좋아요 기능 설계하기 -2. 동시성 제어

이전 좋아요 기능 설계하기 -1. 멱등한 API 편에서도 언급했듯이, 좋아요 기능은 재시도 가능성이 높다.
동시성 문제가 가능하기 아주 쉬운 기능인 것이다.
그래서 원자적 연산과 가시성을 보장하도록 동시성을 제어할 다양한 방법들을 고려해봐야 한다.
동시성 문제가 발생하는 시나리오
현재 상태에서는 동시에 여러 요청이 발생할 경우 race condition으로 인한 좋아요 개수 누락이 발생할 수 있다. 좋아요 등록 service 메서드의 예시를 보자.
@Transactional
public ChallengeCommentLikeResponse addCommentLike(Long memberId, Long challengeId, Long commentId){
// 해당 챌린지에 참여 정보 조회
ChallengeParticipant participant = getChallengeParticipant(challengeId, memberId);
// 코멘트 조회 해오기
ChallengeComment comment = challengeCommentRepository.findById(commentId)
.orElseThrow(() -> new CIllegalArgumentException(ErrorDetail.ENTITY_NOT_FOUND);
// 좋아요 데이터 등록
int insertCount = challengeCommentLikeRepository.insertIgnoreByParticipantIdAndCommentId(
participant.getId(),
comment.getId()
);
if(insertCount == 1){ // 좋아요가 insert 된 경우
comment.updateLikeCount(+1); // 좋아요 개수 업데이트
}
return ChallengeCommentLikeResponse.of(comment); // 반영된 좋아요 개수 반환
}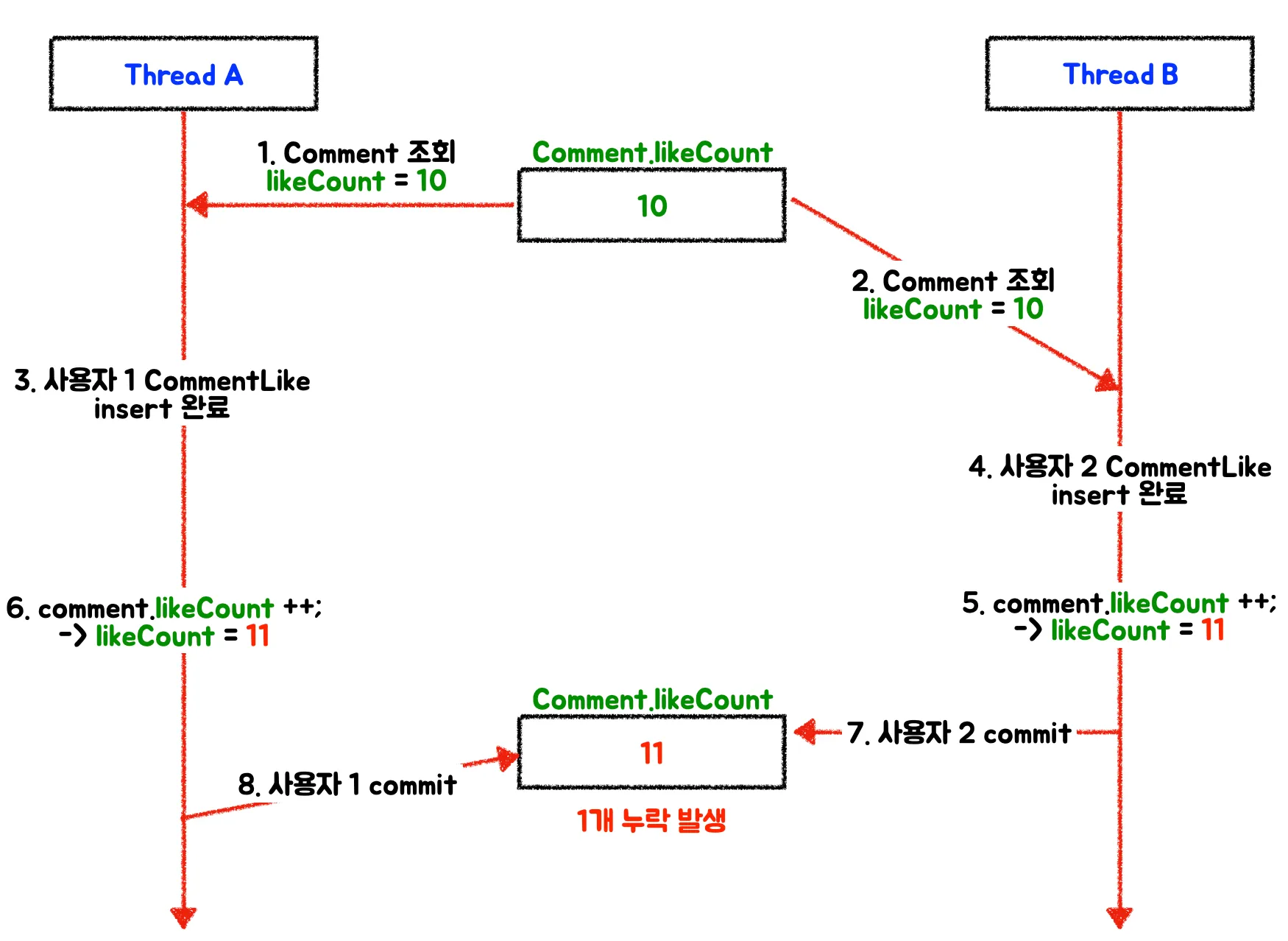
기존에 좋아요가 10개였던 코멘트에 대해 두 사용자가 동시에 좋아요를 눌렀다고 가정해보자.
Thread A와 Thread B가 동시에
Comment를 조회했다.두 Thread가 보고 있는
Comment의likeCount는 10이다.Thread B가 먼저 작업을 끝내고
likeCount++를 한 다음 commit 했다.
