Multilayer Perceptron
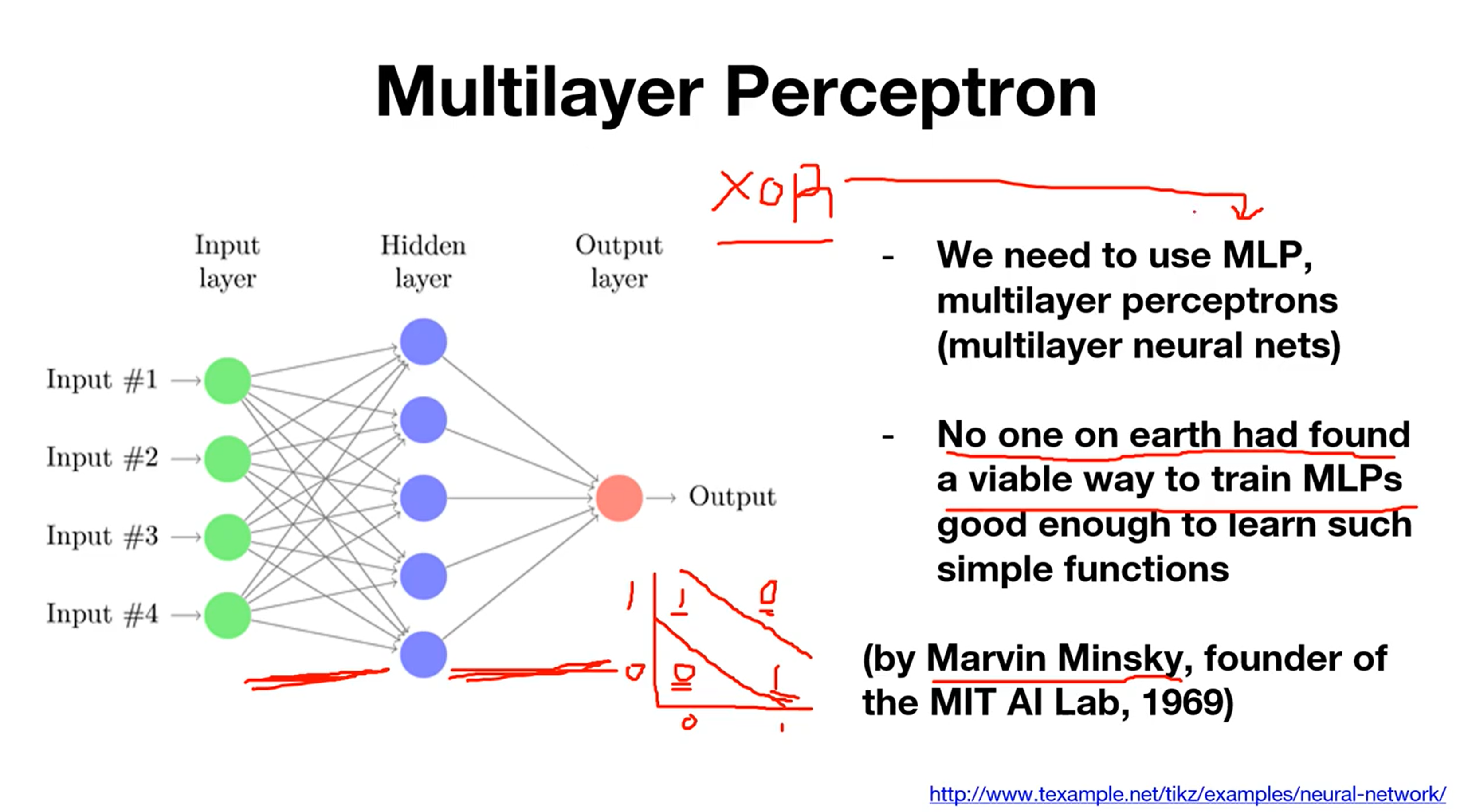
이후 Backpropagation algorithm의 등장으로 MLP 학습이 가능하게 되었습니다!
