ShedLock을 사용해도 스케줄러가 두 번 실행 되는 문제
저번에 Spring scheduler로 이달의 랭킹을 업데이트 하는데, 두 개의 인스턴스가 한 번에 monthly_reading 테이블에 대한 락을 점유하려고 해서 Deadlock이 발생하는 일이 있었다.
그래서 @SchedulerLock을 사용해 둘 중 한 애플리케이션만 락을 점유하도록 데드락을 방지했다.
 그럼에도 불필요하게 두 서버 모두가 스케줄러를 실행하고 있다.
그럼에도 불필요하게 두 서버 모두가 스케줄러를 실행하고 있다.
다른 시간대에도 계속 중복 스케줄링이 발생하나 싶어서 다른 로그들도 살펴봤지만, 꼭 매일 자정에만 중복으로 2번의 업데이트 스케줄링이 발생하고 있었다.
ShedLock을 도입하게 된 배경이 스케줄러가 중복 실행을 해결해준다는 점이었는데, 자정에 또 두 번씩 실행된다.
중복 실행이 다시 발생한 이유
@SchedulerLock 의 설정 내용은 아래와 같다.
@Scheduled(cron = EVERY_TEN_MINUTES_CRON, zone = TIME_ZONE)
@SchedulerLock(name = "ten_minutely_calculate_member_rank", lockAtLeastFor = "PT1.5S", lockAtMostFor = "PT3S")
public void calculateMemberRank() {
log.info("이달의 독서왕 순위 업데이트");
readingService.updateMonthlyRanking();
log.info("이달의 독서왕 순위 업데이트 완료");
}lockAtLeastFor: 작업이 일찍 끝나더라도 최소 1.5초는 락을 잡고 있는다.lockAtMostFor: 작업에 대해 최대 3초 락을 잡고 있는다.
ShedLock 내부 로직
⚠️ 아래 나오는 쿼리는 실제 발생하는 쿼리가 아닌 내부 로직을 이해하기 위한 pseudo code이다.
- 락을 점유하려는 서버가
shedlock테이블에 아래 작업을 시도한다.
# pseudo code
UPDATE shedlock
SET lock_until = now + lockAtMostFor, # 락 최대 점유 시간까지 타 서버가 락을 점유하지 못하도록 업데이트한다.
locked_at = :lockedAt, # 현재 락 점유 시점
locked_by = :lockedBy # 점유한 락의 서버
WHERE name = :name
AND lock_until <= :now; # 현재 시점 이전에 락이 풀려있을 경우- 락 점유를 성공한 스레드가 작업을 완료하면
