Dask의 dataframe

1. dask dataframe 정리
dask데이터프레임은 index(수정!) 따라 배열된 여러 pandas데이터프레임(or 시리즈)의 묶음이다.
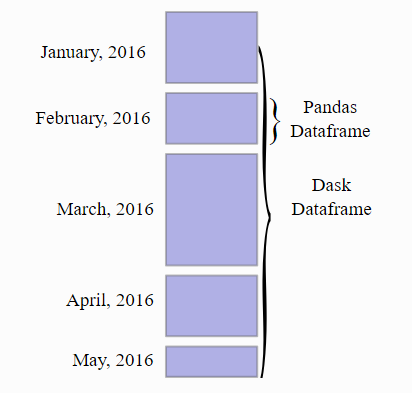
dask는 데이터를 가상의 데이터프레임으로 형성한다. 가상의 데이터프레임은 메모리에 모든 데이터를 적재하지 않는다. 가상의 데이터프레임을 파티션(partitions)으로 나누어 메모리에 순차적으로 올리고 내리면서 연산을 한다.
그렇기 때문에 대용량 데이터라도 그에 비해 적은 메모리로 처리가 가능해진다.
pandas의 read_csv로 csv파일을 읽어서 df에 저장하면, 디스크로부터 메모리로 데이터를 가져온다.
import pandas as pd
df = pd.read_csv("datda/2020-01-01.csv",parse_dates = ["timestamp"])
df이렇게되면 데이터를 빠르게 조작할 수 있다.
df.groupby("name").x.std()하지만 많은 파일이나 거대한 데이터를 판다스에 적재하기에는 메모리가 부족 문제가 발생할 수 있다. 따라서 dask를 사용한다.
import dask.dataframe as dd
df = dd.read_csv("datda/2020-01-01.csv",parse_dates = ["timestamp"])
df
Pandas 데이터프레임과 유사하지만 실제 결과를 보면 아직 데이터를 메모리에 읽지 않았기 때문에 값은 표시되지 않는다. df.head()를 해주어야 값을 알 수 있다.
df.head()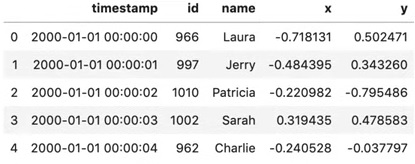
mean은 연산 반환값의 결과가 아닌 작업(task)이기 때문에 아래와 같이 lazy loading(메모리에 아직 로드 안됨)된다. 구체적으로 어떤 작업인지보려면 visualize 매서드를 사용하여 작업 그래프(graph)를 볼 수 있다.
df.x.mean()##결과##
Dask Series Structure:
npartitions=1
g0 float64
주소 ...
dtype: float64
Dask Name: dataframe-mean, 7 graph layers실제 값을 구하려면 결과로 받은 작업 객체의 compute 매서드를 호출해야 한다.
df.x.mean().compute()##결과##
나이 4.570000e+01
예금액 4.931679e+08
g0 5.288840e+01
dtype: float642. n파티션(npartitions)
npartitions 속성은 단일 Dask 데이터 프레임을 구성하는 Pandas 데이터 프레임의 수이다. 일반적으로 코어보다 몇 배 더 많은 파티션이 필요하다.
파티션시 유의점
- 파티션이 충분하지 않으면 모든 코어를 효과적으로 사용하지 못할 수 있다. 예를 들어 dask.dataframe에 파티션이 하나만 있는 경우 한 번에 하나의 코어만 작동할 수 있다.
- 파티션이 너무 많으면 스케줄러에서 각 작업을 계산할 위치를 결정하는 데 많은 오버헤드가 발생할 수 있다.
## 1.파티션 할당 예시
import dask.dataframe as dd
filepath = "/data40/adid/project-fileroot/p/performtest/100.csv"
df = pd.read_csv(filepath)
ddf = dd.from_pandas(df, npartitions=5)
ddf.npartitions## 2.repartition으로 파티션 설정하기
import dask.dataframe as dd
filepath = "/data40/adid/project-fileroot/p/performtest/100.csv"
ndf = dd.read_csv(filepath, blocksize=25e6)
ndf = ndf.repartition(npartitions=10)
Rustacean🦀