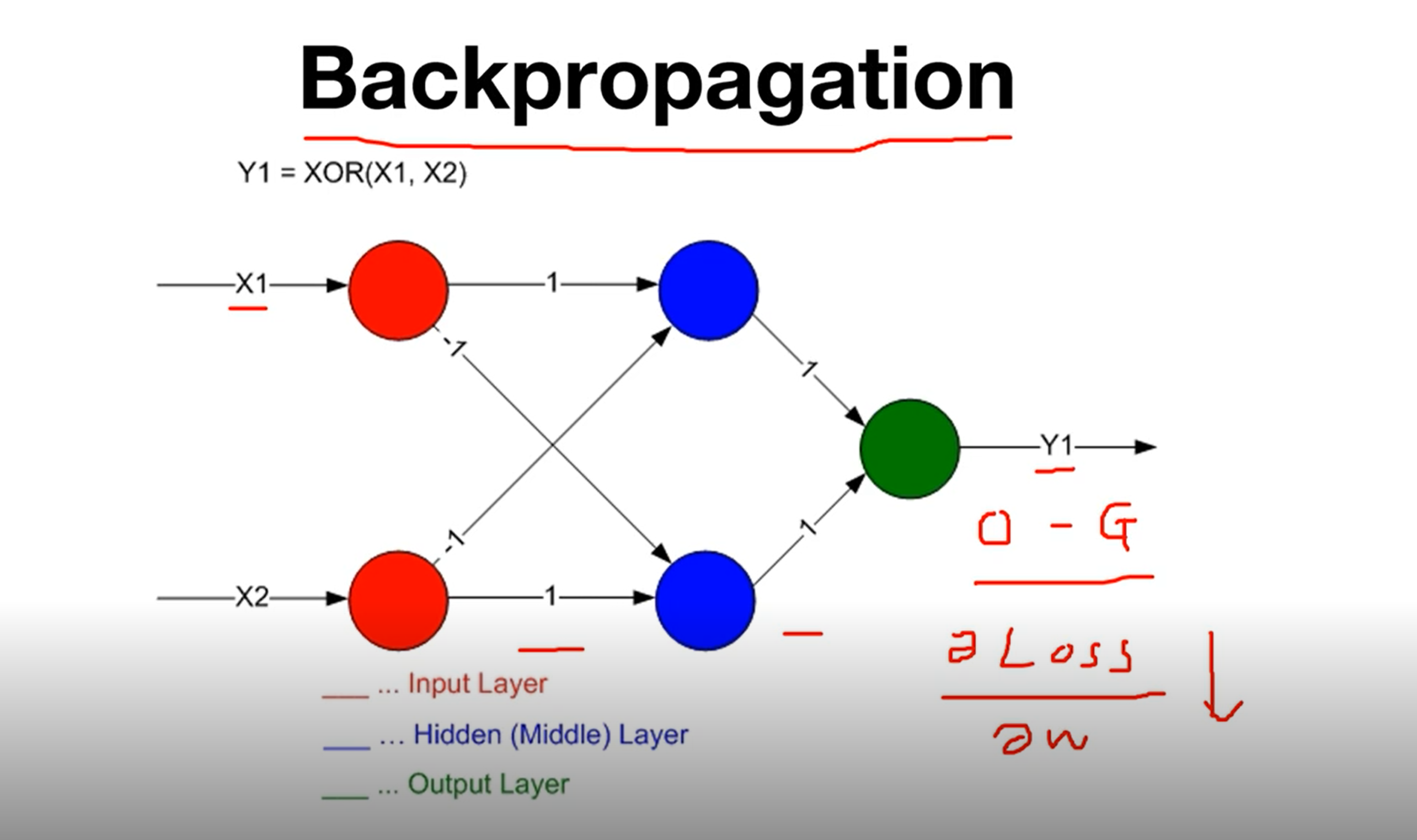
참고 영상: 모두를 위한 딥러닝 시즌1 Kim Sung
# Lab 9 XOR
import torchdevice = 'cuda' if torch.cuda.is_available() else 'cpu'
# for reproducibility
torch.manual_seed(777)
if device == 'cuda':
torch.cuda.manual_seed_all(777)X = torch.FloatTensor([[0, 0], [0, 1], [1, 0], [1, 1]]).to(device)
Y = torch.FloatTensor([[0], [1], [1], [0]]).to(device)# nn layers
linear1 = torch.nn.Linear(2, 2, bias=True)
linear2 = torch.nn.Linear(2, 1, bias=True)
sigmoid = torch.nn.Sigmoid()# model
model = torch.nn.Sequential(linear1, sigmoid, linear2, sigmoid).to(device)# define cost/loss & optimizer
criterion = torch.nn.BCELoss().to(device)
optimizer = torch.optim.SGD(model.parameters(), lr=1) # modified learning rate from 0.1 to 1for step in range(10001):
optimizer.zero_grad()
hypothesis = model(X)
# cost/loss function
cost = criterion(hypothesis, Y)
cost.backward()
optimizer.step()
if step % 100 == 0:
print(step, cost.item())0 0.7434073090553284
100 0.6931650638580322
200 0.6931577920913696
300 0.6931517124176025
400 0.6931463479995728
500 0.6931411027908325
600 0.693135678768158
700 0.6931295394897461
800 0.693122148513794
900 0.6931126713752747
1000 0.6930999755859375
1100 0.693082332611084
1200 0.6930568814277649
1300 0.6930190920829773
1400 0.6929606199264526
1500 0.6928659677505493
1600 0.6927032470703125
1700 0.6923960447311401
1800 0.6917301416397095
1900 0.6899654865264893
2000 0.6838318109512329
2100 0.6561676263809204
2200 0.4311096668243408
2300 0.1348954439163208
2400 0.0663050040602684
2500 0.04216844588518143
2600 0.03045402094721794
2700 0.02366602048277855
2800 0.019277796149253845
2900 0.01622406765818596
3000 0.013983823359012604
3100 0.012273991480469704
3200 0.010928178206086159
3300 0.009842487052083015
3400 0.008949032984673977
3500 0.008201336488127708
3600 0.007566767744719982
3700 0.007021686062216759
3800 0.006548595614731312
3900 0.006134253926575184
4000 0.005768374539911747
4100 0.0054430365562438965
4200 0.005151890218257904
