300만 건의 아티클 데이터에서 조회 성능 개선하기
우리 봄봄 서비스에 정말 많은 MAU를 확보했다는 행복한 상상을 하며, 정말 많은 아티클 데이터가 쌓이는 상황에서의 성능 개선을 진행해보았다.
쿼리 튜닝이란?
Query optimization is a feature of many relational database management systems and other databases such as NoSQL and graph databases. The query optimizer attempts to determine the most efficient way to execute a given query by considering the possible query plans.
쿼리 최적화(Query Optimization)는 많은 관계형 데이터베이스 관리 시스템(RDBMS)뿐 아니라 NoSQL이나 그래프 데이터베이스 같은 다른 데이터베이스에서도 제공되는 기능입니다.
쿼리 옵티마이저(Query Optimizer)는 주어진 쿼리를 실행하는 여러 가능한 실행 계획(Query Plan)을 고려하여, 그중 가장 효율적인 방법으로 쿼리를 수행하는 방식을 결정하려고 시도합니다.
위는 wikipedia에서 말하는 Query Optimization의 의미이다. 간단하게는, 쿼리 튜닝은 데이터베이스 쿼리 실행 계획을 분석하고 불필요한 작업을 줄여 응답 시간을 최소화 하는 과정이다.
어떻게 쿼리 튜닝을 할까?
나도 처음 쿼리 튜닝이라는 단어를 들었을 땐 단순히 SQL문 구조를 변경해서 절의 실행 순서를 조정하는 것이라고 생각했다. 하지만 생각보다 쿼리 튜닝의 의미는 매우 넓었다. 쿼리가 수행 되는 과정 자체를 개선하는 작업이기 때문에 SQL문 수정 외에도 다양한 방법들이 있다.
- SQL문 최적화
- 인덱스 활용
- 데이터 아키텍처 수정
- 캐싱 활용
