이번에 다룰 내용은 제 2고지의 일부분이다.
원래 제 2고지를 한번에 리뷰하려고 했는데 그러자니 내용이 너무 많아서 한번 끊고 코드를 리뷰하고 나머지를 리뷰하려고 한다.
제 2고지는 자연스러운 코드로라는 제목을 가지고 있는데 이는 크게 가변 길이 인수를 처리하는 법,복잡한 계산그래프를 역전파하는 법 메모리 개선 및 기타 사용성 개선이다.
이번에는 그 중 가변 길이 인수 처리, 복잡한 계산 그래프 처리에 대해서 다룬다.
이전 글과 마찬가지로 Variabl클래스와 Function클래스 두개가 있으며 각각에 대해서 리뷰하겠다.
다만 순서를 전과 다르게 Function 부터 리뷰한다.
그 이유는 이번 파트의 내용인 가변 길이 인수 처리와 복잡한 함수 미분은 모두 함수부분에서 내용을 바꾸고 그에 맞춰 Variable의 구현을 수정하는 식이기 때문이다.
그에 앞서 사용한 모듈에 대해서 잠깐 설명하자면 heapq와 weakref라는 python 표준 라이브러리가 사용되었는데 이는 사용된 파트에서 사용 목적과 함께 설명하겠다.
import numpy as np
import heapq
import weakrefFunction Class
def as_array(x):
if np.isscalar(x):
return np.array(x)
return x
class Function:
def __call__(self,*inputs): #가변 인자로 처리한다. *을 붙이면 가변 인자들이 tuple형태로 저장된다.
xs = [x.data for x in inputs]
ys = self.forward(*xs) #forward 부분에서 unpack : 입력이 [x0,x1] -> x0,x1으로 각각 입력하도록 만든다
if not isinstance(ys,tuple): #tuple이 아닌 경우 tuple로 만들어준다.
ys = (ys,)
outputs = [Variable(as_array(y)) for y in ys]
self.generation = max([x.generation for x in inputs])# inputs generation들 중 최대 값을 generation으로 지정
for output in outputs:
output.set_creator(self)
self.inputs = inputs
#self.outputs = outputs
self.outputs = [weakref.ref(output) for output in outputs]
#약한 참조를 이용하여 순환 참조를 막아준다
#output과 creator간의 이중 참조구조를 막아주는 것
return outputs if len(outputs) > 1 else outputs[0] #원소가 하나라면 굳이 리스트 형태가 아닌 한개의 원소로 반환
def __lt__(self,other):
if self.generation >= other.generation: #오름차순
return True
else:
return False
def forward(self,xs):
raise NotImplementedError()
def backward(self,gys):
raise NotImplementedError()
class Add(Function):
def forward(self,x0,x1):
y= x0 + x1
return y
def backward(self,gy):
return gy,gy #더하기 연산상 global grad 그대로 전달
def add(x0,x1): #편하게 함수화
return Add()(x0,x1)
class Square(Function):
def forward(self,x):
y = x**2
return y
def backward(self,gy):
x = self.inputs[0].data #일변수 함수이므로 inputs의 첫번째 원소로 x를 지정
gx = 2*x*gy
return gx
def square(x):
return Square()(x)
1.def call(self,*inputs) :
파이썬을 조금 관심있게 사용해본 사람이라면 사실 함수의 가변 길이 인자를 활용하는 법은 알 것이다.
인자에 *를 붙이면 가변 길이의 인자를 tuple 형태로 묶어서 함수 내에서 사용할 수 있다.
위 경우 inputs가 함수 내에서 가변 길이 인자를 원소로 가지는 tuple이 된다.
따라서 필자는 이 tuple을 사용해 가변 길이 인자를 리스트로 만들어 사용한다.
xs = [x.data for x in inputs] 와 같이 list comprehension으로 input들을 리스트 xs에 저장한다.
그리고 이 리스트를 forward 함수에 흘려보내서 ys라는 결과를 얻는다.
이때 인자를 unpack해서 넣고 나온 ys라는 결과를 Variable 객체 리스트로 만들어서 outputs로 지정한다.