→ 10 + 1 = 11로 데이터베이스에 update 된다.이후에 Thread A가 작업을 끝내서
likeCount++를 한 다음 commit했다.
→ 10 + 1 = 11로 데이터베이스에 update 된다.실제 등록된 좋아요 수는 12개지만,
Comment에 업데이트 된likeCount는 11개로, 1개가 누락되었다.
race condition의 대표적 문제점인 lost update인 것이다.
두 개의 스레드가 하나의 동작을 요청해도 순서가 어떻냐에 따라 likeCount가 11이 될 수 있고 12가 될 수 있다.
동시성 문제 상황 재현하기
위 service 코드에 대해 동시성 문제가 재현될 수 있는 테스트코드를 작성했다.
동시에 100명의 사용자가 좋아요 등록 요청을 한다고 가정한다.
@Test
void 동시에_100번_좋아요를_누르면_likeCount가_유실될_수_있다() throws Exception {
// given
// challenge, team, writer, comment 세팅 후
int threadCount = 100; // 100명이 좋아요를 누른다고 가정
System.out.println("insert하려는 좋아요 개수=" + threadCount);
// 좋아요 누를 참여자들 100명 세팅
List<ChallengeParticipant> likers = challengeParticipantRepository.saveAll(
LongStream.rangeClosed(10_000, 10_000 + threadCount - 1)
.mapToObj(memberId -> TestFixture.createChallengeParticipantWithTeam(
challenge.getId(),
memberId,
team.getId(),
0,
0
))
.toList()
);
CountDownLatch start = new CountDownLatch(1); // 다같이 동시 시작을 위한 세팅
CountDownLatch done = new CountDownLatch(threadCount); // 100개 요청이 모두 처리될 때까지 대기하기 위한 세팅
ExecutorService pool = Executors.newFixedThreadPool(threadCount); // 스레드풀 100개 세팅
// when
for (ChallengeParticipant liker : likers) {
pool.submit(() -> {
try {
start.await(); // start가 0 될 때까지 대기함
challengeCommentService.addChallengeCommentLike(
liker.getMemberId(),
challenge.getId(),
comment.getId()
);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
} finally {
done.countDown(); // 각 스레드가 작업 끝날 때마다 cound를 줄여감
}
});
}
start.countDown(); // 메인 스레드가 start count를 1->0으로 줄임 -> 요청 100개 동시에 풀림
boolean finished = done.await(30, TimeUnit.SECONDS); // done count가 0이 되면 true 반환, 30초도안 기다렸는데도 안되면 false 반환
pool.shutdownNow(); // 스레드풀에 즉시 종료 요청
assertThat(finished).isTrue(); // 100개 요청들이 모두 잘 완료됐는지 검증
// then: 최신 상태로 검증하기 위해 clear + 새 트랜잭션에서 조회
int finalLikeCount = transactionTemplate.execute(status -> { // 코멘트 필드에 반영된 최종 좋아요 개수
em.clear();
ChallengeComment refreshed = challengeCommentRepository.findById(comment.getId()).orElseThrow();
return refreshed.getLikeCount();
});
long likeRows = challengeCommentLikeRepository.count(); // 테이블에 실제로 저장된 좋아요 개수
System.out.println("insert된 좋아요 row 수=" + likeRows + ", 코멘트에 반영된 최종 좋아요 수=" + finalLikeCount);
}
실행 결과, 코멘트 필드로 반영된 최종 좋아요 개수는 12개로 실제 좋아요 개수는 100개인데 정상적으로 필드에 반영된 상황은 12개 뿐이다.
정확하게 실제 코멘트 개수대로 Comment 필드에도 반영되려면 동시성 제어가 필수적이다.
동시성 제어 방법으로 크게 5가지를 고민했다.
1. 메서드에 synchronized 사용하기
2. 낙관적 락 사용하기
3. 비관적 락 사용하기
4. 분산 락 사용하기 (네임드 락)
5. update 쿼리 직접 날리기
1. 메서드에 synchronized 사용하기
Java의 synchronized는 메서드 레벨의 race condition을 제어해주는 키워드로, 이 키워드가 붙은 메서드에는 오로지 하나의 스레드만 접근할 수 있는 일종의 뮤텍스와 유사한 메커니즘이다.
@Transactional
public synchronized ChallengeCommentLikeResponse addChallengeCommentLike(Long memberId, Long challengeId, Long commentId) {
// 좋아요를 등록하는 로직
}단순히 메서드에 synchronized 키워드만 추가하고 동시성 테스트를 재실행했다. 이전에 12개만 반영되던 상황에서 50개까지 반영된 개수가 늘었다.
이전에 12개만 반영되던 상황에서 50개까지 반영된 개수가 늘었다.
하지만 여전히 100개가 온전하게 모두 반영된 것은 아니었다. 이유가 무엇일까?
Spring의 트랜잭션을 사용하는 환경이라면 synchronized도 완전하게 동시성을 제어할 순 없다.
Spring의 @Transactional가 붙은 메서드면 AOP의 service 프록시 객체가 감싸서 실행하기 때문이다.
class ChallengeCommentServiceTxProxy {
private ChallengeCommentService target;
private TransactionManager tx;
ChallengeCommentLikeResponse addChallengeCommentLike(memberId, challengeId, commentId) {
// 1) 트랜잭션 시작(또는 기존 트랜잭션 참여)
tx.begin();
// 2) 실제 서비스 메서드 호출 (synchronized 영역)
result = target.addChallengeCommentLike(memberId, challengeId, commentId);
// 3) 트랜잭션 커밋 (이때 flush -> SQL 실행 -> commit)
tx.commit();
return result;
}
}어디서 간극이 발생할까? 여러 개의 요청이 들어왔을 때 2번과 3번 사이 간극에서 다른 요청이 해당 Comment의 likeCount를 읽어갈 수 있다고 예상했다.

1-1. @Transactional 적용 간격 때문이 확실할까?