shedlock테이블을 업데이트한다.
# pseudo code
UPDATE shedlock
SET lock_until = MAX(start_at + :lockAtLeastFor, NOW())
WHERE name = :lockName
AND locked_by = :currentInstance;start_at+lockAtLeastFor: 최소한으로 락을 점유하기까지의 기간NOW(): 작업이 끝난 현재 시점- 스케줄러가 일찍 끝나더라도 바로 락이 풀려서 재실행이 되지 않도록
lockAtLeastFor을 적절히 지정해야한다.
스케줄러 실행 타임라인 분석
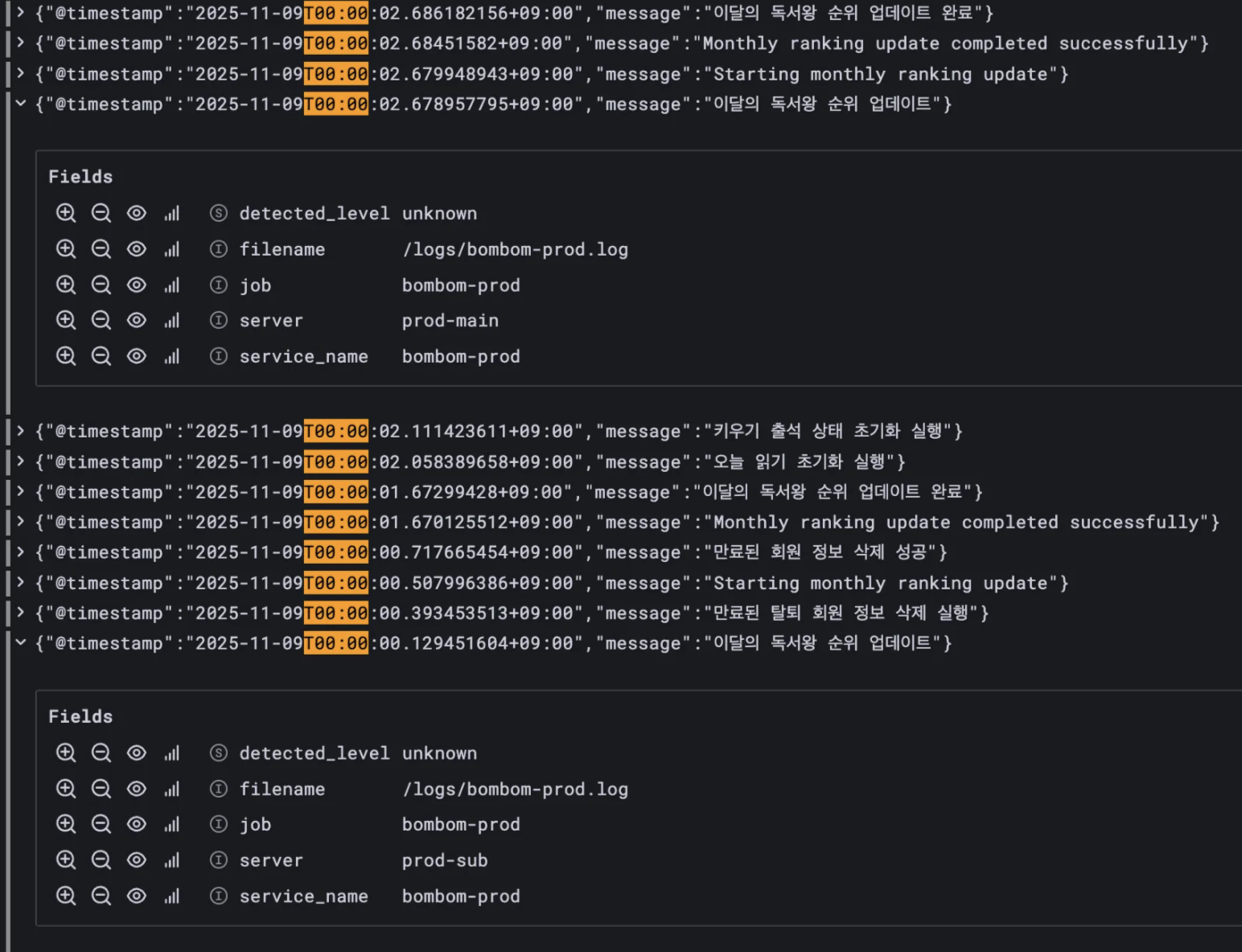
중복 실행 타임라인을 shedlock 점유 과정과 함께 분석했다.
📝 스케줄러 실행 타임라인
- T00:00:00.1294: prod-sub에서 작업 시작
- T00:00:01.6729 : prod-sub에서 작업 종료
lock_until= MAX(start_at+lockAtLeastFor,ended_at) = T00:00:01.6729
start_at(0.1294s) +lockAtLeastFor(1.5s) = 1.6294sended_at= 1.6729s- T00:00:02.6789 : prod-main에서 작업 시작
- 1.6279s(
lock_until) ≤ 2.6789s(now) 이므로 락 점유 가능- prod-main에서 락 점유 후 스케줄러 작업 실행
- T00:00:02.6861 : prod-main에서 작업 종료
스케줄러는 00:00:00, 즉 자정에 실행되도록 cron을 설정했다.
prod-sub는 00:00:00에 시도했는데, prod-main은 00:00:02로 2초의 delay가 발생한 것이다.
예상했던 것은 prod-sub, prod-main 두 서버 다 스케줄러 실행 로그가 00:00:00에 찍혀야했다.
왜 이러한 스케줄러 실행 delay가 발생할까?
스케줄러가 00:00:00에 시작하지 않는 이유
랭킹 업데이트 스케줄러는 10분 단위로 실행된다.
그래서 00:00:00부터 10분 단위로 로그를 분석해본 결과, 오로지 자정에만 딜레이가 발생한다.
10분, 20분 등 그 이후의 스케줄러는 정상적으로 한 번 작동함을 확인할 수 있었다.
cron을 00:00:00로 지정한 스케줄러가 꽤 있는데, 이 부분들까지 포함해서 분석했다.  하지만 실행하는 시간은 모두 다르고, 초 단위도 넘어서 딜레이가 발생한다.
하지만 실행하는 시간은 모두 다르고, 초 단위도 넘어서 딜레이가 발생한다.
