🔎구글 뉴스 크롤링
구현하고자 하는 기능
키워드 검색하기
원하는 페이지까지 나오게 하기
🎈 기본세팅
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()url = "https://www.google.com/search?q=%ED%8C%8C%EC%9D%B4%EC%8D%AC&newwindow=1&sxsrf=ALiCzsZVk55WnQZg9Y2JEr7mSJL-m5YaWw:1672363518875&source=lnms&tbm=nws&sa=X&ved=2ahUKEwjU9-jLl6D8AhUw3TgGHWeUBVQQ_AUoAXoECAEQAw&biw=1866&bih=1051&dpr=1.8"
url.format("")
driver.get(url)🎈 요소를 제대로 찾았는지 확인해보기
titles = driver.find_elements(By.CLASS_NAME, 'mCBkyc')
for title in titles:
print(title.text) # 기사 제목 확인
contents = driver.find_elements(By.CLASS_NAME, 'GI74Re')
for content in contents:
print(content.text) # 기사 내용 확인
links = driver.find_elements(By.CLASS_NAME, 'WlydOe')
for link in links:
print(link.get_attribute('href')) # 기사 링크 확인 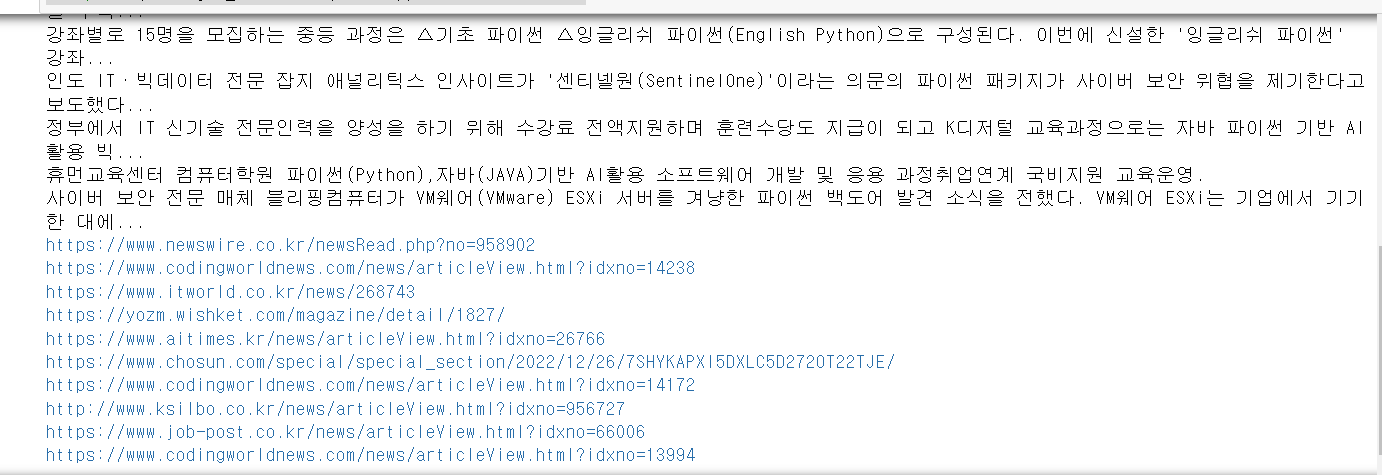
- 기사 제목과 내용, 링크주소가 제대로 출력되는 것을 볼 수 있습니다.
- href는 태그가 아니고
<a>태그안에 있는 요소이기때문에get_attribute('href')으로 작성해야합니다.
🎈 페이지가 넘어가는 규칙 찾기





1페이지 -> start=0
2페이지 -> start=10
3페이지 -> start=20
4페이지 -> start=30
5페이지 -> start=40
- 어떻게 페이지를 넘길까 고민하다가 url 주소의 규칙을 파악해보기로 했습니다. start={} 부분만 바꿔주는 것으로 페이지를 바꿀 수 있었습니다.
- XPATH 주소를 사용하는 방법도 있습니다.
🎈 키워드 검색
word = input("검색하고자 하는 단어를 입력해주세요!")
url = 'https://www.google.com/search?q={}&newwindow=1&tbm=nws&ei=TUmuY5LlINeghwOfw7egDQ&start={}&sa=N&ved=2ahUKEwjSv42woqD8AhVX0GEKHZ_hDdQQ8tMDegQIBBAE&biw=763&bih=819&dpr=2.2'
import time
import random
page = 1
title_list = []
content_list = []
link_list = []
timesleep = random.randint(1,10)
for i in range(0,20,10):
new_url = url.format(word, i)
driver.get(new_url)
time.sleep(3)
print("*"*10 + str(page) + "*" * 10)
page = page + 1
titles = driver.find_elements(By.CLASS_NAME, 'mCBkyc')
for title in titles:
title_list.append(title.text.replace(",", ""))
contents = driver.find_elements(By.CLASS_NAME, 'GI74Re')
for content in contents:
content_list.append(content.text.replace(",", ""))
links = driver.find_elements(By.CLASS_NAME, 'WlydOe')
for link in links:
link_list.append(link.get_attribute('href'))-
결과를 확인하기 위해 계속 실행하다보면 트래픽이 비정상적이라고 판단되어져서 로봇인지 확인하는 창이 나옵니다. 그래서 이와 같은 경우
time.sleep()을 사용하여 적당히 쉴 수 있게 하는 것이 중요합니다. 몇 초간 쉬는 것이 좋은지는 서버 상황에 따라 상이하나, 3초 정도 쉬어주면 서버에 크게 무리 주지 않고 접근 가능하다고 합니다.

-
replace는 해당 문자열의 일부분을 바꿔주는 함수입니다. 엑셀 파일로 변환될 때 제목과 내용에,(콤마)가 있는 부분을 제거해주기 위해 사용했습니다.🎈 엑셀 파일로 저장하기
num = len(title_list) for i in range(num): csv = open("google_news_test.csv", "a", encoding="UTF-8") csv.write("{}, {}, {}\n".format(title_list[i], content_list[i], link_list[i])) csv.close() -
for문은 출력된 title_list의 길이만큼 돌리면 됩니다.
-
가끔 인코딩 오류가 생겨서 encoding="UTF-8"을 추가했습니다.

^_^