그리고 generation 변수가 추가되는데 이 변수는 함수의 위계를 나타내기 위한 변수이다. 이것이 필요한 이유를 아래 계산 그래프를 통해 보자.
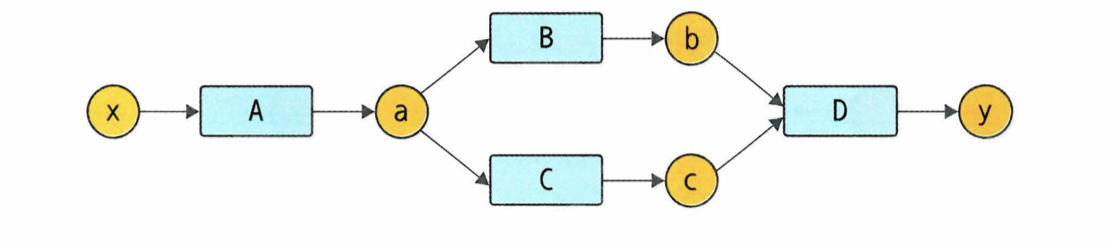
위 그래프를 역전파할 때 dA를 구하기 위해서는 dB,dC의 grad를 모두 구하고 더한 값을 흘려보내야한다.
따라서 역전파 연산 순서가 D->B,C->A순이어야 한다.
그런데 기존에 구현한 코드는 상위 함수를 리스트에 우선 순위 없이 더하고 마지막 원소부터 pop하므로(일종의 stack구조)연산 순서가
D->B->A->C->A 또는 D->C->A->B->A가 된다.
이렇게 복잡한 연산을 위해서는 앞으로 함수별 계산의 위계가 필요하다는 것이다. 이를 위해 함수와 변수에 generation 변수를 부여한다.
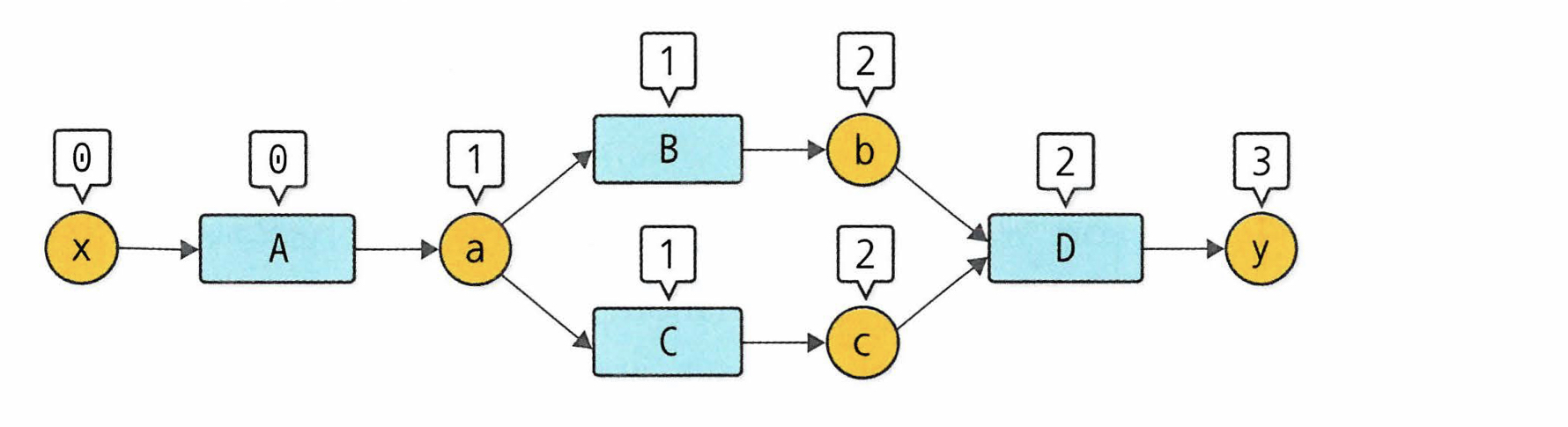
위처럼 generation은 0부터 시작해서 단계별로 높여가는 구조이다.
