MySQL 내부 아키텍처 & SQL 실행 흐름
- MySQL의 전체 구조를 이해한다
- SQL 쿼리가 어떻게 실행되는지 처음부터 끝까지 추적할 수 있다
- 각 단계별 성능 영향을 이해한다
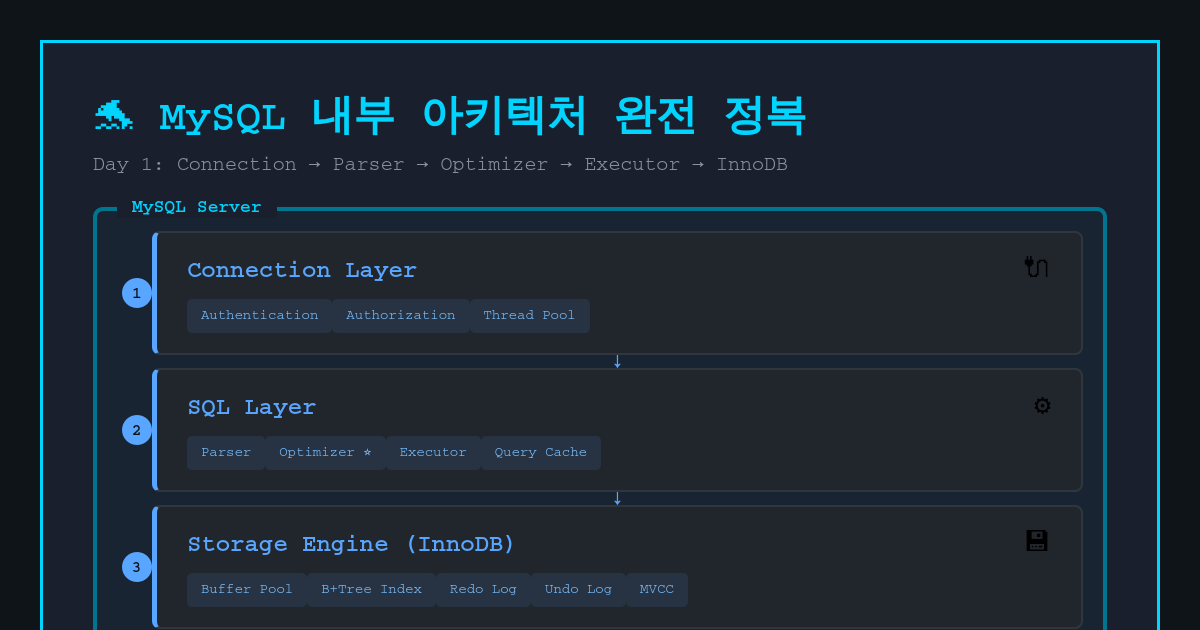
MySQL 아키텍처 개요
┌─────────────────────────────────────┐
│ Client (JDBC, CLI, etc.) │
└──────────────┬──────────────────────┘
↓
┌─────────────────────────────────────┐
│ MySQL Server Layer │
│ ├─ Connection Handler │
│ ├─ SQL Parser │
│ ├─ Optimizer │
│ ├─ Query Cache (8.0에서 제거됨) │
│ └─ Query Executor │
└──────────────┬──────────────────────┘
↓
┌─────────────────────────────────────┐
│ Storage Engine Layer │
│ ├─ InnoDB (주로 사용) │
│ ├─ MyISAM │
│ └─ Memory, etc. │
└─────────────────────────────────────┘SQL 실행과정 개요(Write)
INSERT INTO users (name, email) VALUES ('Chu', 'Chu@test.com');실행 단계:
1. Connection Handler
↓ 인증 & 권한 확인
2. Query Parser
↓ SQL 문법 분석 (Syntax Tree 생성)
3. Preprocessor
↓ 테이블/컬럼 존재 여부, 권한 재확인
4. Optimizer
↓ 실행 계획 수립 (Write는 단순)
5. Storage Engine (InnoDB)
↓ a. Undo Log 작성 (롤백 대비)
↓ b. Buffer Pool에서 데이터 페이지 찾기/로드
↓ c. 데이터 수정 (Dirty Page 생성)
↓ d. Redo Log 작성 (크래시 복구용)
6. Transaction Commit
↓ Redo Log를 디스크에 플러시
7. Background Thread
↓ 나중에 Dirty Page를 디스크에 기록MySQL 전체 구조 이해하기
MySQL의 3계층 아키텍처
- Client Layer JDBC Driver, MySQL CLI, MySQL Workbench …..