“synchronized의 완벽한 제어가 안되는 원인이 @Transactional 때문”이라는 검증을 해보고싶어서 동일한 비즈니스 로직을 수행하도록 코드를 일부 변경해 테스트했다.
왜 코드를 변경하는가? 라고 물어본다면, 지금 상태에서는 @Transactional 을 제거한 상태의 테스트가 불가능하다. @Transactional을 제거하기에는 addChallengeCommentLike() 내부 로직에서 데이터를 INSERT 하기 위해선 쿼리에 @Modifying이 필수이며, 이는 트랜잭션이 보장되어야 사용할 수 있다. Comment의 likeCount 또한 더티 체킹을 사용하고 있으므로, 트랜잭션의 commit이 발생하지 않는 이상 flush 되지 않아 변경사항이 데이터베이스에 반영되지 못한다.
그래서 아래는 좋아요를 직접 save 하고, unique 제약으로 인해 발생하는 exception은 일단 간단하게 Exception으로 잡아 바로 comment의 좋아요 개수를 반환하도록 수정했다. 또한, 기존의 Comment 좋아요 개수를 더티체킹으로 업데이트 했던 부분을 명시적 save 하도록 변경했다.
@Transactional
public synchronized ChallengeCommentLikeResponse addChallengeCommentLike(Long memberId, Long challengeId, Long commentId) {
ChallengeParticipant participant = getChallengeParticipant(memberId, challengeId);
ChallengeComment comment = challengeCommentRepository.findById(commentId)
.orElseThrow(() -> new CIllegalArgumentException(ErrorDetail.ENTITY_NOT_FOUND);
try { // 좋아요 엔티티를 생성해 save 하도록 코드 수정
challengeCommentLikeRepository.save(ChallengeCommentLike.builder()
.participantId(participant.getId())
.commentId(comment.getId())
.build()
);
} catch (Exception e) { // unique로 인해 save 안되면 바로 반환
return ChallengeCommentLikeResponse.of(comment);
}
comment.updateLikeCount(+1);
challengeCommentRepository.save(comment); // 명시적 flush
return ChallengeCommentLikeResponse.of(comment);
}일단 @Transactional 을 붙였을 때의 결과이다. 아까와 동일한 상황으로,
아까와 동일한 상황으로, synchronized를 붙였음에도 100개로 다 업데이트 되지 않고 50개가 누락됐다.
이제 @Transactional을 제거해보자.
100개가 누락되지 않고 완벽하게 업데이트 되었다.
정말 @Transactional이 붙었을 때 프록시 객체를 통해 트랜잭션을 수행하는 간극 사이에 누락이 발생한다는 점을 검증하게 되었다.
일단 기존에 의도했던 코드 베이스는 아까 말한 INSERT 쿼리의 @Modifying으로 인해 @Transactional과 synchronized를 모두 사용해선 동시성을 완전히 제어할 수는 없다.
1-2. synchronized의 치명적 단점
그리고 치명적인 단점으로는 분산환경에서 동시성 제어가 안된다는 점이다.
같은 JVM 내에 있는 스레드끼리는 락 상태가 공유되어 다른 스레드들이 접근할 수 없지만, 다른 서버는 다른 JVM이므로 이 락 상태를 공유할 수 없어 결국 동시성 문제가 똑같이 발생한다.
현재 우리 서버는 분산환경이므로 이 synchronized 방식을 적용할 수 없다.
2. 낙관적 락 (Optimistic Lock) 사용하기
낙관적 락이란 “충돌은 자주 나지 않는다”라는 낙관적 가정이 기반인 공유자원 처리 방식이다.
“누가 접근 안했겠지~” 하고 데이터를 그냥 읽어와서 처리를 다 한 후,
마지막에 커밋하기 전에 자원이 처음에 봤던 상태 그대로 있는지를 확인한다.
만약 달라져있다면 충돌이 발생했다고 판단해 실패처리한다.
데이터베이스 레벨의 실제 락은 걸지 않아 다른 스레드들과의 동시처리 성능은 좋다.
낙관적 락은 버저닝을 통해 판단한다.
내가 자원을 가져올 때 봤던 version이 커밋 시점 version과 달라지면 다른 스레드가 먼저 업데이트 했다고 판단하고 OptimisticLockException 예외를 발생시킨다.
낙관적 락의 메커니즘 정리는 아래와 같다.
