Multi-Modal 논문 리뷰
1.[논문리뷰] CLIP: Learning Transferable Visual Models From Natural Lanugage Supervision
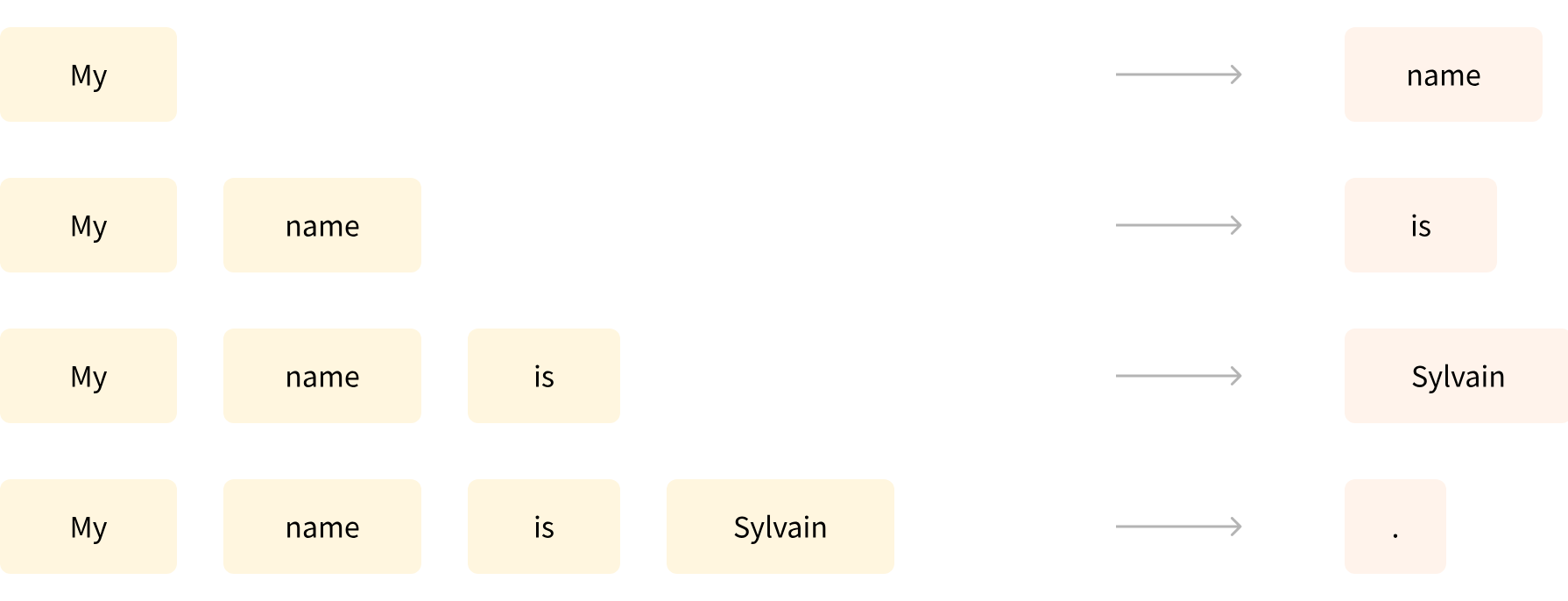
https://arxiv.org/abs/2103.00020이 논문은 2021년에 OpenAI로부터 발표된 Multi Modal 관련 논문이다. 앞으로 이 벨로그에서는 Multi Modal의 초기 모델부터 최신 모델까지 리뷰와 스크래치 구현을 할 예정이다. Ab
2024년 9월 9일
2.[논문리뷰] Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision
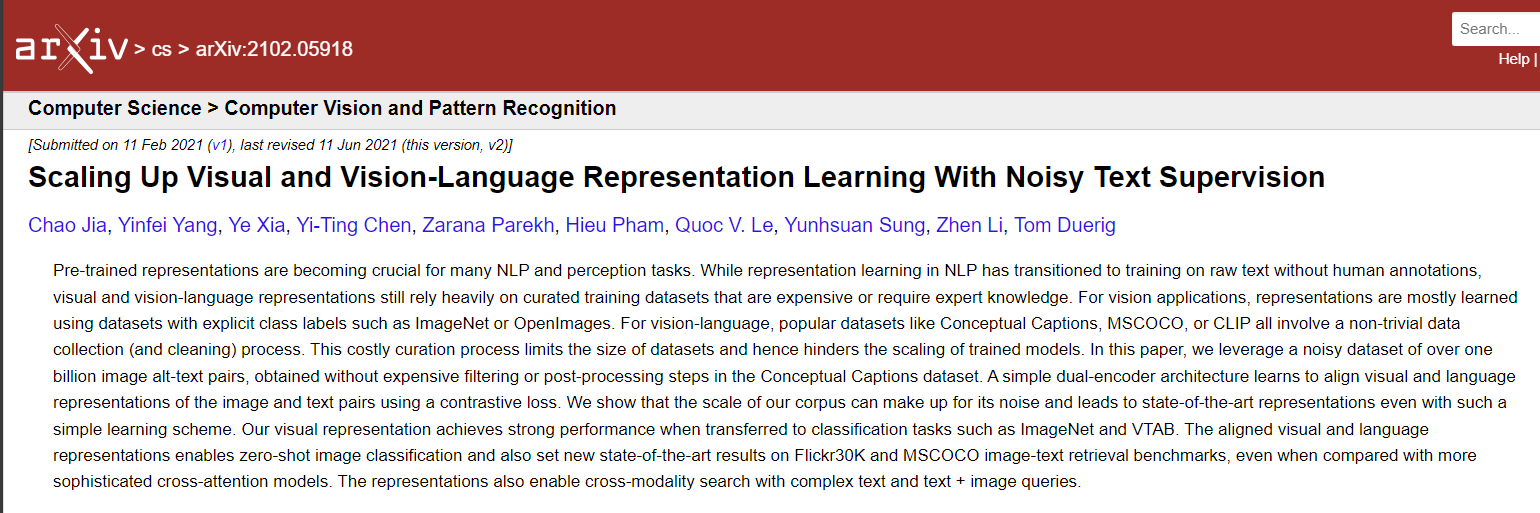
https://arxiv.org/abs/2102.059182021년 Google AI에서 발표한 논문이다. Abstract NLP에서는 사람이 직접 주석을 달지 않은 텍스트 데이터를 사용하여 학습하는 방식으로 전환되고 있지만, Vision 학습이나 Vision
2024년 9월 15일
3.[논문 리뷰] BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation

2022년 1월에 공개한 논문이다. Abstract Vision-Language Pre-training (VLP) 방법론에 관한 내용을 다룬다. 기존 모델들은 Understanding-based Task나 Generation-based Task 중 하나에만 뛰어난 경우
2024년 9월 24일
4.[논문 리뷰] LLAVA:Visual Instruction Tuning

https://llava-vl.github.io/2023년 7월에 컬럼비아 및 여러 대학교에서 연구한 VLP에 관한 논문이다.이 논문을 읽게 된 계기는 기존 논문들(CLIP, BLIP, Align 등)은 학습 시 데이터셋의 형식이 단순한 Image-Text p
2024년 10월 3일