우리가 Deadlock을 겪다니 (원인 파악부터 해결까지)
우리 서비스는 뉴스레터 읽기 개수로 '이달의 랭킹'이 10분마다 갱신된다.
그런데 어느날부터 이 스케줄링에서 Deadlock 예외가 발생했다.
내부 스케줄링으로 갱신되는 랭킹 작업을 추적하기 위해 로그와 트레이스를 분석했다.
그러고나니 스케줄러 수행 시점에 prod 서버에서 데드락 error trace가 반복적으로 발생하는 것을 발견했다.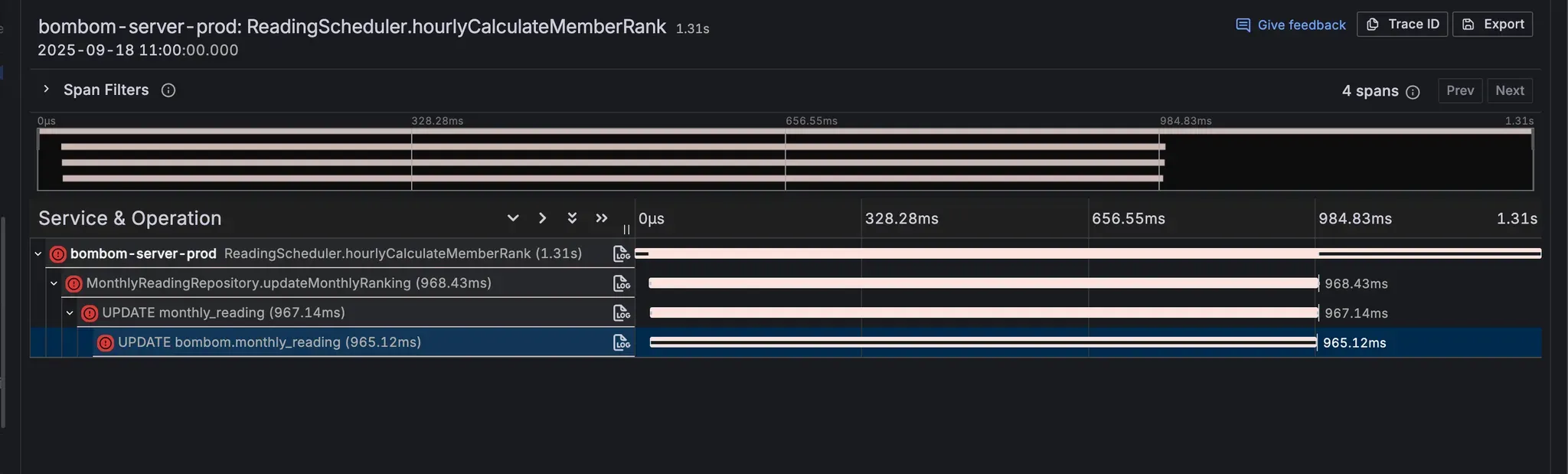 trace의 예외 로그는 다음과 같았다.
trace의 예외 로그는 다음과 같았다.
exception.stacktrace 
"org.springframework.dao.CannotAcquireLockException: JDBC exception executing SQL [
&{이달의 랭킹 업데이트 쿼리;}
] [Deadlock found when trying to get lock; try restarting transaction] [n/a]; SQL [n/a]
at org.springframework.orm.jpa.vendor.HibernateJpaDialect.convertHibernateAccessException(HibernateJpaDialect.java:287)
at org.springframework.orm.jpa.vendor.HibernateJpaDialect.convertHibernateAccessException(HibernateJpaDialect.java:256)
at org.springframework.orm.jpa.vendor.HibernateJpaDialect.translateExceptionIfPossible(HibernateJpaDialect.java:244)
at org.springframework.orm.jpa.AbstractEntityManagerFactoryBean.translateExceptionIfPossible(AbstractEntityManagerFactoryBean.java:560)
at org.springframework.dao.support.ChainedPersistenceExceptionTranslator.translateExceptionIfPossible(ChainedPersistenceExceptionTranslator.java:...)
at org.springframework.dao.support.DataAccessUtils.translateIfNecessary(DataAccessUtils.java:343)🎯 Deadlock이 발생하는 작업
서비스에서 이달의 랭킹을 10분마다 업데이트한다. 이 작업은 Spring의 @Scheduled 로 수행하고 있었다. monthly_reading 테이블에 대해 UPDATE 하는 쿼리를 실행하는 작업인데, 여기서 계속 Deadlock found when trying to get lock 에러가 발생하고 있었다.
CannotAcquireLockException이 발생한 것으로 보아, 데이터베이스 레벨에서 트랜잭션을 수행하는데 데드락이 발생한 것이다.
🤔 Deadlock이 발생하는 원인 찾기
Deadlock이란 두 개 이상의 프로세스나 스레드가 서로의 자원을 기다리며 무한히 기다리는 현상이다.
위 작업에서 Deadlock이 발생한 이유는 두 트랜잭션이 서로가 보유한 monthly_reading 락을 무한히 대기하고 있기 때문이다.
❓하나의 애플리케이션에서 두 개 이상의 스케줄러끼리 데드락이 발생할 수 있을까?
@Scheduled는 Spring에서 제공하는 스케줄링 전용 스레드 풀에서 스레드를 꺼내 사용하는데,
이 스레드 풀에 대해 추가적으로 설정한 config가 없으면 default 스레드 풀 사이즈가 1이다.즉, 단일 스레드 환경에서 스케줄러가 실행되는 것이다.
