In Lecture 6 we discuss many practical issues for training modern neural networks. We discuss different activation functions, the importance of data preprocessing and weight initialization, and batch normalization; we also cover some strategies for monitoring the learning process and choosing hyperparameters.
Keywords: Activation functions, data preprocessing, weight initialization, batch normalization, hyperparameter search
Overview

- Part 1

Activation Functions
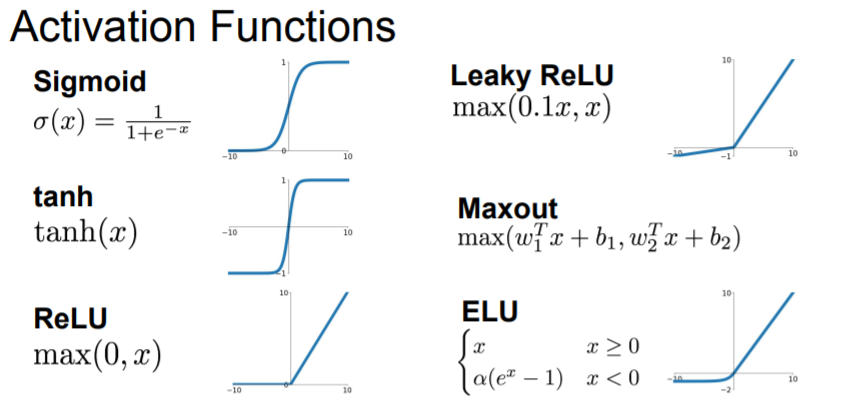
Today we're gonna talk about different chocies for these different non-linearlities and trade-off between them.
Sigmoid

Problems
- If x is equal to large positive or negative numbers, a zero gradient passed down to downstream nodes after chain rule.
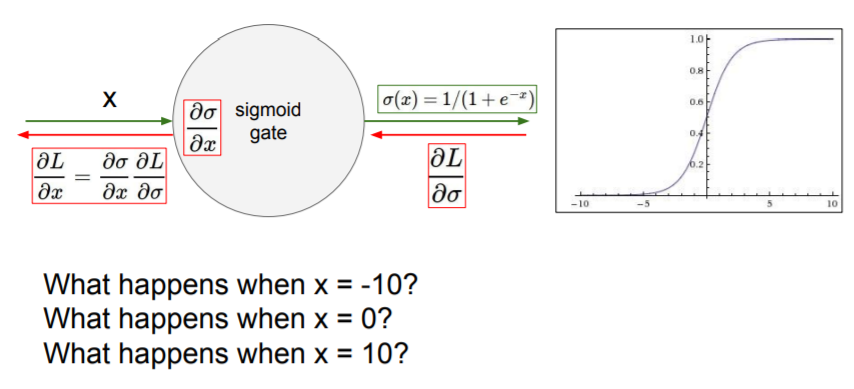
- If all of x is positive or negative, they are always going to move in the same direction. And this gives very inefficient gradient updates.


Let's say W is 2-Dimensional. We have our two axes for W, and if we say that we can only have all positive or all negative updates, then we only have two quadrants. And these are the only directions in which we're allowed to make a gradient update.
Let's say our hypothetical optimial W is actually this blue vector. We can't just directly take a gradient update in this direction, because this is not in one of those two allowed gradient directions.
my Q? what does this mean
Tanh(x)