이 외에도 다양한 방법이 있고, 각 카테고리별로도 솔루션이 세분화 되는데 만약 MySQL을 사용한다면 MySQL 최적화 공식 문서를 읽어봐도 좋을 듯 하다.
언제 쿼리 튜닝을 해야할까?
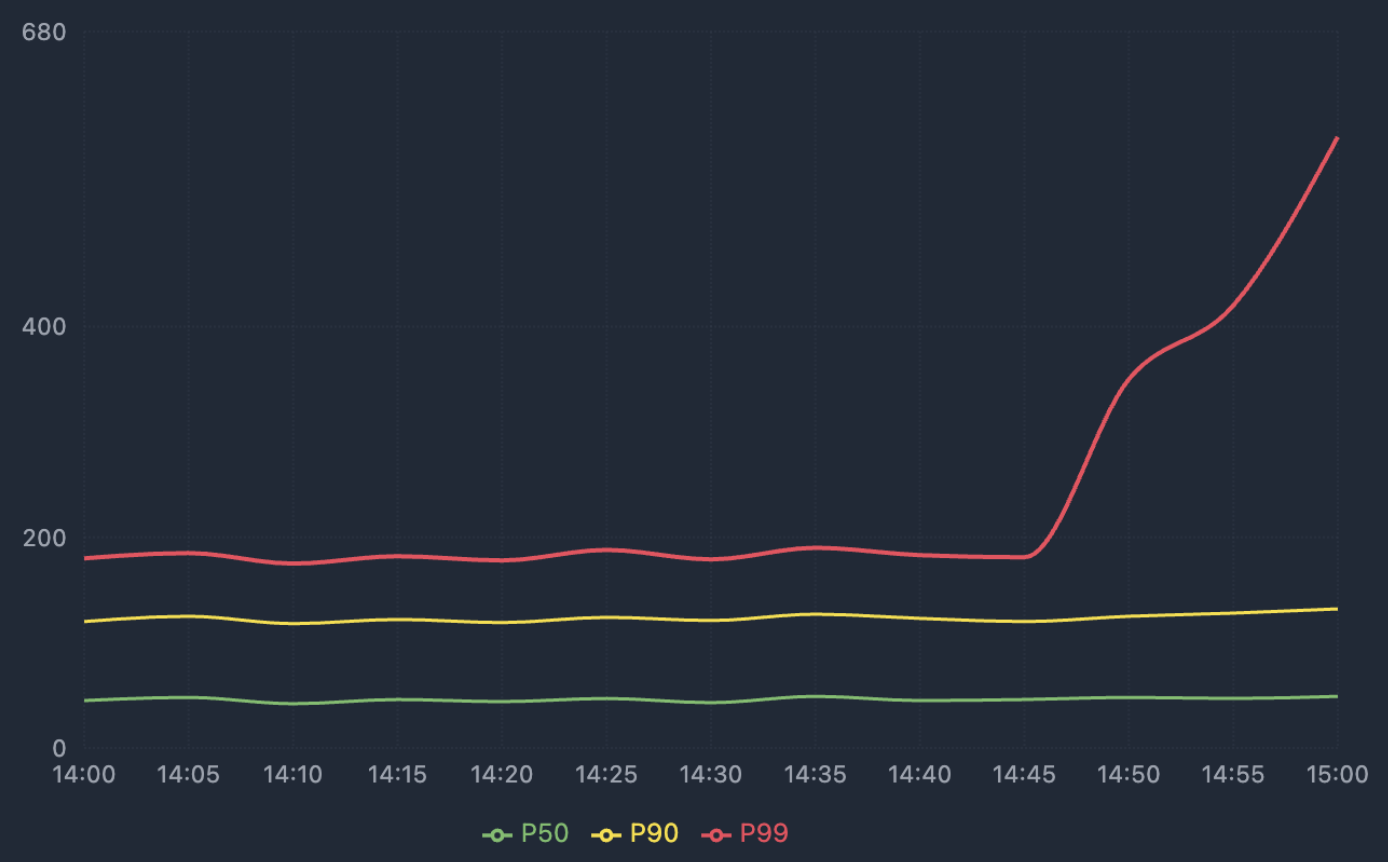
아래는 실제 봄봄 서비스에서 부하 테스트 했을 때 Grafana로 관측했던 p99 그래프이다.
 위처럼 모니터링에서 p99 값의 두드러진 급증이 나타날 경우, 쿼리 튜닝이 필요한 신호로 이해할 수 있다.
위처럼 모니터링에서 p99 값의 두드러진 급증이 나타날 경우, 쿼리 튜닝이 필요한 신호로 이해할 수 있다.
❓ p99란?
p99란 전체 요청 중 가장 느린 상위 1% 요청의 응답 시간을 의미한다.
p99 값이 높다는 것은, 대부분의 요청이 빠르지만 일부 요청이 매우 느리다는 것이다.
기존의 평균 응답 시간으로 판단하면 평균의 함정으로 인해 감지되지 않는 병목이나 쿼리 이상 징후를 판단하기가 어렵다.
그래서 p99를 측정해 평균 값으로는 감지할 수 없던 응답의 병목 현상 및 이상 징후를 확인할 수 있다.
p99가 갑자기 치솟는다는 건, 특정 시점부터 일부 요청이 비정상적으로 오래 걸리기 시작했다는 신호이기도 하다. 따라서, 평균 지연 시간보다 이러한 p99 수치를 주기적으로 관찰하면 쿼리 튜닝이 필요한 API를 알아낼 수 있다.
봄봄에서는 조회 비율이 가장 높은 핵심 도메인 Article 에 대해 데이터를 쌓고 쿼리 튜닝을 해보고자 한다.
CREATE TABLE article (
id BIGINT NOT NULL AUTO_INCREMENT PRIMARY KEY,
title VARCHAR(255) NOT NULL,
contents MEDIUMTEXT NOT NULL,
member_id BIGINT NOT NULL,
arrived_date_time DATETIME NOT NULL,
...
);나는 위에서 소개한 4개의 방법들 중 인덱스를 활용해 두 가지 시나리오에 대해 개선했다.