따라서 하나의 애플리케이션 안에서 스케줄러 스레드 여러 개가
monthly_reading을 점유하느라 발생한 데드락은 아닌 것이다.
데드락이 발생한 결과 정보를 얻기위해 SHOW ENGINE INNODB STATUS를 사용했다.
❓
SHOW ENGINE INNODB STATUS
SHOW ENGINE INNODB STATUS명령은 현재 InnoDB Monitor의 결과를 보여준다.
결과에는 백그라운드로 실행되는 스레드, 세마포어, 가장 최근에 발생한 FK 에러, 그리고 가장 최근에 감지된 Deadlock 등이 포함된다.실행 결과에서 한 개의 블럭은 PK 하나의 레코드에 대한 락 정보를 보여준다.
*** (1) HOLDS THE LOCK(S): RECORD LOCKS space id 65 page no 4 n bits 192 index PRIMARY of table `bombom`.`monthly_reading` trx id 351844299710552 lock mode S Record lock, heap no 56 PHYSICAL RECORD: n_fields 9; compact format; info bits 64 0: len 8; hex 8000000000000002; asc ;; 1: len 6; hex 000000000006; asc kv;; ... 7: len 5; hex 900000000c; asc l\;; 8: len 5; hex 9000000000; asc ;;
*** (1) HOLDS THE LOCK(S):하위에는 해당 트랜잭션이 얻은 모든 lock의 정보가 나타난다.
- 첫 번째 트랜잭션이 S lock을 점유한다. (lock mode S) (
LOCK(S)에 있는 S는 상관 X)- 락은 primary key에 대한 인덱스, 즉 클러스터드 PK 인덱스에 대해 lock을 점유한다.
monthly_reading테이블의 PK는 id이므로, id에 대한 인덱스이다.0: len 8; hex 8000000000000002; asc ;;
- InnoDB는 인덱스의 key 값을 0번 필드에 기록한다.
hex 8000000000000002: 0번 필드 값을 나타내므로 PK 값인 것이다.
- PK 값이 2인 인덱스임을 추측할 수 있다.
- 나머지 1 ~ 8번 까지는 해당 레코드의 다른 필드 데이터들이다.
실제 조회한 Deadlock 메타데이터를 분석해보자.
1) 첫 번째 애플리케이션의 트랜잭션
첫 번째 트랜잭션이 id = 2인 레코드에 대해 S lock을 점유하고 있다.
*** (1) HOLDS THE LOCK(S):
RECORD LOCKS space id 65 page no 4 n bits 192 index PRIMARY of table `bombom`.`monthly_reading` trx id 351844299710552 lock mode S
Record lock, heap no 56 PHYSICAL RECORD: n_fields 9; compact format; info bits 64
0: len 8; hex 8000000000000002; asc ;;
...첫 번째 트랜잭션은 id = 9인 레코드에 대해 S lock을 대기하고 있다.
*** (1) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 65 page no 4 n bits 192 index PRIMARY of table `bombom`.`monthly_reading` trx id 351844299710552 lock mode S waiting
Record lock, heap no 57 PHYSICAL RECORD: n_fields 9; compact format; info bits 64
0: len 8; hex 8000000000000009; asc ;;
...2) 두 번째 애플리케이션의 트랜잭션
두 번째 트랜잭션은 id = 9인 레코드에 대해 X record lock을 점유하고 있다.
*** (2) HOLDS THE LOCK(S):
RECORD LOCKS space id 65 page no 4 n bits 192 index PRIMARY of table `bombom`.`monthly_reading` trx id 158951 lock_mode X locks rec but not gap
Record lock, heap no 57 PHYSICAL RECORD: n_fields 9; compact format; info bits 64
0: len 8; hex 8000000000000009; asc ;;
...두 번째 트랜잭션은 id = 2인 레코드에 대해 X record lock을 대기하고 있다.
*** (2) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 65 page no 4 n bits 192 index PRIMARY of table `bombom`.`monthly_reading` trx id 158951 lock_mode X locks rec but not gap waiting
Record lock, heap no 56 PHYSICAL RECORD: n_fields 9; compact format; info bits 64
0: len 8; hex 8000000000000002; asc ;;
...T1 : S(2) holding → S(9) request
T2 : X(9) holding → X(2) request
서로의 lock을 요청하고 있었기에 deadlock이 발생하고 있었다.
🚨 그리고 중요한 단서로는 두 개의 트랜잭션 IP가 달랐다.
❓ UPDATE 쿼리에 S lock은 왜 포함되어 있을까?
쿼리에 UPDATE 대상인 테이블
monthly_reading이 조인/서브쿼리에서도 읽기용으로 참조한다.
MySQL의 의도에 따르면, UPDATE 대상 테이블이 조인/서브쿼리에서 동일하게 사용되면 읽기 과정을 위해 S lock을 점유하도록 설계되어있다고 한다.이를 따른다면 쿼리 실행에 따른 lock 점유 순서는 아래와 같을 것이다.