It squashes to the range -1 ~ 1. It's zero centered!
ReLU
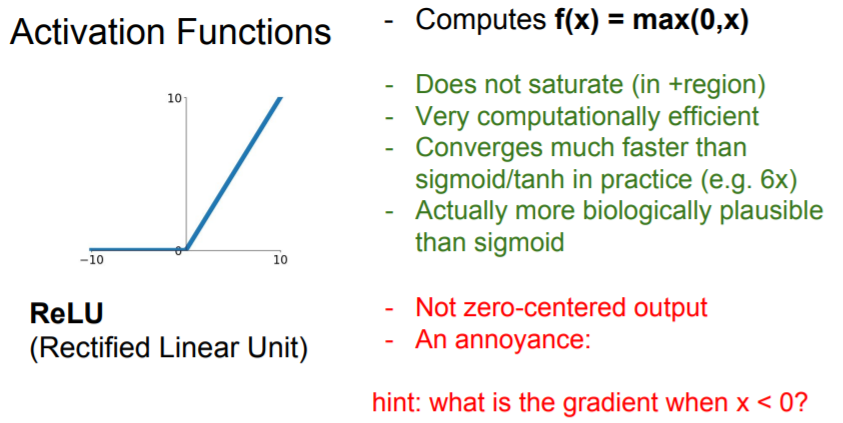
For these advantages, ReLU were starting to be used a lot around 2012 when we had AlexNet.
But the problem is that it kills the gradient in half of the regime(negative).
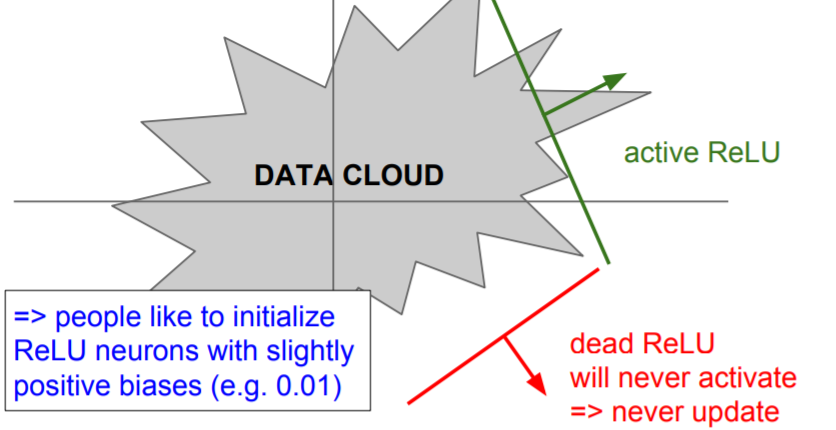
If you look at this data cloud(training data), we might have Dead ReLUs that are basically off of the data cloud. In this case, it will never activate and never update as compared to an active ReLU.
There are some of reasons that can happen.
- it can happen when you have bad initialization.(rare case)
- When our learning rate is too high(general case).
Because you're making these huge updates, the weights jump around and then your ReLU unit gets knocked off of the data manifold. So it was fine at the beginning and at some point it became bad and it died.
❓ How do we know when the ReLU is going to be dead or not?
❗ Some of your ReLU will be in different places with respect to the data cloud when you train it.
Leaky ReLU

