
1. 시작말
안녕하세요.
데이터 엔지니어링 & 운영 업무를 하는 중 알게 된 지식이나 의문점들을 시리즈 형식으로 계속해서 작성해나가며
새로 알게 된 점이나 잘 못 알고 있었던 점을 더욱 기억에 남기기 위해 글을 꾸준히 작성 할려고 합니다.
Spark의 경우 Spark 완벽 가이드 책을 많이 참고하여 운영을 하고 있습니다.
반드시 글을 읽어 주실 때 잘 못 말하고 있는 부분은 정정 요청 드립니다.
저의 지식에 큰 도움이 됩니다. :)
2. Spark Streaming 란?
언제 발생할 지 모르는 데이터를 수집하고 전처리하기 위해서는 주기적으로 데이터를 가져오는 방식을 취하는 방법도 있지만, 실시간이거나 실시간에 가깝게 배치 주기를 짧게 잡는 방법도 있습니다.
Spark Streaming 은 기본적으로 이런 데이터를 실시간에 가깝게 배치 주기를 짧게 잡는 방법으로 데이터를 실시간 요구사항을 맞춰내는 방법을 제공합니다.
Spark Streaming 은 아래 2가지 API로 Stream 처리를 지원하고 있습니다.
1. Spark Streaming(DStreams)

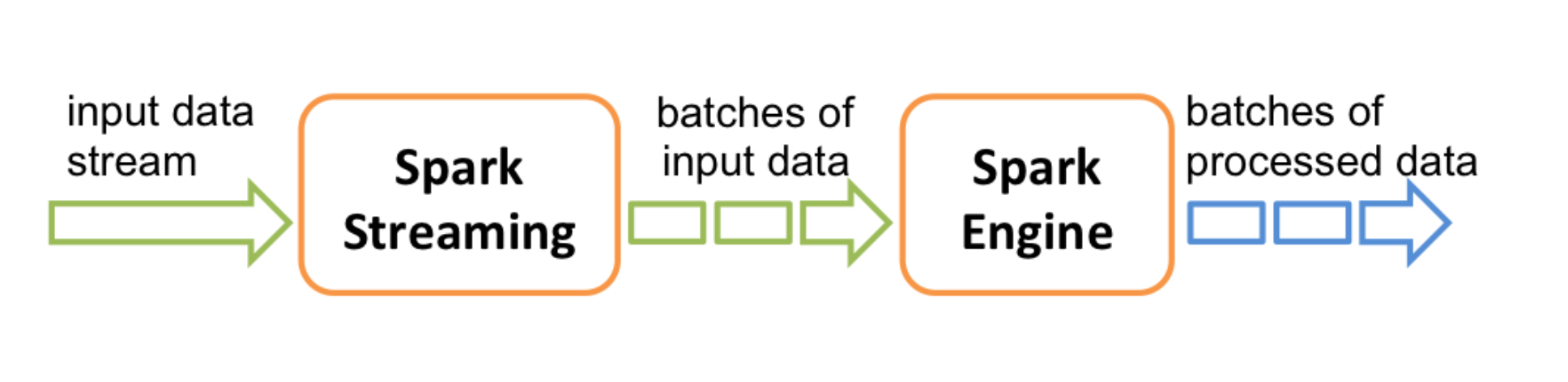
이미지 출처 : Spark 3.2.3 공식 Documentation - Spark Streaming Programming Guide
저수준 API 로 Streaming 데이터를 rdd로 받아서 데이터를 처리할 수 있도록 지원합니다. 기본적으로 rdd 로 데이터를 처리하기 때문에 개발자의 손을 많이 탈 수 있습니다.
2. Structured Streaming
이미지 출처 : Spark 3.2.3 공식 Documentation - Structured Streaming Programming Guide
고수준 API를 지원하며 DataFrame, DataSet 을 지원합니다. 개발자는 Stream 데이터를 처리할 때 RDD 가 아닌 DataFrame 으로 데이터를 처리할 수 있기 때문에 조금 더 간단하게 처리할 수 있습니다.
저는 보통 처리하기가 용이한 Structured Streaming API 를 활용해서 데이터를 처리하는데, Structured Streaming 의 데이터 처리 방식을 조금 더 알아보겠습니다.
3. Structured Streaming 데이터 수집
Sturectured Streaming 의 공식 Documentation 의 overview 는 다음과 같습니다.