- 첫 번째 JOIN 서브쿼리에 대해 S lock 획득
→monthly_reading의 모든 레코드가 S lock 점유SELECT member_id, RANK() OVER (ORDER BY current_count DESC) AS calculated_rank FROM monthly_reading;
- 두 번째 LEFT JOIN 서브쿼리에 대해 S lock 획득
→monthly_reading에서 ON 조건에 맞는 레코드들이 S lock 점유SELECT DISTINCT mr1.member_id, COALESCE(MIN(mr2.current_count) - mr1.current_count, 0) AS next_diff FROM monthly_reading mr1 LEFT JOIN monthly_reading mr2 ON mr2.current_count > mr1.current_count GROUP BY mr1.member_id, mr1.current_count
- UPDATE 시점에 대상 레코드들에 대해 X lock으로 승격
→monthly_reading의 모든 레코드가 X lock으로 승격UPDATE monthly_reading mr JOIN (sub_query_1) ranks ON mr.member_id = ranks.member_id LEFT JOIN (sub_query_2) diffs ON mr.member_id = diffs.member_id SET mr.rank_order = ranks.calculated_rank, mr.next_rank_difference = diffs.next_diff;
📌 원인 결론: 분산환경으로 인한 스케줄링 중복 실행
현재 서비스는 분산 환경으로, ec2 인스턴스 2개로 운영 중이다.
따라서 두 개의 애플리케이션에서 동일한 시간에 스케줄러가 실행된다.
이 때 두 개의 스케줄러 스레드가 동시에 monthly_reading 에 대해 update를 시도한다.
그리고 이 부분이 원인임을 단정지을 수 있던 가장 명확한 근거는 두 개의 트랜잭션 IP가 달랐다는 점이다.
📝 Deadlock 해결하기
위 Deadlock을 해결하기 위해선 스케줄러의 단일 실행을 보장하면 된다.
애플리케이션 레벨에서 제어해서 해결하도록 시도했다.
고려해본 방법으로 3가지가 있었다.
1. Spring 환경변수로 스케줄러 실행 활성화 / 비활성화
2. 스케줄러 수행 API를 만들고 cron job으로 실행하기
3. 분산락 도입
1️⃣ Spring 환경변수로 스케줄러 실행 활성화 / 비활성화
yml 파일 환경변수로 각 서버 별 scheduler.enabled를 분리하고, Config 파일에서 스케줄러 실행 여부를 제어할 수 있다.
# application.yml
scheduler:
enabled: true // false1) 서버의 전체 Scheduler에 대한 On/Off
SchedulerConfig 파일을 생성하고 @ConditionalOnProperty 애노테이션으로 환경변수에 따른 스케줄링 실행을 On/Off 한다.
@ConditionalOnProperty는 bean을 등록할지 여부에 대해 조건을 거는 애노테이션이다.
@Configuration
@EnableScheduling // ServerApplication에서는 애노테이션 제거
@ConditionalOnProperty(
prefix = "scheduler",
name = "enabled",
havingValue = "true",
matchIfMissing = false // scheduler.enabled 미설정 시 false
)
public class SchedulerConfig {
}@ConditionalOnProperty 조건이 true가 되면 이 SchedulerConfig가 config로 로딩된다.
그럼 @EnableScheduling이 활성화 되고 @Scheduled가 동작한다.
2) 개별 Scheduler Class에 대한 On/Off
@ConditionalOnProperty 애노테이션을 개별 Scheduler Class에 적용한다.
@Component
@ConditionalOnProperty(
prefix = "scheduler",
name = "enabled",
havingValue = "true",
matchIfMissing = false
)
public class ReadingScheduler {
...조건이 true면 Scheduler 클래스가 bean으로 등록되므로 스케줄러가 실행된다.
3) 개별 Scheduler method에 대한 On/Off
메서드 수준의 제어를 위해선 @ConditionalOnProperty 애노테이션만으로는 해결할 수 없다.
따라서 @Value로 직접 property 값을 가져와서 early return 해야한다.
@Component
public class RankingScheduler {
@Value("${scheduler.enabled:false}")
private boolean isEnabled;
@Scheduled(cron = "0 0 * * * *")
public void updateMonthlyReading() {
if (!isEnabled) {
return; // 해당 스케줄러 비활성화
}
...
}
@Scheduled(cron = "0 */10 * * * *")
public void updateRanking() {
// 두 서버에서 스케줄러 모두 실행
...
}
}Q. 도입한다면 어떤 수준을 사용해야할까?
서버 전체 → 클래스 → 메서드 순으로 세밀하게 제어할 수 있다.
만약 도입한다면 1번 서버 전체 스케줄러 On/Off 수준으로 제어해도 괜찮을 것 같다.
우리 서비스는 단일 DB이기 때문이다.
만약 각 서버가 다른 DB를 보고 있었다면, 스케줄러가 두 번 수행되는 것이 의미있을지도 모른다.
하지만 지금은 두 서버가 하나의 DB를 바라보기 때문에 결국 하나의 DB에 중복 연산을 하는 것이다.
어떤 스케줄러들은 서버 각각 실행해야 하고, 어떤 스케줄러는 한 번만 실행 해야할 필요가 없다.
모든 스케줄러가 두 서버 통들어 딱 한 번만 실행하면 된다.
따라서 서버 전체 스케줄러에 대한 On/Off로 제어할 수 있을 것이다.
2️⃣ 스케줄러 수행 API를 만들고 cron job으로 실행하기
현재 실행되는 스케줄러를 API로 만들어서 cron job으로 실행하는 방법이다.
lambda에서 특정 시간에 스케줄러 API를 실행하게 만들면 로드밸런싱을 통해 한 쪽으로만 API 요청이 가서 중복 실행을 방지할 수 있다.
이 뿐만 아니라 서버가 죽었을 때 skip 된 스케줄러를 수동으로 실행하기에도 편리한 방안을 제공한다. 다만 외부에서 API를 접근할 수 없게 보안을 철저히 관리해야한다.