ELU

Maxout Neuron

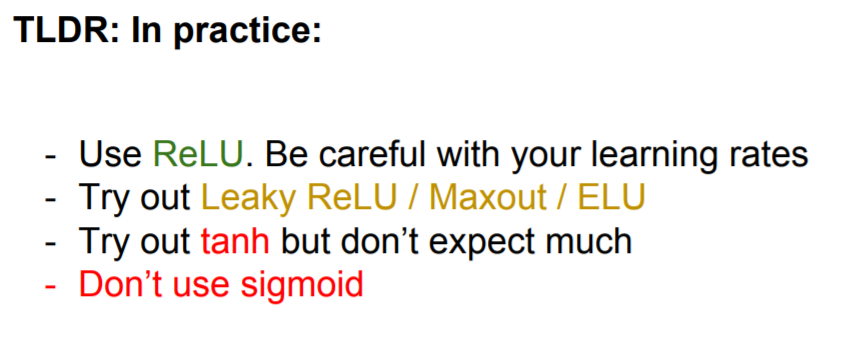
TLDR
Data Preprocessing
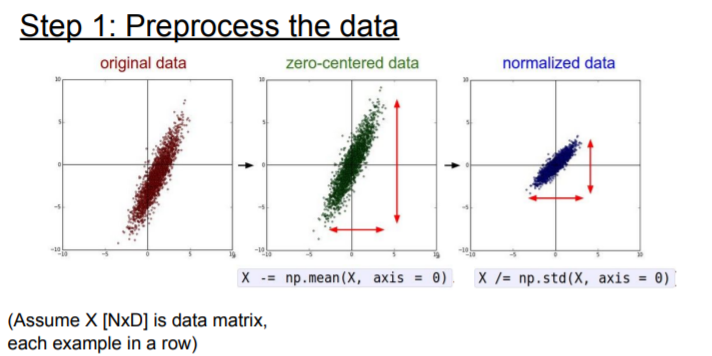
Now we want to train the network, and we have our input data that we want to start training form. So generally we always want to preprocess data.
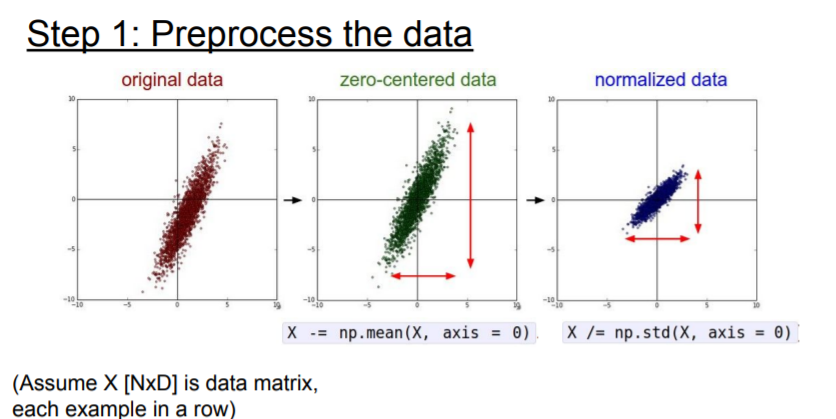
So why do we want this?

TLDR

Basically for images, we typically just do the zero mean pre-processing and we can subtract either the entire mean image.
Weight Initialization
❓ We have to start with some values. What happensss when we just set all of the parameters to be zero?
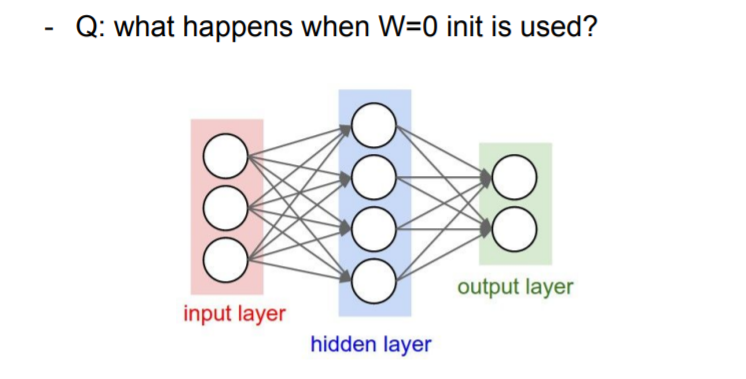
❗ They will do the same things. They will have same operation basically on top of your inputs. They're also goint to get the same gradient which is not you want.
First idea to try: small values

