비식별화
식별자 제거를 통해 식별을 방지하거나, 비식별화 모델을 기반해 추론을 방지하는 것. 빅데이터 비식별화 기본 원칙에는 식별방지(식별자 제거), 추론방지(비식별화 모델 준수) 두가지가 존재. 비식별화 모델이란 다양한 추론 공격에 대해 개인정보 추론 위험 정도를 확률적/정량적으로 제한하는 방법론.
1. 식별자(Identifier)
개인 또는 개인과 관련한 사물에 고유하게 부여된 값 또는 이름. 정보집합물에 포함된 식별자는 삭제하는 것이 원칙이지만, 데이터 이용 목적상 반드시 필요한 식별자는 비식별 조치 후 활용해야 함.
예: 주민번호, 전화번호, 이메일, 이름, 계좌번호, 상세 주소, 기념일, MRI 사진, 유전자 정보, 암호화된 값
2. 속성자(Attribute value) 혹은 준 식별자(QI: Quasi-Identifiers)
식별자는 아니지만 개인과 관련된 정보로 다른 정보와 쉽게 결합하는 경우 특정 개인을 알아볼 수도 있는 정보.
정보집합물에 포함된 속성자도 데이터 이용 목적과 관련이 없는 경우에는 원칙적으로 삭제해야함. 데이터 이용 목적과 관련이 있는 속성자 중 식별요소가 있는 경우에는 변형/조작 하여 비식별 조치 해야함.
예: 성별, 연령(나이), 국적, 고향, 시·군·구명, 우편번호, 병역여부, 결혼여부, 종교, 취미, 동호회·클럽 등
3. 민감정보(SA:Sensitive Attributes)
개인의 사생활을 드러낼 수 있는 속성. 데이터 분석시 주로 측정되는 대상 속성으로, 대부분의 현대적 비식별화 기법들에서 해당 값들을 보존함.
예: 병명, 예금 잔고, 카드 결제 액
비식별화 모델
가능한 추론의 형태와 사생활 노출에 대한 정량적인 위험성을 규정하는 방법론
- 관계형 마이크로 데이터를 위한 프라이버시 모델
- k-anonymity(익명성), l-diversity(다양성), t-closeness(근접성)
- δ-presence, m-invariance, m-confidentiality, m-privacy 등
- 기타 유형의 데이터를 위한 비식별화 모델
- 그래프 데이터, 스트림 데이터, 위치 데이터 등
일반적으로 데이터를 활용할 때, 개인을 직접 식별할 수 있는 식별자는 삭제한다. 하지만 일부 데이터가 다른 데이터와 결합하여 개인이 식별될 수 있는 문제가 발생할 수 있다.
예: 선거인명부와 지역 코드, 연령, 성별에 의해 결합되면, 개인의 민감한 정보인 병명이 드러날 수 있음(미국 매사추세츠 주, ‘선거인명부’와 ‘공개 의료데이터’가 결합하여 개인의 병명 노출 사례)
1. k-익명성
- 공개된 데이터에 대한 연결공격(linkage attack) 등 취약점을 방어하기 위해 제안된 프라이버시 모델
- 주어진 데이터 집합에서 같은 값이 적어도 k개 이상 존재하도록 하여 쉽게 다른 정보로 결합할 수 없도록 함
- 동질 그룹 내의 데이터 개체 수를 계산하여 k를 구함
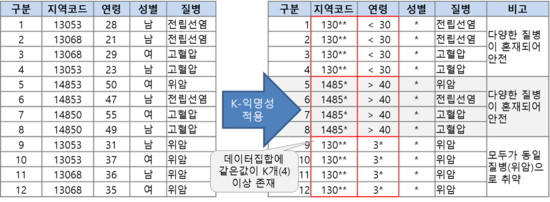
k-익명성 모델은 비식별화를 할 때 정보의 다양성을 고려하지 않고, 공격자의 배경지식을 고려하지 않아 이를 이용한 공격에 취약함
2. l-다양성
- k-익명성에 대한 두 가지 공격, 즉 동질성 공격 및 배경지식에 의한 공격을 방어하기 위한 모델
- 동질 그룹 내 특정 속성에서 최소한 l 개 이상의 구분되는 값이 존재하도록 제약하는 방법 (nunique >= l)
- 동질 그룹내 특정 속성에 대하여 고유한 값의 갯수를 계산하여 l을 구함
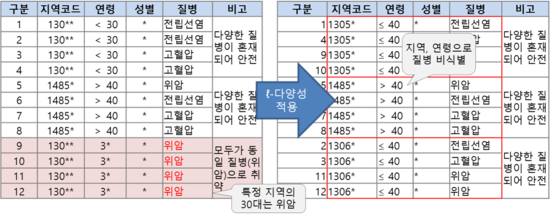
ℓ-다양성 모델에 의해 비식별되었더라도 쏠림 공격 및 유사성 공격을 방지하기 위해선 t-근접성 적용 필요
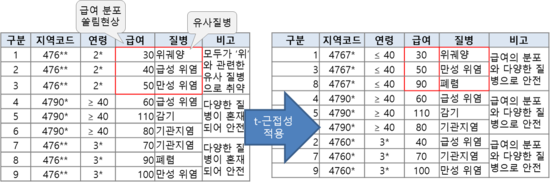
3. t-근접성
- ℓ-다양성의 취약점(쏠림 공격, 유사성 공격)을 보완하기 위한 모델
- 각 동질 집합에서 ‘특정 정보의 분포’가 전체 데이터집합의 분포와 비교하여 너무 특이하지 않도록 함
- 전체 데이터셋의 분포와 동질 그룹 내의 데이터셋 분포를 비교하여 분포 유사도를 나타내는 거리 값이 최대 t 이하가 되도록 제약 (t는 EMD로 계산)
참고자료