처음 생각한 방법은 스케줄러 API를 만들고 LB 서버에서 cron job 스크립트를 작성해 호출하는 방법이었다. 그런데 AWS를 찾아보니 EventBridge Scheduler + Lambda 조합으로 스케줄러 API를 호출하는 방법도 있었다.
2-1. 비용 고려: 10분 주기 1개는 거의 0원에 가깝다.
랭킹 스케줄러는 10분에 한 번 호출한다.
한 달 실행 횟수는 대략 6회/시간 × 24시간 × (30~31)일 = 약 4,320회다.
EventBridge Scheduler는 월 1,400만회까지 무료 구간이 있고,
초과하더라도 백만 건당 과금이라 이 수준은 비용이 사실상 0원에 가깝다.
Lambda도 월 100만건까지 무료 지원이므로 월 4천 번대 호출이면 요청 비용은 체감이 어려운 수준이다.
2-2. 구현 아키텍처 (랭킹 스케줄러 1개)
- EventBridge Scheduler: 10분마다 Lambda 트리거 (크론 등록)
- Lambda: 내부 인증 헤더를 붙여 기존 LB의 내부 전용 경로 호출
- 기존 LB(Nginx/HAProxy):
/internal/jobs/*경로만 백엔드로 프록시 - Spring Scheduler API: 랭킹 계산 실행 + 중복 실행 방지 테이블로 선점
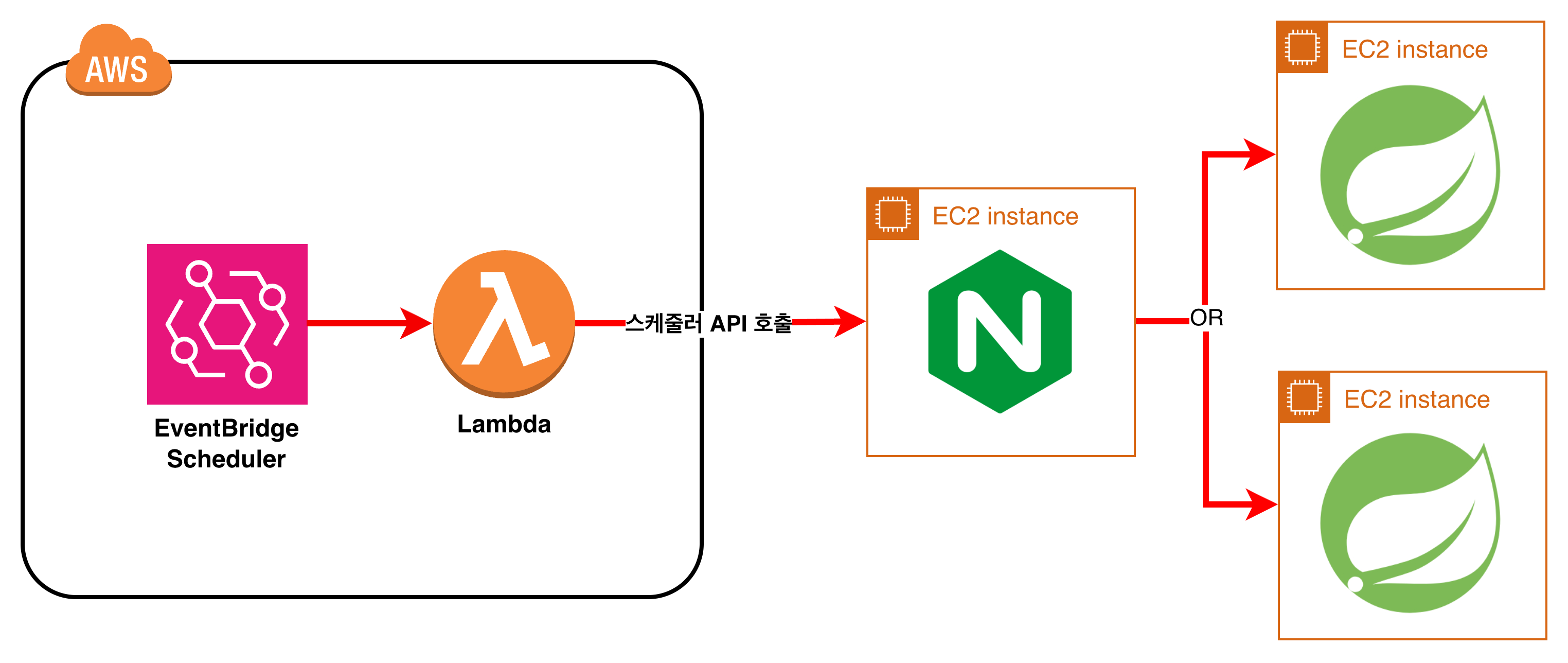
(우리는 비용 절감이 최우선이었기에 ALB 대신 자체 LB 서버를 구축해 사용하고 있다.)
2-3. 구현 과정
1) 랭킹 스케줄러를 “내부 전용 API”로 만들기
엔드포인트는 외부 공개가 목적이 아니므로 internal로 엔드포인트를 명시해준다.