- MySQL Server Layer
- Connection Management & Thread Handling
- Connection Pool
- Authentication & Authorization
- SQL Interface
- SQL 명령어 처리
- Stored Procedure, Trigger, View 관리
- Parser(구문 분석기)
- Lexical Analysis (어휘 분석)
- Syntax Analysis (구문 분석)
- Parse Tree 생성
- Optimizer (최적화기)
- Cost-based Optimization
- 실행 계획 수립
- 인덱스 선택
- Join 순서 결정
- Cache & Buffer (MySQL 8.0에서 Query Cache 제거)
- Executor (실행기)
- Storage Engine API
- Connection Management & Thread Handling
- Storage Engine Layer
- InnoDB(Default)
- 트랜잭션, MVCC, Row Lock, 외래키
- MyISAM(구버전)
- 트랜잭션X, Table Lock, 빠른 읽기
- Memory(임시용)
- 메모리 Only, 빠르지만 휘발성
- InnoDB(Default)
레이어의 역할 상세 분석
Connection Layer(Connection Management & Thread Handling)
- 클라이언트 연결 수락
- 인증 (Authentication)
- 사용자 이름, 비밀번호 확인
- 연결 허용 IP 체크
- 권한 부여 (Authorization)
- SELECT, INSERT, UPDATE, DELETE 권한
- 데이터베이스별, 테이블별 권한
- 쓰레드 관리
- 각 연결마다 별도 쓰레드 할당
- Connection Pool로 재사용
실제동작
mysql -h localhost -u root -p- TCP 3306 포트로 연결 수신
- mysql.user 테이블에서 인증 정보 조회
- 비밀번호 해시 비교
- 권한 정보 로드(mysql.db, mysql.tables_priv)
- 쓰레드 할당
- welcome 메시지 전송
Parser(구문 분석기)
SQL 문자열을 MySQL이 이해할 수 있는 구조로 변환
// 입력
SELECT id, name FROM users WHERE age > 23;
// step1: Lexical Analysis (어휘 분석) -> 토큰 분리
[SELECT] [id] [,] [name] [FROM] [users] [WHERE] [age] [>] [23] [;]
// step2: Syntac Analysis(구문 분석) -> 문법 규칙 확인
SELECT_STATEMENT
- SELECT_LIST
- COLUMN : id
- COLUMN : name
- FROM_CLAUSE
- TABLE: users
- WHERE_CLAUSE
- CONDITION: age > 23
// step3: Parse Tree 생성
Query
|
SELECT_STMT
/ | \
FIELDS FROM WHERE
/ \ | |
id name users age>23
→ 잘못된 SQL 문은 Parser 가 체크
→ 존재하지 않는 테이블 → Parser 통과 → Preprocessor에서 에러 발생!
Optimizer(최적화기) ⭐ 중요!
어떻게 실행할 것인가? 를 결정
- 가장 빠른 실행 경로 찾기
- 비용 기반 최적화 (Cost-based Optimization)
판단 기준
- 각 인덱스의 Cardinality(고유값 비율)
- 예상 반환 행 수
- 인덱스 크기
- I/O 비용 계산
Optimizer가 사용하는 정보
- 통계정보 -> ANALYZE TABLE users;
- 확인 가능한 통계 -> SHOW TABLE STATUS LIKE ‘users’;
- 인덱스 고유값 개수 -> SHOW INDEX FROM users;Optimizer가 하는 결정들 예시
- 인덱스 선택
SELECT * FROM users WHERE age = 23 AND city = 'Seoul'- idx_age 사용
- idx_city 사용
- idx_age_city 사용 (복합 인덱스)
- Full Table Scan
→ city는 몇개 안되고 age는 많으므로 idx_city로 좁힌 후 age 필터링
- Join 순서
SELECT *
FROM users U
JOIN orders o ON u.id = o.user_id
JOIN products p ON o.product_id = p.id
WHERE u.age > 30- 순서 A : users → orders → products
- 순서 B : users → products → orders
- 순서 C : orders → users → products 등등..