이를 통해 스케줄러가 직렬로 실행됨을 파악했다. 왜 직렬로 실행됐을까?
Spring Scheduler의 스레드 풀 사이즈는 1이다.
Spring은 Scheduler 전용 스레드 풀을 갖고있다.
Spring이 내부적으로 TaskScheduler를 하나 만들어두고 그 스레드 풀에서 주기적으로 메서드를 실행해주는 것이다. (일반적으로 client에서 요청하는 Tomcat 요청 스레드 풀과는 완전히 다르다.)
@EnableScheduling이 켜져있으면, 기본 스케줄러 풀 크기를 1로 지정한다.
아래는 @EnableScheduling의 주석이다.
Spring은 기본적으로 scheduler와 관련된 빈 정의를 탐색합니다. (ex:
TaskScheduler)
TaskScheduler나ScheduledExecutorService에 대한 커스텀 빈이 존재하지 않으면, 기본적으로 로컬 싱글 스레드가 생성되어 스케줄러에 사용됩니다.
따라서 별도의 스케줄러 스레드풀 설정이 없다면 애플리케이션 하나 당 싱글 스레드로 스케줄러를 실행하는 것이다.
즉, 매일 자정에 실행하는 스케줄러가 10개 있으면 이들이 단일 스레드로 순차 처리된다.
고려한 해결법
1. Spring Scheduler의 스레드 풀 크기를 늘린다.
스케줄러를 멀티스레드로 돌리기 위해 스케줄러 스레드 풀 크기를 늘리는 방법이 있다.
- yaml 파일에서 설정하기
spring:
task:
scheduling:
pool:
size: 3- 코드에서
TaskSchedulerConfiguration추가하기
@Configuration
public class SchedulingConfig {
@Bean
public ThreadPoolTaskScheduler taskScheduler() {
ThreadPoolTaskScheduler scheduler = new ThreadPoolTaskScheduler();
scheduler.setPoolSize(10); // Set your desired pool size
scheduler.setThreadNamePrefix("my-scheduled-task-");
scheduler.initialize();
return scheduler;
}
}Q. 스레드 풀을 늘리면 지금의 문제가 해결되는가?
스레드풀 사이즈를 정각 스케줄러 개수만큼 늘리면 해결이 가능하다.
정각에 모든 스케줄러가 병렬 실행되기 때문이다.
하지만 정각에 실행하는 스케줄러 수가 더 늘어난다면 어떨까?
이전 증상과 똑같이 스케줄러 task는 pending 될 수 있으며, 딜레이가 생기는건 마찬가지일 것이다.
따라서 근본적인 해결 방법이라기보단, 지금의 상황을 위한 일종의 임시 방편이다.
❓스케줄러에서 스레드 풀을 키워야 하는 경우는?
스레드 풀 크기를 너무 크게 늘려버리면 리소스가 낭비되기 쉽다.
따라서 정말 필요한 경우일 때 스레드 풀을 조정하고 사용해야 한다.1. 하나의 스케줄러가 오랜 시간 작업할 경우
하나의 스케줄러가 오랜 시간 실행되면, 스케줄러의 단일 스레드를 오랫동안 점유하게 된다.
같은 스케줄러에 등록된 다른 작업들은 이 스케줄러가 비워질 때까지 대기해야 한다.
그럴 때 스레드 풀 크기를 적절히 늘려서 병렬로 실행하면, 다른 작업들은 오래 걸리는 스케줄러의 영향을 받지 않을 것이다.
- 외부 API 호출하기
- S3 같은 외부 시스템에 대한 접근
- 대량 데이터 정리같은 데이터 볼륨이 큰 작업
2. 짧은 텀으로 자주 실행되는 경우
짧은 텀으로 실행하는 스케줄러가 가끔이라도 지연되면, 싱글 스레드로 인해 뒤에 예정된 실행들이 연속적으로 지연될 수 있다. 즉, 정해진 텀마다 실행한다는 보장이 깨질 수 있다.
이 때 스레드 풀 크기를 늘리면 한 번 스케줄러가 지연되어도 다음 작업은 여분의 스레드에서 실행할 수 있으므로 영향을 받지 않는다.
- 실시간 랭킹 갱신
- 모니터링
- 알림 트리거 등 계속 도는 가벼운 작업
🤔 하지만 이러한 경우들은 보통 스프링 스케줄러 자체에서 모두 처리하는게 아니라,
스케줄러는 일종의 작업 트리거 역할을 하고
1. 실제 작업은@Async로 비동기 처리 하거나
2. 별도의 메세지 큐로 넘기는 것이 더 합리적일 것 같단 생각이 든다.
