
solution 테이블에 대해 result를 가지고 아래와 같이 조회할 일이 있었다.
SELECT * FROM solution WHERE result LIKE '%점';solution은 테스트 데이터로 FAKER를 사용해 1000만개 데이터를 삽입했다. 그 중 저 쿼리의 결과는 1,001,664개다. 전체 데이터의 약 10%정도를 차지한다.
보통 wildcard(%)를 맨 앞에 위치시키면 인덱스를 사용하지 못한다는 점에서 성능 저하가 발생한다고 알려져 있다.
하지만 생각보다 성능이 좋았다.
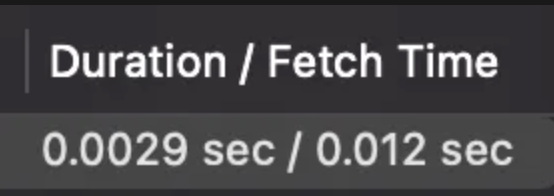
EXPLAIN으로 실행 설계를 찾아보았다.
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | solution | NULL | ALL | NULL | NULL | NULL | NULL | 9622368 | 11.11 | Using where |
key가 NULL인걸 보아, full scan을 하고있단 것을 알 수 있다. filtered도 11.11%로 꽤나 정확한 수치를 예측하고 있다.
1. %를 맨 앞에 뒀을 때 성능 저하가 되는 수준은 어느 정도일까?
이걸 처음에 알아내는 게 정말 힘들었다. 일일이 테스트 데이터 수를 조정해가며 언제부터 부하가 일어나는지를 찾고 있었기에..
stackoverflow에서 조회하고자 하는 데이터가 전체의 20%정도가 되면 옵티마이저가 index scan보다 full scan이 더 효율적이라고 판단한다는 이야기를 보았다.
현재 케이스의 경우, 전체 100만건 데이터 중 10%도 안된다. 그럼에도 성능이 저정도였다.
1000만건 중 약 1%로 약 10만개의 데이터가 저 쿼리에 해당하도록 데이터를 만들었다.
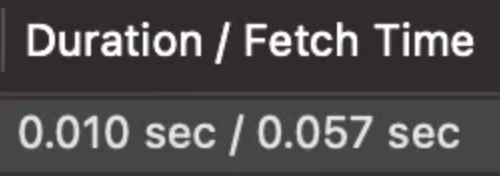 여전히 빠르다..
여전히 빠르다..
이번엔 그냥 1000만건 중 100건만 해당하도록 데이터를 세팅했다.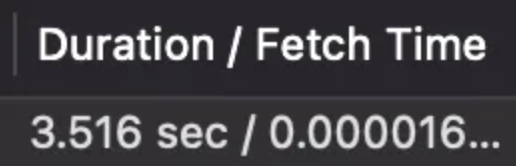 이제야 부하가 발생한다.
이제야 부하가 발생한다.
1000건이 해당하도록 데이터를 수정했다.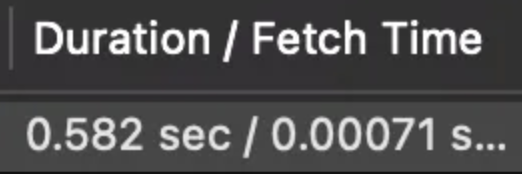 급격하게 조회 속도가 빨라진다.
급격하게 조회 속도가 빨라진다.
아마 성능 부하가 있는 마지노선의 데이터 수는 몇백건대가 되는 것 같다. 1000만 중에 수백이라니...
2. 왜 index scan 없이도 full table scan으로 성능이 좋을 수 있는걸까?
성능 부하가 발생하는 데이터 수는 대강 추려졌고, 그렇다면 왜 full scan으로도 성능이 좋을수가 있을까?
