
1. 서론
안녕하세요.
데이터 엔지니어링 & 운영 업무를 하는 중 알게 된 지식이나 의문점들을 시리즈 형식으로 계속해서 작성해나가며
새로 알게 된 점이나 잘 못 알고 있었던 점을 더욱 기억에 남기기 위해 글을 꾸준히 작성 할려고 합니다.
Spark의 경우 Spark 완벽 가이드 책을 많이 참고하여 운영을 하고 있습니다.
반드시 글을 읽어 주실 때 잘 못 말하고 있는 부분은 정정 요청 드립니다.
저의 지식에 큰 도움이 됩니다. :)
2. Spark 란?

Spark 는 Driver 와 Executor 로 이루어진 데이터 분산 병렬 처리 도구 입니다. Spark 자체로는 엔진과 구동 클라이언트로 구성이 돼 있습니다.
별도의 Spark 클러스터를 구성하여 동작시킬 수 있으며, 기존의 Container orchestration 클러스터(Kafka or Yarn) 에서 별도 클러스터 구축 없이 동작 가능합니다.
아래는 Apache Spark 공식 문서에서의 간략한 설명입니다.
"Apache Spark is a unified analytics engine for large-scale data processing. It provides high-level APIs in Java, Scala, Python and R, and an optimized engine that supports general execution graphs. It also supports a rich set of higher-level tools including Spark SQL for SQL and structured data processing, MLlib for machine learning, GraphX for graph processing, and Structured Streaming for incremental computation and stream processing."
Spark 은 데이터 병렬 분산 처리 엔진이라고 보는게 맞는 듯 합니다.
그래서 이 Spark 을 사용하기 위해서는 활용 로직을 작성하실 필요가 있습니다.
Spark 은 아래 4가지 언어로 구동이 가능합니다.
- R
- Python
- Scala
- Java
실제로 현업에서 대표적으로 사용되고 있는 언어들은 주로 Python 과 Scala 일 텐데요.
저의 경우에는 주로 데이터 파이프라인을 만들 때 통계 함수(ex. scipy) 라이브러리를 활용한 DL/ML 쪽 데이터 전처리 또는 배포 전 psedo code 수준에서 Python 을 활용하여 Spark 을 구동시킵니다.
그리고 배포 단계 때는 Scala 로 포팅하거나 처음 부터 스칼라로 프로젝트를 진행합니다. 특히 JDBC 를 활용(MERGE INTO | Spark 에서는 Upsert 를 지원하지 않기 때문에 직접 JDBC로 구현해야 합니다.)하거나 UDF 를 활용하는 작업들은 스칼라로 구성하는게 편하고 성능을 보장합니다.
3. Spark 구성
스파크는 보통 yarn 위에서 사용이 많이 되는데요. (kubernetes 는 Spark 3 버전 부터 GA 입니다.) 클러스터 기반에서 동작을 가정으로 아래와 같이 동작을 합니다.
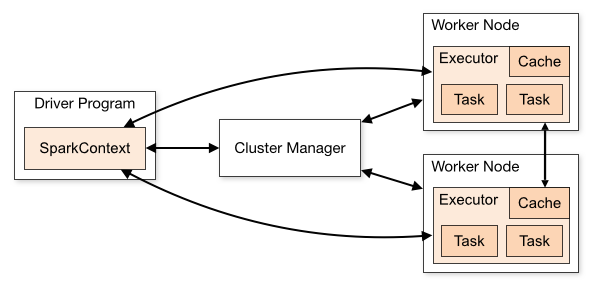
spark-submit 이 설치 된 클라이언트에서 클러스터로 매니저를 통해 각 워커노드들로 executor 라는 컨테이너들을 생성 시켜 데이터를 병렬 분산 처리합니다.
이 과정을 상당히 간단하게 명령어로 구성할 수 있는데요.
spark-submit \
--master yarn \
--deploy-mode cluster \
--queue etl \ # yarn 옵션
--py-files libs.zip \
etl1.pymaster 옵션에 클러스터를 넣어 주고 위의 driver 프로그램을 deploy-mode 옵션을 통해서 어디서 뛰울지 정해준 후 작성한 파일을 넣고 돌려주면 분산 병렬 처리를 시작합니다.
