이 문단에서는 CLIP 모델에서 사용된 이미지 인코더와 텍스트 인코더의 구조 및 설계 사항을 설명한다. 이미지 인코더는 ResNet-50 기반과 ViT를 사용하였다. 텍스트 인코더는 트랜스포머를 사용하였다.
(5) Training
학습 시에는 ResNet-50, ResNet-101, 그리고 확장된 RN50x4, RN50x16, RN50x64 모델을 훈련했으며, ViT는 ViT-B/32, ViT-B/16, ViT-L/14를 훈련했다. 모든 모델은 32 에폭 동안 훈련되었고, Adam 최적화기, 코사인 스케줄, 대규모 배치 크기(32,768)를 사용했다. 메모리 절약과 Train 속도를 위해 혼합 정밀도, 그라디언트 체크포인팅, 절반 정밀도 기법이 적용되었다. 가장 큰 모델인 RN50x64는 592개의 V100 GPU에서 18일, ViT-L/14는 256개의 V100 GPU에서 12일 동안 훈련되었다. ViT-L/14는 336 픽셀 해상도로 추가 훈련해 성능을 더 높였다.
[ Experiments ]
(1) Zero-Shot Transfer
-
Zero-Shot Transfer의 동기
제로샷 학습은 보통 보지 못한 객체를 인식하는 능력을 평가하는데, CLIP에서는 보지 못한 데이터셋에 대한 일반화로 정의한다. 이는 시스템이 새로운 작업을 학습하는 능력을 평가하는 방법으로 사용된다. -
CLIP의 제로샷 학습 방식
대조 학습의 기본 아이디어는 정답 쌍(positive pairs)과 오답 쌍(negative pairs)을 구분하는 능력을 기르면서, 임베딩 공간에서 이미지와 텍스트가 같은 의미일수록 가까워지고, 다른 의미일수록 멀어지게 학습하는 것입니다.
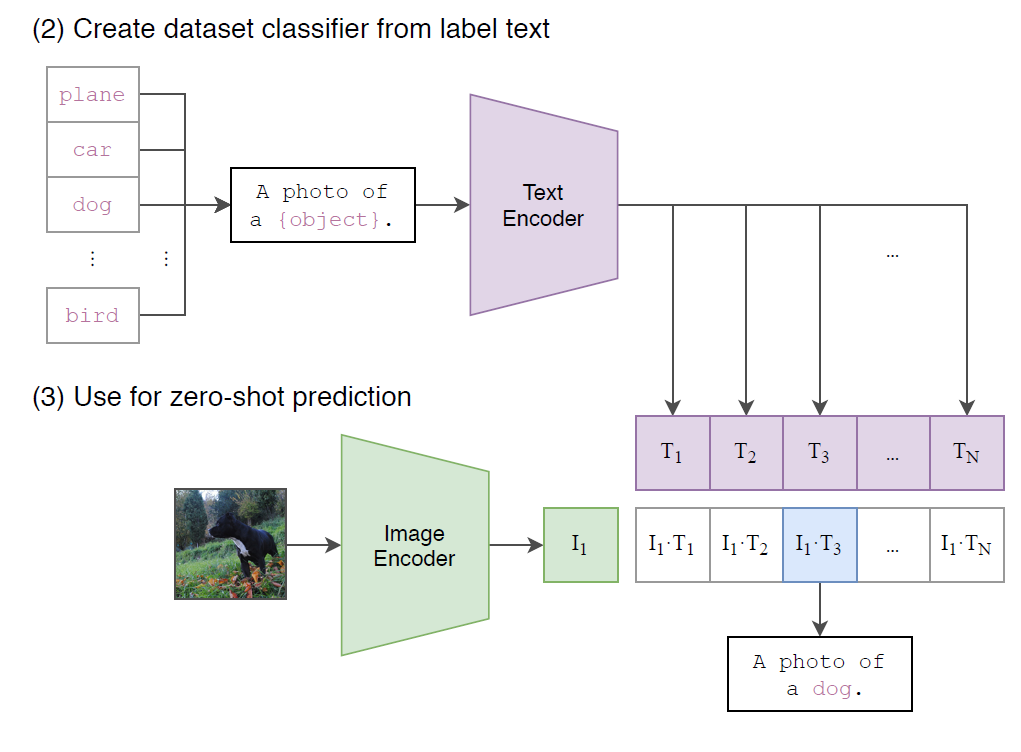
이미지 분류 task의 경우, 이미지가 주어지면 데이터셋의 모든 class와의 (image, text) 쌍에 대해 유사도를 측정하고 가장 그럴듯한(probable) 쌍을 출력한다. 구체적으로는 위의 그림과 같이, 각 class name을 "A photo of a {class}." 형식의 문장으로 바꾼 뒤, 주어진 이미지와 유사도를 모든 class에 대해 측정하는 방식이다.