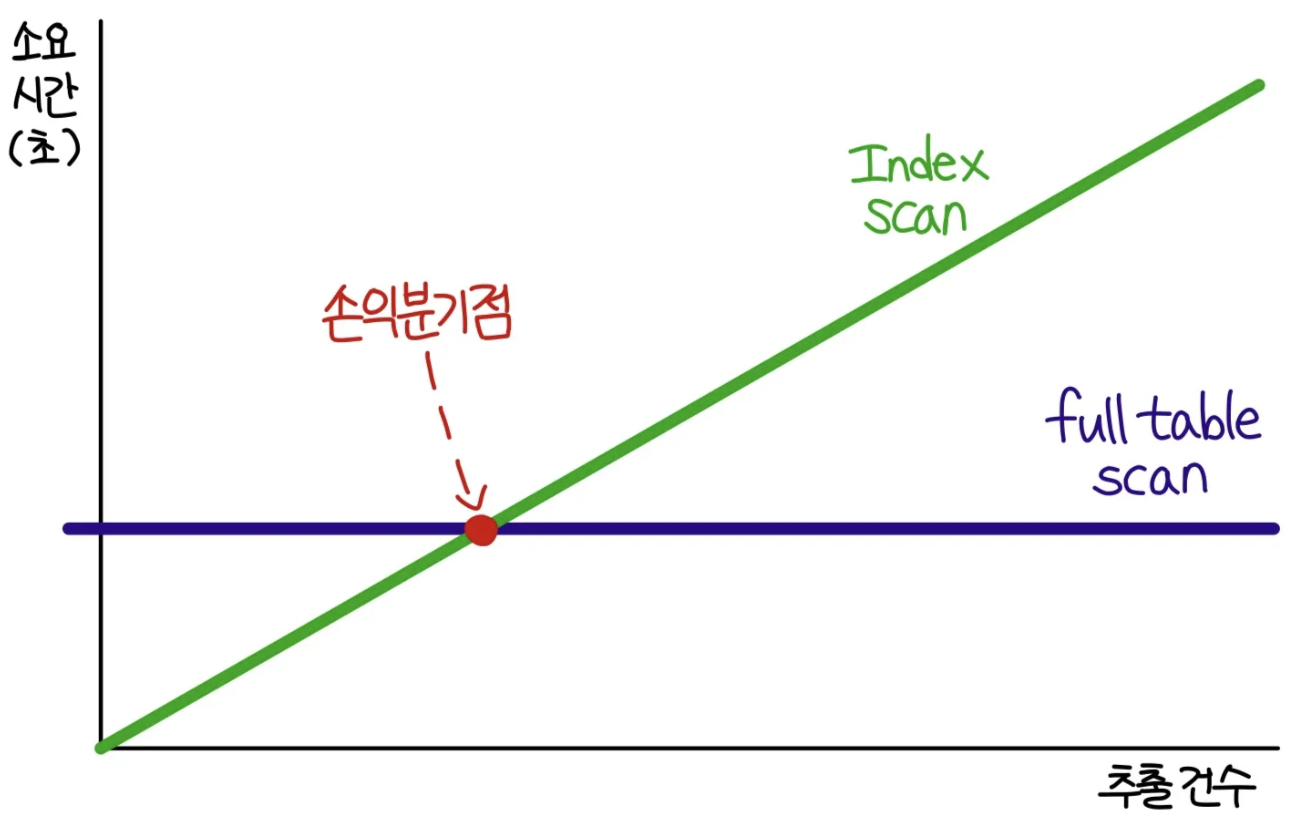
인덱스는 손익분기점이 있다. DB에서 데이터를 조회할 때 일정 건수 이상을 추출하게 되면 index scan보다 full scan이 덜 걸릴 수 있다. 그 지점이 손익분기점이다.
그렇다면 이러한 손익분기점은 왜 나타날까?
인덱스를 스캔하는 이유는 WHERE을 만족하는 적은 수의 데이터에 대해 인덱스를 빠르게 찾기 위해서이다. 인덱스 스캔 후 테이블 레코드를 랜덤 액세스 하는데 이 과정에서 부하가 발생한다.
데이터가 적을 경우에는 이 방식이 속도 향상에 이점을 줄 수 있다. 하지만, 이 구역을 모두 찾아봐야 한다면 인덱스 → I/O로 반복적인 접근이 필요하다.
full scan의 경우 순차 접근이다. 메모리에 적재해야 하는 건 많아져도 블록 별 순차 접근으로 접근 비용이 감소한다. 더구나 Multi block I/O 방식을 사용해 I/O call이 필요한 시점에 인접한 블록들을 같이 읽어 메모리에 적재한다. 이로 인해 동시 처리량이 늘어나는 것이다.
Index scan은 Single block I/O 방식으로 블록을 읽는다. 한 번의 I/O call에 하나의 데이터 블록만 읽어 메모리에 적재하는 것이다.
그럼 손익분기점의 기준이 어떻게 될까?