❓ 인덱스란?
특정 컬럼의 데이터들을 정렬해 데이터베이스 테이블에 대한 검색 속도를 향상시켜주는 자료구조이다.
※ 아래에서 사용한 RDBMS는 MySQL 8.0 (InnoDB) 기준이다.
첫 번째 시나리오
1. 요구사항
회원에게 오늘 온 아티클 목록을 최신순으로 보여주려 한다.
매우 간단하고도 필수적인 요구사항이다.
Article 테이블에서 member_id 조건을 걸고 arrived_date_time을 내림차순 정렬해 조회하는 쿼리이다.
SELECT *
FROM article
WHERE member_id = ?
ORDER BY arrived_date_time DESC;2. 300만건 article에 대한 실행 결과
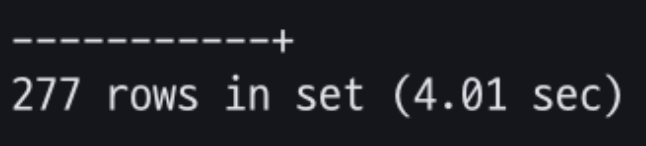 아티클 300만건에 대해 특정 member_id를 넣고 위 쿼리를 실행해보았다.
아티클 300만건에 대해 특정 member_id를 넣고 위 쿼리를 실행해보았다.
두 번째 쿼리부터 10번을 실행했을 때 평균적인 실행 결과 약 4s정도가 걸렸다.
❓첫 번째 쿼리는 왜 제외했는가?
쿼리를 처음 실행할 경우, 대상 데이터 페이지가 아직 InnoDB 버퍼 풀에 로드되지 않은 상태이다.1. 처음 실행 시 : 요청한 데이터 페이지가 InnoDB 버퍼 풀에 없다.
→ 디스크에서 페이지를 읽어 버퍼 풀에 적재한다. (Random I/O가 발생)
→ I/O 지연으로 실행 시간이 더 길어진다.
→ 이후 버퍼 풀에 캐시된 상태로 유지한다.
(데이터가 많은 테이블 기준 약 2초 더 걸렸던 것 같다.)2. 두 번째 이후 실행 시 : 동일한 데이터 페이지가 이미 버퍼 풀에 존재한다.
→ 메모리 접근만으로도 처리 가능하다.
→ Disk I/O가 없어 실행 시간이 짧아진다.첫 번째 실행 결과를 평균 계산에 포함하면 Disk I/O로 인한 왜곡이 발생한다.
따라서 2~10회에서 평균값을 사용하는 것이 더 정확한 값을 내기에 적합하다.
3. 실행 계획 파악하기
MySQL에서는 쿼리의 앞에 EXPLAIN 키워드만 붙여주면 실행 계획을 간단히 파악할 수 있다.
EXPLAIN SELECT *
FROM article
WHERE member_id = ?
ORDER BY arrived_date_time DESC;❓
EXPLAINvsEXPLAIN ANALYZE
실행계획을 파악할 수 있는 2가지 방법으로EXPLAIN과EXPLAIN ANALYZE가 있다.
EXPLAIN: DB 옵티마이저가 예상한 실행 계획을 보여준다.
EXPLAIN ANALYZE: 실제 쿼리를 실행하면서 걸린 시간과 row 수를 측정한다.이러면 당연히
EXPLAIN ANALYZE가 훨씬 정확하고 좋은 방법 아니냐 할 수 있는데,EXPLAIN ANALYZE는 실제로 쿼리를 실행하므로 실행 계획을 파악하는데EXPLAIN보다 더 오래 걸릴 수 있다.뿐 만 아니라, SELECT 쿼리는 데이터에 영향을 주지 않지만 데이터를 변경/추가/삭제 하는 쿼리에 적용할 경우 의도치않게 데이터를 조작하게 될 수 있다.
실행 계획 결과는 아래와 같다.
 실행 계획에서
실행 계획에서 type과 Extra 컬럼에 집중해보자.
