02_함수

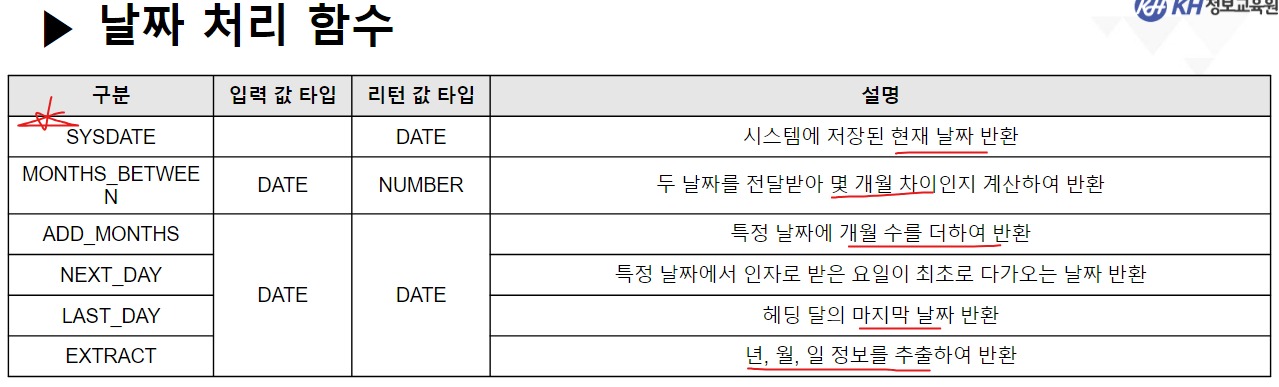
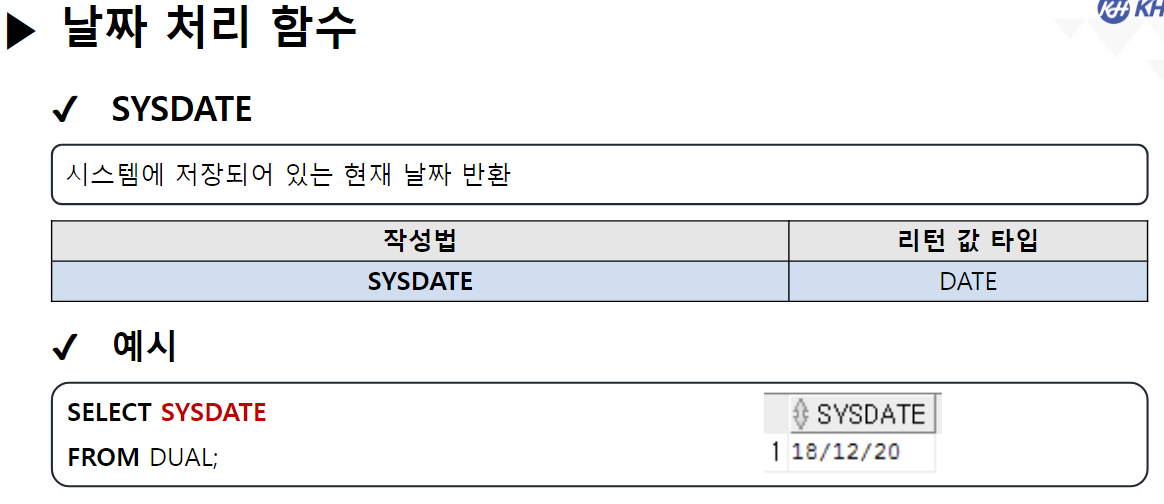
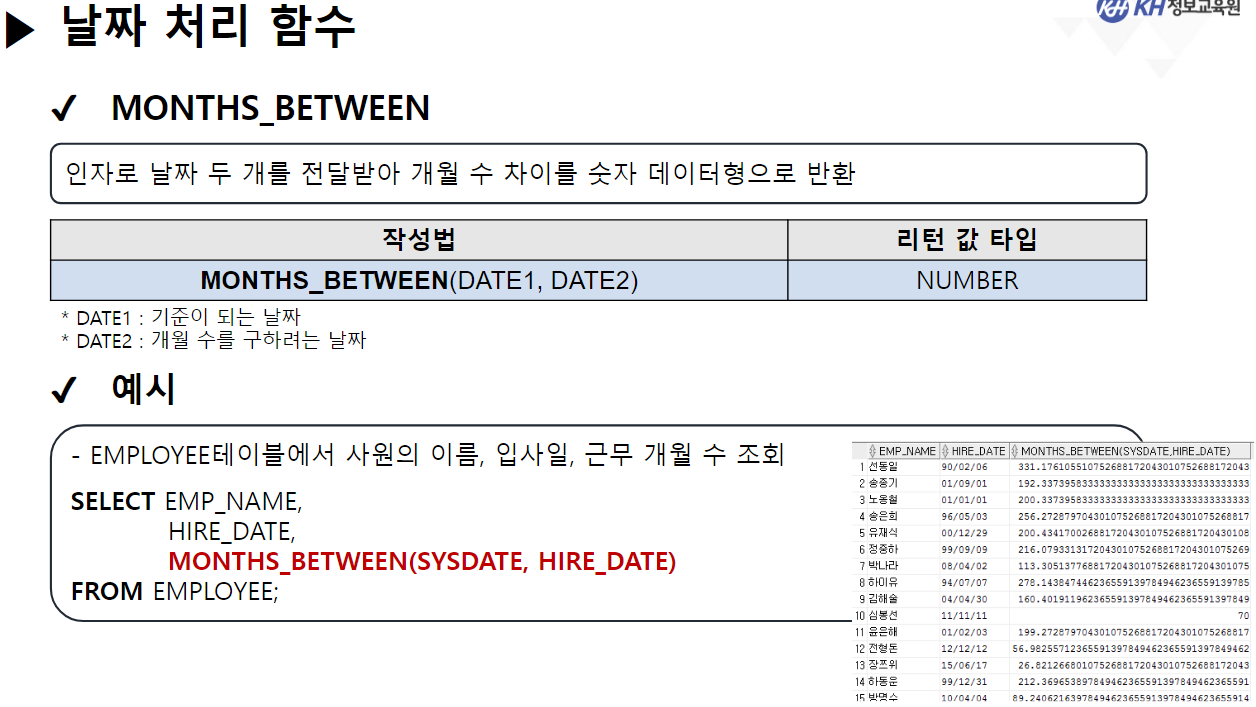
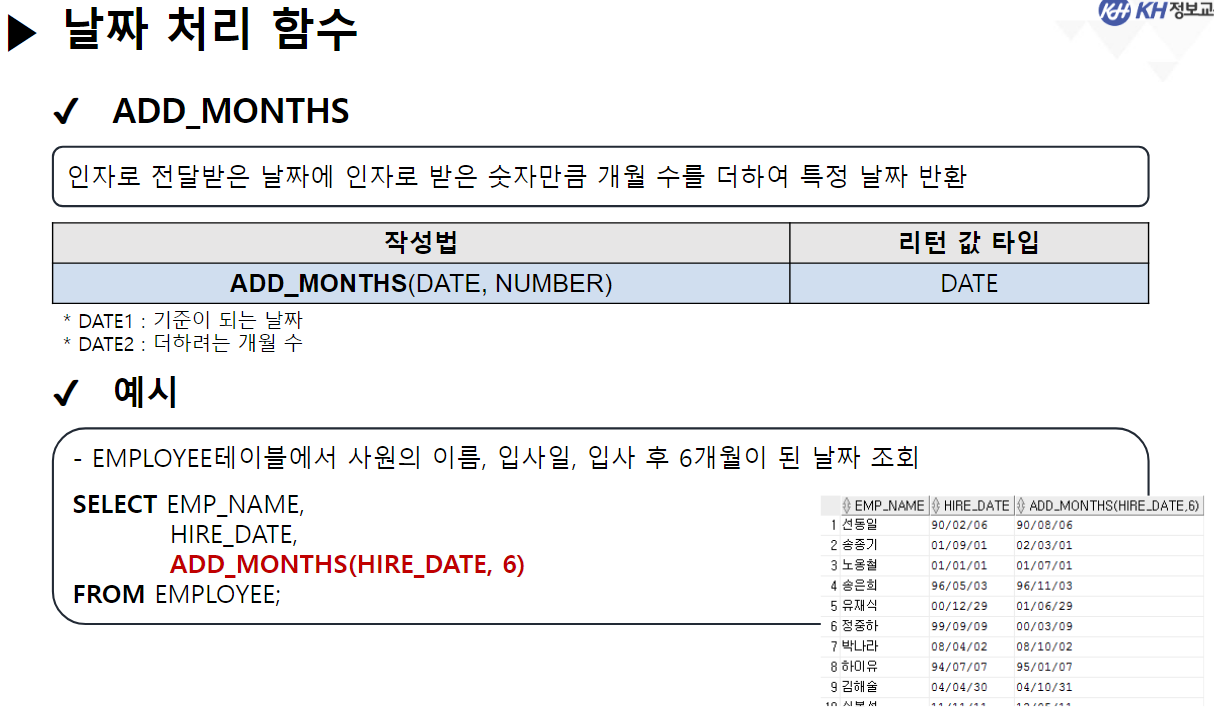
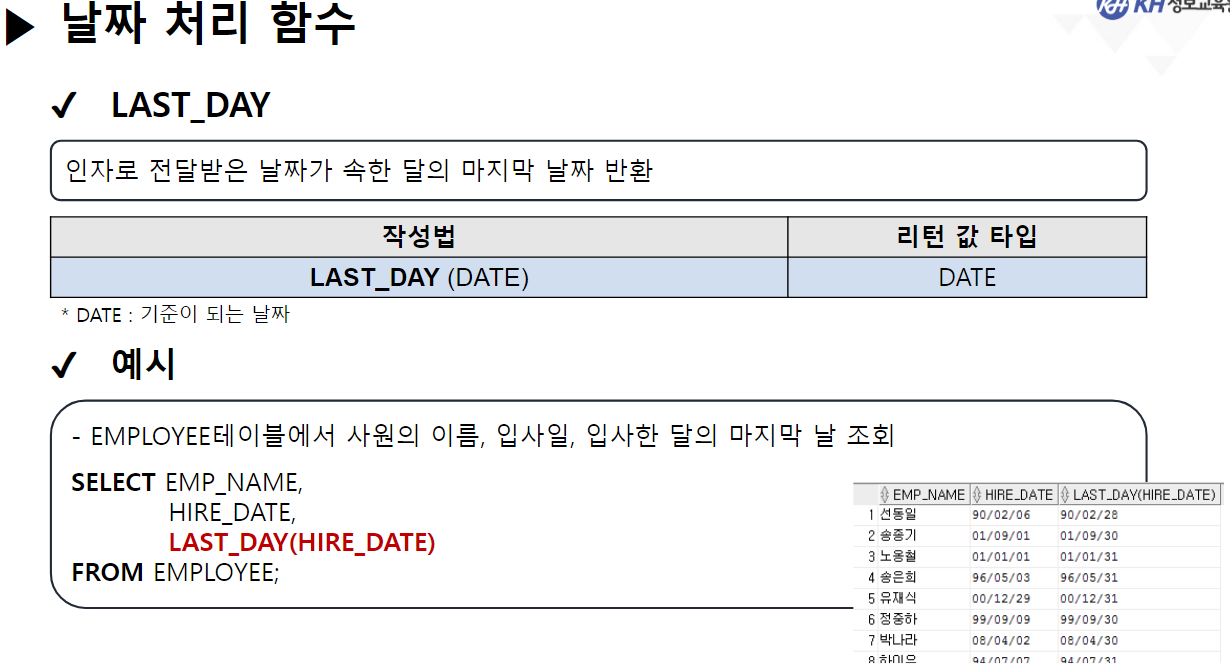
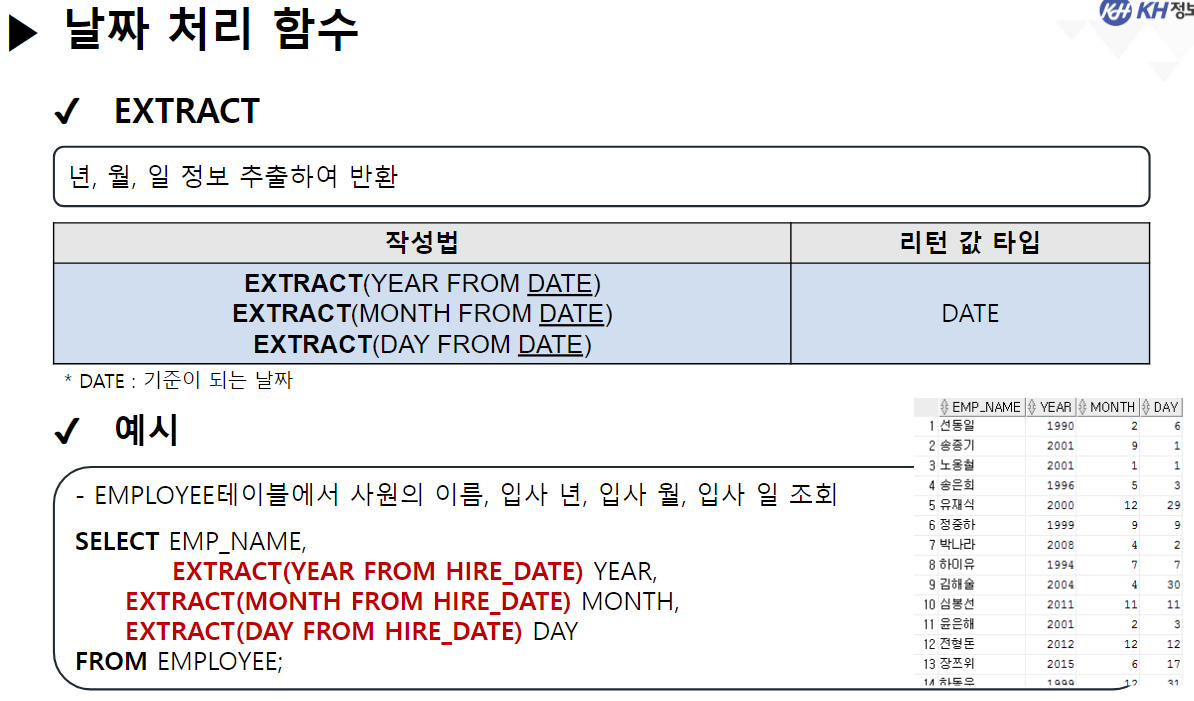
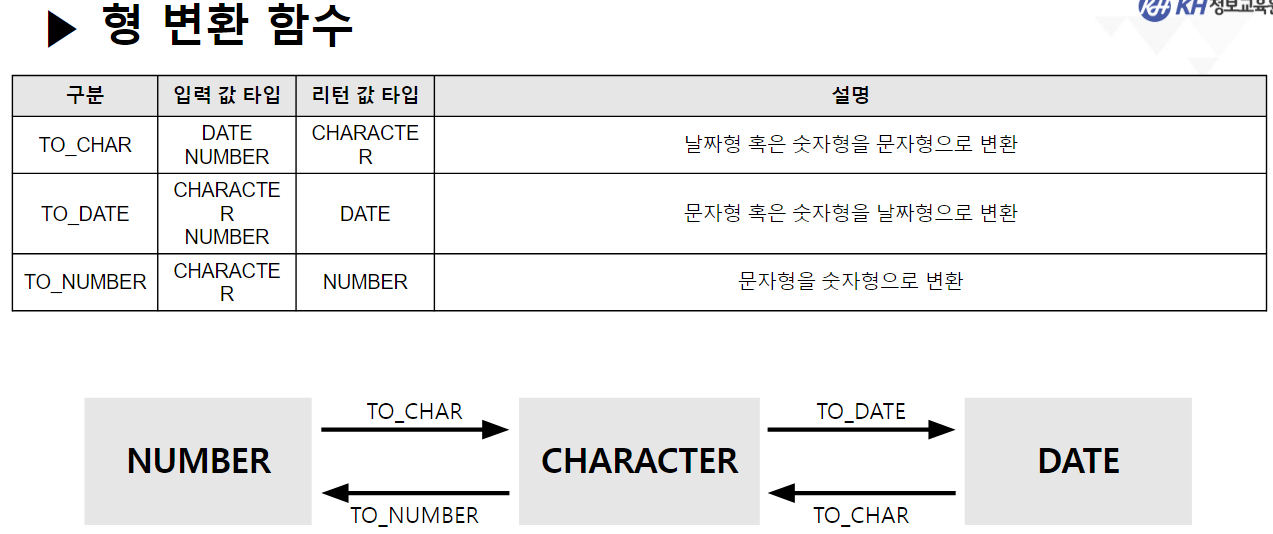
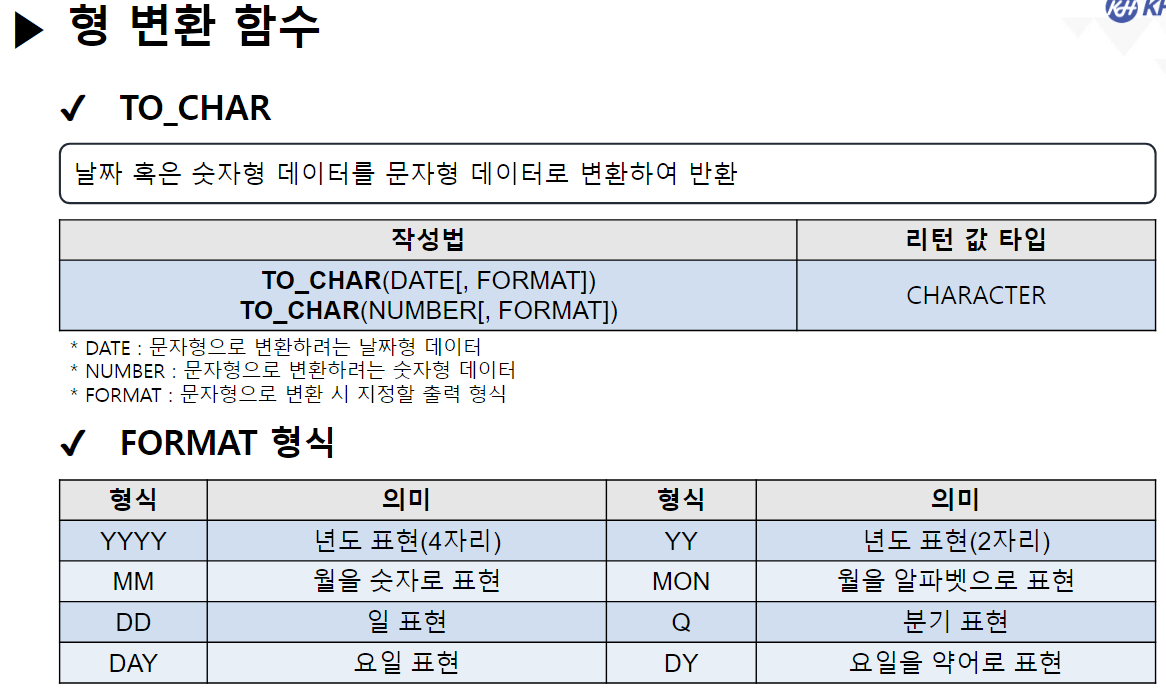
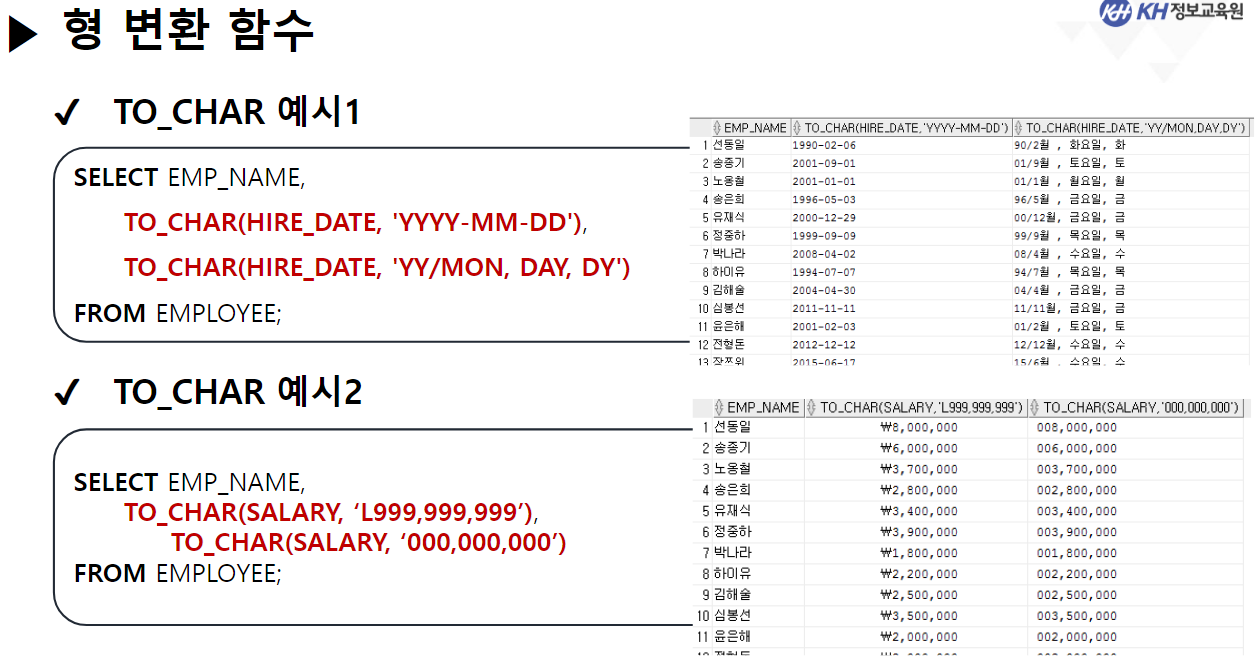
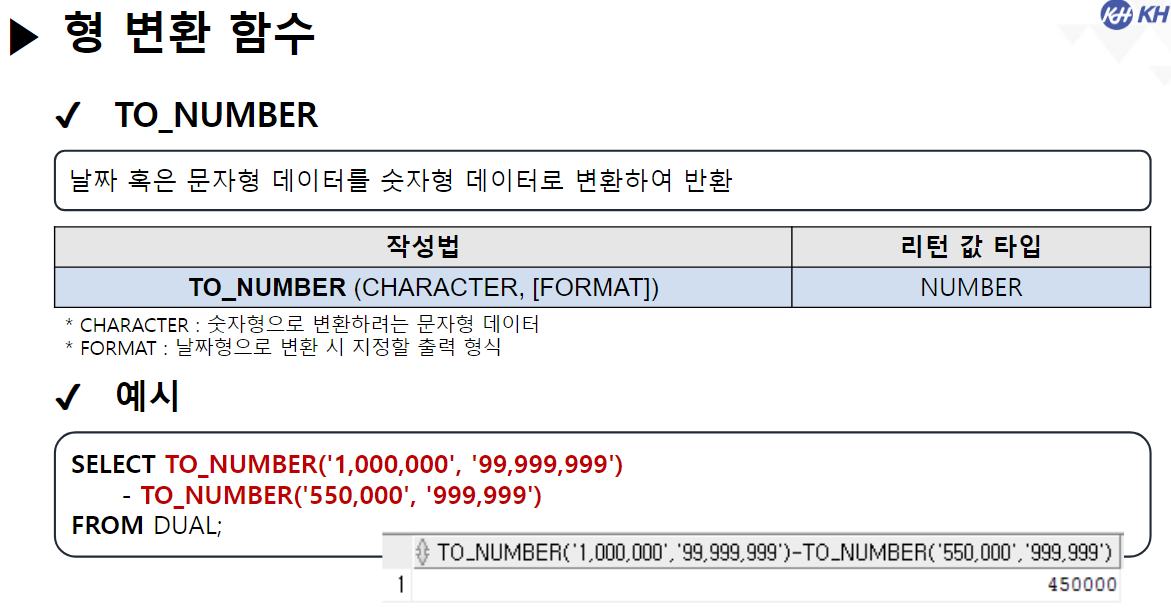
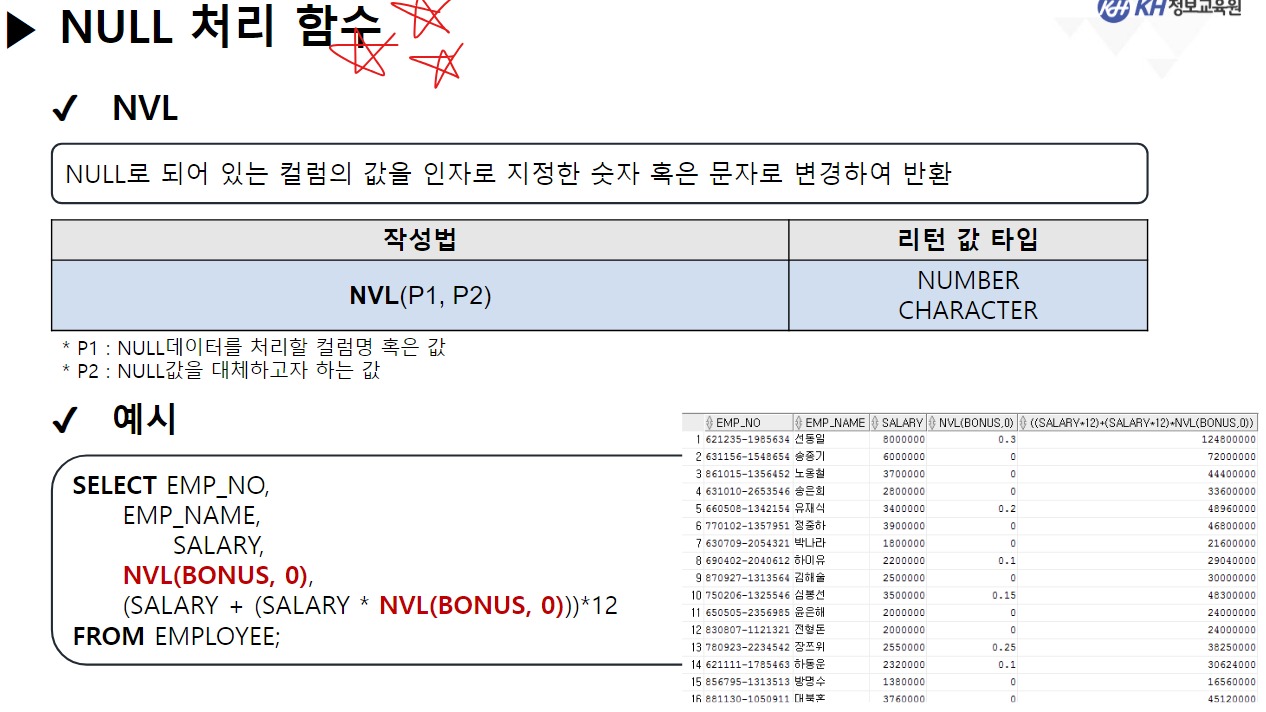
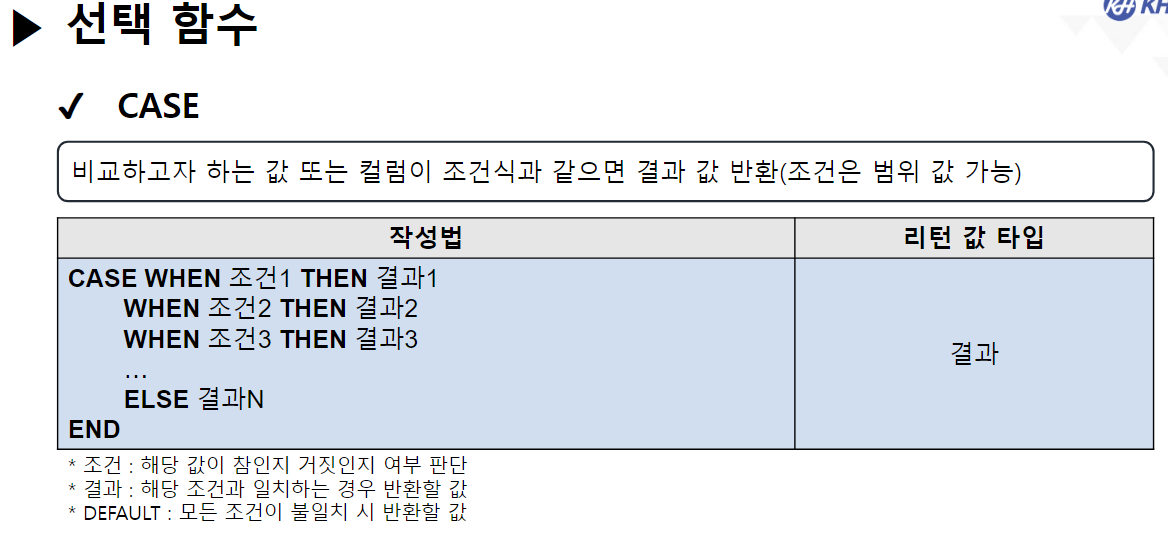
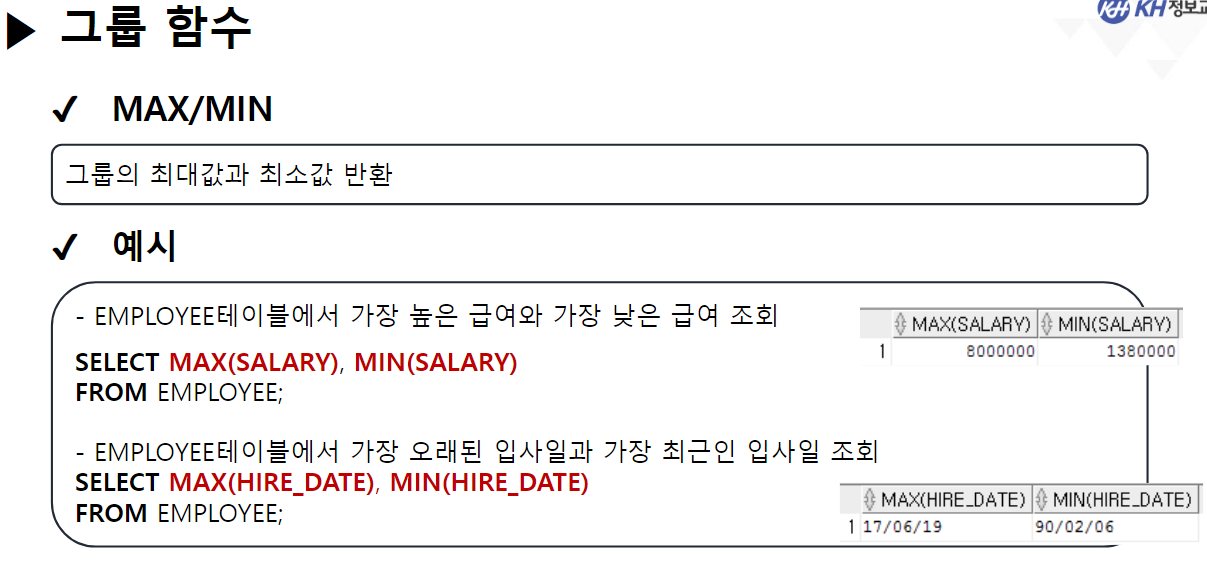
/* 날짜(DATE) 관련 함수 */ -- SYSDATE : 시스템에 현재 시간(년, 월, 일, 시, 분, 초)을 반환 SELECT SYSDATE FROM DUAL; -- SYSTIMESTAMP : SYSDATE + MS 단위 추가 SELECT SYSTIMESTAMP FROM DUAL; -- TIMESTAMP : 특정 시간을 나타내거나 기록하기 위한 문자열 -- MONTHS_BETWEEN(날짜, 날짜) : 두 날짜의 개월 수 차이 반환 SELECT ABS( ROUND( MONTHS_BETWEEN(SYSDATE, '2023-12-22'), 3) ) "수강 기간(개월)" FROM DUAL; -- 4.568 -- EMPLOYEE 테이블에서 -- 사원의 이름, 입사일, 근무한 개월수, 근무 년차 조회 SELECT EMP_NAME, HIRE_DATE, CEIL( MONTHS_BETWEEN(SYSDATE, HIRE_DATE) ) "근무한 개월 수", CEIL( MONTHS_BETWEEN(SYSDATE, HIRE_DATE) / 12) || '년차' "근무 년차" FROM EMPLOYEE; /* || : 연결 연산자 (문자열 이어쓰기) */ -- ADD_MONTHS(날짜, 숫자) : 날짜에 숫자만큼의 개월 수를 더함. (음수도 가능) SELECT ADD_MONTHS(SYSDATE, 4) FROM DUAL; -- 현재 날짜에서 4개월 뒤 SELECT ADD_MONTHS(SYSDATE, -1) FROM DUAL; -- 현재 날짜에서 1개월 전 -- LAST_DAY(날짜) : 해당 달의 마지막 날짜를 구함 SELECT LAST_DAY(SYSDATE) FROM DUAL; SELECT LAST_DAY('2020-02-01') FROM DUAL; -- EXTRACT : 년, 월, 일 정보를 추출하여 리턴 -- EXTRACT(YEAR FROM 날짜) : 년도만 추출 -- EXTRACT(MONTH FROM 날짜) : 월만 추출 -- EXTRACT(DAY FROM 날짜) : 일만 추출 -- EMPLOYEE 테이블에서 -- 각 사원의 이름, (입사 년도, 월, 