DNS란 무엇인가?
- Domain Network System의 약자. 도메인 주소를 Ip주소로 바꿔주는 시스템이다. 간단히 말해서 www.naver.com을 172.24.85.82 같은 Ip주소로 바꿔주는 시스템이다.(저게 실제 ip주소는 아니다)
Domain Name Space
- www.google.com 같은 domain들을 분산,계층적 구조로 이루어진 space
DNS 서버
- DNS 서버는 DNS Recursor, Root Name Server, TLD Name Server, Authoritative Name Server(SLD Name Server)로 분류됨.
- DNS Cache가 존재하지 않는다면 위의 4개 서버를 순차적을 작동하여 IP주소를 클라이언트에 전달함
- DNS Recursor는 Resolver, Recursive DNS Server, Local Server, ISP(통신사) Server로 부르기도함.
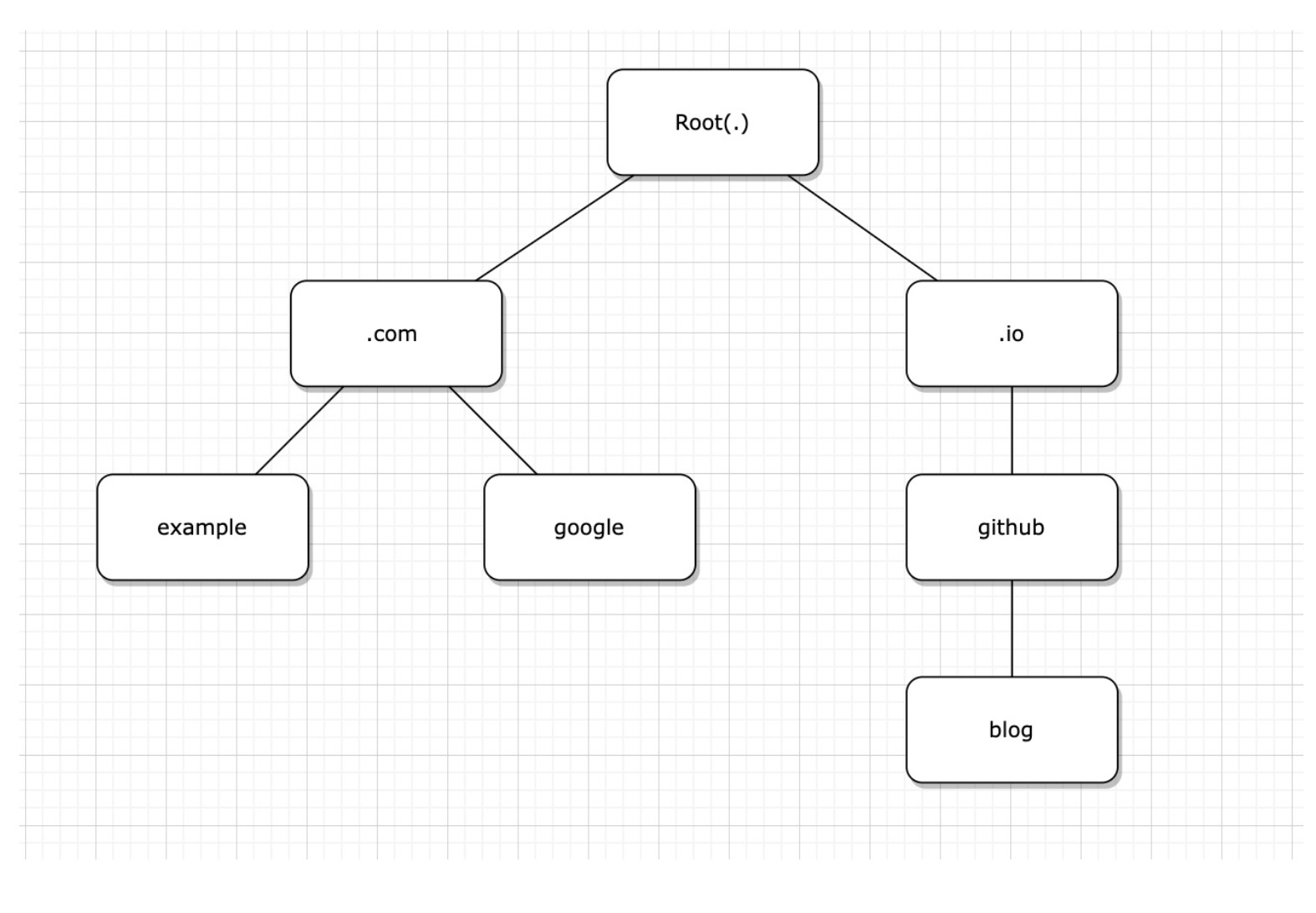
Root Name Server
- dns name space에서 최상위 경로를 담당
- 도메인주소 www.google.com(.)은 대부분 마지막 doot(.)이 생략되어 있는데, 이 doot을 담당하는 서버
- 도메인 확장자( .kr, .com)레이블을 구분해서 TLD 서버로 안내함
TLD(Top Level Domain) Server
- Authoritative Name server의 주소를 저장하고 그리로 안내하는 역할
