
정리 카테고리
Lecture 2 formalizes the problem of image classification. We discuss the inherent difficulties of image classification, and introduce data-driven approaches. We discuss two simple data-driven image classification algorithms: K-Nearest Neighbors and Linear Classifiers, and introduce the concepts of hyperparameters and cross-validation.
Keywords: Image classification, K-Nearest Neighbor, distance metrics, hyperparameters, cross-validation, linear classifiers
slides:
http://cs231n.stanford.edu/slides/2017/cs231n_2017_lecture2.pdf
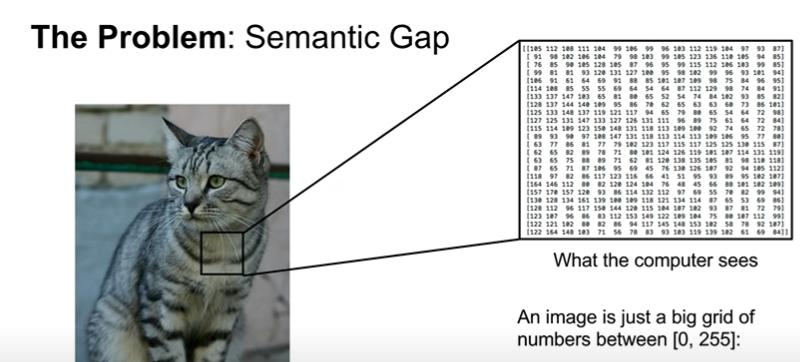
How do we work on this image classification task?
-
system input: images, predermined category labels
-
what computer really seas: just a grid
Challenges:
our classification algorithm should be robust at different kinds of transforms.
- Viewpoint variation
- Illumination
- Deformation
- Occulusion
- Background Clutter
- Intraclasss variation
Data-Driven Approach
- Collect a datasset of images, labels
- Use ML to train a classifier
- Evaluate the classifier on new images
Classifier
K-Nearest Neighbor
- majority vote among K
- tends to smooth out our decision boundaries and lead to better results.
- L1 distance, L2 distance
- dependent on problem or data
- so just reccomend to try them both and see what works better
- Actually, never used
- very slow at test time
- Distance metrics on pixels are not informative
- Curse of dimensionality
Hyperparamets
- choices about the algorithm that we set rather than learn
Setting Hyperparameters
-
Choose hyperparameters that work best on the data (Don't do this)
-> K=1 always works perfectly on training data -
Split data into
trainandtest; choose hyperparameters that work best on test data (Don't do this)
-> No idea how algorithm will perform on new data -
Split data into
trainandval, andtest; choose hyperparameters on val and evaluate on test (Better!) -
Cross-Validation: Split data in folds, try each fold as validation and average the results
Q. training set vs validation set
- algorithm doesn't have direct accesss to the labels of
validation set. - uses validation set
only for checkinghow well algorithm is doing.
Linear Classification