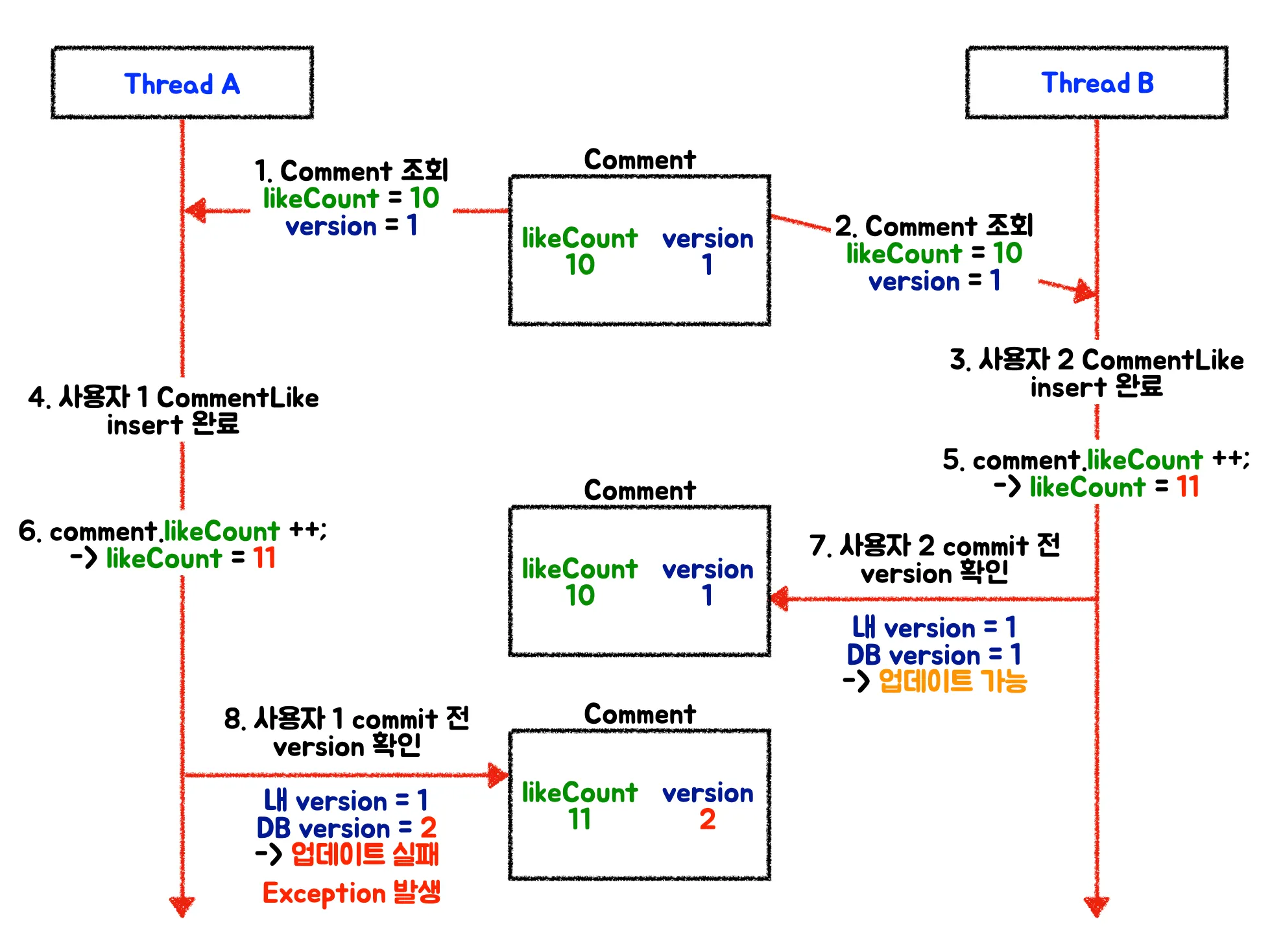
- 스레드 A, B 둘다 version = 1인 데이터를 조회했다.
- 스레드 B 트랜잭션이 변경사항 커밋을 먼저 시도한다.
- DB를 조회했을 때 해당 데이터의 version이 1이다.
내가 처음에 조회했던 version인 1과 일치해 version을 1 올리고 업데이트한다.- 이후 스레드 A가 변경사항 커밋을 시도한다.
- 스레드 A가 처음에 조회했던 version은 1인데 DB의 version은 2이므로 충돌 발생이라고 여겨 exception을 던진다.
이제 비즈니스코드에 낙관적 락을 도입해보자!
1️⃣ Entity에 version 필드 세팅
낙관적 락을 구현하기 위해서는 대상 테이블의 컬럼으로 version을 추가해야한다.
@Entity
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class ChallengeComment extends BaseEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Builder.Default
private int likeCount;
...
@Version // jakarta.persistence.Version
private Long version;
...
}@Version 애노테이션의 역할은 다음과 같다.
1. 자동으로 version 컬럼을 업데이트 해준다.
낙관적 락을 직접 구현하게 되면 해당 엔티티가 업데이트 될 때마다 아래처럼 version 확인 + version 업데이트를 하는 쿼리를 작성해야할 것이다.
UPDATE comment
SET like_count = :like_count, version = version + 1
WHERE id = :id AND version = :version하지만 @Version 을 붙여두면 JPA가 자동으로 version 확인 + version 업데이트를 진행해준다.
2. 필드를 변경한 트랜잭션 커밋 시점에 충돌이 감지되면 ObjectOptimisticLockingFailureException 을 발생시킨다.
충돌이 생기면 자동으로 ObjectOptimisticLockingFailureException을 발생시켜주지만, catch해서 후처리하는건 개발자의 몫이다.
2️⃣ Repository에서 조회할 때 @Lock(LockModeType.OPTIMISTIC) 걸기
해당 엔티티를 조회 해올 때 낙관적 락을 사용한다는 애노테이션이다.
public interface ChallengeCommentRepository extends JpaRepository<ChallengeComment, Long> {
@Lock(LockModeType.OPTIMISTIC)
@Query(value = "SELECT cc FROM ChallengeComment cc WHERE cc.id = :id")
Optional<ChallengeComment> findByIdWithOptimisticLock(Long id);
...
}3️⃣ Service에서 낙관적 락 사용하도록 수정하기
2번 repository 메서드를 호출하도록 수정만 하면 된다.
@Transactional
public ChallengeCommentLikeResponse addChallengeCommentLike(Long memberId, Long challengeId, Long commentId) {
ChallengeParticipant participant = getChallengeParticipant(memberId, challengeId);
// 낙관적 락 적용 후 조회하는 메서드로 변경
ChallengeComment comment = challengeCommentRepository.findByIdWithOptimisticLock(commentId)
.orElseThrow(() -> new CIllegalArgumentException(ErrorDetail.ENTITY_NOT_FOUND);
...
}4️⃣ Facade 패턴으로 락 점유 실패 시 재시도 로직 작성하기
이렇게 낙관적 락으로 업데이트를 시도했다가 version 불일치로 인한 업데이트 실패 시, 일정 횟수 재시도하는 로직을 추가해야한다.
Spring이 제공하는 @Retryable도 사용 가능하고, 아니면 try-catch로 직접 구현할 수도 있다.
나는 @Retryable을 사용해서 구현해봤다.
gradle에 아래처럼 의존성을 추가해야한다.