일) 입사일 조회 -- 입사일 -- 2023년 08월 04일 SELECT EMP_NAME, EXTRACT(YEAR FROM HIRE_DATE) || '년 ' || EXTRACT(MONTH FROM HIRE_DATE) || '월 ' || EXTRACT(DAY FROM HIRE_DATE) || '일' AS 입사일 FROM EMPLOYEE; --------------------------------------------------------------------------------------- /* 형변환 함수 */ -- 문자열(CHAR), 숫자(NUMBER), 날짜(DATE) 끼리 형변환 가능 /* 문자열로 변환 */ -- TO_CHAR(날짜, [포맷]) : 날짜형 데이터를 문자형 데이터로 변경 -- TO_CHAR(숫자, [포맷]) : 숫자형 데이터를 문자형 데이터로 변경 -- <숫자 변환 시 포맷 패턴> -- 9 : 숫자 한칸을 의미, 여러개 작성 시 오른쪽 정렬 -- 0 : 숫자 한칸을 의미, 여러개 작성 시 오른쪽 정렬 + 빈칸 0 추가 -- L : 현재 DB에 설정된 나라의 화폐 기호 SELECT TO_CHAR(1234, '99999') FROM DUAL; -- ' 1234' SELECT TO_CHAR(1234, '00000') FROM DUAL; -- '01234' SELECT TO_CHAR(1234) FROM DUAL; -- '1234' SELECT TO_CHAR(1000000, '9,999,999') || '원' FROM DUAL; SELECT TO_CHAR(1000000, 'L9,999,999') FROM DUAL; -- '\1,000,000'-- <날짜 변환 시 포맷 패턴> -- YYYY : 년도 / YY : 년도 (짧게) -- MM : 월 -- DD : 일 -- AM 또는 PM : 오전/오후 표시 -- HH : 시간 / HH24 : 24시간 표기법 -- MI : 분 / SS : 초 -- DAY : 요일(전체) / DY : 요일(요일명만 표시) --2023/08/04 10:06:35 금요일 SELECT TO_CHAR(SYSDATE, 'YYYY/MM/DD HH24:MI:SS DAY') FROM DUAL; -- 08/04 (금) SELECT TO_CHAR(SYSDATE, 'MM/DD (DY)') FROM DUAL; -- 2023년 08월 04일 (금) SELECT TO_CHAR(SYSDATE, 'YYYY"년" MM"월" DD"일" (DY)') FROM DUAL; --SQL Error [1821] [22008]: ORA-01821: 날짜 형식이 부적합합니다 -- 년, 월, 일이 날짜를 나타내는 패턴으로 인식이 안되서 오류 발생 --> "" 쌍따옴표를 이용해서 단순한 문자로 인식시키면 해결됨 ---------------------------------------------------------------------------------------- /* 날짜로 변환 TO_DATE */ -- TO_DATE(문자형 데이터, [포맷]) : 문자형 데이터를 날짜로 변경 -- TO_DATE(숫자형 데이터, [포맷]) : 숫자형 데이터를 날짜로 변경 --> 지정된 포맷으로 날짜를 인식함 