보통 손익분기점은 5%~20%의 낮은 수준으로 결정된다고 한다. Clustering factor에 의해 많이 달라지며, CF가 나쁘면 손익분기점이 5% 미만에서 결정되고, 심하면 1% 미만으로 낮아지기도 한다. 반대로 CF가 좋으면 90%까지 향상한다. 나의 케이스에서는 데이터가 완전한 랜덤 저장이기에 CF가 매우 좋지 않다. 그래서 1% 미만이 된 것인가 싶기도 하다.
3. 성능 저하 상태에서 REVESE() function을 사용한 functional index를 활용해보자
아까 위에서 작성한 쿼리의 성능이 저하된 상태의 데이터 셋을 만들었다. 아까 쿼리의 치명적인 단점은 와일드카드(%)를 맨 앞에 쓴다는 것이다. 인덱스를 사용하지 못하게 되는데, 그렇다면 와일드카드가 맨 뒤로 오도록 만들어서 성능을 향상시킬 수 있지 않을까? 라는 생각을 하게 되었다. function-based index를 사용하는 것이다.
MySQL은 8 버전부터 functional index를 지원한다. 기존엔 컬럼의 형태를 그대로 유지한 채 인덱스를 생성했다. 그래서 조회할 때 인덱스를 사용하고자 하는 컬럼의 형태가 변형되면 인덱스를 사용하지 못한다는 단점이 있었다. functional index가 이러한 점을 보완한다.
functional index는 컬럼 형태를 변형해 인덱스를 만드는 것이다. 내가 위에서 제시한 쿼리를 아래 형태처럼 변형해보고자 한다.
SELECT * FROM solution WHERE REVERSE(result) LIKE "점%";result의 값을 거꾸로 뒤집으면 기존에 ‘100점’, ‘틀렸습니다’ 등이 ‘다니습렸틀’, ‘점001’ 이런 식으로 변형되는 원리를 사용하고자 한 것이다. 그렇다면 점수로 끝나는 result의 solution도 와일드카드를 뒤에 붙이면서 인덱스 사용도 가능해지게 되고 성능도 향상될 것이라고 생각했다.
위 쿼리를 수행하기 위해선 아래와 같은 functional index를 생성한다.
CREATE INDEX idx_reversed_result ON solution((REVERSE(result)));functional index를 사용하기 위해선 변형한 컬럼 그대로의 형태로 사용해야 한다는 규칙이 있다. 즉, 위와 같은 쿼리를 사용하면 되는 것이다.
저렇게 생성하고 테스트를 해봤는데 여전히 성능이 향상되지 못했다. EXPLAIN으로 실행 계획을 살펴보니 idx_reversed_result를 사용하지 않았다. 여전히 full scan을 사용했다.
혹시 MySQL의 옵티마이저가 적절치 않은 인덱스라고 판단해 사용하지 않은 것일까 싶었다. 그래서 FORCE INDEX (idx_reversed_result) 로 인덱스도 지정해보았다. 하지만 이번에도 인덱스를 사용하지 않았다.
USE INDEX였으면 해당 인덱스를 사용하라는 힌트만 줄 뿐 강요하지 않는다. 이도 옵티마이저가 판단하에 적절한 인덱스다 싶으면 사용하는 것이다. 하지만 FORCE INDEX는 다르다. FORCE INDEX는 직접 인덱스를 지정해주고 강제로 사용하게 한다. 그럼에도 사용하지 않는데.. 원인이 뭘까 싶어서 진짜 몇주간 찾아본 것 같다.
4. 결론은.. MySql의 버그
https://bugs.mysql.com/bug.php?id=104713
https://stackoverflow.com/questions/79031941/why-my-query-doesnt-use-a-functional-index-in-mysql8
너무 허무하게도.. MySQL에서 functional index를 도입할 때 LIKE가 포함된 쿼리에 대해서는 버그가 있다고 한다. MySQL 버그 리포트를 찾다가 저 글을 보긴 했었다. LOWER() 함수 인덱스에 대해서 LIKE 쿼리가 작동하지 않는다는 내용이었는데, 그게 초점이 LOWER() 함수가 아닌 functional index와 LIKE 쿼리였던 것이다. REVERSE() 함수 뿐 만 아니라 모든 function에 대해서 index를 만들면 LIKE 쿼리에선 적용되지 않는 버그가 있었고, 이미 2021년에 보고된 버그라고 한다. 현재 기준 가장 최신 버전에서도 여전히 해결이 안된 모양이다.
마지막이 좀 허무한 버그로 끝나버렸지만.. 그래도 DB에 대해 좀 더 깊은 내용들을 공부해 볼 수 있었던 게 좋은 경험이었다.