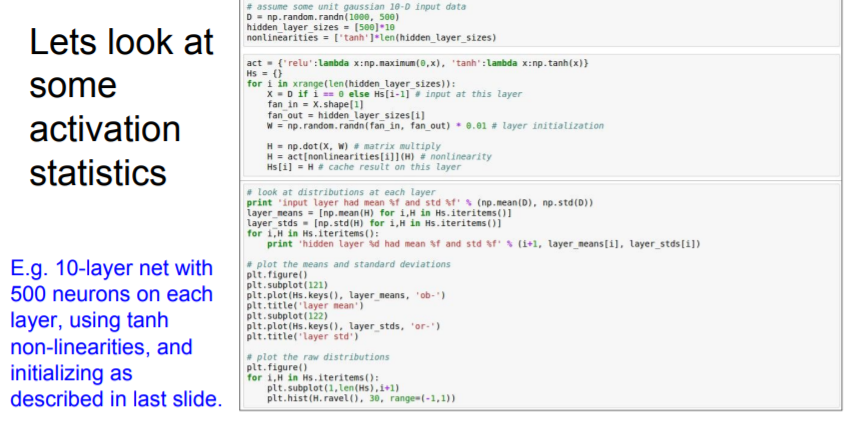
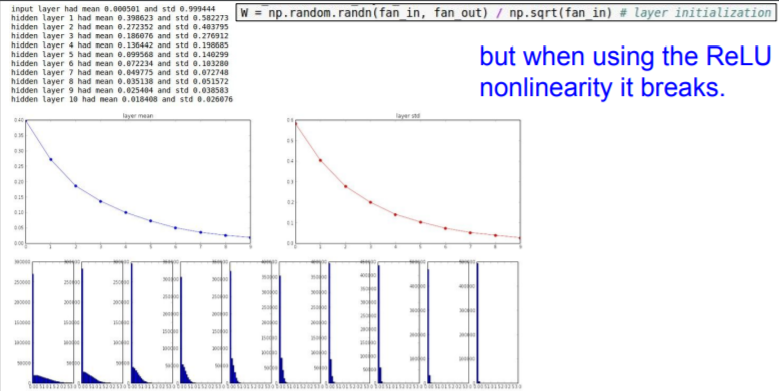
Let's see an example. We use Tanh as a activation function.
Forward pass
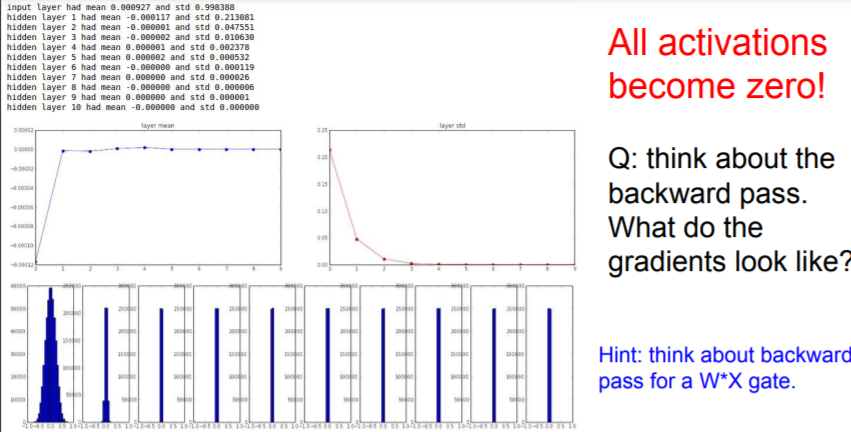
It can make all activations become zero! As our mean of W is zero and
Tanh function is also centered in zero, it quicklly collapes to zero.
At first layer, we have a good Gaussian looking thing, but after 2nd layer, all of thesse values collapse as we multiply these small values over and over again.
Backward pass
In order to get the gradient on the weights, we did dot products W times X. Actually going backwards at each layer, we're basically doing a multiplication of the upstream gradient by our weights in order to get the next gradient flowing downwards. So we're multiplying by W over and over again.
