
In Lecture 5 we move from fully-connected neural networks to convolutional neural networks. We discuss some of the key historical milestones in the development of convolutional networks, including the perceptron, the neocognitron, LeNet, and AlexNet. We introduce convolution, pooling, and fully-connected layers which form the basis for modern convolutional networks.
Keywords: Convolutional neural networks, perceptron, neocognitron, LeNet, AlexNet, convolution, pooling, fully-connected layers
1. Preview
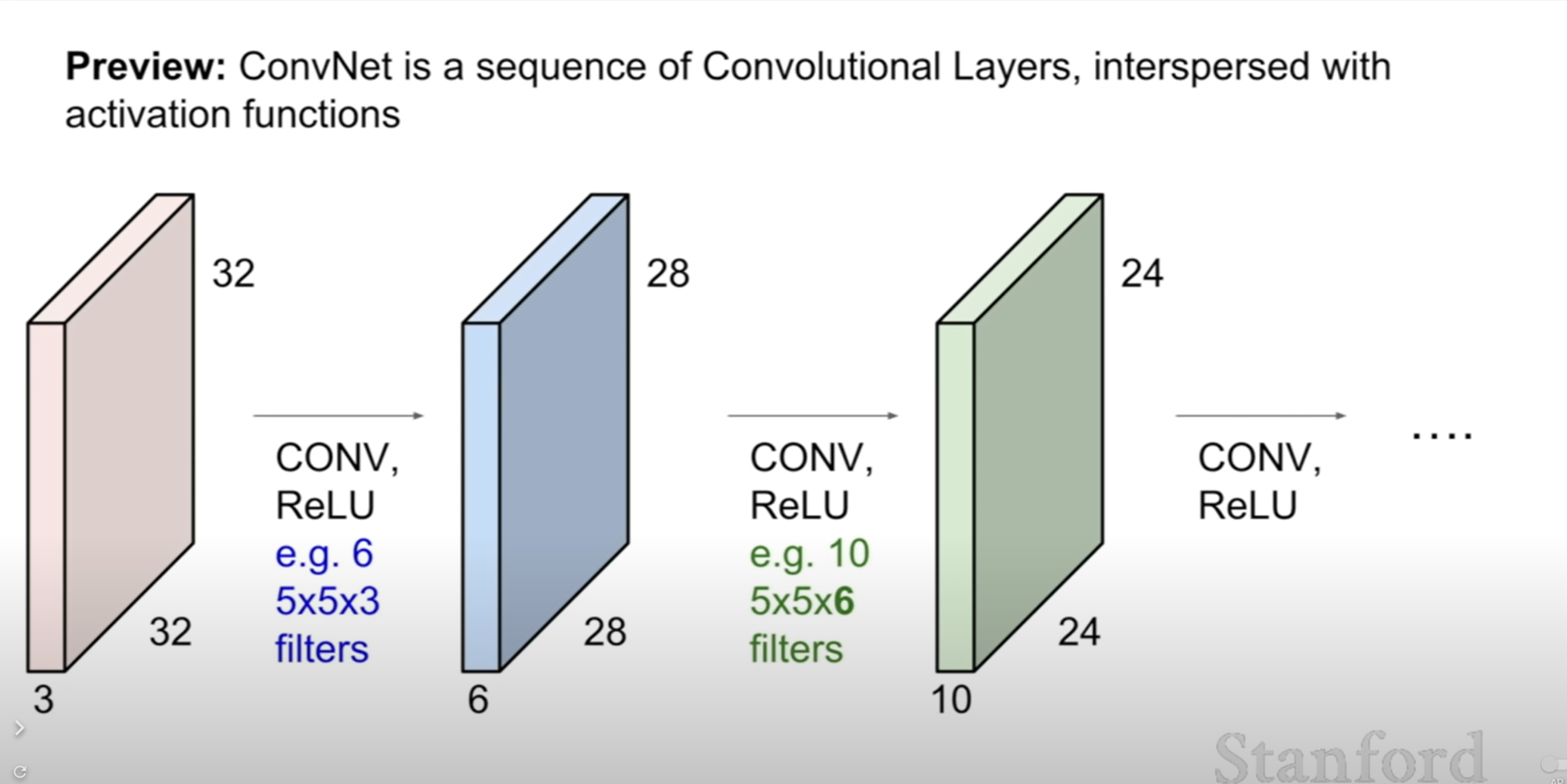
You are gonna have many design choices in convolutional network(ex. size of filter, stride, number of filter). We will gonna talk about these later.