- Root Name Server가 .com을 담당하는 TLD Server로 안내하면 TLD Server는 google.com을 담당하는 Autoritative 서버로 안내함
- TLD 서버는 (.com),(.net)과 같이 특정 국가에 종속되지 않는 일반 최상위 도메인과 (.kr)같이 특정 국가에 종속되는 도메인으로 나뉨
Authoritative Name Server(SLD Name Server)
- 일반적으로 DNS 서버의 가장 마지막 단계
- 실제 도메인과 IP주소의 관계가 기록,저장,변경되는 서버
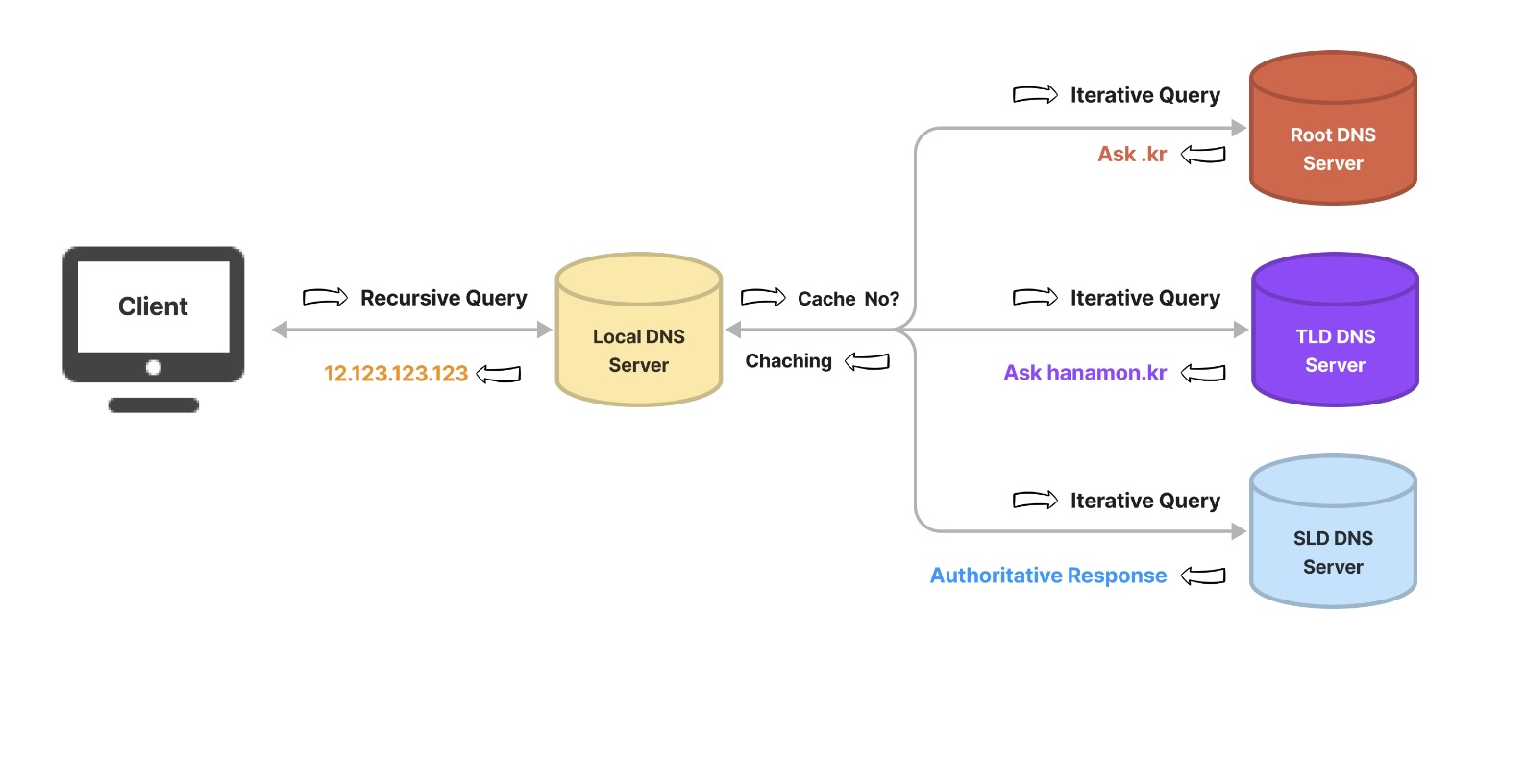
DNS Recursor
- 클라이언트의 요청을 받아서 Name Server로 전달하고 반환받은 IP주소를 다시 클라이언트에 전달하는 중계자 역할의 서버
- 이 과정에서 계층 구조의 서버에서 순차적으로 반환하는 결과를 재귀적으로 탐색 (재귀적으로 탐색한다는 게 무슨 말인지 잘 모르겠음)
- 최종 결과를 DNS Cache에 저장 해서 나중에 똑같은 요청이 오면 즉시 반환해서 불필요한 탐색을 하지않음

DNS Query
- DNS 클라이언트와 DNS 서버는 DNS Query를 교환해서 요청과 응답을 함
Recursive Query
- client와 DNS Recursor 사이의 통신에 사용되는 쿼리
- 실제 IP주소를 반환
Iterative Query
- DNS Recursor와 Name Server 통신에 사용되는 쿼리