SELECT TO_DATE('2022-09-02') FROM DUAL; -- DATE 타입 변환 SELECT TO_DATE(20230804) FROM DUAL; SELECT TO_DATE('230803 101835', 'YYMMDD HH24MISS') FROM DUAL; -- SQL Error [1861] [22008]: ORA-01861: 리터럴이 형식 문자열과 일치하지 않음 --> 패턴을 적용해서 작성된 문자열의 각 문자가 어떤 날짜 형식인지 인지 시킴 -- EMPLOYEE 테이블에서 각 직원이 태어난 생년월일 조회 -- 630709-2054321 -- 내 풀이 SELECT EMP_NAME, TO_CHAR(TO_DATE(SUBSTR(EMP_NO, 1, 6), 'RRMMDD'), 'YYYY"년" MM"월" DD"일"') 생년월일 FROM EMPLOYEE; -- 강사님 풀이 SELECT EMP_NAME, TO_CHAR(TO_DATE( SUBSTR( EMP_NO, 1, INSTR(EMP_NO, '-') -1 ), 'RRMMDD'), 'YYYY"년" MM"월" DD"일"') AS 생년월일 FROM EMPLOYEE; -- Y 패턴 : 현재 세기(21세기 == 20XX년 == 2000년대) -- R 패턴 : 1세기 기준으로 절반(50년) 이상인 경우는 이전세기 (1900년대) -- 절반(50년) 미만인 경우 현재 세기(2000년대) SELECT TO_DATE('500505', 'YYMMDD') FROM DUAL; SELECT TO_DATE('490505', 'RRMMDD') FROM DUAL; -------------------------------------------------------------------------------------------- /* 숫자 형변환 */ -- TO_NUMBER(문자데이터, [포맷]) : 문자형데이터 숫자 데이터로 변경 SELECT '1,000,000' + 500000 FROM DUAL; SELECT TO_NUMBER('1,000,000', '9,999,999') + 500000 FROM DUAL; -- 1,500,000 -- SQL Error [1722] [42000]: ORA-01722: 수치가 부적합합니다 /* NULL 처리 함수 중요 !! */ -- NVL(컬럼명, 컬럼값이 NULL 일때 바꿀 값) : NULL인 컬럼값을 다른 다른값으로 변경 /* NULL 과 산술 연산을 진행하면 결과는 무조건 NULL */ SELECT EMP_NAME, SALARY, NVL(BONUS, 0), SALARY * NVL(BONUS, 0) FROM EMPLOYEE; -- NVL2(컬럼명, 바꿀값1, 바꿀값2) -- 해당 컬럼의 값이 있으면 바꿀값1로 변경, -- 해당 컬럼이 NULL이면 바꿀값2로 변경 -- EMPLOYEE 테이블에서 보너스를 받으면 'O' , 안받으면 'X' 조회 SELECT EMP_NAME, NVL2(BONUS, 'O', 'X') "보너스 수령" FROM EMPLOYEE;-------------------------------------------------------------------------------------------- /* 