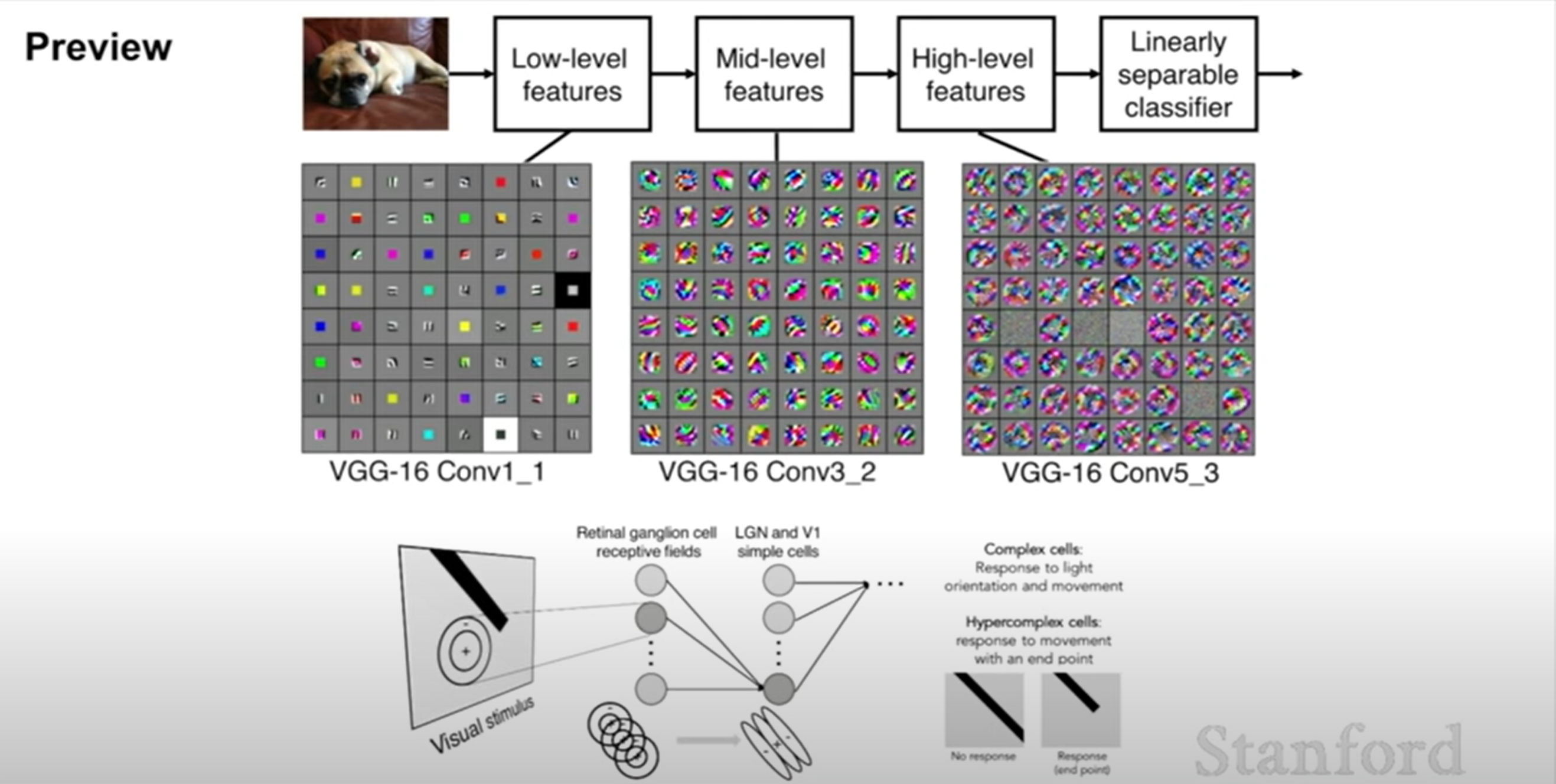
In this picture, each part of these grid is a one nueron. What they visualized here is what the input looks like that maximizes the activation of that particular neuron.