즉, CLIP은 이미지와 텍스트를 각각 임베딩한 후, 그 임베딩들이 서로 어떻게 대응(맵핑)되는지를 학습하는 것이다. 이미지를 이미지 인코더로 임베딩하고, 텍스트를 텍스트 인코더로 임베딩해서, 두 임베딩 간의 유사도를 계산하는 방식을 학습한다. 이 과정을 통해 CLIP은 이미지와 해당 텍스트가 서로 관련이 있는지를 판단할 수 있게 되며, 이를 기반으로 제로샷 예측도 가능하게 되는 것이다.
위 그림 예시로 더 쉽게 설명해보겠다. 예를 들어, CIFAR-10 데이터셋의 클래스 레이블이 다음과 같다면:
"dog", "cat", "car", "plane" 등
CLIP에서는 이를 다음과 같은 텍스트 설명으로 변환한다:
"A photo of a dog."
"A photo of a cat."
"A photo of a car."
"A photo of a plane."
학습할 때, CLIP에게 정답 쌍(이미지와 그에 맞는 텍스트 설명)과 오답 쌍(이미지와 맞지 않는 텍스트 설명)을 제공한다. 예를 들어, 다음과 같은 배치를 모델에 제공한다:
이미지:
강아지 사진
고양이 사진
텍스트:
"A photo of a dog."
"A photo of a cat."
이 배치에서는 강아지 사진과 "A photo of a dog."가 정답 쌍이고, 고양이 사진과 "A photo of a cat."이 정답 쌍이다. 반대로, 강아지 사진과 "A photo of a cat."은 오답 쌍이고, 고양이 사진과 "A photo of a dog."도 오답 쌍이 된다.
모델은 배치에서 각 이미지와 텍스트 설명에 대한 유사도를 계산한다. 이 유사도는 이미지와 텍스트가 얼마나 의미적으로 가까운지를 나타낸다. 이상적인 상황에서는:
강아지 사진과 "A photo of a dog."의 유사도가 높고,
고양이 사진과 "A photo of a cat."의 유사도가 높아야 한다.
반대로:
강아지 사진과 "A photo of a cat."의 유사도는 낮아야 하고,
고양이 사진과 "A photo of a dog."의 유사도도 낮아야 한다.
이때 Label이 존재하는데 왜 Label이 없는 학습이라고 하냐면, 그 Label(Dog)을 바탕으로 새롭게 A photo of a dog이라는 문장으로 변환하기 때문이다. 또한 추후에 Label을 따로 안 만들고 새로운 라벨을 텍스트로만 입력해주면, 추가 학습 없이도 새로운 라벨에 맞는 이미지를 예측할 수 있는 제로샷 학습이 가능하기 때문이다.
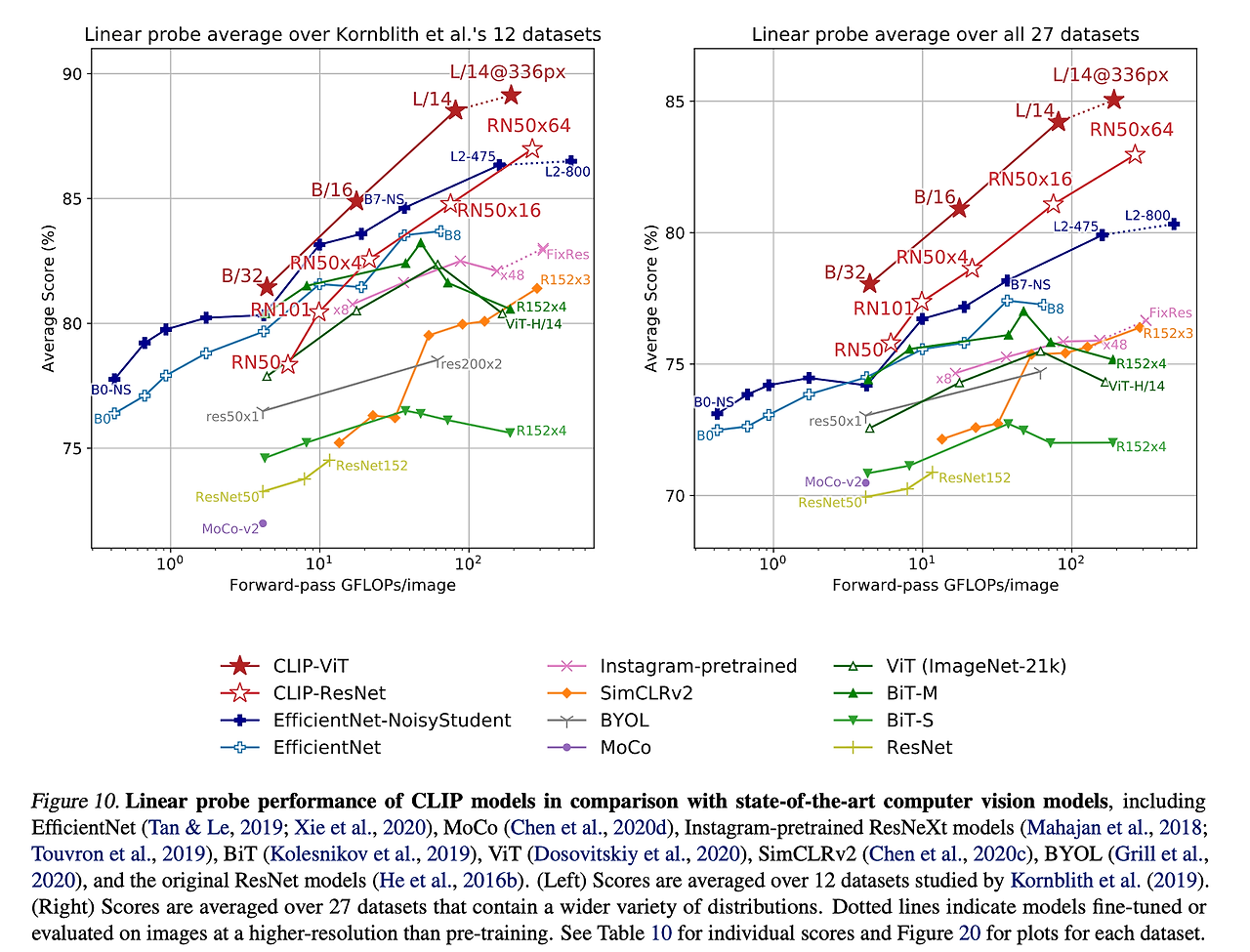