POST/internal/jobs/monthly-ranking/run
@RestController
@RequiredArgsConstructors
@RequestMapping("/internal/jobs")
public class RankingSchedulerController {
private final RankingSchedulerJob rankingSchedulerJob;
@PostMapping("/monthly-ranking/run")
public JobRunResult run() {
return rankingSchedulerJob.run();
}
}2) 공유 저장소에 검증용 헤더 토큰 생성 및 검증 추가
안전하게 내부 서비스에서만 해당 스케줄러 API를 제어할 수 있도록 스케줄러 실행 전 헤더에 검증 토큰을 담아야한다. AWS의 secret으로 등록해서 Lambda, Spring 스케줄러 서버 모두 읽어서 갖고 있는다.
Spring 스케줄러에서는 엔드포인트가 스케줄러 실행 시도일 시 Filter로 internal-token이 자신이 보유한 값과 같은지 검증한다.
@Component
public class InternalSchedulerTokenFilter extends OncePerRequestFilter {
private static final String INTERNAL_PREFIX = "/internal/";
private static final String HEADER_NAME = "X-Internal-Token";
@Value("${internal.scheduler.token}")
private String expectedToken;
@Override
protected boolean shouldNotFilter(HttpServletRequest request) {
String uri = request.getRequestURI();
return uri == null || !uri.startsWith(INTERNAL_PREFIX);
}
@Override
protected void doFilterInternal(HttpServletRequest request,
HttpServletResponse response,
FilterChain filterChain)
throws ServletException, IOException {
// 스프링이 토큰을 못가져왔으면 안전하게 내부 엔드포인트 자체를 막기
if (expectedToken == null || expectedToken.isBlank()) {
deny(response, HttpServletResponse.SC_SERVICE_UNAVAILABLE, "internal token not configured");
return;
}
// 요청에서 내부 토큰 헤더를 포함하지 않으면 거부
String provided = request.getHeader(HEADER_NAME);
if (provided == null || provided.isBlank()) {
deny(response, HttpServletResponse.SC_UNAUTHORIZED, "missing internal token");
return;
}
// 토큰 값이 같은지 확인
if (!expectedToken.equals(provided)) {
deny(response, HttpServletResponse.SC_FORBIDDEN, "invalid internal token");
return;
}
filterChain.doFilter(request, response);
}
private void deny(HttpServletResponse response, int status, String message) throws IOException {
// 예외에 따른 response 세팅
}
}Step 3) 기존 LB에 내부 경로 라우팅 추가
LB 레벨에서 /internal/jobs/*를 백엔드로 넘기되, 외부 트래픽은 차단하는 게 핵심이다.
따라서 LB 레벨에서 Internal-Token 헤더 존재 여부로 사전 차단하면 좋다.
location /internal/jobs/monthly-ranking/run {
# 1. 내부 호출 토큰이 없으면 차단(선택)
if ($http_x_internal_token = "") { return 401; }
# 2. 백엔드로 프록시 (요청 1건 → 백엔드 1대)
proxy_http_version 1.1;
proxy_set_header Connection "";
proxy_set_header Host $host;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
# 3. 토큰 헤더를 백엔드로 전달
proxy_set_header X-Internal-Token $http_x_internal_token;
proxy_connect_timeout 2s;
proxy_read_timeout 30s;
proxy_pass http://api.domain.com;
}Step 4) Lambda 구현: Scheduler payload → 내부 API 호출
Lambda는 내부 토큰을 헤더에 포함해서 전달한다. Node.js를 사용하면 외부 의존성 없이 간편하게 구성할 수 있다고 한다.
// index.mjs (Node.js 18/20)
// handler = index.handler
export const handler = async (event) => {
const url = process.env.TARGET_URL;
const token = process.env.INTERNAL_TOKEN;
const timeoutMs = Number(process.env.TIMEOUT_MS ?? "8000");
if (!url || !token) {
throw new Error("Missing env: TARGET_URL or INTERNAL_TOKEN");
}
const ac = new AbortController();
const t = setTimeout(() => ac.abort(), timeoutMs);
const startedAt = Date.now();
try {
const res = await fetch(url, {
method: "POST",
headers: {
"X-Internal-Token": token,
"Content-Type": "application/json",
},
signal: ac.signal,
});
const elapsed = Date.now() - startedAt;
console.log(JSON.stringify({
msg: "ranking_recalculate_called",
status: res.status,
elapsedMs: elapsed,
}));
// 실패면 에러로 올려서 CloudWatch에서 바로 보이도록 함
if (!res.ok) {
const body = await res.text().catch(() => "");
throw new Error(`Scheduler API failed: ${res.status} ${body}`);
}
return { ok: true };
} finally {
clearTimeout(t);
}
};Step 5) EventBridge Scheduler 등록
10분 주기로 EventBridge Scheduler를 등록한다.