Here is an example of some of the activation maps produced by each filter.
So convolution is basically taking a filter, sliding it spatially over the image and computing the dot product at every location.
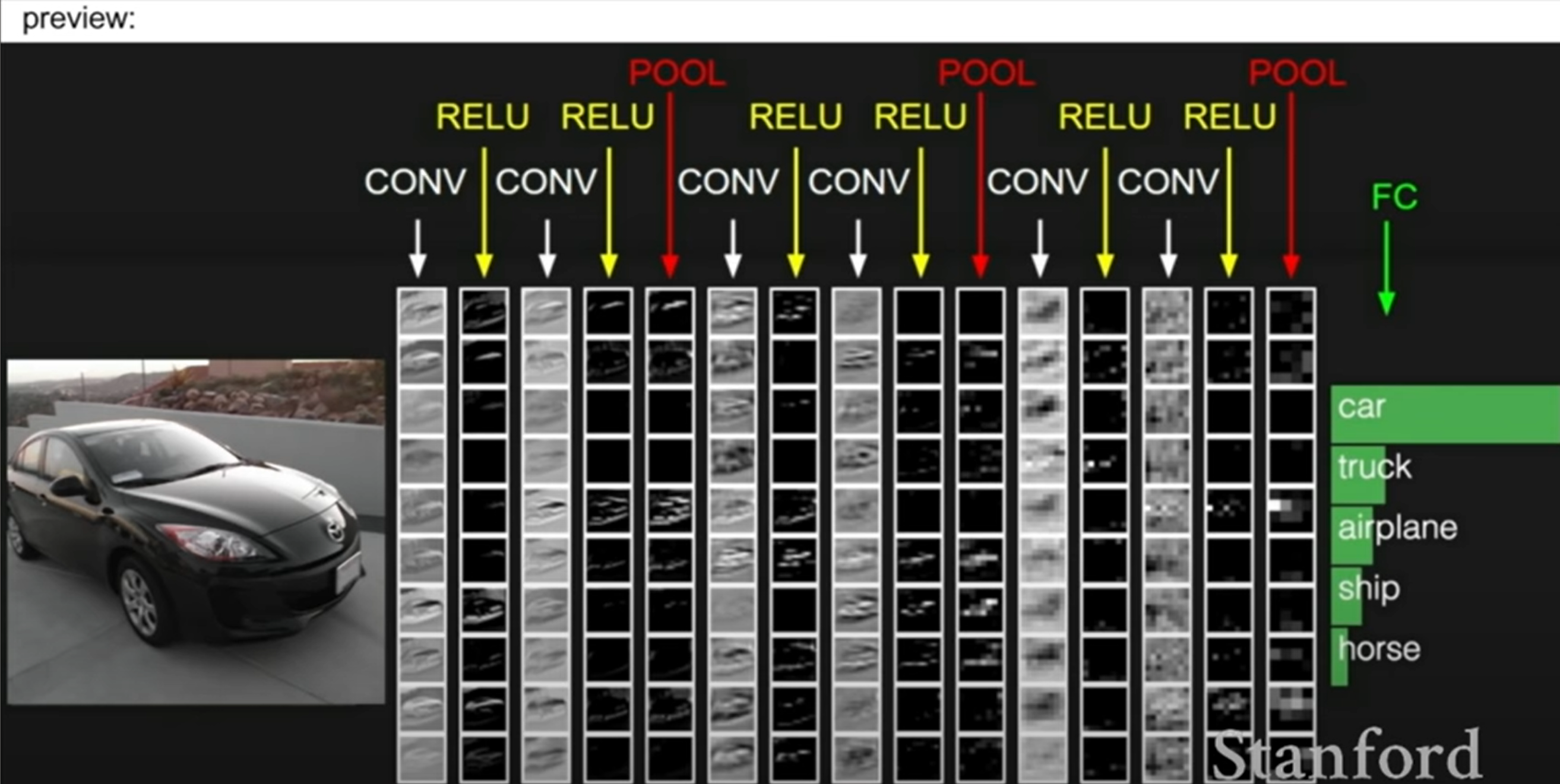
This is another example of convolution. Input image will go through CONV-ReLU-Pooling layers and a fully connected layer which will be used to get a final score function.