선택 함수 */ -- 여러 가지 경우에 따라 알맞은 결과를 선택할 수 있음. -- DECODE(계산식 | 컬럼명, 조건값1, 선택값1, 조건값2, 선택값2, ...., 아무것도 일치하지 않을 때) -- 비교하고자 하는 값 또는 컬럼이 조건식과 같으면 결과값 반환 -- 일치하는 값을 확인(자바의 SWITCH 비슷함) -- 직원의 성별 구하기 (남 : 1 / 여 : 2) -- 630709-2054321 SELECT EMP_NAME, DECODE (SUBSTR(EMP_NO, 8, 1) , '1', '남성', '2', '여성') 성별 FROM EMPLOYEE; -- 직원의 급여를 인상하고자 한다. -- 직급 코드가 J7인 직원은 20% 인상, -- 직급 코드가 J6인 직원은 15% 인상, -- 직급 코드가 J5인 직원은 10% 인상, -- 그 외 직급은 5% 인상 -- 내 풀이 SELECT EMP_NAME, JOB_CODE, SALARY, DECODE(JOB_CODE, 'J7', SALARY * 0.2, 'J6', SALARY * 0.15, 'J5', SALARY * 0.1, SALARY * 0.05) 인상급여 FROM EMPLOYEE; -- 강사님 풀이 SELECT EMP_NAME, JOB_CODE, SALARY, DECODE(JOB_CODE, 'J7', '20%', 'J6', '15%', 'J5', '10%', '5%') 인상률, DECODE(JOB_CODE, 'J7', SALARY * 1.2, 'J6', SALARY * 1.15, 'J5', SALARY * 1.1, SALARY * 1.05) "인상된 급여" FROM EMPLOYEE; -- CASE WHEN 조건식 THEN 결과값 -- WHEN 조건식 THEN 결과값 -- ELSE 결과값 -- END -- 비교하고자 하는 값 또는 컬럼이 조건식과 같으면 결과 값 반환 -- 조건은 범위 값 가능 -- EMPLOYEE 테이블에서 -- 급여가 500만원 이상이면 '대' -- 급여가 300만 이상 500만 미만이면 '중' -- 급여가 300만 미만 '소' 으로 조회 SELECT EMP_NAME, SALARY, CASE WHEN SALARY >= 5000000 THEN '대' -- if WHEN SALARY >= 3000000 THEN '중' -- else if ELSE '소' END "급여 받는 정도" FROM EMPLOYEE; ----------------------------------------------------------------------------------- /* 그룹 함수 */ -- 하나 이상의 행을 그룹으로 묶어 연산하여 총합, 평균 등의 하나의 결과 행으로 반환하는 함수 -- SUM(숫자가 기록된 컬럼명) : 합계 -- 모든 직원의 급여 합 SELECT SUM(SALARY) FROM EMPLOYEE; -- AVG(숫자가 기록된 컬럼명) : 평균 -- 전 직원 급여 평균 SELECT ROUND(AVG(SALARY)) FROM EMPLOYEE; -- 부서코드가 'D9' 인 사원들의 급여 합, 평균 조회 /* 3 */SELECT SUM(SALARY), ROUND(AVG(SALARY)) /* 1 */FROM EMPLOYEE /* 2 */WHERE DEPT_CODE = 'D9'; -- MIN(컬럼명) : 최솟값 -- MAX(컬럼명) : 최대값 --> 타입 제한 없음(숫자: 대/소, 날짜: 과거/미래, 문자열: 문자 순서) -- 급여 최소값, 가장 빠른 입사일, 알파벳 순서가 가장 빠른 이메일 SELECT MIN(SALARY), MIN(HIRE_DATE), MIN(EMAIL) FROM EMPLOYEE; -- 급여 최대값, 가장 늦은 입사일, 알파벳 순서가 가장 느린 이메일 SELECT MAX(SALARY), MAX(HIRE_DATE), MAX(EMAIL) FROM EMPLOYEE; -- EMPLOYEE 테이블에서 급여를 가장 많이 받는 사원의 -- 이름, 급여, 직급 코드 조회 SELECT EMP_NAME, SALARY, JOB_CODE FROM EMPLOYEE WHERE SALARY = ( SELECT MAX(SALARY) FROM EMPLOYEE ); -- 서브쿼리 + 그룹함수 -- * COUNT(* | 컬럼명) : 행 개수를 헤아려서 리턴 -- COUNT([DISTINCT] 컬럼명) : 중복을 제거한 행 개수를 헤아려서 리턴 -- COUNT(*) : NULL을 포함한 전체 행 개수를 리턴 -- COUNT(컬럼명) : NULL을 제외한 실제 값이 기록된 행 개수를 리턴함 -- EMPLOYEE 테이블의 행의 개수 SELECT COUNT(*) FROM EMPLOYEE; -- BONUS를 받는 사원의 수 SELECT COUNT(*) FROM EMPLOYEE WHERE BONUS IS NOT NULL; -- 9명 SELECT COUNT(BONUS) FROM EMPLOYEE; -- 9 SELECT DISTINCT DEPT_CODE FROM EMPLOYEE; -- 7 SELECT COUNT(DISTINCT DEPT_CODE) FROM EMPLOYEE; -- 6 -- COUNT(컬럼명)에 의해서 NULL을 제외한 실제 값이 있는 행의 개수만 조회 -- EMPLOYEE 테이블에서 성별이 남성인 사원의 수 조회 -- 내 풀이 SELECT COUNT(DECODE(SUBSTR(EMP_NO, 8, 1), '1', '남성')) "남성 사원 수" FROM EMPLOYEE; -- 강사님 풀이 SELECT COUNT(*) FROM EMPLOYEE WHERE SUBSTR(EMP_NO, 8, 1) = '1';






03_GROUP BY & HAVING


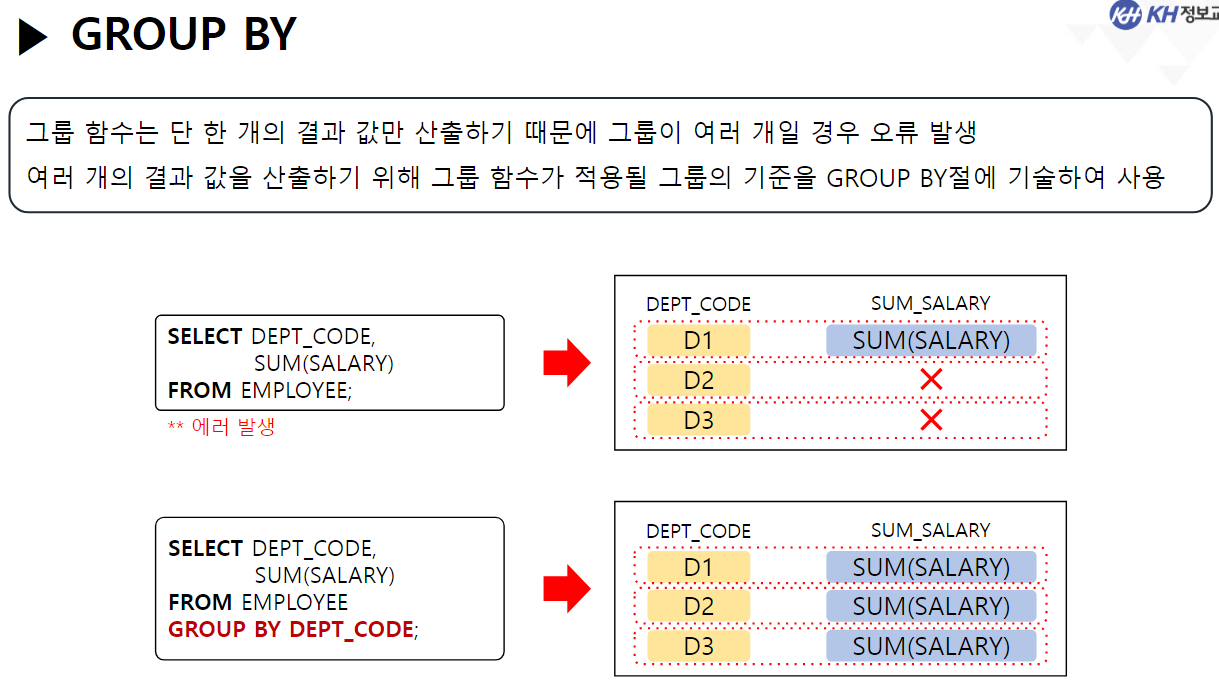


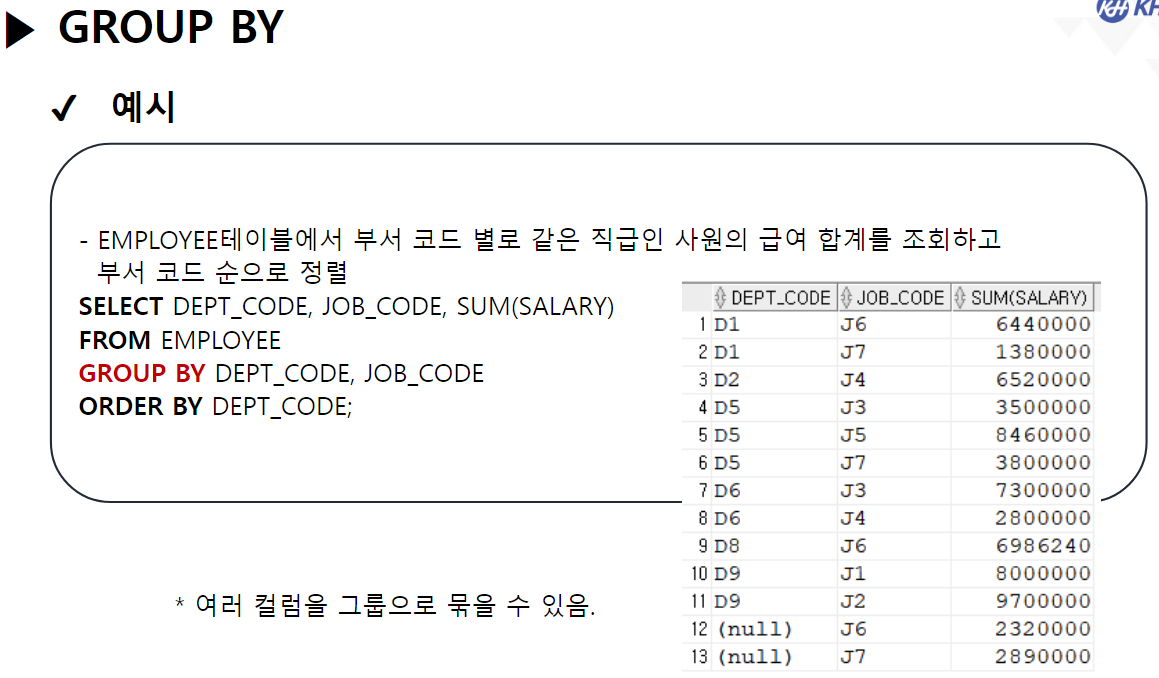
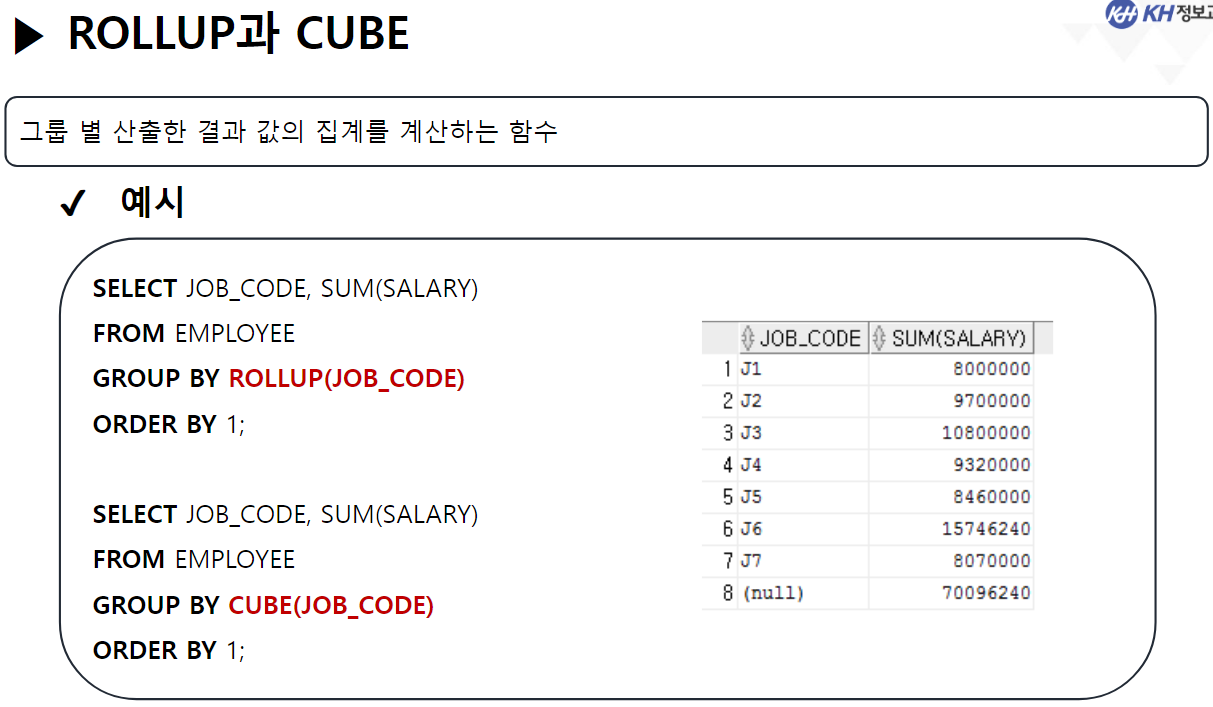
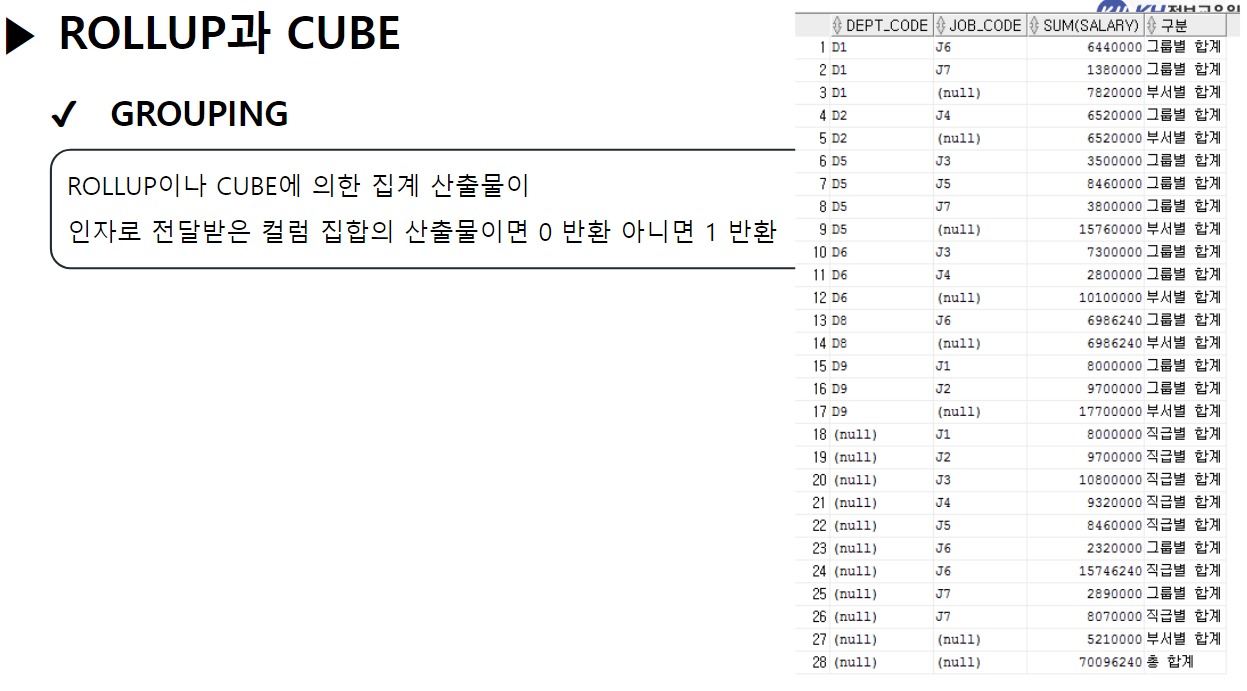
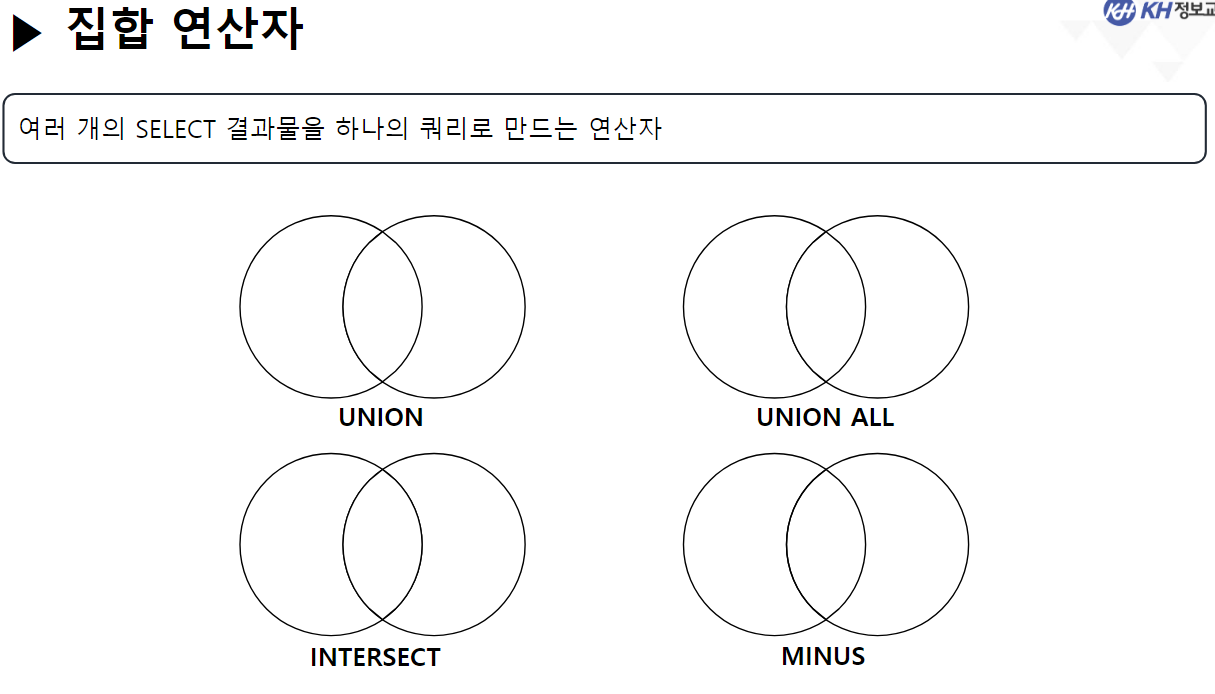
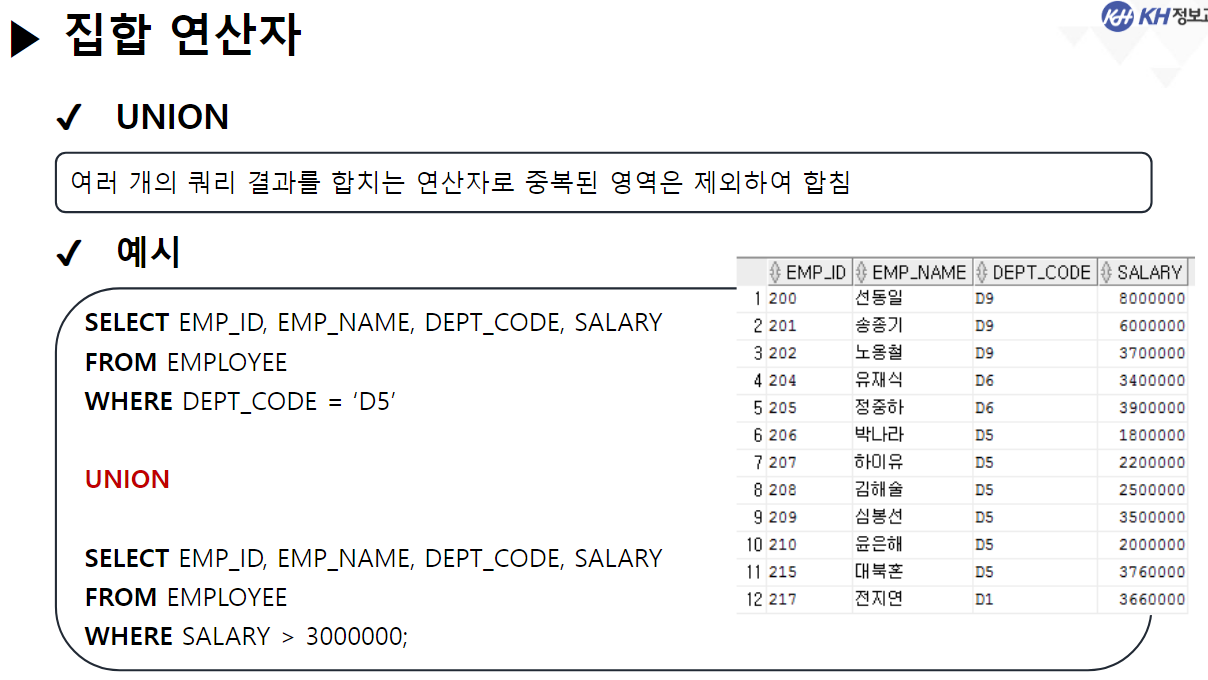
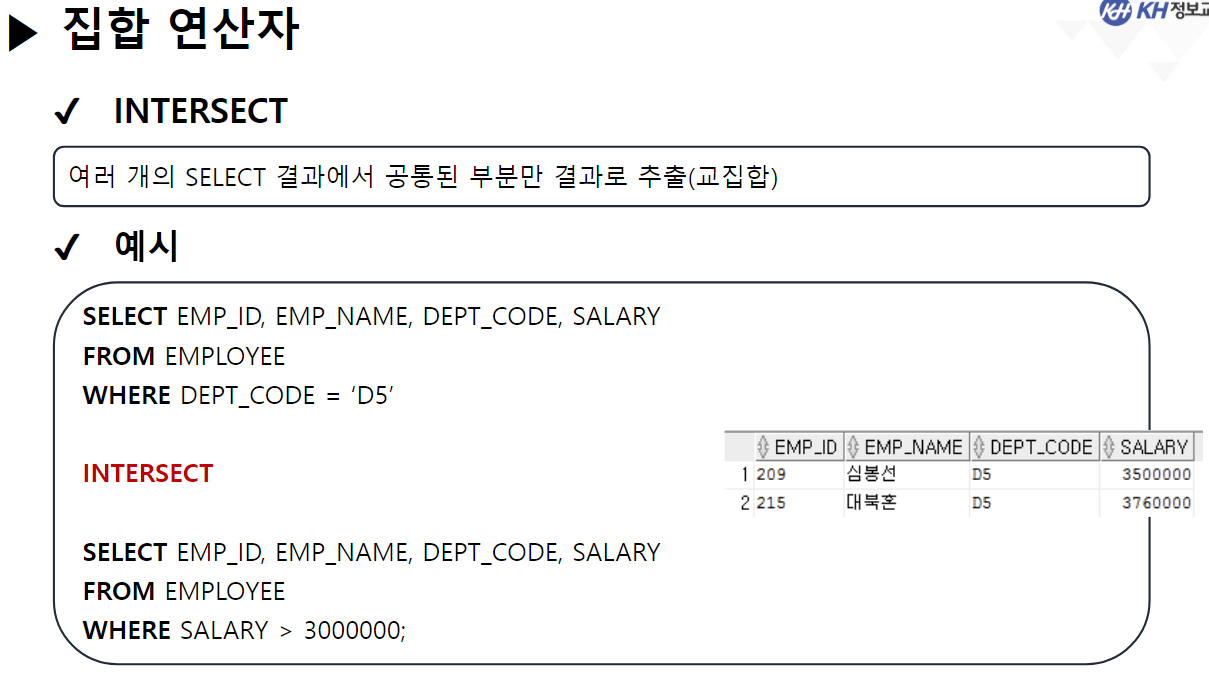
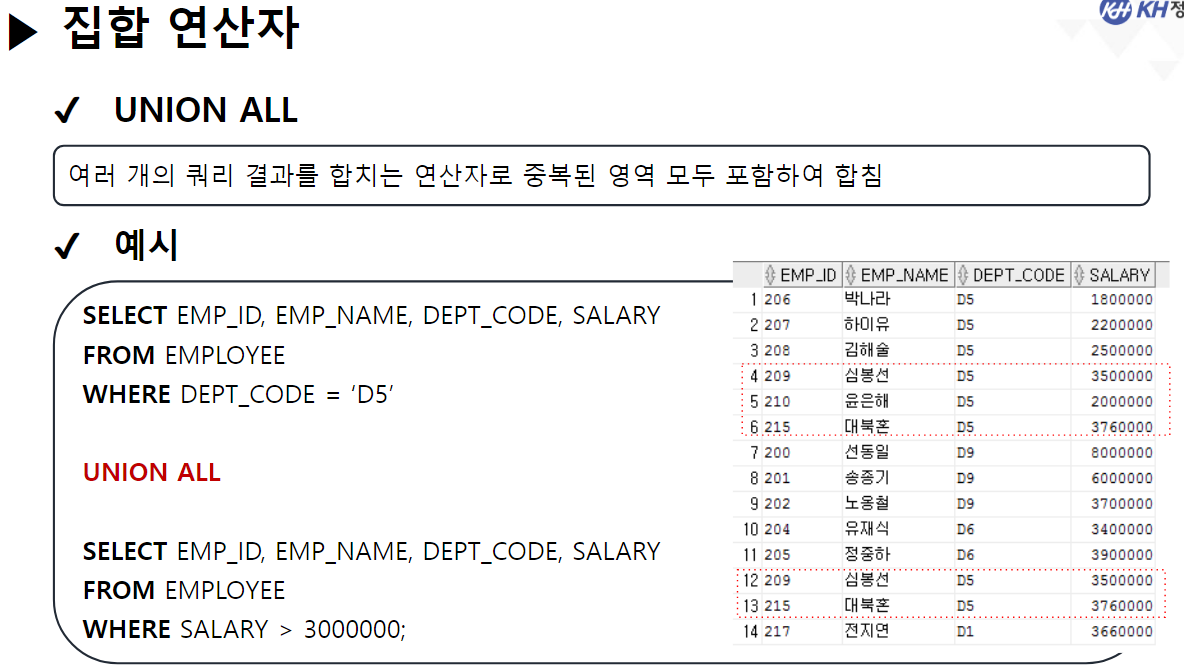
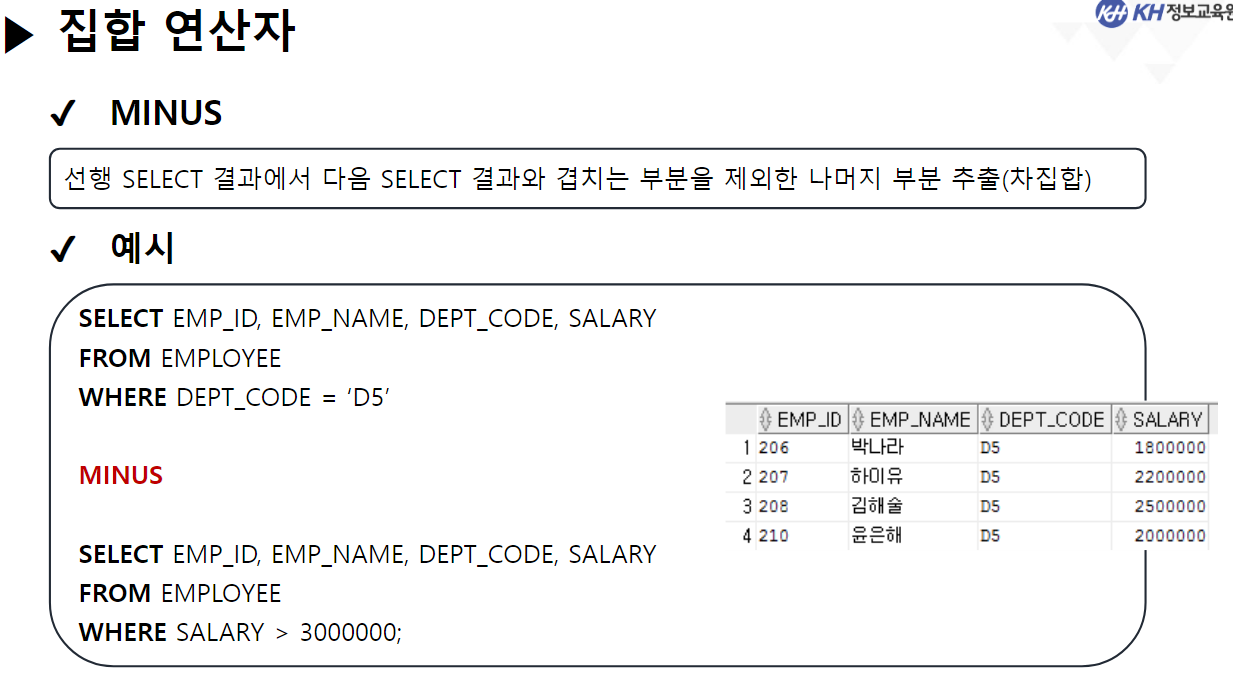