0부터 시작하고 변수에 대한 함수에 같은 generation을 부여한다
가령 a=A(x) 라면 A는 x의 generation을 따라가고 a는 A+1이다.
만약 다변수 함수라면, 변수 중 가장 높은 세대를 부여한다.
그 이후로는 inputs와 outputs를 지정하고 inputs에게 각각 creator를 설정한다. 그리고 outputs 원소가 하나라면 리스트로 반환할 필요가 없으므로 [0]으로 반환한다.
2.Add&Square :
이전과 같이 더하기, 제곱 연산을 수행하는 내용을 forward에 구현하고 이에 대한 미분을 backward에 구현한다.
x0+x1 연산은 각 변수에 대한 편미분값이 1이므로 gy를 2개(x0,x1각각) 반환하고 square은 를 반환한다
3.__lt__:
이 부분은 Function Class의 연산자를 오버로딩하는 것인데 왜 이부분이 필요한지는 Variable Class에서 설명한다.
Variable Class
여기서부터 앞서 구현한 Function Class를 이용하여 역전파를 구현하기 위해 Variable Class를 어떻게 바꿨는지 알아보자
class Variable():
def __init__(self,data):
self.data = data
if data is not None:
if not isinstance(data,np.ndarray):
raise TypeError(f"{type(data)}는 지원하지 않습니다.")
self.grad = None
self.creator = None
self.generation = 0 # 세대를 기록하는 변수
def set_creator(self,func):
self.creator = func #부모를 설정할 때 세대가 하나 증가하는 것이므로 1을 더한다
self.generation = func.generation + 1
def backward(self):
if self.grad is None:
self.grad = np.ones_like(self.data)
funcs = [] #함수 리스트들
seen_set = set() #이미 본 함수인지를 확인하는 집합
def add_func(f): #중첩 함수로 사용해서 함수를 더한다
if f not in seen_set: #집합에 없다면
heapq.heappush(funcs,f)
seen_set.add(f)
add_func(self.creator)
while funcs:
f = heapq.heappop(funcs)
gys = [output().grad for output in f.outputs] #output grads를 list로 저장
#weakref로 참조시 이렇게 ()선언해야지 원하는 값이 output이 나온다
gxs = f.backward(*gys) #리스트를 unpack해서 집어넣음
if not isinstance(gxs,tuple): #
gxs = (gxs,)
for x,gx in zip(f.inputs,gxs):
if x.grad is None: #grad가 없으면 값을 입히고
x.grad = gx
else: #grad가 있는 경우에는 거기에 값을 덮어 씌운다. 이렇게하면 하나의 변수에서 여러개의 grad 고려가능
x.grad =x.grad + gx
#x.grad +=gx #이렇게 연산하면 다르게 나온다 왜??
if x.creator is not None:
add_func(x.creator) #func.append에서 우선순위에 맞게 넣도록 add_func사용
def cleargrad(self):
self.grad = None
1.init:
Function class에서 언급했듯 함수 뿐 아니라 변수도 generation이 필요하므로 클래스 변수에 추가한다.
2.set_creator:
set_creator의 역할은 해당 변수의 부모 함수를 저장하는 역할이다. generation을 구현하기 위해서 이 과정에서 변수의 generation을 부모함수의 generation + 1로 할당한다.
3.backward:
backward에서 구현해야하는 핵심적인 문제는
첫 번째, generation 위계에 맞춰서 역전파가 이루어지도록 한다.
두 번째, 하나의 변수에게 오는 여러개의 global grad를 처리한다.