1. type: ALL
type은 MySQL 옵티마이저가 InnoDB에게 어떤 방식으로 데이터를 읽어오라고 지시했는지를 나타낸다. 즉, 데이터 테이블을 읽어오는 방식을 의미한다. ALL은 가장 비용이 큰 방식으로, 전체 테이블 스캔을 의미한다.
인덱스를 활용하지 못하고 테이블의 모든 레코드를 처음부터 끝까지 읽는 상황인 것이다.
2. Extra: Using where; Using filesort
Extra 컬럼은 MySQL Executor가 메모리 버퍼풀에 있는 데이터들에 대해 수행한 추가 작업을 알려준다.
Using where
- 필터링이 인덱스가 아닌 Executor 단계에서 수행한다.
WHERE member_id = ?부분을 의미한다.
Using filesort
- ORDER BY 수행 시 메모리/디스크에 별도 정렬이 발생한다.
ORDER BY arrived_date_time DESC부분을 의미한다.
4. 개선 포인트 정리
실행 계획 내용을 통합해, 다음과 같이 문제 상황을 정의했다.
- WHERE 조건에 대해 full table scan
- ORDER BY절의 추가 정렬
full table scan을 하고 있다는 점, 그리고 ORDER BY를 위한 정렬을 직접 하고 있다는 점으로 미루어 보아, 인덱스를 사용하면 개선할 수 있을 것 같다.
그 중 Composite Index를 사용하고자 한다.
5. Composite Index로 개선하기
Composite Index(복합 인덱스)란, 두 개 이상의 컬럼을 포함하는 인덱스이다.
(a, b, c)로 복합 인덱스를 구성할 경우, a -> b -> c 순서를 기준으로 두고 정렬해 인덱스를 생성한다.
a 컬럼으로 먼저 정렬한 후 그 다음으로 b 기준 정렬, c 정렬 인 것이다.
개선할 쿼리를 보고 적절한 복합 인덱스를 구성해보자.
SELECT *
FROM article
WHERE member_id = ?
ORDER BY arrived_date_time DESC;- WHERE 조건 : member_id
- 정렬 기준 : arrived_date_time
따라서 member_id와 arrived_date_time을 복합 인덱스에 포함하면 될 것이다.
다만 복합 인덱스는 인덱스의 선행 컬럼이 중요하다. MySQL의 절 실행 순서 때문에 왼쪽부터 일치해야 인덱스를 효율적으로 사용할 수 있다.
❓ MySQL의 SQL절 실행 순서
아래와 같이 MySQL 파서는 구문을 인식하는 논리적 처리 순서가 있다.
FROM: 테이블 및 조인 대상 결정ON: 조인 조건 평가JOIN: 조인 결과 생성WHERE: 행 필터링GROUP BY: 그룹화 수행HAVING: 그룹 필터링SELECT: 필요한 컬럼 선택DISTINCT: 중복 제거ORDER BY: 정렬 수행LIMIT: 결과 행 수 제한
지금 개선할 쿼리에서는 절의 실행 순서가 WHERE -> ORDER BY 이다.
따라서 복합 인덱스를 생성할 때 member_id -> arrived_date_time 순으로 배치하는 것이 올바르다.
-- ❌ 잘못된 Composite Index : 선행 컬럼 불일치로 활용 불가
CREATE INDEX idx_article_member_arrived
ON article (arrived_date_time, member_id);
-- ✅ 올바른 Composite Index
CREATE INDEX idx_article_member_arrived
ON article (member_id, arrived_date_time);생성된 인덱스 결과는 아래 형태이다.
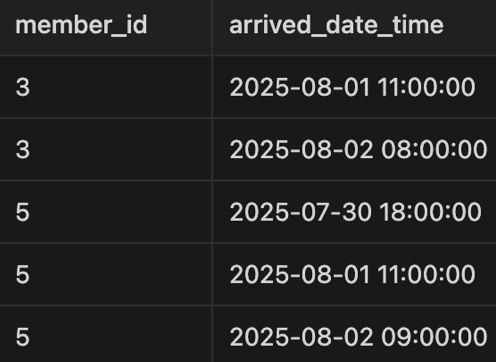
member_id로 먼저 정렬하고 arrived_date_time으로 정렬된 인덱스 모습이다.