Upstream: the gradient flowing from your loss, all the way back to your input. So upstream is what came from what you've already done down into your current node.
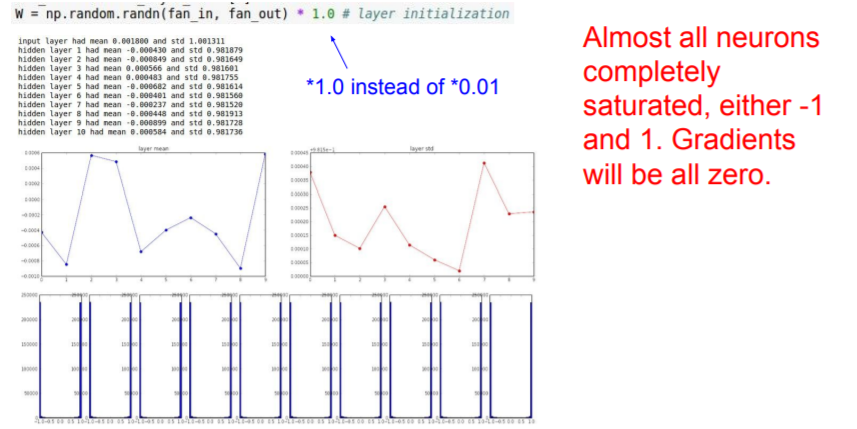
Second idea to try: big values
❓ Then What if we just try and solve this by making our weights big?
Let's sample form this standard gaussian.
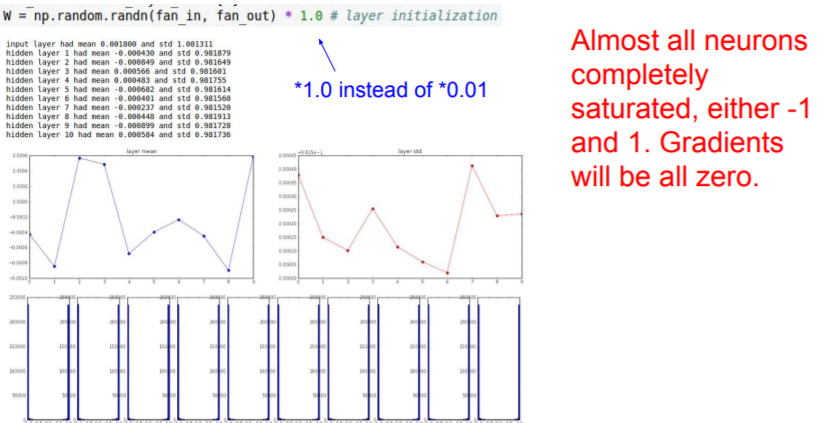
It's going to be saturated! They're going to be all basically negative one or plus one. And when they're saturated, all the gradients will be zero.
Great rule of thumb: Xavier Initialization
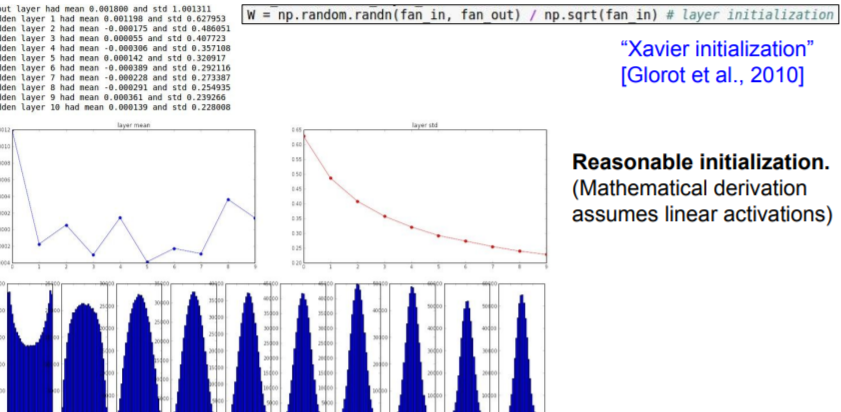
It is assumed that there's linear activations. And the problem is that this breaks when you use something like a ReLU.
Research