// @Retryable
implementation("org.springframework.retry:spring-retry")
implementation("org.springframework:spring-aspects")재시도 로직을 추가한 ChallengeCommentLikeFacade 를 생성했고,
내부에 ChallengeCommentService를 갖고있게 만들어서 재시도 가능하도록 호출했다.
@Service
@RequiredArgsConstructor
public class ChallengeCommentLikeFacade {
private final ChallengeCommentService challengeCommentService;
@Retryable(
include = ObjectOptimisticLockingFailureException.class,
maxAttempts = 10
)
@Transactional
public ChallengeCommentLikeResponse addChallengeCommentLike(Long memberId, Long challengeId, Long commentId) {
return challengeCommentService.addChallengeCommentLike(memberId, challengeId, commentId);
}
}처음에는 좋아요 insert랑 comment 필드 update 작업은 완전히 독립적이라고 생각했다.
그래서 재시도 로직을 짤 때 ‘update 로직까지 내려온거면 insert는 이미 보장된거니까 필드 update만 재시도 하면 되겠지?’ 라고 생각하고, 재시도 로직에는 Comment의 likeCount를 업데이트하는 로직만 넣었었다.
그런데 다시 생각해보니 낙관적 락 충돌로 인해 ObjectOptimisticLockingFailureException 예외가 발생하면, 이는 곧 본 작업의 트랜잭션 롤백으로 이어진다.
그래서 롤백 과정에서 insert 했던 좋아요까지 롤백되어 insert 보장이 안되는 것이다.
따라서 재시도 로직은 항상 실패했던 비즈니스 로직 자체를 원자적으로 재시도하도록 구성해야한다.
테스트에서도 ChallengeCommentLikeFacade 의 메서드를 호출하도록 수정했다.
(이래서 비즈니스 로직의 추상화가 필요하단 걸 깨달았다..)
변경 후 테스트 실행 시, 온전하게 100개의 좋아요 수가 성공적으로 반영됐다.

낙관적 락을 구현해보니 충돌 발생 시 후처리 / retry를 직접 구현해야 한다는 점이 정말 큰 단점으로 와닿았다..
또한 충돌 횟수가 많은 상황에서는 그만큼 재시도 횟수를 많이 올려야 성공적으로 동시성 제어가 될 것이다.
하지만 이는 곧 비즈니스 로직 전체를 N번 반복하는 것이므로, 실행 성능도 매우 좋지 못하다.
그래서 “충돌이 거의 발생하지 않는”라는 상황에서만 사용한다는 점이 이해가 갔다.
3. 비관적 락 (Pessimistic Lock) 사용하기
비관적 락은 “충돌은 자주 발생한다”는 비관적 가정을 기반으로 미리 DB 락을 거는 방식이다.
“누가 접근할 수 있다”라고 생각해, 처음부터 데이터베이스에서 변경하려는 데이터를 조회해올 때
row level로 lock을 걸고 다른 트랜잭션은 수정/접근하지 못하도록 한다.
락 획득에 실패한 트랜잭션은 일단 blocking waiting 하고,
lock_wait_timeout보다 오래 대기하면 timeout이 발생한다.
스프링에서는 @Lock(PESSIMISTIC_WRITE) 를 통해 비관적 락을 구현할 수 있다.
1️⃣ Repository에서 조회할 때 @Lock(LockModeType.PESSIMISTIC_WRITE) 걸기
public interface ChallengeCommentRepository extends JpaRepository<ChallengeComment, Long> {
@Lock(LockModeType.PESSIMISTIC_WRITE)
@Query(value = "SELECT cc FROM ChallengeComment cc WHERE cc.id = :id")
Optional<ChallengeComment> findByIdWithPessimisticLock(Long id);
...
}LockModeType 에 PESSIMISTIC_READ 가 있고 PESSIMISTIC_WRITE 가 있다.
PESSIMISTIC_READ: 읽기 용도로 비관적 락을 건다. (S lock)PESSIMISTIC_WRITE: 쓰기 용도로 비관적 락을 건다. (X lock)
지금 상황에서는 ChallengeComment의 likeCount 업데이트가 목적이기 때문에 PESSIMISTIC_WRTIE 을 건다.
위처럼 설정해주면 실제로 나가는 조회 쿼리는 다음과 같다.
SELECT cc
FROM ChallengeComment cc
WHERE cc.id = :id
FOR UPDATE; // 수정의 목적으로 조회함 (X-lock 조회)2️⃣ Service에서 비관적 락 메서드 호출로 변경하기
이렇게만 변경하면 끝이다!
@Transactional
public ChallengeCommentLikeResponse addChallengeCommentLike(Long memberId, Long challengeId, Long commentId) {
ChallengeParticipant participant = getChallengeParticipant(memberId, challengeId);
// 비관적 락 적용 후 조회하는 메서드로 변경
ChallengeComment comment = challengeCommentRepository.findByIdWithPessimisticLock(commentId)
.orElseThrow(() -> new CIllegalArgumentException(ErrorDetail.ENTITY_NOT_FOUND);
...
}비관적 락 적용 후 동시성 테스트를 진행했다. 모두 온전하게 잘 반영됨을 확인했다.

비관적 락은 동시처리 요청이 많이 들어올 경우, 일종의 줄세우기처럼 직렬처리를 수행하는 것이므로 트랜잭션의 대기 상태가 오래 지속될 수 있다. 이는 곧 병목지점이 될 가능성이 높다.
따라서 적절한 Timeout 정책이 필요하며 트랜잭션을 오래 붙잡고 있지 않도록 해주어야한다.
확실한 상호배제가 중요한 쿼리, 로직이라면 비관적 락이 좋은 선택이 될 것이다.
예를 들자면 좌석 예약이나 쿠폰 사용같이 혹여나 중복 처리가 발생해버리면 큰 비즈니스적 문제로 이어질 수 있는 경우들이다.
성공률을 올리는 대신 처리량을 희생하는 것이다.