6. 개선 후 실행 계획 파악하기
Composite Index를 생성했으니, 기존 쿼리에서 인덱스를 활용하는지 확인해야 한다.
똑같이 EXPLAIN를 붙여 실행 계획을 확인했다.

1. type: ref
기존에 ALL이었던 type이 ref로 바뀌었다.
ref는 인덱스를 사용해 특정 키 값에 매칭되는 행을 찾는 것을 의미한다.
MySQL 엔진이 idx_article_member_arrived 인덱스의 존재를 알고, InnoDB에게 이를 활용하도록 지시한다. 그래서 InnoDB가 디스크로부터 데이터를 읽어올 때, 인덱스를 이용해 필요한 레코드 위치를 찾고 해당하는 레코드들만 가져온다.
2. Extra: NULL
Extra 컬럼은 NULL인 것을 보아 MySQL Executor가 데이터들에 대해 추가 수행하는 작업이 없음을 알 수 있다.
Using where가 없어진 이유는 인덱스를 통해 이미 WHERE member_id = ?로 필터링 된 데이터만 가져왔기 때문이다.
Using filesort는 왜 없어졌나 싶을 수 있지만, 복합 인덱스의 두 번째 컬럼이 arrived_date_time이다. 즉, 필터링으로 가져온 데이터들이 arrived_date_time으로 이미 정렬 되어있는 것이다. 따라서 추가 정렬이 필요 없다.
❓ 인덱스는 ASC로 정렬되는데 DESC 정렬 쿼리에서도 활용 가능한가?
활용 가능하다.
MySQL의 InnoDB 엔진을 사용하면 인덱스는 B+Tree 구조로 생성된다.
기본적으로는 ASC 정렬된 형태이지만, 인덱스 트리는 양방향 탐색이 가능하다.
즉, 리프 노드를 뒤에서부터 읽어 DESC 정렬 효과를 그대로 낼 수 있는 것이다.
 인덱스의 적용 여부를 확인하려면
인덱스의 적용 여부를 확인하려면 key 값을 집중해야 한다.
3. key: idx_article_member_arrived
key는 MySQL 옵티마이저가 실제로 사용하기로 선택한 인덱스를 의미한다.
사용 가능한 인덱스들(possible_keys) 중에서 최종 선택한 인덱스로, 이를 사용해 InnoDB가 데이터에 접근한다.
아까 생성했던 복합 인덱스의 이름(idx_article_member_arrived)이 key로 들어간 것을 보아, 의도대로 인덱스가 잘 채택됨을 알 수 있다.
7. 개선 결과 확인하기
이번에도 동일하게 300만건 아티클 데이터에 대해 동일한 쿼리를 실행해보았다.
 기존에는 평균 약 4s 걸리던 쿼리가 Composite Index 적용 이후로는 0.01s까지 개선됨을 확인했다.
기존에는 평균 약 4s 걸리던 쿼리가 Composite Index 적용 이후로는 0.01s까지 개선됨을 확인했다.
두 번째 시나리오
1. 요구사항
회원의 아티클 목록을 제목들로만 간결하게 보여주려고 한다.
artice의 id와 title만 있으면 된다.
내 아티클 목록을 간단한 summary처럼 보여준다고 생각해보자.
SELECT id, title
FROM article
WHERE member_id = ?2. 300만건 article에 대한 실행 결과
 이번에도 300만건의 아티클에 대해 특정 member_id를 넣고 위 쿼리를 실행했다.
이번에도 300만건의 아티클에 대해 특정 member_id를 넣고 위 쿼리를 실행했다.
두 번째 쿼리부터 10번 실행 시 평균 결과 약 3.56s 걸렸다.