2. lockAtLeastFor을 조정한다.
최소 락을 점유하고 있을 시간을 더 늘리면 해결된다.
@Scheduled(cron = EVERY_TEN_MINUTES_CRON, zone = TIME_ZONE)
@SchedulerLock(name = "ten_minutely_calculate_member_rank", lockAtLeastFor = "PT1.5S", lockAtMostFor = "PT3S")
public void calculateMemberRank() {
log.info("이달의 독서왕 순위 업데이트");
readingService.updateMonthlyRanking();
log.info("이달의 독서왕 순위 업데이트 완료");
}현재의 lockAtLeastFor은 1.5초이다.
적절하게 락을 잡으려면 어떻게 지정해야할까?
Shedlock Github의 README에 아래같은 예시가 있다.
Example
Let's say you have a task which you execute every 15 minutes and which usually takes few minutes to run. Moreover, you want to execute it at most once per 15 minutes. In that case, you can configure it like this:
import net.javacrumbs.shedlock.core.SchedulerLock; @Scheduled(cron = "0 */15 * * * *") @SchedulerLock(name = "scheduledTaskName", lockAtMostFor = "14m", lockAtLeastFor = "14m") public void scheduledTask() { // do something }By setting
lockAtMostForwe make sure that the lock is released even if the node dies. By settinglockAtLeastForwe make sure it's not executed more than once in fifteen minutes.
15분에 한 번씩 실행되는 스케줄러의 텀을 보장하기 위해 lockAtLeastFor을 14m으로 지정한 것이다.그래서 나도 10분이라는 단위를 보장하기 위해 lockAtLeastFor을 9분으로 잡으면 되지 않을까 싶었다.
하지만 스케줄러 작업은 아무리 길어도 약 5~6s 이내에 완료될텐데, shedlock의 최소 락 점유 시간을 이렇게까지 길게 잡아도 될까?
앞 순서에 있던 작업들이 1분 이상 늦어지면, 다음 텀에 스케줄러 실행이 스킵될 수 있다.
📝 스케줄러 스킵 시나리오
스프링 스케줄러는 ‘싱글 스레드’이고,lockAtLeastFor을 9분으로 잡았다고 가정해보자.
‘이달의 랭킹 업데이트’ 스케줄러가 10개 task 중 10번째에 배치됐다.
9번째 스케줄러 작업이 끝난 후, 10번째 스케줄러 실행 시작 시점이 00:01:34 이다.
lock_until=start_at+lockAtLeastFor
= 00:01:34 + 00:09:00
= 00:10:34
즉, 다음 스케줄러는 00시 10분 34초 이후에 락을 점유할 수 있다.
- 다음 스케줄러 실행 시간인 00:10:00 에는 ‘이달의 랭킹 업데이트’ 스케줄러가 싱글 스레드의 첫 번째 작업으로 할당됐다.
- 00:10:00(
start_at) < 00:10:34(lock_until) 이므로, 이번 스케줄러는 락을 점유할 수 없다.- 따라서 10분에 실행한 스케줄러는 스킵된다.
물론 지금 서비스상으로는 몇 초 내에 모든 스케줄러 실행이 가능해서 1분 이상 지연되는 경우는 흔치 않다.
하지만 데이터가 충분히 쌓이면서 스케줄러 하나하나가 작업이 점점 오래걸리게 되면 가능할 수 있는 시나리오라고 생각한다.
그래서 최대 딜레이가 발생할 수 있는 시간으로 적절하게 lockAtLeastFor을 설정한다.
현재까지 발생한 스케줄러 딜레이 시간을 고려했을 때 약 2~3s 걸렸으므로 lockAtLeastFor은 여기서 더 여유있게 지정해 6s로 설정했다.
선택한 해결 방법 : lockAtLeastFor 조정
이미 shedlock을 사용하고 있는 상태에서 가장 비용이 적게 들고 근본적으로 shedlock이 락을 점유할 수 있게 된 것을 방지하는 방법은 lockAtLeastFor 값을 조정하는 것이라고 판단했다.
그래서 lockAtLeastFor을 3s로 수정했다.
참고
https://umbum.dev/2032/
https://github.com/lukas-krecan/ShedLock?utm_source=chatgpt.com