이 때 executor의 갯수, CPU, Memory 사이즈 / driver 의 CPU, Memory 사이즈를 지정할 수 있는 옵션이 존재합니다.
이를 활용하여 클러스터의 전체 용량을 계산하여 대용량 데이터를 병렬 분산 하는 방법을 잘 고려해보면 좋을 듯 합니다.
아래는 해당 구성에서 나오는 용어를 설명 드리겠습니다.
- driver : 프로그램의 main() 메소드가 실행되는 프로세스를 말합니다. 드라이버는 SparkContext를 생성하고 RDD를 만들고 트랜스포메이션과 액션을 실행하는 사용자 코드를 실행하는 프로세스 입니다. 스파크 셸을 실행할 때 이미 드라이버 프로그램을 만듭니다.(스파크 셸은 미리 로딩된 sc라고 불리는 SparkContext 객체를 갖고 시작한다) 드라이버가 종료되면 애플리케이션도 종료됩니다.
-
executor : 주어진 스파크 작업의 개별 태스크들을 실행하는 작업 실행 프로세스 입니다. 익스큐터는 스파크 애플리케이션 실행시 최초 한번 실행되며 대개 애플리케이션이 끝날 때까지 계속 동작하지만, 익스큐터가 오류로 죽더라도 스파크 애플리케이션은 계속 실행됩니다. 익스큐터는 두가지 역할을 합니다. 첫번째로 애플리케이션을 구성하는 작업들을 실행하여 드라이버에 그 결과를 되돌려 줍니다. 두번째로 각 익스큐터 안에 존재하는 블록 매니저라는 서비스를 통해 사용자 프로그램에서 캐시하는 RDD를 저장하기 위한 메모리 저장소를 제공합니다. RDD가 익스큐터 내부에 직접 캐시되므로 단위 작업들 또한 같이 실행되기에 용이 합니다.
-
Cluster Manager : 흔히들 아는 YARN, Kubernetes, Mesos 클러스터를 관리하는 매니저를 뜻합니다.
참고 사이트 : https://12bme.tistory.com/437
4. Spark Config
저는 Spark 을 사용할 때 아래와 같이 Config 을 설정하여 운영 중입니다.
더 효율적인 방법을 찾아가는 중이며, 만약 더 좋은 제안이 있다면 꼭 공유가 됐으면 합니다.
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
# Default system properties included when running spark-submit.
# This is useful for setting default environmental settings.
# Example:
# spark.master spark://master:7077
# spark.eventLog.enabled true
# spark.eventLog.dir hdfs://namenode:8021/directory
# spark.serializer org.apache.spark.serializer.KryoSerializer
# spark.driver.memory 5g
# spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"
spark.master yarn
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoopclustername/user/spark/log
spark.history.fs.logDirectory hdfs://hadoopclustername/user/spark/log
spark.history.provider org.apache.spark.deploy.history.FsHistoryProvider
spark.history.ui.port 18088
spark.lineage.enabled true
spark.sql.hive.metastore.jars path
spark.sql.hive.metastore.jars.path file:///opt/apps/hive-3.1.2/lib/*
spark.sql.hive.metastore.version 3.1.2
spark.sql.hive.metastore.sharePrefixes org.postgresql
spark.driver.extraClassPath file:///opt/apps/spark-3.2.3/jars/*
spark.executor.extraClassPath file:///opt/aps/spark-3.2.3/jars/*
spark.yarn.jars local:/opt/apps/spark-3.2.3/jars/*
spark.yarn.historyServer.address=http://{sparkhistoryserver}:180885. 결론
현재 대용량 데이터 분산 병렬 처리 어플리케이션을 작성할 때 가장 표준이 돼 가고 있는 프레임워크가 아닌가 싶습니다.
간단한 ETL 부터 ML/DL 까지도 Spark 을 활용하여 구성할 수 있다는 점이 매우 매력적인데요.
Spark 을 뛰어 넘고 자리 매김할 프레임워크가 또 어떤게 나올지 오히려 더 기대가 되는 듯 합니다.
