같은 마크업 에러인데 왜 브라우저 반응은 다를까? HTML 파서의 숨겨진 규칙 (feat. Hydration Error)

최근 "밑바닥부터 시작하는 웹 브라우저" 북스터디에서 HTML 파서를 간이로 구현해볼 기회가 있었습니다.
"실제 브라우저는 엉망인 HTML을 어떻게 처리할까?" 라는 궁금증이 생겨,의도적으로 유효하지 않은 마크업들을 W3C Validator에 넣어봤습니다.
🥸 아래 코드에서 어떤 마크업 유효성 위반이 있을까요?
<!DOCTYPE html>
<html>
<body>
<!-- 케이스 1 -->
<p>
문단 시작
<div>이것은 블록 요소입니다</div>
문단 끝
</p>
<!-- 케이스 2 -->
<span>
인라인 텍스트
<div>여기도 블록 요소입니다</div>
</span>
</body>
</html>두 케이스 모두 phrasing content만 허용하는 요소 안에 flow content(블록 요소) 인 <div>를 넣었으니 비슷한 에러가 나올 거라 예상했는데…
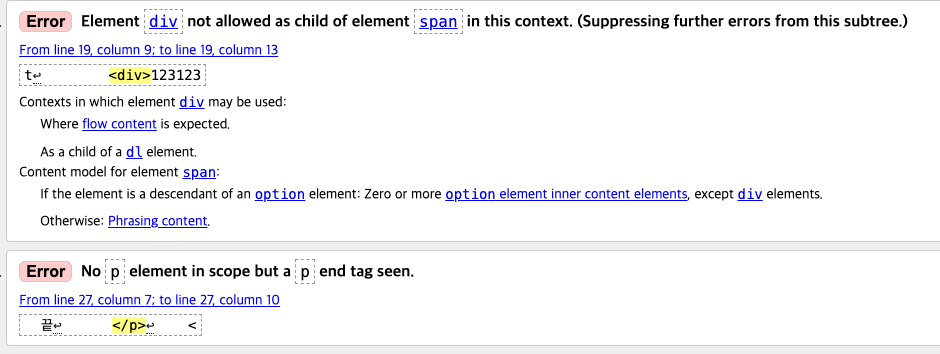
"어? 이상하네요?"
<span><div></div></span>: "div는 span의 자식으로 허용되지 않는다" ✅ 예상대로!<p><div></div></p>: "p 요소가 없는데 p 닫는 태그가 보인다" 🤔 ???
왜 비슷한 이슈인데 에러 메시지가 완전히 다를까?
이 이상한 에러 메시지가 HTML 파서의 동작을 이해하는 핵심 단서였습니다!
🔍 브라우저는 어떻게 파싱할까?
"여는 태그 없이 닫는 태그만 있다"는 에러의 의미를 이해하기 위해, 순수 HTML에서 브라우저가 어떻게 동작하는지 테스트해봤습니다.
HTML 파일
<!DOCTYPE html>
<html>
<body>
<div>
<p>
문단 시작
<div>이것은 블록 요소입니다</div>
문단 끝
</p>
</div>
<div>
<span>
인라인 텍스트
<div>여기도 블록 요소입니다</div>
</span>
</div>
</body>
</html>브라우저가 실제로 생성한 DOM (개발자 도구 Elements 탭 기준):
<!-- p 케이스: 구조가 완전히 바뀜 -->
<p>문단 시작</p>
<div>블록 요소</div>
문단 끝
<p></p> <!-- 빈 p가 하나 더 생김! -->
<!-- span 케이스: 그대로 유지됨 -->
<span>
인라인 텍스트
<div>블록 요소</div>
</span><p> 케이스는 구조가 완전히 바뀌었고, 심지어 빈 <p></p>까지 생겼는데
<span> 케이스는 유효하지 않은 마크업임에도 작성한 구조 그대로 유지되었습니다.
왜 이런 차이가 발생하는지 알아보겠습니다!
1️⃣ Optional End Tags (정상 동작)
HTML 파서는 <p> 바로 뒤에 <div>, <section>, <article> 같은 블록 요소가 나오면
</p>를 아예 생략해도 된다고 규정하고 있습니다.
→ WHATWG HTML Living Standard - 8.1.2.4 Optional tags
A p element’s end tag may be omitted if the p element is immediately followed by an address, article, aside, blockquote, div …
즉, 개발자가 </p>를 안 써도 되고,
파서도 자동으로 </p>를 삽입해서 <p>를 닫아버립니다.
이건 에러가 아니라 완전히 정상적인 파싱 규칙입니다.
<!-- 개발자가 이렇게만 작성해도 유효한 HTML -->
<p>Hello
<div>World</div>→ 브라우저가 만든 실제 DOM
<p>Hello</p>
<div>World</div>✅ 완벽한 HTML, 아무 문제 없음!
2️⃣ Parse Error + 에러 복구 (이게 진짜 문제)
그런데 </p>를 실제로 작성했죠.
파서가 보는 흐름
<p>열림<div>만남 → Optional End Tags 규칙 발동 → 자동으로</p>삽입 → p 닫힘<div>블록 요소</div>처리- 텍스트 “문단 끝” 처리
- 우리가 쓴 실제
</p>를 만남 → 그런데 지금 열린<p>가 없음!