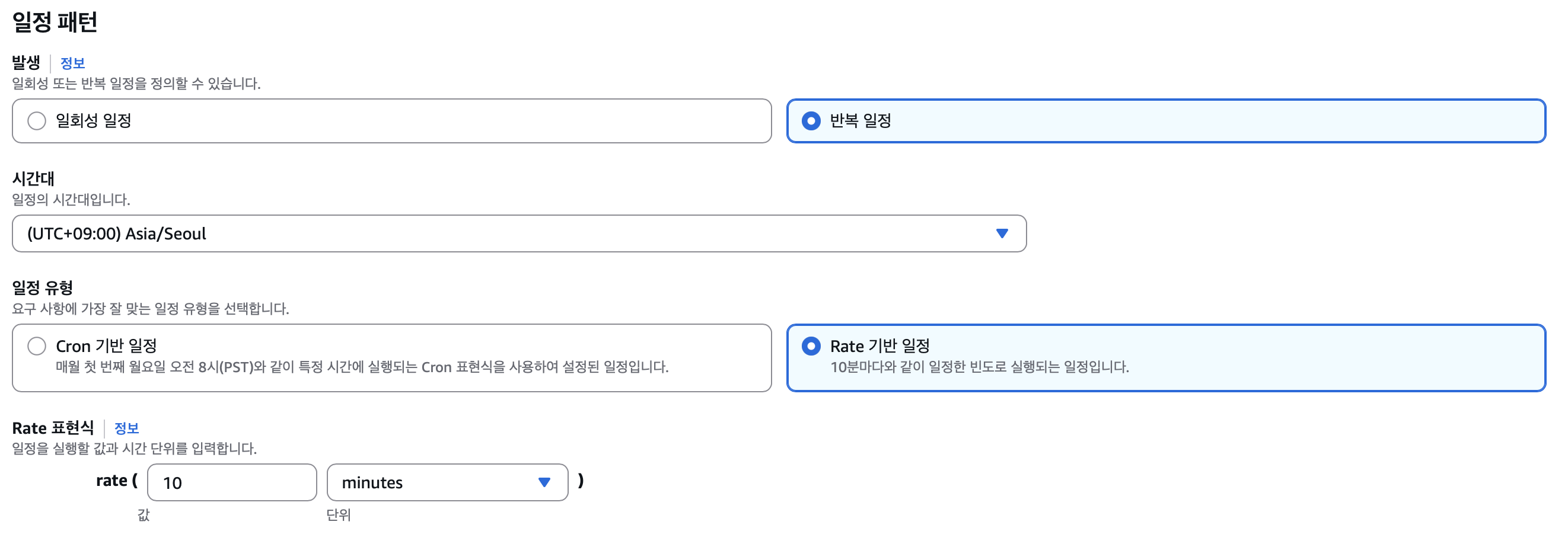
이제 이 EventBridge Scheduler의 대상으로 아까 등록한 Lambda job을 등록하면 된다.
이 구조의 장점은 스케줄 실행 주체가 서버 밖으로 빠지면서,
서버 재시작/장애로 스케줄이 누락돼도 수동 호출이 쉬워진다는 점이다.
3️⃣ 분산락 도입
분산락을 사용해 하나의 서버만 스케줄러를 동작하게 만들도록 하는 방법이 있다.
분산락 구현 방법으로는 MySQL의 네임드락과 ShedLock 라이브러리를 고려했다.
1. 네임드락으로 제어하기
MySQL의 네임드락을 사용하면 락을 얻은 쪽은 정상 수행하고, 락을 얻지 못한 쪽은 대기하게 된다. 이 때 대기 시간을 0초로 설정하면 락을 얻지 못한 쪽은 즉시 실패하면서 하나의 서버만 스케줄러를 실행하도록 보장할 수 있다.
네임드락의 주의점은 락이 커넥션에 붙는 것이므로 트랜잭션과 무관하다.
따라서 @Transactional의 commit/rollback과 락의 get/release는 상관없다.
주의할 시나리오가 락 release에서 실패할 시 트랜잭션과 작업 사항들은 rollback 되지만 락이 점유된 상태로 유지될 수 있다는 것이다.
그래서 네임드락을 점유하는 DataSource 커넥션 또한 같은 것으로 사용되어야 한다.
또한 JPA는 Entity 기반의 쿼리 실행에 최적화 되어있지만, 이런 Native Query가 필요한 경우는 JDBC가 적합하다.
그래서 만약 네임드락을 도입하게 된다면, JdbcTemplate 기반으로 아래와 같이 callback 패턴의 락 get/release를 구현해야한다.
@Component
@RequiredArgsConstructor
public class NamedLockExecutor {
private final JdbcTemplate jdbcTemplate;
public boolean execute(String lockName, Runnable task) {
return Boolean.TRUE.equals(jdbcTemplate.execute((ConnectionCallback<Boolean>) con -> {
if (!getLock(con, lockName, 0)) { // 못 잡으면 바로 종료
return false;
}
try {
task.run(); // 랭킹 스케줄러 수행
return true; // 성공 시 true
} finally {
releaseLock(con, lockName); // 락 해제
}
}));
}
private boolean getLock(Connection con, String lockName, int timeout) throws SQLException {
try (PreparedStatement ps = con.prepareStatement("SELECT GET_LOCK(?, ?)")) {
ps.setString(1, lockName);
ps.setInt(2, timeout);
try (ResultSet rs = ps.executeQuery()) {
rs.next();
return rs.getInt(1) == 1;
}
}
}
private void releaseLock(Connection con, String lockName) throws SQLException {
try (PreparedStatement ps = con.prepareStatement("SELECT RELEASE_LOCK(?)")) {
ps.setString(1, lockName);
ps.executeQuery();
}
}
}사용할 땐 이처럼 사용한다.
@Service
@RequiredArgsConstructor
public class RankingJobService {
private final NamedLockExecutor namedLockExecutor;
private final RankingService rankingService;
public boolean run() {
return namedLockExecutor.execute("monthly-ranking-scheduler", () -> {
rankingService.calculateMonthlyRanking(); // 여기에 @Transactional
});
}
}2. ShedLock 라이브러리 사용하기
ShedLock 라이브러리를 사용하면 간편하게 서버 한 곳에서만 스케줄러를 실행하도록 만들 수 있다.