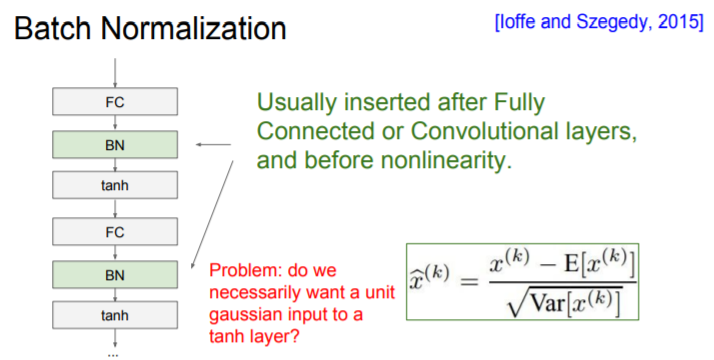
Batch Normalization
The idea behind batch normalization is, we want unit gaussian activations.


If we look at our data, we can think we have N training examples in our current batch, and then each batch has dimension D, and we're going to compute the empirical mean and variance independently for each dimension.
We saw that when we were multiplying by W in these layers, which we do over and over again, then we can have this bad scaling effect with each one. So this basically is able to undo this bad effect.

After the normalization, we do scale by some constant , and shift by another factor of . What actually this does is that this allow you to be able to recover the identity function if you wanted to. So you have the flexibility of doing everything in between and making the network learning how to make your tanh more/less saturated.
And you can also think this as a way to do some regularization. Because at the output of each layer, each of these activations, each of these outputs, is an output of both your input X, as well as the other examples in the batch.
?

?
Babysitting the Learning Process
The first thing we want to do is initializing our network.
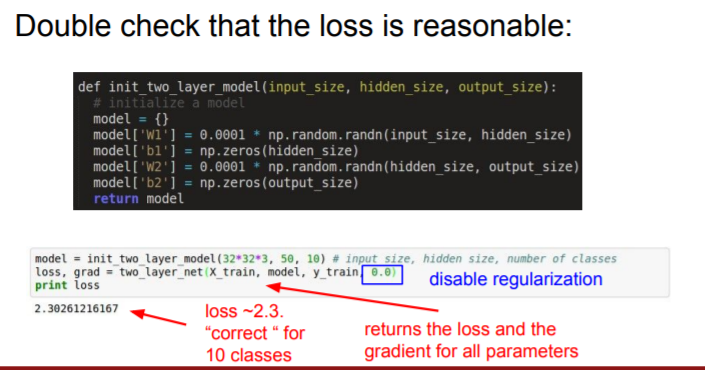
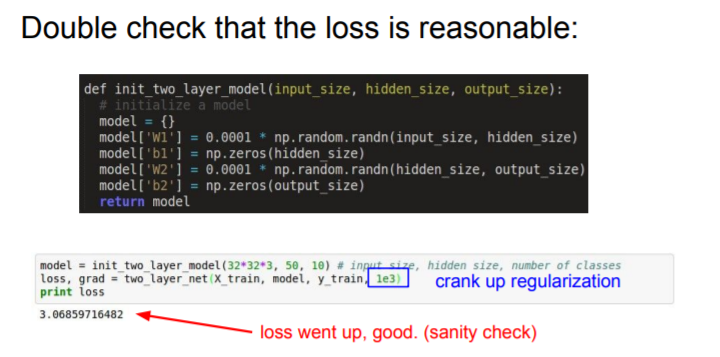
We cranked our regularization and we can check that our loss went up bacause we've added this additional regularization term.
Now we can start trainging. Let's start it.
Good way to start is start up with a very small amount of data.

Your small data might be overfitted. And so in this case turn off the regularization again, and just see if we can make the loss go down to zero.
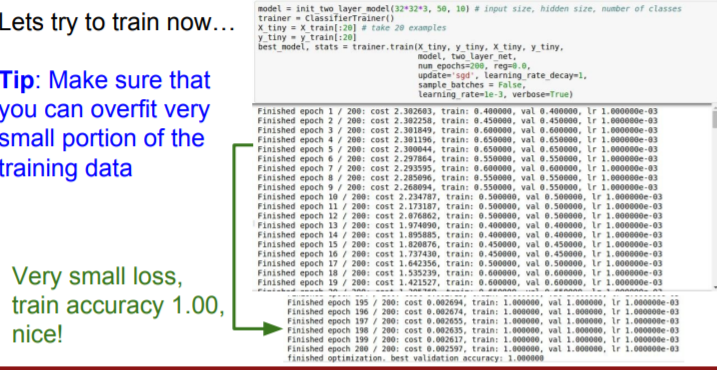
So these are sanity checks, now we can start really trying to train. Take your full training data and start with a small amount of regularization. And first, figure out what's a good learning rate.