여기서부터 진짜 Parse Error가 발생합니다.
→ WHATWG HTML - “in body” insertion mode, “An end tag whose tag name is “p””
If the stack of open elements does not have a p element in scope, this is a parse error;
insert an HTML element for a “p” start tag token (with no attributes), and then pop that p element off the stack.
“열린 p가 없으면 파싱 에러야. 그럼 빈 <p> 하나 삽입하고 바로 닫아버려.”
그래서 우리가 개발자 도구에서 보는 그 의문의 빈 <p></p>가 생기는 겁니다!
| 단계 | 메커니즘 | 에러인가? | 결과 |
|---|---|---|---|
<div> 만나서 <p> 닫힘 | Optional End Tags 규칙 | 아니오 | 정상 동작 (자동 종료) |
실제 </p> 만남 | Unmatched end tag → Parse Error + 복구 | 예 | 빈 <p></p> 삽입 |
이제 W3C Validator 에러 메시지도 완전히 이해가 되죠?
<span><div>→ 단순 Content Model 위반 (구조는 그대로 유지)<p><div></div></p>→ Optional End Tags로 일찍 닫히고 → 남은</p>가 Parse Error → 복구로 빈<p>생성
💡 Next.js Hydration Error
이 HTML 파서의 원리를 이해하고 나니, 예전에 겪었던 경험이 떠올랐습니다.
Next.js 프로젝트에서 AI가 생성한 코드에서 이런 에러를 마주쳤던기억이 있습니다.
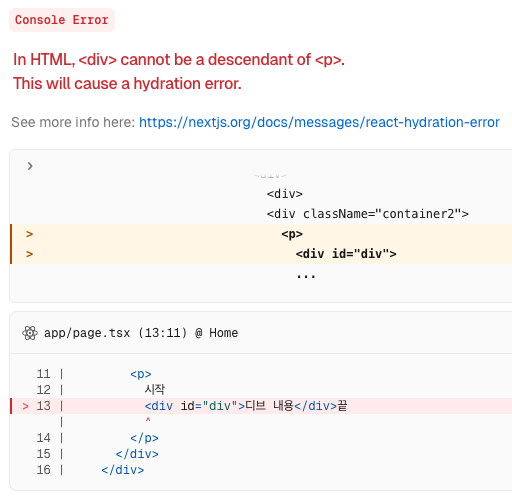
당시에는 "마크업 유효성이 실패한게 hydration에 왜 걸리지?"
정도로 가볍게 생각하고 넘겼는데, 이제 그 이유를 명확하게 알게 되었습니다.
🎯 Next.js SSR + Hydration 과정
먼저 중요한 전제를 이해해야 합니다.
전제: React는 DOM API를 직접 사용한다
<p><div>내용</div></p>
// ↓ JSX 컴파일
React.createElement('p', null,
React.createElement('div', null, '내용')
)
// ↓ 클라이언트에서 실제 DOM 생성 시
const p = document.createElement('p'); // DOM API 직접 사용
const div = document.createElement('div');
div.textContent = '내용';
p.appendChild(div); // HTML 파서를 거치지 않음!React는 DOM API를 직접 사용하므로 HTML 파싱 규칙을 우회합니다!
이제 SSR + Hydration 과정을 단계별로 살펴봅시다.
1단계: 서버 사이드 렌더링
// 서버에서
const html = renderToString(<p><div>내용</div></p>);
// 결과: "<p><div>내용</div></p>" (HTML 문자열)
// 브라우저로 전송2단계: 브라우저가 HTML 파싱
<!-- 받은 HTML 문자열 -->
<p><div>내용</div></p>
<!-- HTML 파서가 처리 -->
<p></p> <!-- <div> 만나서 자동 종료 -->
<div>내용</div>
<p></p> <!-- 일치하지 않는 </p> 태그가 빈 요소로 변환 -->3단계: 클라이언트 하이드레이션
// React가 DOM API로 직접 생성
hydrateRoot(
document.getElementById('root'), // ← 파싱된 DOM
<p><div>내용</div></p> // ← React 예상 구조
);
// React 예상: <p><div>내용</div></p>
// 실제 DOM: <p></p><div>내용</div><p></p>
// → Mismatch! Hydration Error!💡 그냥 넘겼던 에러의 '진짜' 이유
Next.js에서 하이드레이션 에러가 떴을 때 개선이 쉬운 문제라, "하이드레이션에서 마크업 유효성을 체크하나?" 하고 대수롭지 않게 넘겼었는데 브라우저의 HTML파서가 어떻게 동작하는지 공부하고 나서야 왜 에러가 발생했는지 깨달았습니다.
단순히 마크업이 틀려서가 아니라, HTML파서의 동작으로 인해 서버랑 클라이언트가 만든 DOM이 다르기 때문에 필연적으로 발생하는 에러였다니... 😅
그 바탕이 되는 브라우저의 동작 원리와 기본기를 이해하는 것이 얼마나 중요한지 느끼는 계기가 되었습니다!
해결은 1초면 끝나는 정말 사소한 이슈였지만, 그 이면에는 이런 디테일한 원리가 숨어있었네요.
역시 "그런가 보다" 하고 넘기는 것보다, 가끔은 "도대체 왜 그럴까?" 하고 파보는 게 개발의 재미인 것 같습니다! 🚀