"Structured Streaming is a scalable and fault-tolerant stream processing engine built on the Spark SQL engine. You can express your streaming computation the same way you would express a batch computation on static data. The Spark SQL engine will take care of running it incrementally and continuously and updating the final result as streaming data continues to arrive. You can use the Dataset/DataFrame API in Scala, Java, Python or R to express streaming aggregations, event-time windows, stream-to-batch joins, etc. The computation is executed on the same optimized Spark SQL engine. Finally, the system ensures end-to-end exactly-once fault-tolerance guarantees through checkpointing and Write-Ahead Logs. In short, Structured Streaming provides fast, scalable, fault-tolerant, end-to-end exactly-once stream processing without the user having to reason about streaming. ..."
Stream 간의 조인을 실행할 수 있는 것 또한 DataFrame으로 데이터를 처리하는 덕분에 가능하고, SQL 을 활용하여 데이터를 처리할 수 있습니다.
기본적인 Structured Streaming 은 마이크로 배치로 데이터를 처리하고 있는데요.
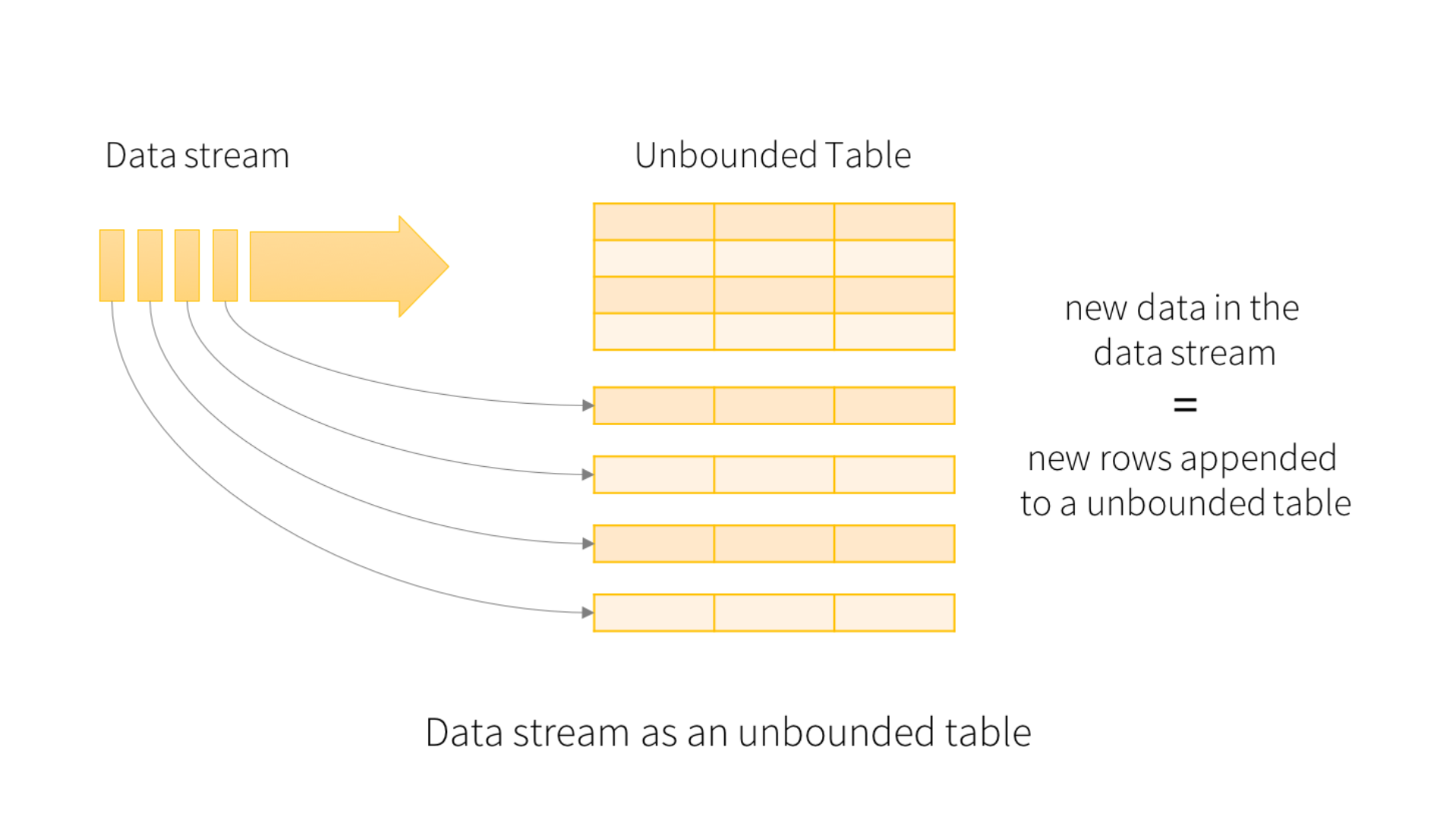
아래 그림을 한 번 더 보면서 이해를 할 수 있으면 좋을 듯 합니다.