2. Closer look at spatial dimensions
From now, let's see how the spatial dimensions work out.
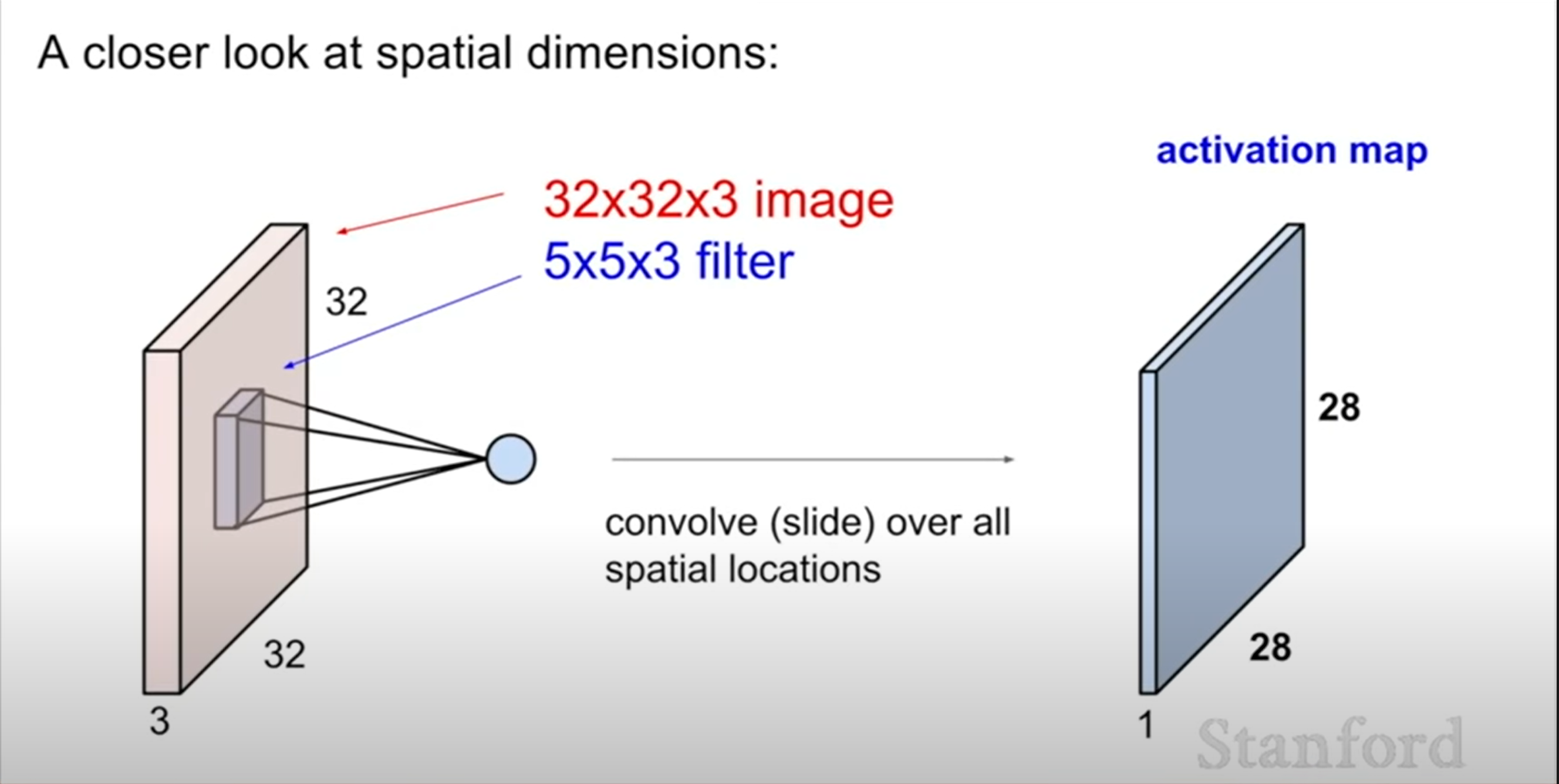
Let's take our 32x32 by three image. and we have 5x5x3 filter. And we're gonna see how we're going to use that to produce exactly this 28x28 activation map.