Optimizer의 선택
- users에서 age > 30 필터링 (10만 → 2만 행)
- orders와 Join (2만 * 평균 5개 주문 = 10만행)
- products와 Join (10만 * 1개 = 10만행)
→ orders 부터 하면 전체 100만 행 부터 처리 해야할수도 있음
- 서브쿼리 최적화
SELECT *
FROM users
WHERE id IN (SELECT user_id FROM orders WHERE total > 1000);
// Optimizer 변환
SELECT u.*
FROM users u
JOIN orders o ON u.id = o.user_id
WHERE o.total > 1000;Executor(실행기)
Optimizer가 만든 실행계획을 실제로 수행 → Storage Engine API를 호출하여 데이터 처리
- Optimizer의 계획 “users 테이블에서 idx_age 인덱스로 age = 25 찾기”
- Executor의 실행
-
Storage Engine에 요청: idx_age 인덱스
handler → index_init(idx_age)
-
age = 25 인 행 찾아줘
handler → index_read(key = 25)
-
다음행 있음?
handler → index_next()
-
없으면 중단
→ 종료
-
모든 행을 클라이언트에 전송
-
SQL 실행과정
SELECT 문
SELECT name, email
FROM users
WHERE age = 23
ORDER BY created_at DESC
LIMIT 10;- Connection Handler
- 클라이언트 연결확인
- 권한 확인 → users 테이블 SELECT 권한
- Parser
- SQL 문법 분석
- Parse Tree 생성
- 문법 오류 체크
- Preprocessor
- users 테이블 존재확인
- name, email, age 컬럼 확인
- 권한 재확인
- Opimizer ⭐
- 분석
- age 칼럼에 idx_age 인덱스 확인
- age = 23인 행 (2000개인 경우)
- 전체 행(10만개)
- 인덱스 사용이 유리
- 실행 계획
- idx_age 인덱스로 age = 23 검색
- created_at DESC 정렬
- 상위 10개 선택
- name, email 칼럼만 반환
- 분석
- Executor → Storage Engine
- InnoDB API 호출
- handler → index_read(idx_age, 23)
- InnoDB가 처리
- Buffer Pool(InnoDB 메모리 캐시, 데이터 페이지) 에서 검색
- 없으면 디스크에서 로드
- B+Tree(자료구조, O(log n), 균형트리) 인덱스 탐색
- 2000개 행 반환
- created_at 정렬
- sort_buffer(정렬 작업용 메모리, ORDER BY, GROUP BY 시 사용)로 충분
- 디스크 임시파일 불필요
- 상위 10개 선택
- InnoDB API 호출
- Result Set 전송
- 10개 행을 클라이언트에 전송
- 네트워크 프로토콜로 패킷 생성
INSERT 문
INSERT INTO users(name, email, age)
VALUES ('Chu', 'Chu@test.com', 23);1~3. Connection, Parse, Preprocess는 SELECT와 동일
-
Optimizer
- INSERT는 최적화 단순
- 제약조건 확인, 계획 수립(UNIQUE 인덱스, 외래키)
-
InnoDB 트랜잭션 시작
-
Undo Log 작성 (롤백 대비)
- 행이 추가될 경우 삭제로 롤백
- ibdata1 또는 별도 undo 파일
-
Buffer Pool에서 페이지 찾기
- users 테이블의 마지막 페이지 없으면 디스크에서 로드
- 16KB 페이지 단위
-
데이터 페이지에 행 삽입
- 페이지 내부 Linked List 수정
- Row 포맷에 맞게 인코딩
- 이 페이지는 이제 Dirty Page
-
인덱스 업데이트
- PRIMARY KEY(id) 인덱스
- UNIQUE (email) 인덱스
- idx_age 인덱스
- idx_created 인덱스
- 각각 B+Tree에 새 엔트리 삽입
-
Redo Log 작성 (WAL(디스크 쓰기 전 로그부터 쓰는것) 방식)
- 페이지 X에 Y를 삽입함
- id_logfile0, ib_logfile1에 기록
- 순차적 쓰기 (매우 빠름)
- 크래시 복구 보장
-
-
COMMIT 처리
- Redo Log를 디스크에 플러시 (fsync(메모리 → 디스크 강제 동기화 시스템 콜, 트랜잭션 안정성))
- 트랜잭션 확정
- 크래시되어도 복구 가능
- Binary Log 기록
- Replication을 위한 로그
- 다른 서버로 전송
- Redo Log를 디스크에 플러시 (fsync(메모리 → 디스크 강제 동기화 시스템 콜, 트랜잭션 안정성))
-
Background 처리
-
Dirty Page Flush
- Buffer Pool → 디스크
- Checkpoint 시점에 일괄 처리
- I/O 최적화
-
Undo Log 정리
- 오래된 버전 제거
- Purge Thread(Undo Log 청소 담당 Thread)가 담당
-
실습
SET profiling = 1;Profiling vs Performance Schema