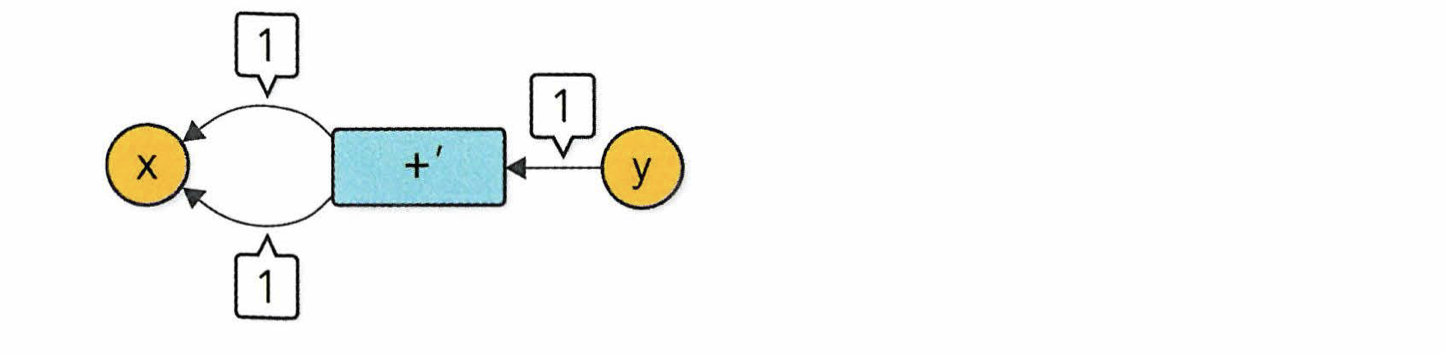
두 번째는 위 처럼 x+x연산을 미분할 때, 1과 1이 흘러오는 global grad인데 이를 x에 더하는 식으로 구현해야 한다는 말이다.
첫 번째를 구현하기 위해서 seen_set 집합과 add_func(f)함수를 활용한다. add_func()함수는 이전에 단지 funcs리스트에 append를 하는 것이 아닌 함수를 추가하면서 generation을 기준으로 정렬된 funcs를 만드는 역할을 한다.
seen_set은이미 연산된 함수는 funcs리스트에 추가하지 않도록 하는 역할을 한다. 이게 없다면 아래 그림에서 B,C의 creator인 A의 역전파가 두 번 발생한다.
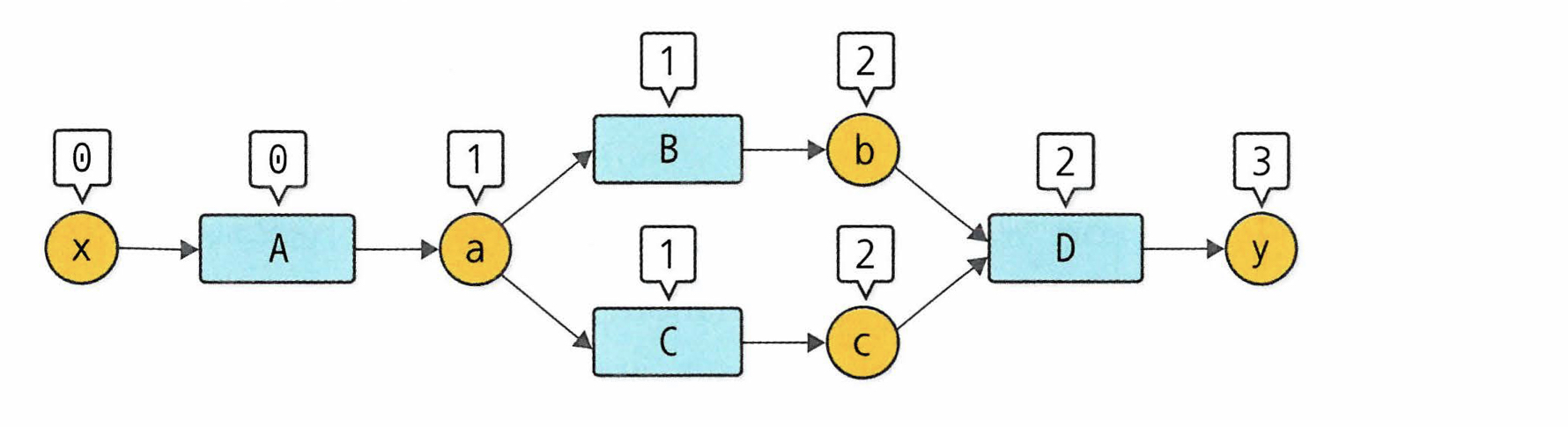
교재에서는 add_func함수를 아래와 같이 구현한다.