이미지 출처 : Spark 3.2.3 공식 Documentation - Structured Streaming Programming Guide
Kafka 나 기타 실시간으로 데이터를 전달하는 Queue 에서 데이터를 가져오게 되면, 그림과 같이 Stream Data 를 Unbounded Table 로 변환하여 지속적으로 마이크로 배치를 실행 후 테이블에 쌓는 방식으로 데이터를 처리할 수 있도록 제공합니다.
이렇게 데이터를 마이크로 배치를 활용하여 Queue 에 데이터를 가져올 수 있지만, Offset을 어떻게 설정하냐에 따라 데이터를 가져올 수 있는 방법은 달라질 수 있습니다.
예를 들어 아래와 같이 Offset option 을 잡아준다면 그림과 같이 계속해서 Queue 에 존재하는 데이터를 가져오는 방식을 취하게 됩니다.
from pyspark.sql import SparkSession
spark = SparkSession.builder().appName("test").getOrCreate()
df = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "host1:port1,host2:port2") \
.option("subscribePattern", "topic.*") \
.option("startingOffsets", "earliest") \
.option("endingOffsets", "latest") \
.load() \
df.selectExpr("cast(Key AS String)", "cast(Value as String)").show()startingOffsets 은 가져올 데이터의 첫 시작점에 대해 지정하는 옵션입니다. 만약 earliest 를 넣게 된다면 Topic 의 가장 첫 데이터 부터 가져오게 됩니다.
그리고 endingOffsets 은 가져올 데이터의 가장 마지막 부분에 대해 지정하는 옵션입니다. 만약 latest 를 넣게 된다면 Topic 의 현재 가장 마지막 데이터까지 가져오게 됩니다.
그러나 Streaming 데이터는 계속해서 새로운 데이터를 처리해야 하는 경우가 많습니다.
그럴 경우 아래와 같이 Offset 만 잘 지정해준다면 계속해서 새로운 데이터를 처리할 수 있게 됩니다.
from pyspark.sql import SparkSession
spark = SparkSession.builder().appName("test").getOrCreate()
df = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "host1:port1,host2:port2") \
.option("subscribePattern", "topic.*") \
.option("startingOffsets", "latest") \
.load() \
df.selectExpr("cast(Key AS String)", "cast(Value as String)").show()뿐만 아니라 maxOffsetsPerTrigger 옵션을 활용하여 1회 Polling 시 얼마만큼의 데이터를 가져올 수 있는지 정할 수도 있습니다.