- Profiling - 가벼운 실험도구 동작방식
-
세션 레벨로 동작 (
SET profiling = 1) -
실행된 쿼리와 각 단계별 시간 기록
-
SHOW PROFILES,SHOW PROFILE FOR QUERY n;확인장점
-
설정 간단
-
바로바로 눈으로 보기 쉬움
-
학습용으로 적합
-
- performance_schema - 정교한 모니터링 엔진 동작 방식
-
performance-schema데이터베이스 내 여러 테이블을 통해 쿼리 실행 정보를 수집 -
MySQL이 내부적으로 쿼리 실행의 모든 단계를 event로 추적
장점
-
운영 환경에서도 사용 가능
-
쿼리 외에도 IO, CPU, 메모리 Lock 등 전부 추적 가능
-
MySQL Workbench, Grafana 등 외부 툴이 이를 기반으로 시각화
단점
-
초반에 데이터 구조가 복잡하게 느껴짐
-
기본적으로 꺼져 있을 수도 있어서 활성화 설정 필요
-
테이블 생성 & 더미 데이터 삽입
-- 테이블 생성
CREATE TABLE users (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(100),
email VARCHAR(100),
age INT,
INDEX idx_age (age)
) ENGINE=InnoDB;
-- 10만 건 데이터 생성 프로시저
DELIMITER $$
CREATE PROCEDURE gen_data(IN num INT)
BEGIN
DECLARE i INT DEFAULT 1;
WHILE i <= num DO
INSERT INTO users VALUES (
i,
CONCAT('user', i),
CONCAT('user', i, '@test.com'),
20 + (i % 50)
);
SET i = i + 1;
END WHILE;
END$$
DELIMITER ;
-- 생성 (30초 소요)
CALL gen_data(100000);DELIMITER $$- 문장 구분자 변경 (MySQL이;과 혼동하는 것을 방지CREATE PROCEDURE- 프로시저 정의 시작DECLARE- 변수 선언WHILE- 반복문SET- 변수값 변경CALL gen_data(100000)- 프로시저 실행
인덱스 성능 - 핵심컬럼
SELECT COUNT(*) FROM users WHERE name = 'user50000';
SELECT COUNT(*) FROM users WHERE age = 25;
| Query_ID | Duration | Query
| 100006 | 0.02376075 | SELECT COUNT(*) FROM users WHERE name = 'user50000' |
| 100007 | 0.00139775 | SELECT COUNT(*) FROM users WHERE age = 25
EXPLAIN SELECT * FROM users WHERE name = 'user50000';
+----+-------------+-------+------------+------+---------------+------+---------+------+-------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+-------+----------+-------------+
| 1 | SIMPLE | users | NULL | ALL | NULL | NULL | NULL | NULL | 99858 | 10.00 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+-------+----------+-------------+
EXPLAIN SELECT * FROM users WHERE age = 25;
+----+-------------+-------+------------+------+---------------+---------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+---------+---------+-------+------+----------+-------+
| 1 | SIMPLE | users | NULL | ref | idx_age | idx_age | 5 | const | 2000 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+---------+---------+-------+------+----------+-------+-
Type
성능 좋은순
- System/const ← 단일 행 (최고)
- eq_ref ← Primary/Unique Key Join
- ref ← 일반 인덱스 (2번 쿼리)
- range ← 범위 검색 (BETWEEN, >, <)
- index ← 인덱스 풀 스캔
- ALL ← 테이블 풀 스캔 (1번 쿼리)
-
Key
실제 사용된 인덱스 이름
- NULL → 인덱스 안 씀 (1번 쿼리)
- idx_age → idx_age 인덱스 사용 (2번 쿼리)
-
rows
검사할 예상 행 수
- 99858 ← 거의 전체
- 2000 ← 2%만
-
Extra
빠름
-
Using index ← 커버링 인덱스
-
NULL ← 깔끔
느림
-
Using filesort ← 디스크 정렬
-
Using temporary ← 임시 테이블
-
Using where ← 추가 필터 (1번 쿼리)