/* SELECT 문 해석순서 * * 5 : SELECT 컬럼명 AS 별칭, 계산식, 함수식 * 1 : FROM 참조할 테이블명 * 2 : WHERE 컬럼명 | 함수식 비교연산자 비교값 * 3 : GROUP BY 그룹을 묶을 컬럼명 * 4 : HAVING 그룹함수식 비교연산자 비교값 * 6 : ORDER BY 컬럼명 | 별칭 | 컬럼순번 정렬방식 [NULLS FIRST | LAST]; * */ ------------------------------------------------------------------------------------- -- GROUP BY 절 : 같은 값들이 여러개 기록된 컬럼을 가지고 -- 같은 값들을 하나의 그룹으로 묶음 -- GROUP BY 컬럼명 | 함수식, ... -- 여러개의 값을 묶어서 하나로 처리할 목적으로 사용함 -- 그룹으로 묶은 값에 대해서 SELECT절에서 그룹함수를 사용함 -- 그룹 함수는 단 한개의 결과값만 산출하기 때문에 -- 그룹이 여러개일 경우 오류 발생 -- EMPLOYEE 테이블에서 부서코드, 부서별 급여 합 조회 -- 1) 부서코드만 조회 SELECT DEPT_CODE FROM EMPLOYEE; -- 23행 -- 2) 전체 급여 합 조회 SELECT SUM(SALARY) FROM EMPLOYEE; -- 1행 SELECT DEPT_CODE, SUM(SALARY) -- 5 FROM EMPLOYEE -- 1 GROUP BY DEPT_CODE; -- 3 --> DEPT_CODE가 같은 행끼리 하나의 그룹이 됨 -- SQL Error [937] [42000]: ORA-00937: 단일 그룹의 그룹 함수가 아닙니다 -- EMPLOYEE 테이블에서 -- 직급코드가 같은 사람의 직급코드, 급여 평균, 인원수를 -- 직급코드 오름 차순으로 조회 SELECT JOB_CODE, ROUND(AVG(SALARY)), COUNT(*) FROM EMPLOYEE GROUP BY JOB_CODE ORDER BY JOB_CODE; -- EMPLOYEE 테이블에서 -- 성별(남/여)와 각 성별 별 인원수, 급여합을 -- 인원수 오름 차순으로 조회 SELECT DECODE ( SUBSTR(EMP_NO, 8, 1), '1', '남', '2', '여' ) 성별, COUNT(*) "인원 수", SUM(SALARY) "급여 합" FROM EMPLOYEE GROUP BY DECODE ( SUBSTR(EMP_NO, 8, 1), '1', '남', '2', '여' ) -- 별칭 사용 X (SELECT절 해석 x) ORDER BY "인원 수 "; -- 별칭 사용 O (SELECT절 해석 완료) -------------------------------------------------------------------------------------- -- * WHERE절 GROUP BY절을 혼합하여 사용 --> WHERE절은 각 컬럼에 대한 조건 /* SELECT 문 해석순서 * * 5 : SELECT 컬럼명 AS 별칭, 계산식, 함수식 * 1 : FROM 참조할 테이블명 * 2 : WHERE 컬럼명 | 함수식 비교연산자 비교값 * 3 : GROUP BY 그룹을 묶을 컬럼명 * 4 : HAVING 그룹함수식 비교연산자 비교값 * 6 : ORDER BY 컬럼명 | 별칭 | 컬럼순번 정렬방식 [NULLS FIRST | LAST]; * */ -- EMPLOYEE 테이블에서 부서코드가 D5, D6인 부서의 부서별 평균 급여, 인원 수 조회 SELECT DEPT_CODE, ROUND(AVG(SALARY)), COUNT(*) FROM EMPLOYEE WHERE DEPT_CODE IN ('D5', 'D6') GROUP BY DEPT_CODE; -- EMPLOYEE 테이블에서 직급별 2000년도 이후(2000년 포함) 입사자들의 급여합을 조회 -- (직급코드 오름차순) -- 내 풀이 SELECT JOB_CODE, SUM(SALARY) FROM EMPLOYEE WHERE EXTRACT(YEAR FROM HIRE_DATE) >= 2000 GROUP BY JOB_CODE ORDER BY JOB_CODE; -- 강사님 풀이 SELECT JOB_CODE, SUM(SALARY) FROM EMPLOYEE WHERE HIRE_DATE >= TO_DATE('2000-01-01') GROUP BY JOB CODE ORDER BY 1; -- 왜 오류..? ------------------------------------------------------------------------------------------------------- -- * 여러 컬럼을 묶어서 그룹으로 지정 가능 --> 그룹내 그룹 -- EMPLOYEE 테이블에서 부서별로 같은 직급인 사원의 수를 조회 SELECT DEPT_CODE, JOB_CODE, COUNT(*) FROM EMPLOYEE GROUP BY DEPT_CODE, JOB_CODE -- DEPT_CODE로 그룹을 나누고, -- 나눠진 그룹내에서 JOB_CODE로 또 그룹을 분류 --> 세분화 ORDER BY DEPT_CODE, JOB_CODE DESC; -- *** GROUP BY 사용 시 주의사항 *** -- SELECT문에 GROUP BY절을 사용할 경우 -- SELECT절에 명시한 조회하려는 컬럼 중 -- 그룹함수가 적용되지 않은 컬럼을 -- 모두 GROUP BY절에 작성해야함. ------------------------------------------------------------------------------ -- * HAVING 절 : 그룹 함수로 구해 올 그룹에 대한 조건을 설정할 때 사용 -- HAVING 컬럼명 | 함수식 비교연산자 비교값 -- 부서별 평균 급여가 3백만원 이상인 부서를 조회 SELECT DEPT_CODE, AVG(SALARY) FROM EMPLOYEE --WHERE SALARY >= 3000000 --> 한사람의 급여가 3백만 이상이라는 조건 GROUP BY DEPT_CODE HAVING AVG(SALARY) >= 3000000 --> DEPT_CODE 그룹 중 급여 평균이 3백만 이상인 그룹만 조회 ORDER BY DEPT_CODE; -- EMPLOYEE 테이블에서 직급별 인원수가 5명 이하인 직급코드, 인원수 조회(직급코드 오름차순) SELECT JOB_CODE, COUNT(*) FROM EMPLOYEE GROUP BY