4. 분산 락 (Distributed Lock) 사용하기 (네임드 락)
분산 락은 여러 프로세스/서버가 동시에 임계영역에 접근하지 못하게 공유 저장소로 락을 거는 방식이다.
여기서 공유저장소란 Redis, DB 같은 곳이 될 것이다.
분산 락 구현 방법으로 크게 생각나는건 두 가지였다.
- Redis를 통한 분산 락 구현하기
- MySQL에서 제공하는 네임드 락 활용하기
사실상 첫 번째는 고려사항에서 제외이다.
우리 서비스는 지금 Redis도 사용하지 않고 있어서, 이 동시성 제어를 위해 Redis를 도입하기엔 더 큰 비용이 들어 투자 대비 임팩트가 좋지 못하다.
그래서 사실상 선택지는 2번으로 확정되었다.
4-1. MySQL의 네임드 락 (Named Lock) 사용하기
MySQL 엔진 레벨에서 제공하는 네임드 락은 일종의 분산락”처럼” 사용할 수 있다.
(완전히 분산 락을 위한 구현체는 아니라고 한다!!)
네임드 락은 특정 문자열을 가진 락을 걸어두면, 다른 커넥션이 이 락을 점유하고자 시도했을 때 대기시키거나 실패시키는 원리이다.
네임드 락의 락은 DB 커넥션에 붙어있는 락이다.
그래서 트랜잭션의 commit/rollback과는 무관하고, 커넥션이 종료되어야 암묵적으로 락이 해제된다.
트랜잭션과 무관하므로 자동 락 획득/해제도 불가능하다. 락 획득/해제 과정도 개발자가 직접 구현해주어야 한다.
네임드 락에서 락을 획득/해제하는 쿼리는 다음과 같다.
SELECT GET_LOCK('update_query', 5); // 'update_query'라는 이름의 락 획득, 최대 5초 대기
SELECT RELEASE_LOCK('update_query'); // 'update_query'라는 이름의 락 해제1️⃣ Repository에 네임드 락 획득/해제 쿼리 추가하기
사실 네임드 락 획득/해제 쿼리는 엔티티들과 무관한 데이터베이스 자체 쿼리라서, JPA Repository를 사용하는 것보다 JdbcTemplate을 사용해서 구현하는게 더 올바를 것이라고 생각한다.
하지만 우리 서비스는 JdbcTemplate을 안쓰고 있으니 일단 JPA Repository에 욱여넣어서(?) 테스트 하기로 했다.
public interface ChallengeCommentRepository extends JpaRepository<ChallengeComment, Long> {
@Query(value = "SELECT GET_LOCK(:key, 5)", nativeQuery = true)
void getLockByKey(String key);
@Query(value = "SELECT RELEASE_LOCK(:key)", nativeQuery = true)
void releaseLockByKey(String key);
...
}2️⃣ Service에서 네임드 락 획득, 해제 추가하기
서비스 메서드의 앞뒤로 네임드 락을 획득하고 해제하는 로직을 추가해야한다.
// 4. 네임드 락
@Transactional
public ChallengeCommentLikeResponse addChallengeCommentLike(Long memberId, Long challengeId, Long commentId) {
String namedLockKey = "add_comment_like:" + commentId;
challengeCommentRepository.getLockByKey(namedLockKey); // 네임드락 획득
ChallengeParticipant participant = getChallengeParticipant(memberId, challengeId);
ChallengeComment comment = challengeCommentRepository.findById(commentId)
.orElseThrow(() -> new CIllegalArgumentException(ErrorDetail.ENTITY_NOT_FOUND);
int insertCount = challengeCommentLikeRepository.insertIgnoreByParticipantIdAndCommentId(
participant.getId(),
comment.getId()
);
if (insertCount == 1) {
comment.updateLikeCount(+1);
}
challengeCommentRepository.releaseLockByKey(namedLockKey); // 네임드락 해제
return ChallengeCommentLikeResponse.of(comment);
}이렇게 구현하고 테스트 했는데 아래처럼 일부 count 누락이 발생했다.
왜 발생했지..? 싶었는데 네임드 락 해제 시점과 트랜잭션 커밋 시점의 격차 때문에 발생한 문제인 것 같다.
지금 내 코드에서 트랜잭션의 begin/commit, 네임드 락의 획득/해제, 비즈니스 로직의 실행 순서를 보면 다음과 같다.
