
1. 시작말
안녕하세요.
데이터 엔지니어링 & 운영 업무를 하는 중 알게 된 지식이나 의문점들을 시리즈 형식으로 계속해서 작성해나가며
새로 알게 된 점이나 잘 못 알고 있었던 점을 더욱 기억에 남기기 위해 글을 꾸준히 작성 할려고 합니다.
Spark의 경우 Spark 완벽 가이드 책을 많이 참고하여 운영을 하고 있습니다.
반드시 글을 읽어 주실 때 잘 못 말하고 있는 부분은 정정 요청 드립니다.
저의 지식에 큰 도움이 됩니다. :)
2. Github Template Repository
- Python
SK(Spark-Kafka) Streaming Python Template Repository 링크
- Scala Github Template Repository
3. Spark Structured Streaming Template
업무를 하면서 Spark Structured Streaming 을 활용하여 Kafka 를 Sink 할 일이 많을 듯 하여 코드 템플릿을 만들었습니다.
개발과 운영을 함께 하고 있기 때문에 약속 된 형식을 활용할 수록 코드의 유지 보수나 패치 시 수월해져서 템플릿 구성을 계획했습니다.
기본적으로 구조는 아래와 같습니다.
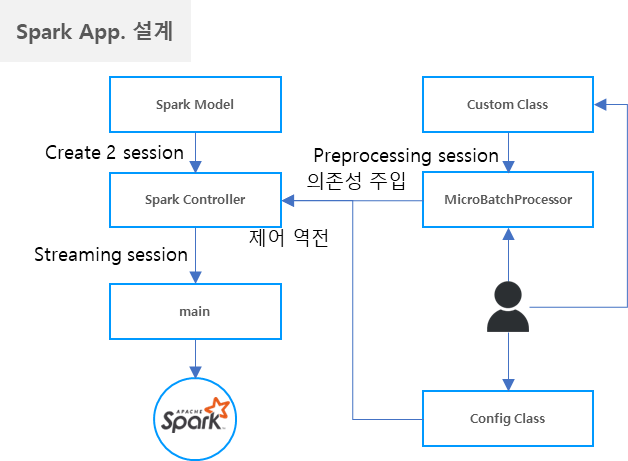
왼쪽부터 보게 되면 SparkModel에서 SparkSession 을 만들고 Kafka 를 Sink 하는 메소드를 만들었습니다.
이 후 Controller 에서 SparkModel을 활용하여 kafka를 Sink 하도록 구성했습니다.
그리고 SparkModel 에서 writeStream 시 foreachBatch 메소드를 활용하여 오른쪽의 개발자가 DataFrame 처리한 MicroBatchProcessor 를 의존성 주입할 수 있도록 구성했습니다.
/**
* 카프카 스트리밍 실행 함수
*/
def kafkaStreamingStarter(spark: DataFrame, sparkSession: SparkSession): Unit = {
val microBatchProcessor = new MicroBatchProcessor
val frequency = ConfigModel.SINK_FREQUENCY
spark
.writeStream
.trigger(Trigger.ProcessingTime(frequency))
.outputMode("append")
.foreachBatch((batchDF: DataFrame, batchId: Long) =>
processor.batch(batchDF, batchId, sparkSession)
)
.start()
.awaitTermination()
}이 템플릿의 목적은 운영 유지 보수의 목적도 있지만, 개발자가 Streaming 을 의식하고 개발하기 보다는 Zeppelin 에서 DataFrame 을 처리하는 느낌으로 쉽게 개발할 수 있도록 만들기 위한 목적도 있습니다.
4. MicroBatchProcessor
MicroBatchProcessor 에서 개발자는 절차 지향적으로 추상화 된 객체나 메소드들을 나열하여 DataFrame을 처리하도록 구상 했습니다.
실질적으로 해당 템플릿을 활용해서 개발을 할 경우 MicroBatchProcessor 에서 나열된 처리를 보고 어떻게 개발이 됐는지 한 눈에 알아 볼 수 있습니다.
그리고 매개변수로 DataFrame 과 배치 번호, Adhoc 처리를 위한 SparkSession을 받습니다. SparkSession의 경우 DataFrame 을 처리한 후 필요한 Spark 처리를 하기 위해 임시로 SparkSession 을 매개변수를 가져오게 했습니다.
그러나 Spark 완벽 가이드에서는 SparkSession을 의존성 주입을 통해 언제나 생성할 수 있도록 구성하는게 좋다라고 하여 지금 현 방식은 교체가 필요할 듯 합니다.
아래의 예시를 통해 추상화 된 코드들을 한 눈에 보고 코드를 파악할 수 있도록 구성했습니다.
package org.company.di
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
import org.company.di.util.{Preprocessor, SchemaRegistry}
class MicroBatchProcessor {
/**
* 의존성 주입 메인 함수
* @param df 카프카로 부터 consume 한 데이터
* @param batch_id 카프카로 부터 consume 한 배치 번호
* @param spark 새로운 스파크 처리를 위한 세션
*/
def batch(df: DataFrame, batch_id: Long, spark: SparkSession): Unit = {
// 0. 데이터 수집
val rowData = df.collect
// 1. 데이터가 없을 경우 모든 장비 신호 미발생 카운트 증가
if(rowData.length == 0) Preprocessor.allEqpAdder()
// 2. 배치 중 이미지 MetaData 축적 리스트
val newRowAData:Seq[Row] = Seq()
// 3. 배치 시작
for(row <- rowData){
// 4. Key 와 value 를 Decode or Parsing 합니다. Deserialize 는 String 입니다.
