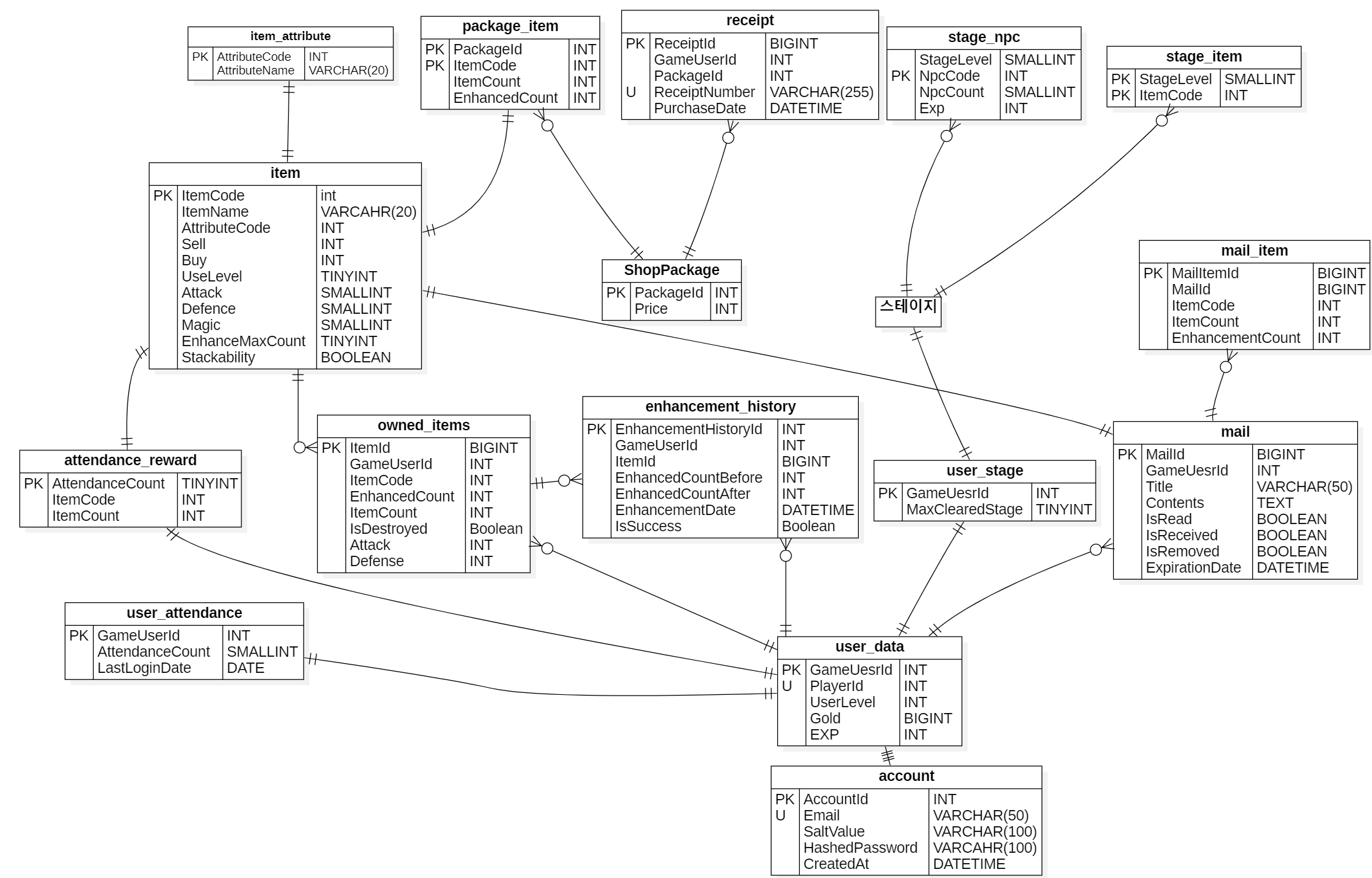
account
최하단의 account는 AccountDB에 있는 테이블입니다. account 외의 테이블은 GameDatabase에 존재합니다.
user_data
user_data는 GameUserId를 기본키로 가집니다.
- 계정이 생성될 때
AccountDB의AccountId를 입력받아PlayerId로 저장합니다. 실제 게임에서AccountDB는 분리되어 있는 경우가 많아서 분리되었다는 것을 강조하기 위해 위와 같이 지었습니다.
owned_item
처음 계획은 user_data 테이블에 아이템 코드별로 열을 추가하여 개수를 저장하려고 했습니다. 그러나 이런 방식은 열의 크기가 굉장히 커지며 다음과 같은 문제가 발생합니다:
- 유지 관리의 어려움: 하나의 테이블이 과도하게 커지면, 유지 관리가 어렵습니다.
- 새로운 아이템이 생기면 테이블의 속성을 수정해야 하는데 이는 비효율적인 작업입니다.
- 성능 저하: 열이 많아지면 데이터의 읽기 및 쓰기 시간이 증가합니다.