Spark Streaming 옵션 참고: Spark 3.2.3 공식 Documentation - Structured-streaming-kafka-integration
4. Structured Streaming 이벤트 처리 방식
Spark Structured Streaming 에서 데이터 수집과 전처리는 다른 모듈을 활용하는 것은 아닌데요.
데이터를 처리하는 이벤트가 발생했을 때 어떻게 데이터를 처리하는지를 아래 그림을 보면 알 수가 있습니다.
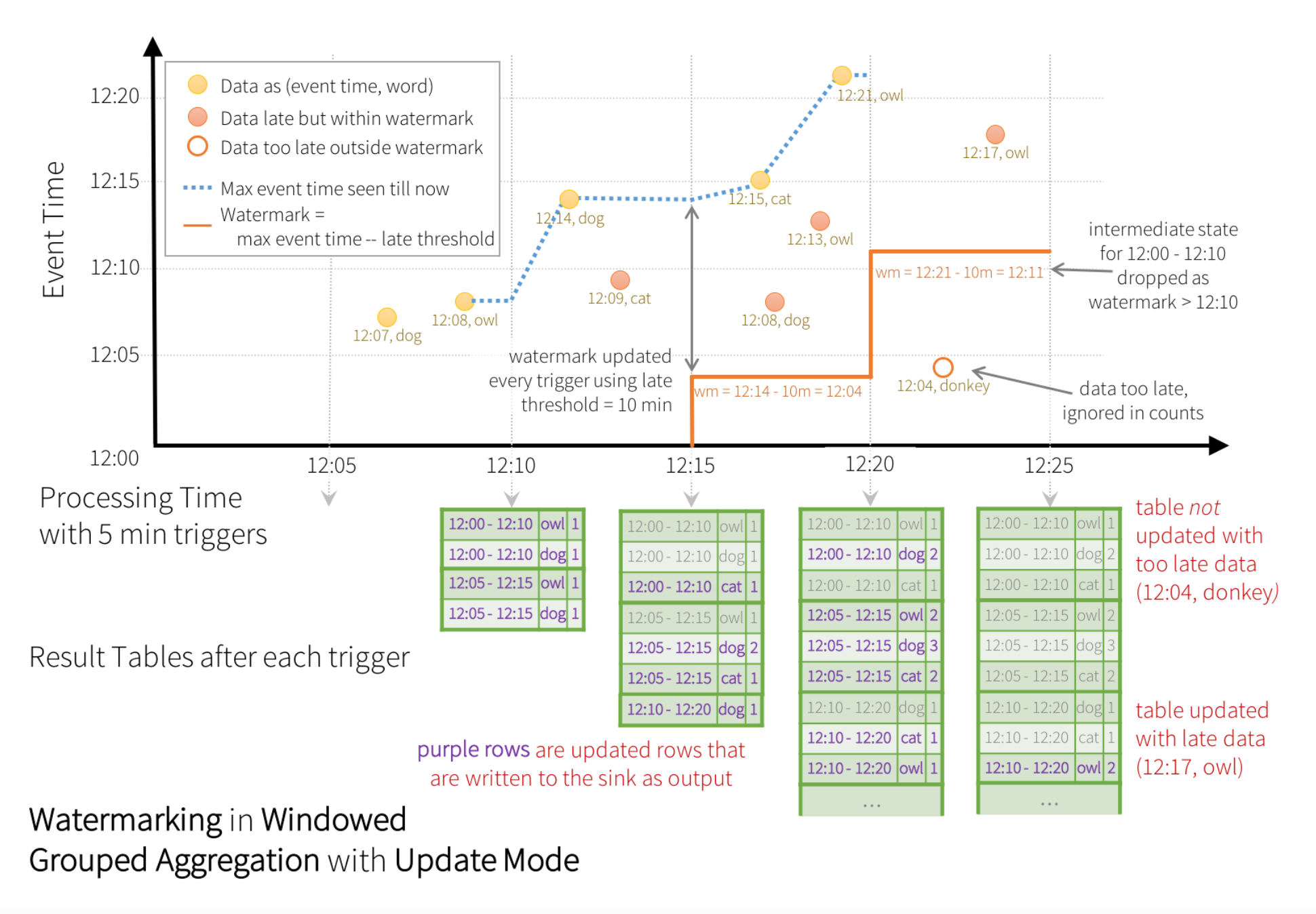
이미지 출처 : Spark 3.2.3 공식 Documentation - structured-streaming-programming-guide
Spark Structured Streaming 에서는 Trigger 를 지정하여 데이터를 원하는 간격으로 처리할 수 있게 구성할 수 있습니다.
위의 그림은 5분 간격으로 데이터를 처리하도록 구성하여 watermark 를 통해 이벤트를 넘어선 이전 데이터까지 처리할 수 있는 능력을 보여주고 있습니다.
앞의 데이터를 수집하는 코드는 아래와 같습니다.
from pyspark.sql import SparkSession
spark = SparkSession.builder().appName("test").getOrCreate()
df = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "host1:port1,host2:port2") \
.option("subscribePattern", "topic.*") \
.option("startingOffsets", "latest") \
.load() \
df.selectExpr("cast(Key AS String)", "cast(Value as String)").show()그러나 데이터 처리 이벤트를 발생 시키는 구문은 아래와 같이 작성을 해줘야 합니다.
# 5분 주기로 데이터를 처리합니다.
def process_batch(df, batch_id):
df.groupby("animal").count()
query = df \
.writeStream \
.outputMode("append") \
.foreachBatch(process_batch) \
.trigger(processingTime="5 minutes") \
.start()
query.awaitTermination()실제로 데이터 처리 이벤트 주기에 맞춰 데이터가 수집되는 것처럼 보이지만 readStream 과 writeStream 은 내부에서 별도로 동작하며 처리됩니다.
이를 통하여 실시간으로 데이터 수집을 할지는 몰라도 이벤트 처리는 별도의 이벤트를 받아 처리할 수 있음을 알 수가 있습니다.
5. 맺음말
Spark Streaming 에서 제공하는 실시간 처리 방법은 마이크로 배치를 이용하여 처리를 하지만 서비스를 하기에는 충분한 간격인듯 합니다.
저도 Structured Streaming 을 활용하여 데이터를 수집, 전처리, 저장 하고 있지만 상당히 코드를 작성하기도 편하고 성능도 만족스럽습니다.
다음에는 동일 Group ID 를 가진 Spark App 들을 한 Topic 의 여러 파티션에 물려서 테스트를 해본 결과를 공유 드려보고 싶습니다.