JOB_CODE HAVING COUNT(*) <= 5 ORDER BY 1; ------------------------------------------------------------------------------------------------------ -- 집계 함수(ROLLUP, CUBE) -- 그룹 별 산출 결과 값의 집계를 계산하는 함수 -- (그룹별로 중간 집계 결과를 추가) -- GROUP BY 절에서만 사용할 수 있는 함수! -- ROLLUP : GROUP BY절에서 가장 먼저 작성된 컬럼의 중간 집계를 처리하는 함수 SELECT DEPT_CODE, JOB_CODE, COUNT(*) FROM EMPLOYEE GROUP BY ROLLUP(DEPT_CODE, JOB_CODE) ORDER BY 1; -- CUBE : GROUP BY 절에 작성된 모든 컬럼의 중간 집계를 처리하는 함수 SELECT DEPT_CODE, JOB_CODE, COUNT(*) FROM EMPLOYEE GROUP BY CUBE(DEPT_CODE, JOB_CODE) ORDER BY 1; ----------------------------------------------------------------------------------------------------- /* SET OPERATOR(집합 연산자) * * -- 여러 SELECT의 결과(RESULT SET)를 하나의 결과로 만드는 연산자 * * - UNION(합집합) : 두 SELECT 결과를 하나로 합침 * 단, 중복은 한번만 작성 * * - INTERSECT(교집합) : 두 SELECT 결과 중 중복되는 부분만 조회 * * - UNION ALL : UNION + INTERSECT : 합집합에서 중복 부분 제거 X * * - MINUS (차집합) : A에서 A,B 교집합 부분을 제거하고 조회 * */ -- 부서코드가 'D5'인 사원의 사번, 이름, 부서코드, 급여 조회 SELECT EMP_ID, EMP_NAME, DEPT_CODE, SALARY FROM EMPLOYEE WHERE DEPT_CODE = 'D5' --UNION --UNION ALL --INTERSECT MINUS -- 급여가 300만 초과인 사원의 사번, 이름, 부서코드, 급여 조회 SELECT EMP_ID, EMP_NAME, DEPT_CODE, SALARY FROM EMPLOYEE WHERE SALARY > 3000000; -- (주의사항 !) 집합 연산자를 사용하기 위한 SELECT문들은 -- 조회하는 컬럼의 타입, 개수가 모두 동일해야 한다! SELECT EMP_ID, EMP_NAME, DEPT_CODE, SALARY FROM EMPLOYEE WHERE DEPT_CODE = 'D5' UNION SELECT EMP_ID, EMP_NAME, DEPT_CODE, SALARY FROM EMPLOYEE WHERE SALARY > 3000000; -- 서로 다른 테이블이지만 컬럼의 타입, 개수만 일치하면 집합연산자 사용 가능! SELECT EMP_ID, EMP_NAME FROM EMPLOYEE UNION SELECT DEPT_ID, DEPT_TITLE FROM DEPARTMENT;