이 문제를 해결하기 위해, GameUserId를 포함하는 별도의 owned_items 테이블을 생성하였습니다. 초기에는 동일한 GameUserId가 반복적으로 나타나는 것이 어색하게 느껴 졌고 아이템 코드와 강화 수치 등 여러 속성을 사용해서 식별을 하다 보니 중복되는 상태를 갖는 아이템을 구별하지 못하는 문제가 생겼습니다.
mail에서 비슷한 문제를 겪고 ItemId를 추가해 개별 아이템에 대한 고유 식별이 가능한 테이블 구조가 완성되었습니다.
처음 생각한 것은 다음과 같습니다.
gameUserId만으로는 유일성이 보장되지 않기 때문에, 모든 열을 기본 키로 포함하려 할 경우 복잡성이 증가합니다. gameUserId를 통해 조회가 가능한 상황에서 MailID는 불필요하다고 생각했습니다.
데이터베이스를 처음 사용하면서 당연한 것도 어색하게 느껴지는 부분이 많았습니다.
그러나 목록 페이지당 최대 개수 기능을 생각하다 보니 MailID가 필요하다는 것을 깨달았습니다.
실장님께서 카페 게시물과 유사하다는 것에서 힌트를 얻었습니다. 게시글에 고유한 ID가 있는 것이 생각이 났고 살펴본 게시글의 특징은 다음과 같습니다.
- 지속적인 ID 증가
- 한 페이지에 제한된 수 표현
MailID가 계속 증가하면 20개씩 분리된 묶음에 포함되는 ID 값을 추정할 수 있습니다.
1. 첫 페이지 = 최근 메일 ID ~ 최근 메일 ID -19
2. ID를 20씩 감소시켜 다음 20개의 메일을 조회할 수 있습니다.
MailID를 기본 키로 설정하고 auto increment로 설정했습니다.
mail_item
user_data에서 owned_items 를 분리한 경험을 토대로 mail에서 mail_items를 분리하였습니다.
해당 테이블은 메일에 첨부될 수 있는 아이템을 위한 테이블입니다.
아이템을 식별하기 위해 필요한 요소로
- ItemCode
- EnhancementCount
를 설정하였고 Gold나 Potion과 같은 아이템이 여러 개 동시에 취득 될 수 있는 상황을 고려하여
-
ItemCount
를 추가하였습니다. 또한, 해당 아이템이 어떤 메일에 속해 있는지 식별하기 위해
MailId와, 메일 아이템 자체를 식별하기 위한MailItemId도 추가하였습니다.
이후 추가적인 고민이 생겼습니다.
반 정규화
데이터의 중복을 줄이는 정규화와 데이터베이스 접근 시 성능 간의 선택에 대한 고민이었습니다.
정규화하여 여러 테이블을 통해 데이터를 조회하는 경우 성능이 저하될 것이라 생각했고,
반대로 단일 테이블에 데이터를 저장하면 불필요한 데이터 접근이 늘어나는 딜레마에 직면했습니다.
결국 클라이언트에게 어떤 데이터를 제공해야 하는지 고려하여 결정을 내렸습니다.
클라이언트가 처음 로그인했을 때, 기본 데이터를 전송받는데 이때 유저에게 전달되는 데이터를 user_data에 유지하고, 그 외 데이터는 특정 요청에 필요한 데이터끼리 묶어서 별도의 테이블에 저장하였습니다.
테이블 크기가 감소함에 따라 유지보수성이 향상되었고, 요청 시 분리된 테이블에 접근하도록 함으로써 불필요한 데이터 접근을 줄일 수 있었습니다.
다시 코드를 검토해보니 메일 아이템 테이블은 메일에 통합하는 것이 좋아 보입니다.
MailList요청과 ReceiveMailItem요청에서 두 테이블에 접근하고 있습니다. 두 가지 요청에서 모두 요구하는 데이터(mail, mail item)고 다른 요청과 크게 연관된 부분이 없습니다.
그래서 반 정규화를 하면 불필요한 데이터베이스 접근을 막을 수 있습니다.
돌아보며
이번 학기에 데이터베이스 수업과 서버캠퍼스 1기의 일정이 겹쳐, 불가피하게 데이터베이스 강의를 수강 취소하게 되었습니다.
하지만 데이터베이스 지식이 필요했고 OT를 했던 4월 11일부터 서버캠퍼스 시작일 4월 18일 전까지 1주일 간 공부했습니다.
이렇게 급하게 학습을 하느라 놓치는 부분이 존재했고 데이터베이스 설계에 어려움을 겪었습니다. 그럼에도, 이론적 지식의 중요성을 다시금 깨닫는 중요한 계기가 되었습니다.
제 4 정규형
제대로 된 데이터베이스 이론의 이해가 있었다면, 아이템 정보를 어떻게 저장할지 고민했던 시간, owned_item 테이블을 만들기까지 걸린 시간을 단축할 수 있었을 것입니다.
BCNF 정규형 까지는 책에서 학습하였으나, 제 4 정규형 부터는 책에 명시되어 있지 않았고 이를 충분히 찾아보지 못했습니다.
제 4 정규형이 다치 종속성을 제거하는 것을 보며, 이런 정규화 과정이 user_data에서 owned_item을 분리하는 과정과 유사하다는 것을 느꼈습니다.