ShedLock은 스케줄링 실행 시 동시에 최대 한 번만 실행되도록 제어하는 라이브러리이다.
하나의 스레드에서 작업이 실행 중이면 잠금이 걸리고, 다른 스레드에서 동일한 작업이 실행되지 않도록 하는 일종의 분산락 개념이다.
한 노드에서 이미 실행 중인 작업이 있을 경우, 다른 스레드는 대기하지 않고 건너뛴다.
MongoDB, JDBC, Redis 등 외부 저장소를 사용해서 테이블에 스케줄러의 실행 정보를 저장해야한다.
⚠️ 데이터베이스 레벨에서 직접 데이터 접근 락을 제어하는게 아닌, 애플리케이션 레벨에서 스케줄러 실행 횟수를 제어하는 것이다.
🔒 ShedLock의 원리
1) Lock 얻는 과정
- 모든 서버가 동시에 스케줄러 작업을 수행하려고 한다.
@SchedulerLockAOP가 먼저 개입해LockProvider를 통해 락을 시도한다.- 현재 시각 기준 점유할 수 있는 락(
lock_until <= now)일 경우에만 업데이트 한다.
# pseudo code
UPDATE shedlock
SET lock_until = now + lockAtMostFor,
locked_at = :lockedAt,
locked_by = :lockedBy
WHERE name = :name
AND lock_until <= :now;- 해당 update가 성공해서 1 row가 변경되면, 해당 인스턴스가 락을 획득한 인스턴스이다.
- 나머지 서버들은 0 row 업데이트이므로, 락을 못잡아 작업을 스킵한다.
2) Lock을 얻은 후 작업 실행
- 락을 잡은 서버가
lock_until = now + lockAtMostFor인 상태로 작업 수행을 시작한다.- 다른 서버는
now + lockAtMostFor이전까지는 락 획득에 실패한다.
- 다른 서버는
3) Lock 해제 과정
- 작업이 정상적으로 끝나면
lockAtLeastFor을 고려해lock_until을 조정한다.- 락의 최소 유지 시점과 실제 작업이 종료되는 시간 중 최대 시간으로
lock_until을 업데이트한다. - 락의 최소 유지 시간을 반영해, 너무 짧은 시간 내에 다른 서버가 재실행을 하는 것을 방지한다.
- 락의 최소 유지 시점과 실제 작업이 종료되는 시간 중 최대 시간으로
# pseudo code
UPDATE shedlock
SET lock_until = MAX(start_at + lockAtLeastFor, NOW())
WHERE name = :lockName
AND locked_by = :currentInstance;🔒 ShedLock 적용하기
기존의 스케줄링 메서드는 아래와 같다.
@Scheduled(cron = EVERY_TEN_MINUTES_CRON, zone = TIME_ZONE)
public void tenMinutelyCalculateMemberRank() {
log.info("이달의 독서왕 순위 업데이트");
readingService.updateMonthlyRanking();
log.info("이달의 독서왕 순위 업데이트 완료");
}ShedLock을 적용하기 위해선 ShedLock 라이브러리를 import하고,
Application 클래스에 @EnableSchedulerLock 애노테이션을 붙여준다.
...
@EnableSchedulerLock
@SpringBootApplication
public class BomBomServerApplication {
...이제 shedlock 전용 테이블이 필요하다.
작업에 대해 락을 잡고 처리하는데 필요한 정보가 shedlock 테이블에 저장되기 때문이다.
shedlock을 생성하는 테이블 스키마는 아래와 같다.
CREATE TABLE shedlock(
name VARCHAR(64) NOT NULL,
lock_until TIMESTAMP(3) NOT NULL,
locked_at TIMESTAMP(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3),
locked_by VARCHAR(255) NOT NULL,
PRIMARY KEY (name)
);name: 작업 이름이다. (PK)lock_until: 이 시간까지 락이 유효하다.locked_at: 락을 획득한 시간이다.locked_by: 락을 가진 인스턴스이다.
ShedLock을 얻는데 사용하는 ShedLockProvider bean도 등록한다.
@Configuration
public class ShedLockConfig {
@Bean
public LockProvider lockProvider(DataSource dataSource) {
return new JdbcTemplateLockProvider(dataSource);
}
}그리고 ShedLock을 적용하려는 스케줄러에 아래처럼 @SchedulerLock을 적용하면 된다.
@Scheduled(cron = EVERY_TEN_MINUTES_CRON, zone = TIME_ZONE)
@SchedulerLock(name = "ten_minutely_calculate_member_rank", lockAtLeastFor = "PT1.5S", lockAtMostFor = "PT3S")
public void tenMinutelyCalculateMemberRank() {
log.info("이달의 독서왕 순위 업데이트");
readingService.updateMonthlyRanking();
log.info("이달의 독서왕 순위 업데이트 완료");
}name: ShedLock용 테이블에 PK로 들어갈 작업 이름이다.- 서버가 여러 대 떠있어도 하나의 시점에
name의 락을 갖는 서버는 딱 한 대이다.
- 서버가 여러 대 떠있어도 하나의 시점에
lockAtLeastFor: 적어도 락을 유지할 시간을 지정한다.- 서버들 간 시간 차이로 인해 작업이 너무 빨리 끝나서 락을 해제하면, 타 서버에서는 락을 점유할 수 있다고 오인할 수 있기 때문에 필요하다.
lockAtMostFor: 락을 최대 유지할 시간을 지정한다.- 평소 예상 실행 시간보다 훨씬 길게 잡아 안전장치로 두어야 한다.