val key = row(0)
val value = row(1)
val (eqpId, fileName, uploadDateTime) = Preprocessor.kafka_key_extractor(key = key)
val valueImage = Preprocessor.kafka_value_extractor(value)
// 5. 이미지 파일 체크
if(Preprocessor.isJpg(fileName)){
// 5.1 장비 신호 미발생 카운트 증가
Preprocessor.allEqpAdder(eqpId)
// 5.2 장비 신호 미발생 카운트 조회
val eqpCount = Preprocessor.eqpCountMap.getOrElse(eqpId, Preprocessor.maxCount)
// 5.3 현재 장비 Ingot 조회
val ingotId = Preprocessor.getIngot(eqpId, eqpCount)
// 5.4 파일 저장 경로 생성
val path = Preprocessor.pathGen(eqpId, ingotId)
// 5.5 이미지 저장
Preprocessor.imgSaver(path, fileName, valueImage)
// 5.6 이미지 Meta Data 축적
newRowAData :+ Row(eqpId, ingotId, fileName, path, uploadDateTime)
}
// 6. 데이터 프레임 생성
val df = spark.createDataFrame(spark.sparkContext.parallelize(newRowAData), SchemaRegistry.imageMetaSchema())
// 7. 이미지 메타 데이터 하이브 저장
Preprocessor.hiveSaver(df)
// 8. 이미지 메타 데이터 오라클 저장
Preprocessor.oracleSaver(df)
}
}
}5. Config Class
별도의 yaml 이나 properties 파일이 아닌 Config Class 를 만들게 된 이유는 다음과 같습니다.
spark-submit 으로 application 을 실행시킬 경우 파일의 경로를 읽어야하는데, 해당 경로를 찾기가 어렵습니다.
그리고 yaml 이나 properties 로 작성을 했다고 하지만 결국 해당 yaml 이나 properties를 다시 읽어내야 하는 Class는 필요하기 때문에 애초에 Config Class 를 작성하여 정보를 인식할 수 있도록 구성했습니다. 그러나 추 후에 yaml 이나 properties 가 더 익숙할 수도 있으니 해당 파일을 읽어오는 기능을 만들 생각은 있습니다.
Config Class 는 별도의 인스턴스를 만들 필요 없도록 구성했습니다.
아래는 Config Class 의 예시 입니다.
package org.company.di.model
object ConfigModel {
private val _APP_NAME = "KAFKA_SINK_SPARK_SCALA_TEST"
private val _BOOTSTRAP_SERVER = "host1:port host2:port host3:port"
private val _SINK_TOPIC = "topic-01"
private val _SINK_FREQUENCY = "1 minute"
private val _ORACLE_JCEKS = ""
private val _ORACLE_JCEKS_ALIAS = ""
private val _ORACLE_JDBC_URL = ""
private val _ORACLE_USER = ""
private val _ORACLE_SCHEMA = ""
private val _ORACLE_TABLE = ""
private val _HIVE_SCHEMA = ""
private val _HIVE_TABLE = ""
def APP_NAME:String = this._APP_NAME
def BOOTSTRAP_SERVER:String = this._BOOTSTRAP_SERVER
def SINK_TOPIC:String = this._SINK_TOPIC
def SINK_FREQUENCY:String = this._SINK_FREQUENCY
def GROWER_MAX_COUNT:Int = this._GROWER_MAX_COUNT
def IMAGE_ROOT_PATH:String = this._IMAGE_ROOT_PATH
def ORACLE_JCEKS:String = this._ORACLE_JCEKS
def ORACLE_JCEKS_ALIAS:String = this._ORACLE_JCEKS_ALIAS
def ORACLE_JDBC_URL:String = this._ORACLE_JDBC_URL
def ORACLE_USER:String = this._ORACLE_USER
def ORACLE_SCHEMA:String = this._ORACLE_SCHEMA
def ORACLE_TABLE:String = this._ORACLE_TABLE
def HIVE_SCHEMA:String = this._HIVE_SCHEMA
def HIVE_TABLE:String = this._HIVE_TABLE
}
6. 실행
Scala 코드 템플릿과 Python 코드 템플릿은 실행 방법이 약간 다릅니다.
1. Scala Template 실행 방법
- Root Folder 에서
sbt package명령어로 jar 파일을 만듭니다. - 해당 jar 파일을 아래 명령어로 실행합니다.
nohup spark-submit \
--master yarn \
--deploy-mode cluster \
--driver-cores 2 \
--driver-memory 8G \
--num-executors 4 \
--executor-cores 2 \
--executor-memory 4G \
Application.jar > /dev/null 2>& 1&2. Python Template 실행 방법
- Root Folder 에서 src 폴더는 zip 파일로 만듭니다.
- main.py 파일을 아래 명령어로 실행합니다.
nohup spark-submit \
--master yarn \
--deploy-mode cluster \
--driver-cores 2 \
--driver-memory 8G \
--num-executors 4 \
--executor-cores 2 \
--executor-memory 4G \
--py-files src.zip \
main.py > /dev/null 2>& 1&SparkJobHistory 서버에서는 세션 명으로 보이지만, Yarn 에서는 Job 이름이 실행 파일 이름으로 보이기 때문에, 실행 파일 이름을 적당한 이름으로 작성해줄 필요가 있습니다.
7. 맺음말
언제나 개발은 유지 보수를 생각해야 합니다.

좋은 글 감사합니다.