def add_func(f): #중첩 함수로 사용해서 함수를 더한다
if f not in seen_set: #집합에 없다면
funcs.append(f) #함수를 추가하고
seen_set.add(f) #집합에도 추가한다 -> 중첩 미분을 막음
funcs.sort(key = lambda x:x.generation) #generation에 따라 정렬
add_func(self.creator)직관적으로 리스트에 함수를 append하고 리스트 내 함수들의 generation을 기준으로 정렬한다. 하지만 generation이 큰 함수를 리스트에서 꺼내기 위해 수많은 함수들에 대해서 하나하나 추가하고 정렬하는 과정은 비효율적이고 시간이 오래 걸린다.
이때 우선 순위 큐를 활용하면 보다 효율적이고 빠르므로 나는 python의 heapq를 사용했다.
다만 heapq는 sort 메소드처럼 key를 지원하지 않는다. 즉 비교연산을 통해서 우선순위를 계산하는데 리스트에 넣을 Function 객체는 객체이므로 비교가 안된다.
이를 위해서 앞서 언급한 Function Class의 비교 연산자(__lt__)를 오버로딩한다.
def __lt__(self,other):
if self.generation >= other.generation:
return True
else:
return False위의 코드를 통해 우리는 Function 객체를 직접 대소비교할 수 있으며 이것의 기준은 객체의 generation이 된다. 추가로 generation이 같은 경우는 연산 순서와 상관 없으므로 신경쓰지 않는다.
이로써 우리는 함수 리스트를 generation을 기준으로 넣고 뽑을 수 있다.
이제 while funcs 내부를 보자. heapq를 사용하고 있으므로 heapq.pop()메소드로 함수를 가져오며 이 함수의 output에 대한 grad를 리스트 gys로 저장한다. 여기서 앞선 언급한 backward에서 구현해야하는 두 번째 요소를 구현한다. 여러 방향에서 오는 global grad를 리스트로 저장한다. 그리고 함수의 backward에 통과시켜서 grad를 gxs로 저장한다. 이 gxs는 f.inputs리스트의 변수 객체와 상응한다.
가령 y=f(a,b)함수가 있다면 f의 inputs는 (a,b)이며 gxs는 (ga,gb)로 각각 변수와 그에 대한 grad로 쌍을 이룬다.
이를 이용해 f.inputs,gx를 zip으로 묶어 반복문을 돌리고 결과적으로 함수의 input에게 그에 대한 gx를 grad를 전달한다.
이때 x.grad가 없으면 당연히 gx를 할당하고 이미 x.grad가 있다면 할당하는게 아닌 거기에 값을 더하도록 구현해서 두 번째 문제를 해결한다. 그리고 creator가 있다면 add_func으로 추가한다.
이때 재밌는 점을 grad를 더할 때 아래 두 코드의 결과가 다르다는 것이다.
x.grad =x.grad + gx
x.grad +=gx 파이썬은 두 번째 줄과 같이 할당연산자를 지원하며 기본 연산 후 할당의 축약형이라고 알려져도 있는데 내부 구현이 달라서 결과적으로 값이 달라진다.
이는 다음 글에서 다룰 메모리 효율화와 연결지점이 있으므로 다음글에서 다뤄보겠다.
4.cleargrad:
마지막 cleargrad는 같은 변수를 이용해서 연산을 다시 하는 경우에 grad값을 다시 None으로 만들어준다.
마무리
지금까지 2장의 절반이 조금 넘는 내용을 리뷰했다. 역시 책을 따라서 하나하나 구현하는게 전반적인 이해에 도움이 되는 것 같다.
다음 글에서는 메모리 효율화를 위해 weak_ref를 이용하는 방법과 할당연산자가 왜 다른결과를 내는지에 대해서 다뤄보겠다.