And you can also see that even though our loss doesn't change, our train/val accuracy goest to 20% very quickly.
The reason is that when we shift all of these probabilites slightly in the right direction, now the accuracy all of a sudden can jump, because we're taking the maximum correct value and we're goint to get a big jump in accuracy, even thought our loss is still relatively diffuse.

You might get Nan as a cost value when your learning rate is too high.

Hyperparameter Optimization
So, how do we exactly pick these hyperparameters?
Cross-validation

Cross-validation is training on our training set, and then evaluating on a validation set.
We only run few epochs, and we can already get a pretty good sense of which values are good or not.
uniform
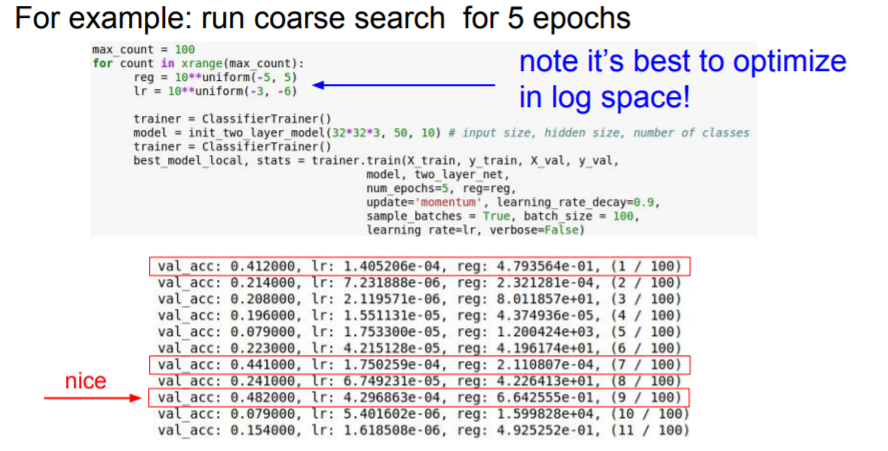
Random Search & Grid Search
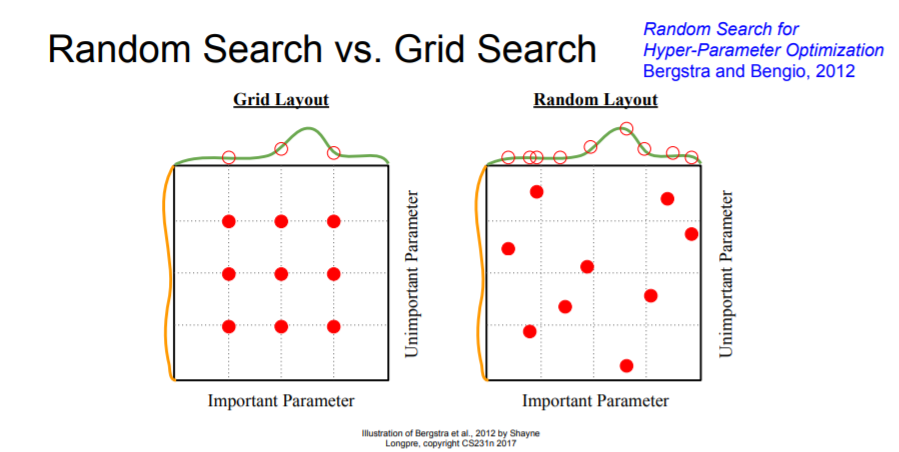
Random Search is better than Grid search. The reason is that, If a function is sort of more of a function of one variable than another, Then you're going to get many more samples of the important variable that you have. Basically we will get much more useful signal overall since we have more samples of different values of the important value.