4300 0.0048899175599217415
4400 0.004652872681617737
4500 0.004437457304447889
4600 0.004240859299898148
4700 0.00406070239841938
4800 0.0038950315210968256
4900 0.003742194501683116
5000 0.003600734518840909
5100 0.0034694799687713385
5200 0.0033473046496510506
5300 0.0032333978451788425
5400 0.0031268750317394733
5500 0.0030270610004663467
5600 0.002933340147137642
5700 0.0028452035039663315
5800 0.002762140706181526
5900 0.0026837773621082306
6000 0.0026096487417817116
6100 0.0025394847616553307
6200 0.0024729417636990547
6300 0.0024097643326967955
6400 0.0023497282527387142
6500 0.0022925485391169786
6600 0.002238075714558363
6700 0.002186085097491741
6800 0.0021364721469581127
6900 0.002089011948555708
7000 0.0020436146296560764
7100 0.0020001311786472797
7200 0.0019584116525948048
7300 0.0019184107659384608
7400 0.0018799942918121815
7500 0.0018430722411721945
7600 0.0018075400730594993
7700 0.0017733527347445488
7800 0.0017404207028448582
7900 0.0017087138257920742
8000 0.001678097527474165
8100 0.0016485570231452584
8200 0.001620002556592226
8300 0.0015924491453915834
8400 0.0015657917829230428
8500 0.0015400308184325695
8600 0.0015150615945458412
8700 0.001490913680754602
8800 0.0014674977865070105
8900 0.001444813678972423
9000 0.0014228166546672583
9100 0.0014014765620231628
9200 0.0013806892093271017
9300 0.0013606036081910133
9400 0.0013410557294264436
9500 0.001322030322626233
9600 0.001303557539358735
9700 0.001285637030377984
9800 0.0012681199004873633
9900 0.0012511102249845862
10000 0.0012345188297331333# Accuracy computation
# True if hypothesis>0.5 else False
with torch.no_grad():
hypothesis = model(X)
predicted = (hypothesis > 0.5).float()
accuracy = (predicted == Y).float().mean()
print('\nHypothesis: ', hypothesis.detach().cpu().numpy(), '\nCorrect: ', predicted.detach().cpu().numpy(), '\nAccuracy: ', accuracy.item())Hypothesis: [[0.00106364]
[0.99889404]
[0.99889404]
[0.00165861]]
Correct: [[0.]
[1.]
[1.]
[0.]]