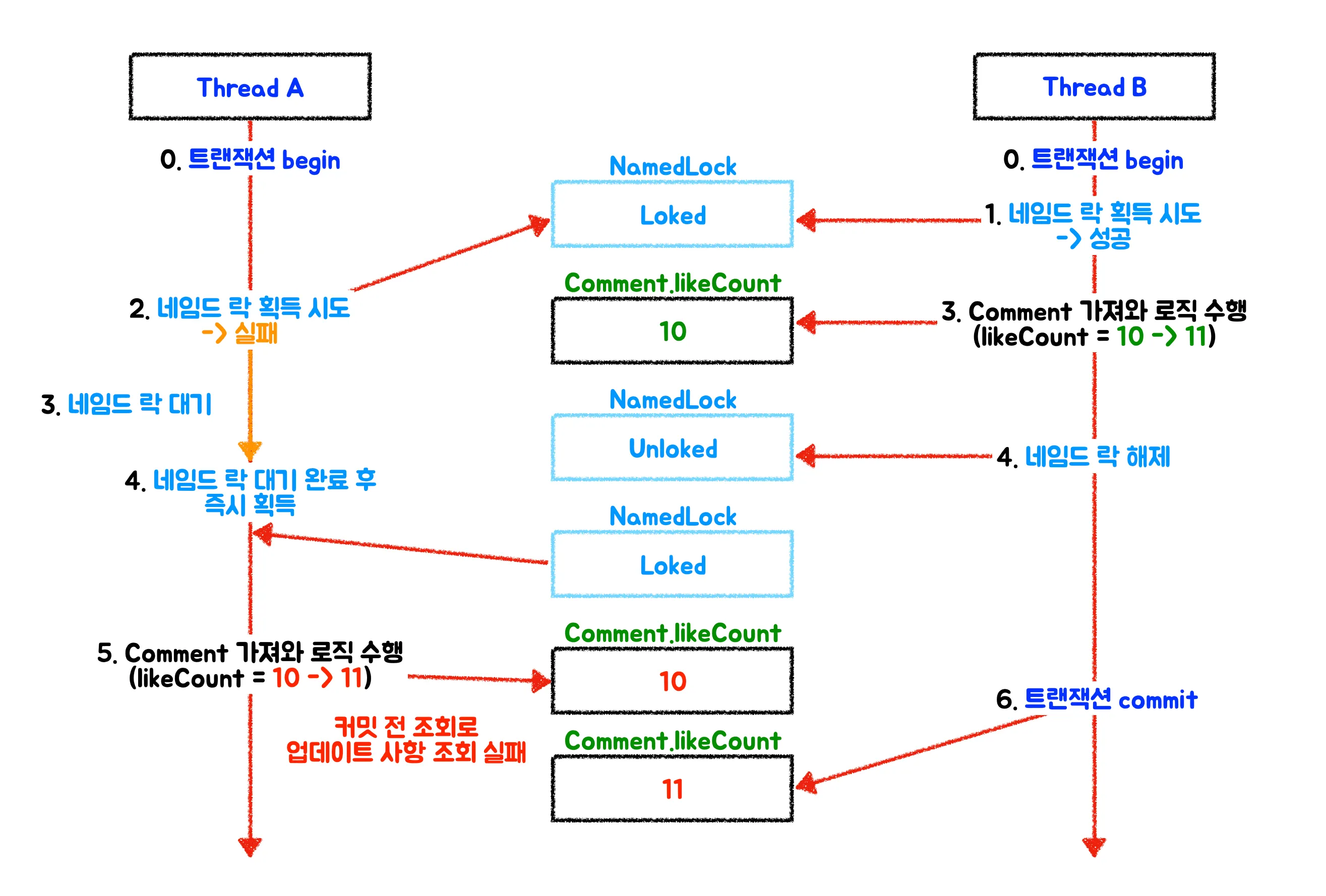
먼저 락을 얻었던 스레드가 네임드 락을 먼저 해제한 후, 변경 사항을 커밋하려고 한다.
그 사이에 다른 스레드가 네임드 락을 즉시 획득해서 이전 변경 사항이 커밋되기 전에 데이터를 조회해온 것이다.
결국 likeCount에 동일한 누락 현상이 발생한다.
그래서 비즈니스 로직의 트랜잭션을 네임드 락 획득/해제의 안쪽에 위치하도록 수행해야한다.
기존에 Service 비즈니스 로직은 그대로 두로, Facade에 네임드 락 획득/해제 로직으로 감싸준다.
@Service
@RequiredArgsConstructor
public class ChallengeCommentLikeFacade {
private final ChallengeCommentService challengeCommentService;
private final ChallengeCommentRepository challengeCommentRepository;
public ChallengeCommentLikeResponse addChallengeCommentLikeWithNamedLock(Long memberId, Long challengeId, Long commentId) {
String namedLockKey = "add_comment_like:" + commentId;
try {
// 네임드 락 획득 후
challengeCommentRepository.getLockByKey(namedLockKey);
// 비즈니스 로직 트랜잭션 수행
return addChallengeCommentLike(memberId, challengeId, commentId);
} finally {
// 예외 발생 상관없이 네임드 락 해제하기
challengeCommentRepository.releaseLockByKey(namedLockKey);
}
}
}락 해제와 트랜잭션 간 간극 문제가 맞았다! 이제 누락 없이 모두 업데이트 되었다.

네임드 락으로 분산 락을 구현해서 비즈니스 로직을 원자적으로 잘 수행했다.
하지만 아까 말했던 JPA Repository를 사용해서 구현해야한다는 점, 그리고 이를 위해 JdbcTemplate이나 native query를 실행할 계층 또는 repository 구현체를 추가해야한다는 점이 걸림돌이라고 느껴졌다.
5. 직접 Update 쿼리 작성하기
직접 UPDATE 쿼리를 작성하면 row level의 X-lock이 발생한다.
X-lock은 다른 트랜잭션이 S-lock, X-lock 모두 얻지 못하며, 데이터 수정을 위해 row를 독점한다.
1️⃣ Repository에 UPDATE 쿼리 추가하기
Repository에 UPDATE 쿼리를 직접 날리도록 메서드를 추가했다.
likeCount = likeCount + 1로 써도 되지만 나는 좋아요 취소에서도 재활용하고자 amount를 파라미터로 받도록 만들었다.
public interface ChallengeCommentRepository extends JpaRepository<ChallengeComment, Long> {
@Modifying(clearAutomatically = true)
@Query("UPDATE ChallengeComment SET likeCount = likeCount + :amount WHERE id = :commentId")
void updateLikeCount(Long commentId, int amount);
}✅
@Modifying옵션에는clearAutomatically와flushAutomatically가 있다.
clearAutomatically: 쿼리를 실행한 후 영속성 컨텍스를 clear 한다.
- 쿼리 실행 후 해당 엔티티를 다시 조회하게 될 때, 영속성 컨텍스트의 엔티티와 DB의 데이터가 동기화 되지 않는다.
- 따라서 영속성 컨텍스트를 비우고 다시 조회해오도록 할 때 사용하는 옵션이다.
flushAutomatically: 쿼리를 실행하기 전 영속성 컨텍스트의 변경사항을 모두 flush 한다.
- 같은 트랜잭션에서 이전에 변경한 것들이 flush 안되어 있을 수 있다.
- 이 때 반영된 최신 상태에서 지금의 쿼리를 수행해야 할 경우 사용하는 옵션이다.
