MySQL
1.MySQL 공부 1 - MySQL 아키텍처 및 실행 흐름
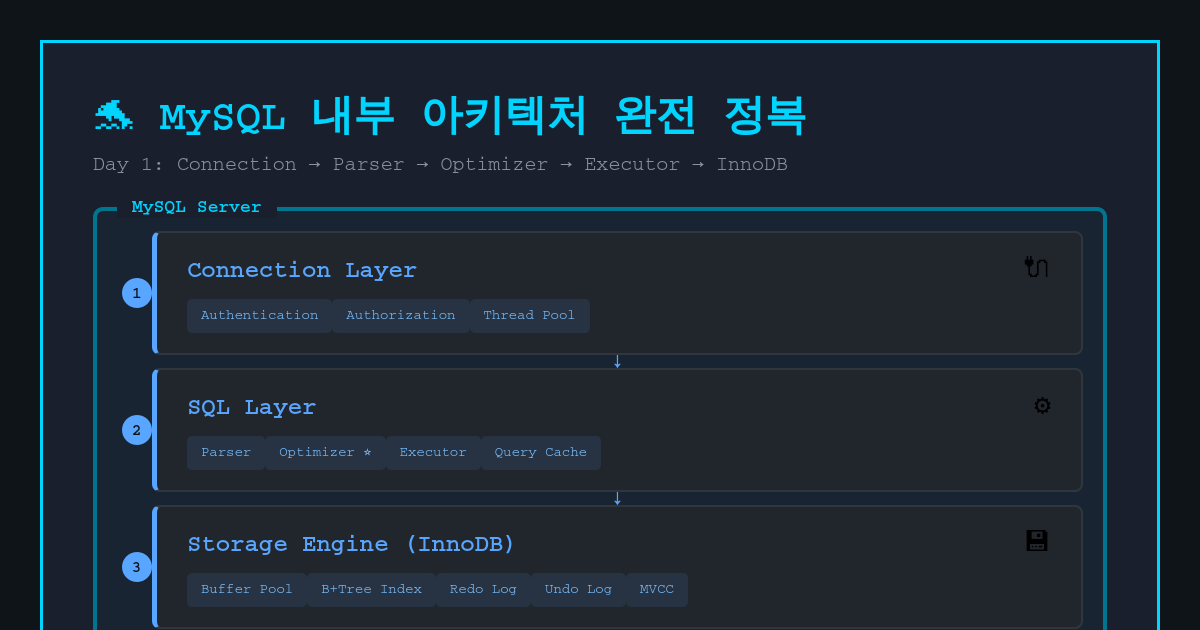
목표 : MySQL의 전체 구조를 이해한다 SQL 쿼리가 어떻게 실행되는지 처음부터 끝까지 추적할 수 있다, 각 단계별 성능 영향을 이해한다
2.MySQL 공부 2 - InnoDB 스토리지 엔진 분석

InnoDB Buffer Pool의 내부구조와 동작 원리 Redo Log와 WAL(Write-Ahead Logging) 매커니즘 Undo Log와 MVCC(Multi-Version Concurrency Contorl)Write 프로세스 살펴보기실습
3.MySQL 공부 4 - 격리 수준, Lock, B+Tree
이번 편에서는 트랜잭션 격리 수준과 Lock 메커니즘, 그리고 인덱스의 근간이 되는 B+Tree를 다룬다.격리 수준은 동시성과 일관성의 트레이드오프를 조절하는 도구다
4.MySQL 공부 3 - Redo Log, Undo Log, MVCC 심화
핵심 역할을 하는 세 가지를 깊게 파고든다. 데이터를 잃지 않게 해주는 WAL과 Redo Log, 롤백과 동시성을 가능하게 하는 Undo Log, 그리고 락 없이 읽기/쓰기가 동시에 가능한 이유인 MVCC다.
5.MySQL 공부 5 - JPA 영속성 컨텍스트와 Proxy, Lazy Loading
4편에서 격리 수준, Lock, B+Tree를 다뤘다. 이번 편은 레이어를 한 단계 올려서 JPA가 어떻게 DB 접근을 최적화하는지, 그리고 Proxy와 Lazy Loading이 왜 존재하는지를 다룬다.
6.MySQL 공부 6 - N+1 문제와 해결 전략, Query Plan Cache, Batch Fetching 내부 구현
5편에서 영속성 컨텍스트와 Proxy, Lazy Loading을 다뤘다. 이번 편에서는 Lazy Loading의 구조적 문제인 N+1을 어떻게 해결하는지, 그리고 쿼리 실행 최적화를 위한 Query Plan Cache와 Batch Fetching 내부 동작을 파고든다.
7.MySQL 공부 7 - JPA 엔티티 생명주기 완전 분석
6편에서 N+1 문제와 해결 전략을 다뤘다. 이번 편에서는 JPA 엔티티가 어떤 상태를 거치며 관리되는지, 그리고 각 상태 전환 시 내부에서 무슨 일이 일어나는지를 파고든다.
8.MySQL 공부 8 - JPQL 내부 동작 원리, QueryDSL, Native Query
7편에서 엔티티 생명주기를 다뤘다. 이번 편에서는 실제로 쿼리가 어떻게 처리되는지 JPQL 내부 동작부터 파고든다. 그리고 JPQL의 한계를 보완하는 QueryDSL과 Native Query를 함께 정리한다.
9.MySQL 공부 9 - 실제 적용: EXPLAIN 분석, N+1 해결, 쿼리 최적화 실전
8편에서 JPQL 내부 동작과 QueryDSL, Native Query를 다뤘다. 이번 편에서는 이론을 실제 코드에 적용한 사례들을 정리한다. EXPLAIN으로 인덱스 효과를 확인하고, 실제 프로젝트에서 발생한 N+1을 여러 방법으로 해결하면서 성능을 비교한 내용이다.