Accuracy: 1.0# Lab 9 XOR
import torchdevice = 'cuda' if torch.cuda.is_available() else 'cpu'
# for reproducibility
torch.manual_seed(777)
if device == 'cuda':
torch.cuda.manual_seed_all(777)X = torch.FloatTensor([[0, 0], [0, 1], [1, 0], [1, 1]]).to(device)
Y = torch.FloatTensor([[0], [1], [1], [0]]).to(device)# nn layers
linear1 = torch.nn.Linear(2, 10, bias=True)
linear2 = torch.nn.Linear(10, 10, bias=True)
linear3 = torch.nn.Linear(10, 10, bias=True)
linear4 = torch.nn.Linear(10, 1, bias=True)
sigmoid = torch.nn.Sigmoid()# model
model = torch.nn.Sequential(linear1, sigmoid, linear2, sigmoid, linear3, sigmoid, linear4, sigmoid).to(device)# define cost/loss & optimizer
criterion = torch.nn.BCELoss().to(device)
optimizer = torch.optim.SGD(model.parameters(), lr=1) # modified learning rate from 0.1 to 1for step in range(10001):
optimizer.zero_grad()
hypothesis = model(X)
# cost/loss function
cost = criterion(hypothesis, Y)
cost.backward()
optimizer.step()
if step % 100 == 0:
print(step, cost.item())0 0.6948983669281006
100 0.6931558847427368
200 0.6931535005569458
300 0.6931513547897339
400 0.6931493282318115
500 0.6931473016738892
600 0.6931453943252563
700 0.6931434869766235
800 0.6931416988372803
900 0.6931397914886475
1000 0.6931380033493042
1100 0.6931362152099609
1200 0.6931343078613281
1300 0.6931324005126953
1400 0.6931304931640625
1500 0.6931284666061401
1600 0.6931264400482178
1700 0.6931242942810059
1800 0.6931220293045044
1900 0.6931196451187134
2000 0.6931171417236328
2100 0.6931145191192627
2200 0.6931115984916687
2300 0.6931085586547852
2400 0.693105161190033
2500 0.6931014657020569
2600 0.6930974721908569
2700 0.6930930018424988
2800 0.6930880546569824
2900 0.6930825710296631
3000 0.6930763125419617
3100 0.6930692791938782
3200 0.6930612325668335
3300 0.6930519342422485
3400 0.693041205406189
3500 0.693028450012207
3600 0.6930133104324341
3700 0.6929951906204224
3800 0.6929729580879211
3900 0.6929453015327454
4000 0.6929103136062622
4100 0.6928650140762329
4200 0.6928046941757202
4300 0.6927220225334167
4400 0.692604124546051
4500 0.6924278736114502
4600 0.692147970199585
4700 0.6916665434837341
4800 0.6907395720481873
4900 0.6886204481124878
5000 0.6820821762084961
5100 0.6472558379173279
5200 0.4495784044265747
5300 0.041401054710149765
5400 0.00973653607070446
5500 0.0050338273867964745
5600 0.00329551356844604
5700 0.0024154414422810078
5800 0.0018910930957645178
5900 0.0015457704430446029
6000 0.0013024783693253994
6100 0.001122395507991314
6200 0.0009841559221968055
6300 0.0008749148109927773
6400 0.0007865495281293988
6500 0.0007136262720450759
6600 0.0006525927456095815
6700 0.000600747880525887
6800 0.0005561667494475842
6900 0.0005174618563614786
7000 0.0004836336011067033
7100 0.0004537721397355199
7200 0.0004272061923984438
7300 0.00040348825859837234
7400 0.00038214115193113685
7500 0.00036286652903072536
7600 0.00034532143035903573
7700 0.00032935672788880765
7800 0.000314718927256763
7900 0.00030131853418424726
8000 0.0002889616880565882
8100 0.0002774993481580168
8200 0.0002669314562808722
8300 0.0002570493088569492
8400 0.00024786783615127206
8500 0.00023931238683871925
8600 0.00023129362671170384
8700 0.0002237667649751529
8800 0.00021670199930667877
8900 0.00021005462622269988
9000 0.000203779898583889
9100 0.0001978629152290523
9200 0.00019222912669647485
9300 0.00018693818128667772
9400 0.00018191552953794599
9500 0.00017716118600219488
9600 0.00017261551693081856
9700 0.00016829342348501086
9800 0.00016415018762927502
9900 0.00016021561168599874
10000 0.0001565046259202063# Accuracy computation
# True if hypothesis>0.5 else False
with torch.no_grad():
hypothesis = model(X)
predicted = (hypothesis > 0.5).float()
accuracy = (predicted == Y).float().mean()
print('\nHypothesis: ', hypothesis.detach().cpu().numpy(), '\nCorrect: ', predicted.detach().cpu().numpy(), '\nAccuracy: ', accuracy.item())Hypothesis: [[1.1168354e-04]
[9.9982882e-01]
[9.9984241e-01]
[1.8533420e-04]]
Correct: [[0.]