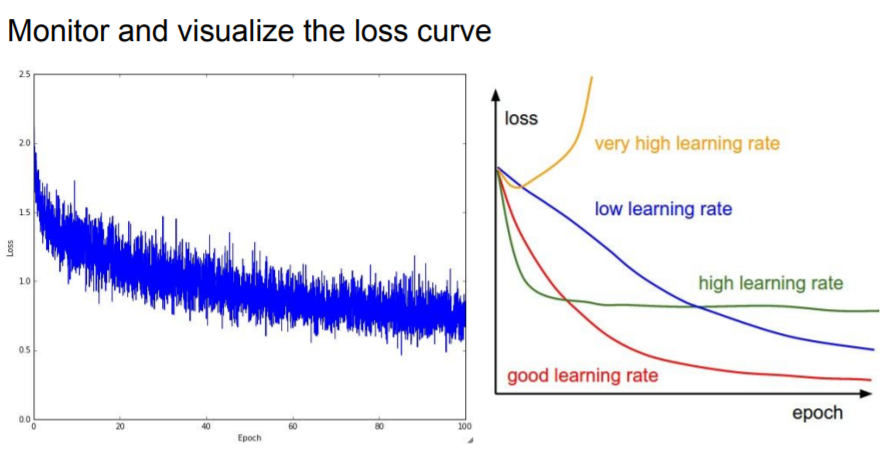
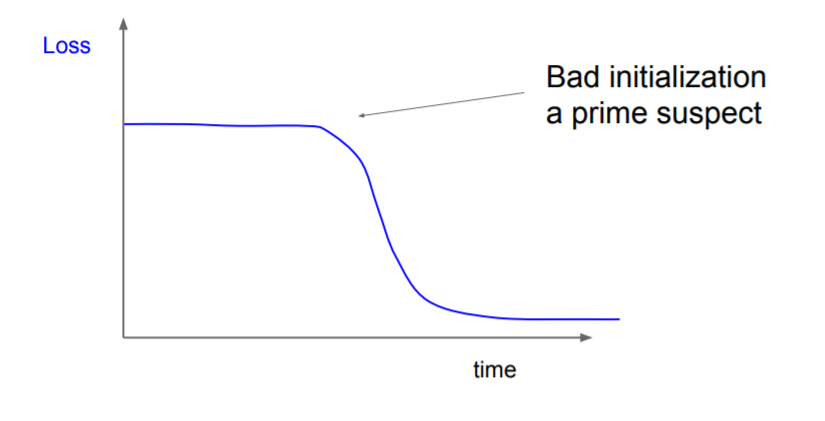
? why is this relevant with Bad initialization?
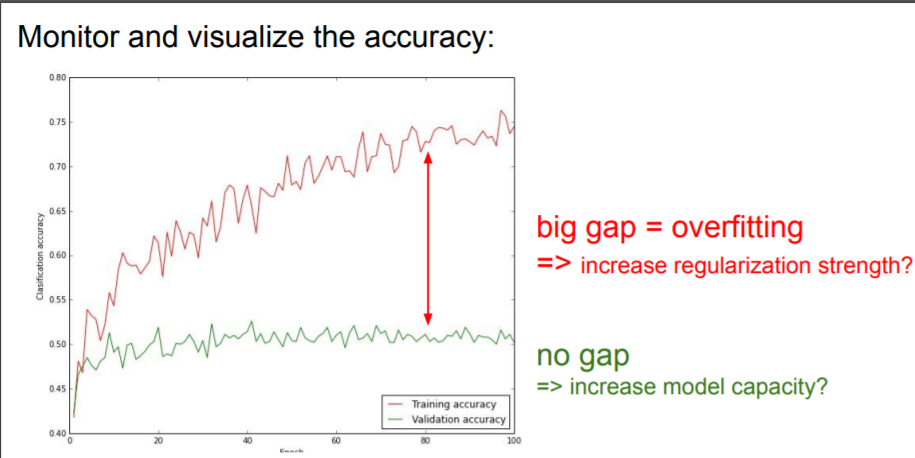
Summary