지금 상태에서는 좋아요 개수 업데이트를 한 후 다시 코멘트 좋아요 수를 조회해야하므로 영속성 컨텍스트를 비우고자 clearAutomatically를 켰다.
같은 트랜잭션의 이전 작업들은 위 좋아요 업데이트와 독립적인 작업들이다.
따라서 flushAutomatically는 키지 않았다.
2️⃣ Service에서 UPDATE 메서드 사용하기
코멘트에 좋아요 개수 수정하는 부분만 repository 메서드로 바꿔주면 된다.
@Transactional
public ChallengeCommentLikeResponse addChallengeCommentLike(Long memberId, Long challengeId, Long commentId) {
ChallengeParticipant participant = getChallengeParticipant(memberId, challengeId);
ChallengeComment comment = challengeCommentRepository.findById(commentId)
.orElseThrow(() -> new CIllegalArgumentException(ErrorDetail.ENTITY_NOT_FOUND);
int insertCount = challengeCommentLikeRepository.insertIgnoreByParticipantIdAndCommentId(
participant.getId(),
comment.getId()
);
if (insertCount == 1) { // update 쿼리 직접 날리기
challengeCommentRepository.updateLikeCount(commentId, +1);
}
return ChallengeCommentLikeResponse.of(comment);
}누락없이 좋아요 개수가 모두 잘 반영됐다.

최종 비교 및 선택하기
1. synchronized
| 개념 | 장점 | 단점 |
|---|---|---|
| JVM에서 메서드 레벨로 제어하는 동시성 | 사용하기 간편 상호배제 보장 | 분산환경에서 사용 불가, @Transactional에서 사용시 온전한 동시성 보장 불가 |
synchronized는 사용하기 정말 편리했지만 현재 분산환경인 우리 서비스에서는 활용할 수 없는 방식이다. 또한 @Transactional이 필수인 메서드라 사용할 수 없어 제외했다.
2. 낙관적 락
| 개념 | 장점 | 단점 |
|---|---|---|
| 처음 가져온 락 버전과 데이터 변경 후 락 버전 비교 - 일치하면 충돌 X 판단 후 업데이트 - 일치하지 않으면 다른 트랜잭션과 충돌해 예외 발생 | DB 락을 오래 붙들고있지 않음 → 동시처리성 성능 좋음 | 충돌 발생 시 재시도 로직 직접 개발 필요, 재시도 횟수 및 충돌 횟수 따라 정합성 보장 안될 수 있음 |
낙관적 락은 재시도 횟수, 충돌 횟수에 따라 정합성 보장이 안될 수 있다는 점이 꽤 불안정하다고 생각했다.
또한 재시도 로직도 직접 개발을 해줘야 한다는 점에서도 단점이 느껴졌지만,
쓰기보다 읽기가 많은 우리 서비스에서는 어느정도 생각해볼만 방법이라 일단은 보류로 두었다.
3. 비관적 락
| 개념 | 장점 | 단점 |
|---|---|---|
| 데이터베이스 레벨에서 직접 row level lock 걸기 ( SELECT ~ FOR SHARE, FOR UPDATE) | DB 락이라 동시성 보장 확실 | 락 오래 붙잡고 있으면 트랜잭션 오래 유지 → 타 트랜잭션들도 오래 대기 |
비관적 락은 데이터베이스 락을 직접 걸어서 동시성 보장도 확실하게 되어서 안전해보였다.
비관적 락의 단점이 비즈니스 로직이 복잡해지면 락을 그만큼 오래 갖고있게 되는데,
우리 로직도 조회 → 삽입 → 업데이트까지 락을 갖고있는 상황이라,
이 또한 오래 점유하는 것일까봐 우려되어 보류했다.
4. 분산 락 - 네임드 락
| 개념 | 장점 | 단점 |
|---|---|---|
| MySQL에서 제공하는 커넥션 기반 문자열 락 - 락 점유한 커넥션이 작업 수행 - 타 커넥션이 락 점유하려고 하면 대기 후 타임아웃 | 비즈니스 로직 자체를 묶어서 원자적으로 락 걸기 가능 | 락의 자동 획득/해제가 없어서 직접 구현 필요 로직 단위 락이라 오래 점유 가능 |
분산 락을 네임드 락으로 구현하면, 긴 비즈니스 로직 작업 전체를 원자적으로 수행해야할 때 사용하면 좋을 것이다.
하지만 구현해보면서 락의 획득/해제 타이밍이 트랜잭션과 맞지 않다는 점이 불편하게 느껴졌다.
자동 락 획득/해제 로직이 없어서 직접 구현해야하고, 트랜잭션과 커넥션 간 격차를 세밀하게 제어해줘야했다.
또한 앞서 말했듯 네임드 락은 테이블 스키마와 상관없게 쿼리를 발생하는 로직이므로 JdbcTemplate을 사용하면 좋겠지만, 이를 위해 도입하는 것은 비용 대비 임팩트가 적다고 생각했다.
그래서 네임드 락은 동시성 후보에서 제외했다.
5. update 쿼리 직접 사용
| 개념 | 장점 | 단점 |
|---|---|---|
| update 쿼리 작성해 실행하면 X-lock이 걸려 타 트랜잭션의 update는 막음 | check-then-act 없이 원자적 처리 유용, 단순함 | 직속 쿼리 수행으로 영속성 컨텍스트와의 동기화 필요 |
MySQL에서 update 쿼리를 사용하면 row level의 X-lock으로 타 트랜잭션의 update를 막아 원자적 연산을 할 수 있다.
현재 우리 서비스에서 가장 간편하게 구현하고 동시성도 온전히 제어하기에 최적의 방법으로 생각했다.
영속성 컨텍스트와의 동기화는 단순 findById()로 조회해오면 됐기에, 그리 큰 비용이 아니라고 생각했다.
✅ 결론적으로는 "update 쿼리를 직접 사용"하는 방식이 가장 적절하다고 생각해 이 방식을 채택했다.