위 그래프의 X축 (Forward-pass GFLOPs/image)은 이미지 하나를 처리하는 데 필요한 계산량을 나타낸다. GFLOPs는 초당 수행되는 연산량을 기가 단위로 표현한 것이다. Y축 (Average Score %)은 여러 데이터셋에서 평가된 모델의 평균 성능을 백분율로 나타낸다.
CLIP 모델에서는 GFLOPs가 높은 모델일수록 성능이 좋아지며, 특히 CLIP-ViT L/14@336px이 데이터셋에서 모두 최고의 성능을 보여준다. CLIP-ResNet은 높은 연산량을 사용할수록 성능이 향상되는 패턴을 보인다. 또한, CLIP 모델들은 대부분의 기존 컴퓨터 비전 모델들보다 더 높은 성능을 보이며, 특히 제로샷 학습 능력에서 강점을 보인다.

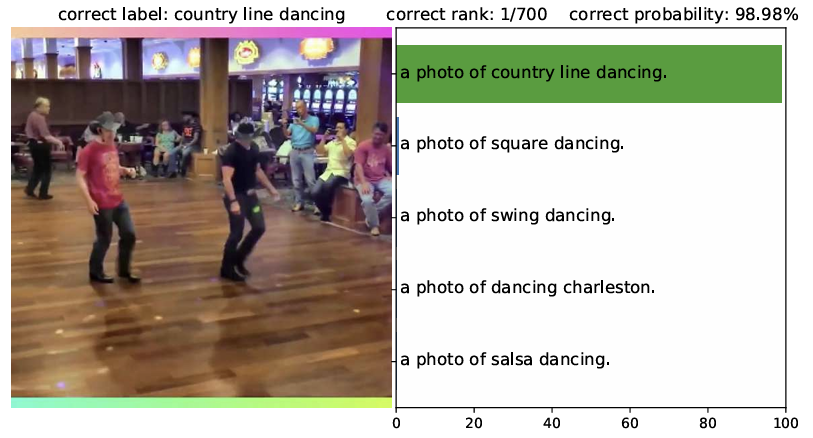
부록에서 Clip의 Qualitative example을 볼 수 있는데, 위에 보이는 예시처럼 label과 가까운 대답을 하는 것을 알 수 있다.
[ Limitations ]
CLIP에도 여러 한계가 있다.
(1) 성능 한계
ResNet-50, 101과 비교해 zero-shot CLIP 성능이 더 좋지만, SOTA 모델에 비하면 여전히 낮다. SOTA 성능에 도달하려면 계산량이 1000배 증가해야 하지만, 이는 현재 불가능하므로 효율성을 높이기 위한 추가 연구가 필요하다.
(2) Task-specific 성능 부족
CLIP은 특정 작업에서 강한 성능을 보이지만, 세분화된 좁은 범위의 분류 문제에서는 약하다. 사전 학습에서 다루지 않았던 새로운 유형의 문제에서는 성능이 떨어질 수 있다.
(3) MNIST 성능
CLIP은 고품질의 OCR representation을 학습하지만, MNIST에서 88%의 정확도밖에 달성하지 못한다. 매우 단순한 logistic regression 모델보다 낮은 이 성능은 사전학습 데이터셋에 MNIST의 손글씨 이미지와 유사한 example이 거의 없기 때문일 것이며, 이러한 결과는 CLIP이 일반적인 딥러닝 모델의 취약한 일반화(generalization)라는 근본적인 문제를 거의 해결하지 못했음을 의미한다.
(4) 윤리적 문제
인터넷에서 수집한 데이터로 학습한 CLIP은 사회적 편견을 학습할 위험이 있다.
[ 참고 문헌 출처 ]
https://wikidocs.net/166788
https://wikidocs.net/222419
https://simonezz.tistory.com/88
https://greeksharifa.github.io/computer%20vision/2021/12/19/CLIP/