Let's assume that there are 7x7 size input and 3x3 filter.
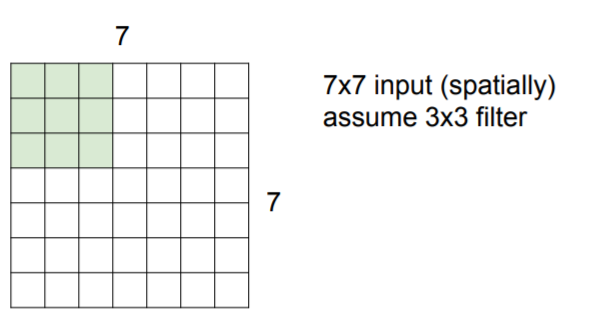
And we will slide this filter from upper left to bottom right.
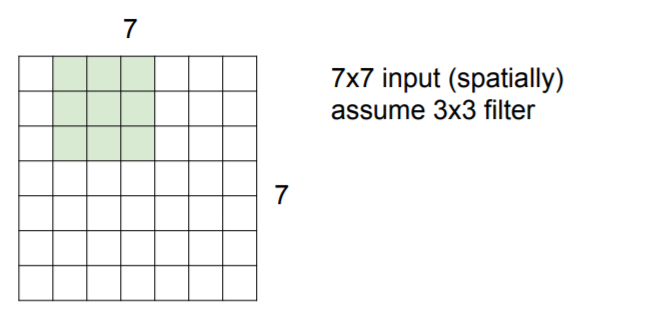
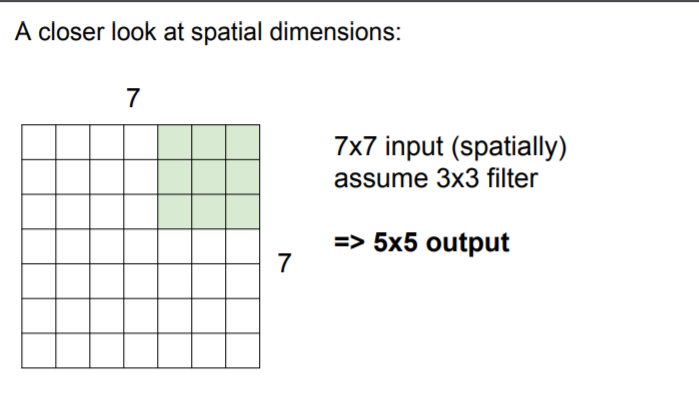
So we can continue with this to have values and we will finally get 5x5 output.
1) Different kinds of choices
Stride
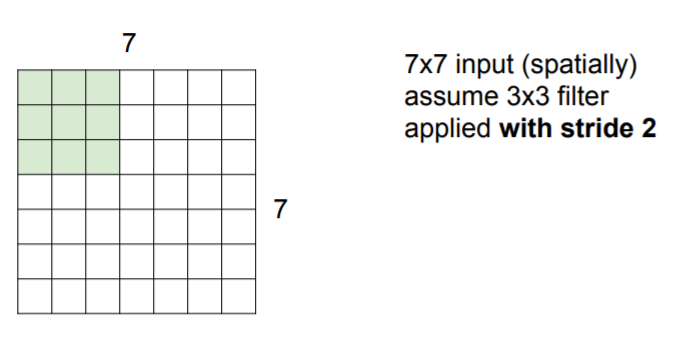
So here we will see different kinds of choices that we can design. We are going to skip two pixels over.