3. 실행 계획 파악하기
EXPLAIN 키워드를 통해 실행 계획을 파악해본다.
EXPLAIN SELECT id, title
FROM article
WHERE member_id = ?실행 계획 결과는 아래와 같았다.
 실행 계획에서 마찬가지로
실행 계획에서 마찬가지로 type과 Extra를 분석한다.
1. type: ALL
이번 쿼리도 마찬가지로 인덱스 없이 테이블의 모든 레코드를 처음부터 끝까지 읽고 있다.
2. Extra: Using where
이번에도 WHERE절에 대한 필터링을 Executor 단계에서 수행한다.
4. 개선 포인트 정리
이번 쿼리에서도 발생하는 문제점은 동일하다.
- WHERE 조건에 대한 full table scan
이 외에도 실행 계획에서는 나타나지 않는 추가적인 개선 포인트를 찾을 것이 있다.
"불필요한 컬럼들의 메모리 적재"
SELECT id, title 과정에서 필요한 필드들(id, title)은 MySQL 엔진에서만 알고있다.
그리고 InnoDB 엔진은 MySQL 엔진으로부터 어떤 "데이터 페이지"를 읽을지에 대한 정보만을 얻는다.
따라서, InnoDB 엔진은 조건에 해당하는 "데이터 페이지"를 버퍼 풀에 올리는 역할만 한다.
즉 InnoDB가 조건에 해당하는 모든 레코드를 버퍼 풀에 올려주면, MySQL 엔진은 여기서 필요한 컬럼만 골라 쓰는 것이다.
현재 article 테이블에는 컬럼 수가 14개이다. 이 중 쿼리에서 필요한 컬럼은 단 2개이다.
2개의 컬럼을 위해 나머지 12개의 컬럼은 불필요하게 메모리에 적재되는 것이다.
이 과정을 통해 최종적으로 개선해야 할 부분들은 아래와 같다.
- WHERE 조건에 대한 full table scan
- id, title 컬럼을 위해 불필요한 나머지 컬럼이 메모리에 적재된다.
개선점 2번을 미루어보아 적용하기 가장 좋은 인덱스는 Covering Index이다.
5. Covering Index로 개선하기
Covering Index(커버링 인덱스)란 쿼리를 수행할 때 필요한 모든 컬럼이 인덱스에 포함되어 있어, 데이터 페이지 접근 없이 인덱스만으로 결과를 반환할 수 있는 인덱스이다.
즉, InnoDB가 디스크 테이블의 실제 데이터를 읽지 않고 인덱스(B+Tree)만으로 쿼리를 처리할 수 있게 되는 구조이다.
일반 인덱스와 커버링 인덱스의 동작 차이는 아래와 같다.
일반 인덱스 : 인덱스 탐색 → PK 추출 → PK 사용해 데이터 페이지 접근 (모든 컬럼 로드)
커버링 인덱스 : 인덱스 탐색 → 필요 컬럼들이 인덱스에 모두 있으므로 데이터 바로 반환
즉, 커버링 인덱스는 데이터 페이지 접근이 없으므로 Disk I/O가 생략되는 것이다.
성능상으로 강력한 이점을 볼 수 있다.
❓그럼 항상 모든 컬럼을 인덱스에 포함하면 되지 않나?
Covering Index는 디스크 접근을 없애주는 강력한 효과를 갖기 때문에,
“그럼 모든 컬럼을 인덱스에 넣으면 I/O가 사라지고 쿼리 속도가 가장 빠르지 않을까?” 싶었다.하지만 인덱스도 결국 디스크에 저장되는 별도의 페이지이다.
따라서 인덱스 컬럼을 많이 포함할수록, 인덱스 페이지 자체가 커지고 무거워진다.
이는 곧 디스크 낭비로 이어질 수 있으므로, 적절한 컬럼을 선택해 포함하는 것이 중요하다.
이번 쿼리에서 적절한 커버링 인덱스를 구성해보자.
SELECT id, title
FROM article
WHERE member_id = ?- 필요한 컬럼 : id, title, member_id
필요한 3가지 컬럼을 모두 포함하는 인덱스를 아래처럼 생성했다.