🚀 최종적으로 선택한 방법
아래는 각 방법들의 장단점을 정리했다.
1. Spring 환경변수로 스케줄러 실행 활성화 / 비활성화
| 장점 | 단점 |
|---|---|
| - 단일 실행 단위를 서버부터 메서드까지 세밀한 제어가 가능하다. | - 스케줄링 담당 서버가 죽을 경우 실행되지 않는다. |
| - 서버를 교체하려면 다시 스케줄링 서버를 재설정해주어야 한다. |
2. 스케줄러 수행 API를 만들고 cron job으로 실행하기
| 장점 | 단점 |
|---|---|
| - EventBridge+Lambda 조합으로 서버 오류 및 재가동으로 인한 재시도가 수월하다. | - 스케줄링 API를 외부에 공개하게 되므로 헤더 토큰이나 보안그룹 등 민감한 보안 관리가 필요하다. |
| - 스케줄링 실행 주기나 일시중지, 재시도 등의 정책이 배포없이 이뤄질 수 있다. |
3. 분산락 도입
| 장점 | 단점 |
|---|---|
| - 하나의 서버가 죽으면 나머지 다른 서버가 스케줄러를 실행하면 되므로 유연하게 단일 실행을 보장할 수 있다. | - 락 저장소에 장애가 발생하면 스케줄러도 연계적으로 같이 멈춘다. |
| - 락 테이블로 어떤 서버가 언제 스케줄러를 실행했는지 모니터링이 용이하다. |
첫 번째 방법은 스케줄링 담당 서버에게 스케줄링 책임이 과도하게 부여된다는 점이 큰 단점으로 와닿았다.
또한 이 방법의 장점도 우리에겐 크게 다가오지 않는다. 모든 스케줄러가 단일 실행되어야 하므로 메서드 별 제어가 필요 없었기 때문이다. 그래서 첫 번째 방법은 제외했다.
두 번째 방법인 EventBridge+Lambda 조합을 활용한 스케줄러 API를 cron job으로 수행하기도 고려했으나, 보안상의 문제로 좋지 못하다고 판단했다. 만약 우리 자체 LB 서버가 아닌 ALB를 사용했다면 internal API와 internet-facing이 명확히 분리해서 메인 서버에는 이 ALB로부터 온 API만을 허용하도록 스케줄러 API 보안을 탄탄하게 구성할 수 있었을 것이다. 하지만 ALB는 꽤나 비용이 나가는 AWS 서비스이며, 우리는 현재 비용 절감이 더 중요한 상황이라 선택하지 않았다.
3번 분산락 도입은 나머지 두 방법 대비 유지보수 비용과 유연하단 장점이 컸고, 단점이 크지 않게 느껴졌다.
분산락을 어떻게 구현하더라도 우리는 RDS를 사용해야했고, 사실상 RDS가 SPOF는 맞지만 이 단점은 모든 방법들도 마찬가지였기 때문이다.. 감안할 수 있는 수준의 단점이라고 여겼다.
그래서 분산락 구현 방법 중 네임드락 구현과 ShedLock 라이브러리 사용의 장단점을 비교했다.
MySQL 네임드락 구현
| 장점 | 단점 |
|---|---|
| - 지금 스택에서 추가 인프라 없이 구현할 수 있다. | - 현재 JPA 구조로는 한계가 있어 JDBC를 도입해야 한다. |
| - 커넥션에 붙은 락이므로 커넥션 관리를 직접 해줘야해 구현복잡도가 높다. |
ShedLock 라이브러리 사용
| 장점 | 단점 |
|---|---|
| - 락을 잡은 후 서버가 죽는 상황이 와도 lockAtMostFor 옵션으로 자동 락 해제가 되어 안정적이다. | - 락 점유 시간에 대한 튜닝이 필요하다. (lockAtLeastFor, lockAtMostFor) |
| - 애노테이션으로 손쉽게 분산락 적용이 가능하다. | - 라이브러리 의존성이 추가된다. |
두 방법을 비교했을 때, 네임드락 대비 ShedLock의 장점이 훨씬 크다고 판단했다.
분산락 적용도 라이브러리 import와 애노테이션 붙이기로 간단했으며, lockAtLeastFor, lockAtMostFor 옵션들이 주어져 더 안정적으로 락을 제어할 수 있다.
✅ 그래서 결론적으로 ShedLock을 도입하기로 결정했다.
이렇게 Deadlock 발생 원인에 대해 파악해보고 ShedLock으로 간단하게 해결했다.
분산환경에서 발생할 수 있는 문제로 "스케줄러 중복 실행"을 깨닫게 됐다.
공부해보면서 Shedlock은 분산 환경 + 단일 DB 일 때 사용하기 좋은 전략임을 느꼈다.
하지만 규모가 훨씬 큰 서비스에서는 스케줄러 전용 서버가 분리될 수도 있을 것 같고, 여러 대의 스케줄러 서버가 생기면 AWS의 ALB + EventBridge + Lambda 조합을 사용할 것 같다. 아무래도 수동 재시도의 이점이 크게 여겨지지 않을까 싶다.
참고
https://mariadb.com/docs/server/reference/sql-statements/administrative-sql-statements/show/show-engine-innodb-status
https://bugs.mysql.com/bug.php?id=72005
https://github.com/lukas-krecan/ShedLock
https://mariadb.com/docs/server/reference/sql-statements/administrative-sql-statements/show/show-engine-innodb-status