[1.]
[1.]
[0.]]
Accuracy: 1.0# Lab 10 MNIST and softmax
import torch
import torchvision.datasets as dsets
import torchvision.transforms as transformsdevice = 'cuda' if torch.cuda.is_available() else 'cpu'
# for reproducibility
torch.manual_seed(777)
if device == 'cuda':
torch.cuda.manual_seed_all(777)# parameters
learning_rate = 0.5
batch_size = 10# MNIST dataset
mnist_train = dsets.MNIST(root='MNIST_data/',
train=True,
transform=transforms.ToTensor(),
download=True)
mnist_test = dsets.MNIST(root='MNIST_data/',
train=False,
transform=transforms.ToTensor(),
download=True)# dataset loader
data_loader = torch.utils.data.DataLoader(dataset=mnist_train,
batch_size=batch_size,
shuffle=True,
drop_last=True)w1 = torch.nn.Parameter(torch.Tensor(784, 30)).to(device)
b1 = torch.nn.Parameter(torch.Tensor(30)).to(device)
w2 = torch.nn.Parameter(torch.Tensor(30, 10)).to(device)
b2 = torch.nn.Parameter(torch.Tensor(10)).to(device)torch.nn.init.normal_(w1)
torch.nn.init.normal_(b1)
torch.nn.init.normal_(w2)
torch.nn.init.normal_(b2)Parameter containing:
tensor([ 0.3078, -1.9857, 1.0512, 1.5122, -1.0199, -0.7402, -1.3111, 0.6142,
-0.6474, 0.1758], requires_grad=True)def sigmoid(x):
# sigmoid function
return 1.0 / (1.0 + torch.exp(-x))
# return torch.div(torch.tensor(1), torch.add(torch.tensor(1.0), torch.exp(-x)))def sigmoid_prime(x):
# derivative of the sigmoid function
return sigmoid(x) * (1 - sigmoid(x))X_test = mnist_test.test_data.view(-1, 28 * 28).float().to(device)[:1000]
Y_test = mnist_test.test_labels.to(device)[:1000]
i = 0
while not i == 10000:
for X, Y in data_loader:
i += 1
# forward
X = X.view(-1, 28 * 28).to(device)
Y = torch.zeros((batch_size, 10)).scatter_(1, Y.unsqueeze(1), 1).to(device) # one-hot
l1 = torch.add(torch.matmul(X, w1), b1)
a1 = sigmoid(l1)
l2 = torch.add(torch.matmul(a1, w2), b2)
y_pred = sigmoid(l2)
diff = y_pred - Y
# Back prop (chain rule)
d_l2 = diff * sigmoid_prime(l2)
d_b2 = d_l2
d_w2 = torch.matmul(torch.transpose(a1, 0, 1), d_l2)
d_a1 = torch.matmul(d_l2, torch.transpose(w2, 0, 1))
d_l1 = d_a1 * sigmoid_prime(l1)
d_b1 = d_l1
d_w1 = torch.matmul(torch.transpose(X, 0, 1), d_l1)
w1 = w1 - learning_rate * d_w1
b1 = b1 - learning_rate * torch.mean(d_b1, 0)
w2 = w2 - learning_rate * d_w2
b2 = b2 - learning_rate * torch.mean(d_b2, 0)
if i % 1000 == 0:
l1 = torch.add(torch.matmul(X_test, w1), b1)
a1 = sigmoid(l1)
l2 = torch.add(torch.matmul(a1, w2), b2)
y_pred = sigmoid(l2)
acct_mat = torch.argmax(y_pred, 1) == Y_test
acct_res = acct_mat.sum()
print(acct_res.item())
if i == 10000:
break736
862
860
881
874
890
904
923
916
920
Nice to meet you. I would really appreciate your feedbacks. Thank you