-
-
select_type
- SIMPLE: 단순 쿼리
- SUBQUERY: 서브 쿼리
- UNION: UNION 쿼리
-
possible_keys
사용가능한 인덱스 목록
- filltered WHERE 조건으로 필터링된 비율 100%면 전부 조건 만족
INNODB STATUS
SHOW ENGINE INNODB STATUS\G- LOG
Log sequence number 66135635 Log buffer assigned up to 66135635 Log buffer completed up to 66135635 Log written up to 66135635 Log flushed up to 66135635 Added dirty pages up to 66135635 Pages flushed up to 66135635 Last checkpoint at 66135635-
Log sequence number ← 현재까지 쓴 로그
-
Log flushed up to ← 디스크에 쓴 로그
-
Last checkpoint at ← 실제 데이터 쓴 시점
→ 셋이 같은 경우 Drity Page 없음
-
-
Buffer Pool
Total large memory allocated 0 Dictionary memory allocated 554450 Buffer pool size 8191 <- 전체 8191 페이지 Free buffers 6329 <- 비어있음: 6329 Database pages 1856 <- 사용중 1856 Old database pages 665 Modified db pages 0 <- Dirty Page: 0 Pending reads 0 Pending writes: LRU 0, flush list 0, single page 0 Pages made young 0, not young 0 0.00 youngs/s, 0.00 non-youngs/s Pages read 1088, created 768, written 2488 0.00 reads/s, 0.00 creates/s, 0.00 writes/s No buffer pool page gets since the last printout Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s LRU len: 1856, unzip_LRU len: 0 I/O sum[0]:cur[0], unzip sum[0]:cur[0]- 사용률 = 1856 / 8191 → 22.6%
- 페이지 크기 8191 x 16KB → 128 MB, 사용중 1856 x 16KB → 29MB
- Modified db pages = 0 ← Dirty Page 없음
-
ROW OPERATIONS
0 queries inside InnoDB, 0 queries in queue 0 read views open inside InnoDB Process ID=1, Main thread ID=281472078507776 , state=sleeping Number of rows inserted 100000, updated 0, deleted 0, read 206000 0.00 inserts/s, 0.00 updates/s, 0.00 deletes/s, 0.00 reads/s Number of system rows inserted 31, updated 348, deleted 8, read 5152 0.00 inserts/s, 0.00 updates/s, 0.00 deletes/s, 0.00 reads/s- INSERT → 10만 건, READ → 20.6만 건
- 0.00 inserts/s, 0.00 reads/s 현재 초당 0건
INSERT문 사용
INSERT INTO users VALUES (100001, 'test', 'test@test.com', 30);
INSERT INTO users VALUES
(200001, 'a', 'a@test.com', 30),
(200002, 'b', 'b@test.com', 31),
(200003, 'c', 'c@test.com', 32);
+----------+------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Query_ID | Duration | Query |
+----------+------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| 100012 | 0.00925475 | INSERT INTO users VALUES (100001, 'test', 'test@test.com', 30) |
| 100013 | 0.00507650 | INSERT INTO users VALUES (200001, 'a', 'a@test.com', 30),
(200002, 'b', 'b@test.com', 31),
(200003, 'c', 'c@test.com', 32)- 단건 INSERT x 1 → 9.25 ms x3 → 27.75ms → fsync에서 병목 데이터 → Redo Log → fsync 데이터 → Redo Log → fsync 데이터 → Redo Log → fsync → 3번 fsync
- 배치 INSERT x 3 → 5.07 ms 모아서 → Redo Log → fsync (1번)