이번 인덱스도 여러 개의 필드를 포함하므로, 사실상 복합 인덱스와의 교집합 인덱스이기도 하다.
따라서 이번에도 선행 컬럼 순서를 잘 고려해 생성하도록 하자.
CREATE INDEX idx_article_member_id_title
ON article (member_id, title);⁉️ id가 포함이 안되어있는데?
id는 일부로 포함하지 않았다.
이유는 InnoDB의 보조 인덱스(Secondary index) 구조 때문이다.
InnoDB의 리프 노드는 데이터 페이지의 레코드를 찾아가기 위해, 항상 PK 값을 리프 노드 말단에 함께 저장한다.
따라서 사실상 인덱스는 아래처럼 (member_id, title, id)로, PK가 포함되어 생성되는 것이나 다름없다. id가 명시적으로 인덱스에 없어도, 리프 노드에 이미 포함되어 있으므로 디스크 접근 없이도 PK 값을 얻을 수 있다.
id가 명시적으로 인덱스에 없어도, 리프 노드에 이미 포함되어 있으므로 디스크 접근 없이도 PK 값을 얻을 수 있다.
따라서 (member_id, title) 인덱스만으로도 완전한 커버링 인덱스(Covering Index) 역할을 수행한다.
❓ 인덱스에 명시적으로 PK를 포함할 때의 차이
InnoDB는 인덱스에 PK를 명시하지 않아도 자동으로 갖고 있는데,
“그렇다면 굳이 인덱스 생성에 PK를 명시할 필요가 있을까?”→ 필요하기도 하다. 목적이 다를 뿐이다.
이미 인덱스를 잘 알고 있다면 눈치 챘겠지만, 명시적으로 PK를 포함하면 PK 기준 정렬이 수행된다.
(member_id, title, id)로 인덱스를 생성하면 2번 째 컬럼(title)까지 tie-break가 발생할 경우,
마지막은 id 값을 기준으로 정렬을 수행하는 것이다.만약 tie-break에 대한 순서가 중요하고 PK를 정렬해 사용해야한다는 요구사항이 명확하면
PK도 인덱스 생성 시 포함하자.
6. 개선 후 실행 계획 파악하기
이제 쿼리가 생성한 Covering Index를 채택하는지 확인한다.
마찬가지로 EXPLAIN으로 확인한 결과는 아래와 같다.

1. type: ref
이번에도 type 값이 ref가 되었다. 인덱스로 특정 키 값에 매칭되는 행을 찾고 있다.
WHERE절의 member_id 일치 비교로 매칭되는 행을 찾는 것이다.
2. Extra: Using Index
Extra 컬럼은 Using Index라는 값이 생겼다.
데이터 테이블 접근 없이 인덱스만으로 결과 반환 가능하다는 것을 뜻한다.
커버링 인덱스 사용을 의미한다.
인덱스 적용 여부도 key 값으로 확인해보자.

3. key: idx_article_member_id_title
생성한 커버링 인덱스(idx_article_member_id_title)이 채택됨을 확인했다.
7. 개선 결과 확인하기
같은 데이터셋에 대해 동일한 쿼리를 실행했다.
 기존에는 3.56s 걸리던 쿼리가 0.00s, ms 단위까지 성능이 개선됐다.
기존에는 3.56s 걸리던 쿼리가 0.00s, ms 단위까지 성능이 개선됐다.
이번에 쿼리 성능 향상을 해보면서, 쿼리 튜닝 중 가장 간단하고도 강력한 개선 효과를 볼 수 있는 것이 인덱스라는 점을 확실히 깨달을 수 있었다.
쓰기 작업 대비 조회 수행률이 높다면 인덱스 추가는 어쩌면 당연한 작업이 아닐까 싶다.
참고
https://dev.mysql.com/doc/refman/9.0/en/optimize-overview.html
https://en.wikipedia.org/wiki/Query_optimization