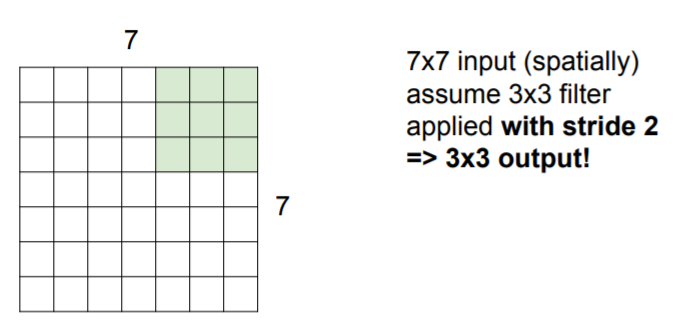
Then we will get 3x3 output!
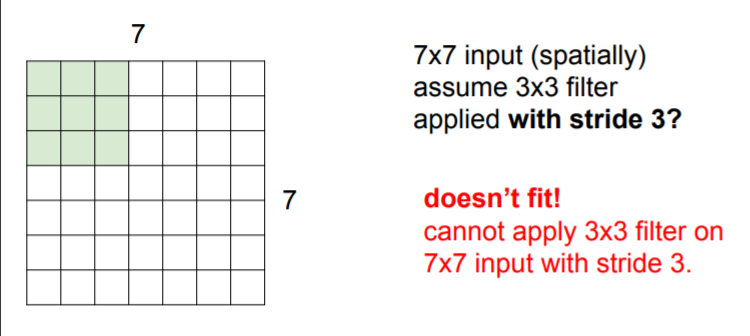
❓ What happens when we have a stride of three? what will be the output size of this?
❗ It doesn't fit with the image!!! It doesn't match!!
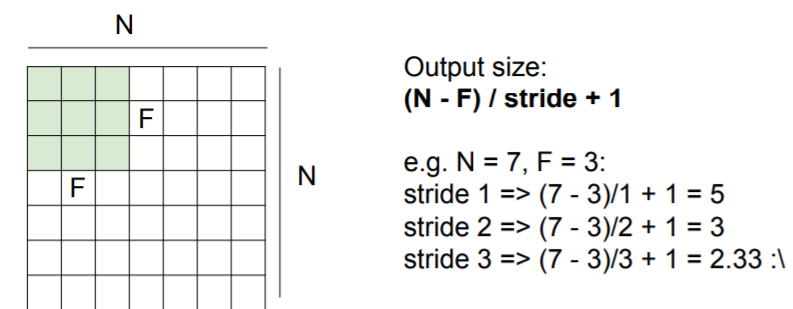
Output size will be calculated like this.
Padding

If we do padding, our input/output size will be changed.
In general, common to see CONV layers with stride 1, filters of size FxF, and zero-padding with (F-1)/2
- ex
F=3 -> zero pad with 1
F=5 -> zero pad with 2
F=7 -> zero pad with 3
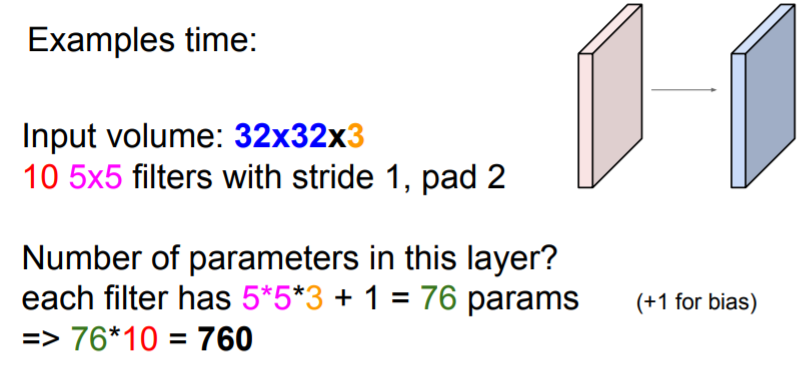
❓ Guess output volume size
❗ output volume size will be 32x32x10!

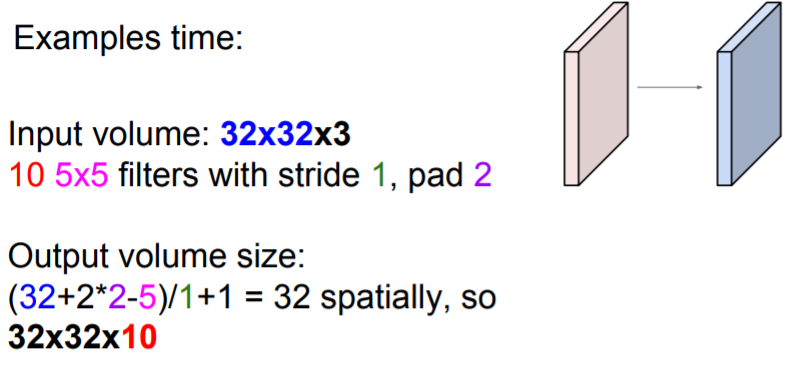
❓ Guess Number of parameters
❗ There are 760 total parameters! Don't forget the bias!

Summary(Filter, Padding, Stride)

2) Pooling layers
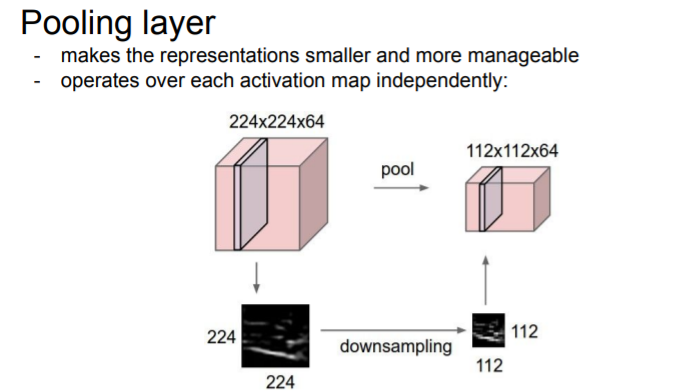
The reason why we want to make it smaller is that it effects the number of parameters and does some invariance over a given region.
So the pooling layer does is it exactly downsamples, and takes your input volume sptially downsamples. (Depth will be the same)
Max Pooling
The most common pooling is max pooling.
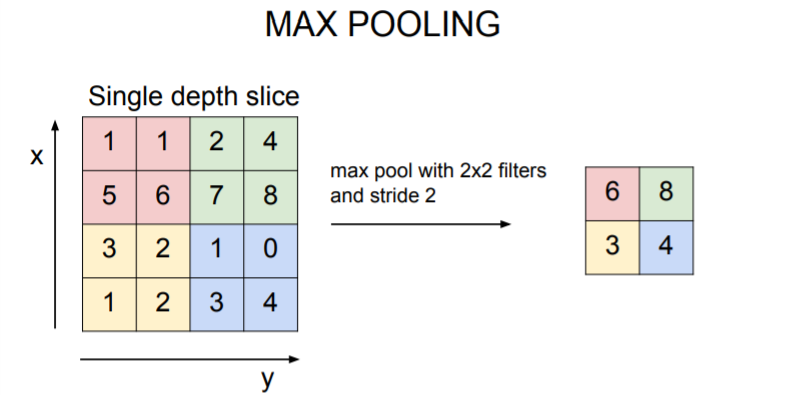
In this example, we have 2x2 filters withs stride two. We just take maximum value in each regions.
👀 Q. Why max pooling is better than doing something like average pooling?
👀 A. Intuition Behind is that it can have interpretation of these are activations of my neurons, and each value is kind of how much this neuron fired in this location. And you can think of max pooling as saying, giving a signal of how much did this filter fire at any location in this image. Whether a light or some aspect of your image that you're looking for, we want to fire at with a high value.
👀 Recently, neural network architectures use stride more in order to do the downsampling instead of just pooling.
Summary(with Pooling)

3. Summary

Today we talked about how convolutional neural network work. Next lecture, we'lll go into some architectures like ResNet and GoogLeNet, which give pretty different types of architectures.
Thank you.