- 반복적으로 쿼리를 보내 Ip주소를 알아내서 DNS Recursor에 IP주소를 보내줌
- DNS Recursor에 캐싱되어 있으면 이 쿼리는 안 보냄
DNS의 동작과정
- www.naver.com을 검색창에 치면 내 단말에 있는 hosts란 파일을 찾아본다. 여기에 Ip주소가 적혀있으면 그 Ip주소로 요청을 보낸다.(Hosts파일이 DNS보다 우선순위가 높다)
- Ip주소가 없다면 DNS Recursor에 recursive Query로 요청을 보낸다. DNS Recuror에 Ip주소가 캐싱되어 있으면 이 주소를 클라이언트에게 보내고 끝나고 없다면 root서버에 iterative query를 보내 .com서버가 어디 있는지 물어본다.
- 루트서버는 .com을 담당하는 TLD 서버가 어디 있는지 iterative query로 DNS Recursor에 응답한다.
- DNS Recursor는 .com을 담당하는 TLD 서버에 iterative query로 .google을 담당하는 authoritative name server가 어디 있는지 물어보고 TLD서버는 이에 응답한다.
- DNS Recursor는 google.com을 담당하는 authoritative 서버에 iterative query로 google.com라는 주소가 있는지 물어보고 있다면 authoritative 서버는 google.com의 IP주소를 응답한다.
- DNS Recursor는 받은 Ip주소를 캐싱하고 클라이언트에게 이 주소를 Recursive query로 전달한다.
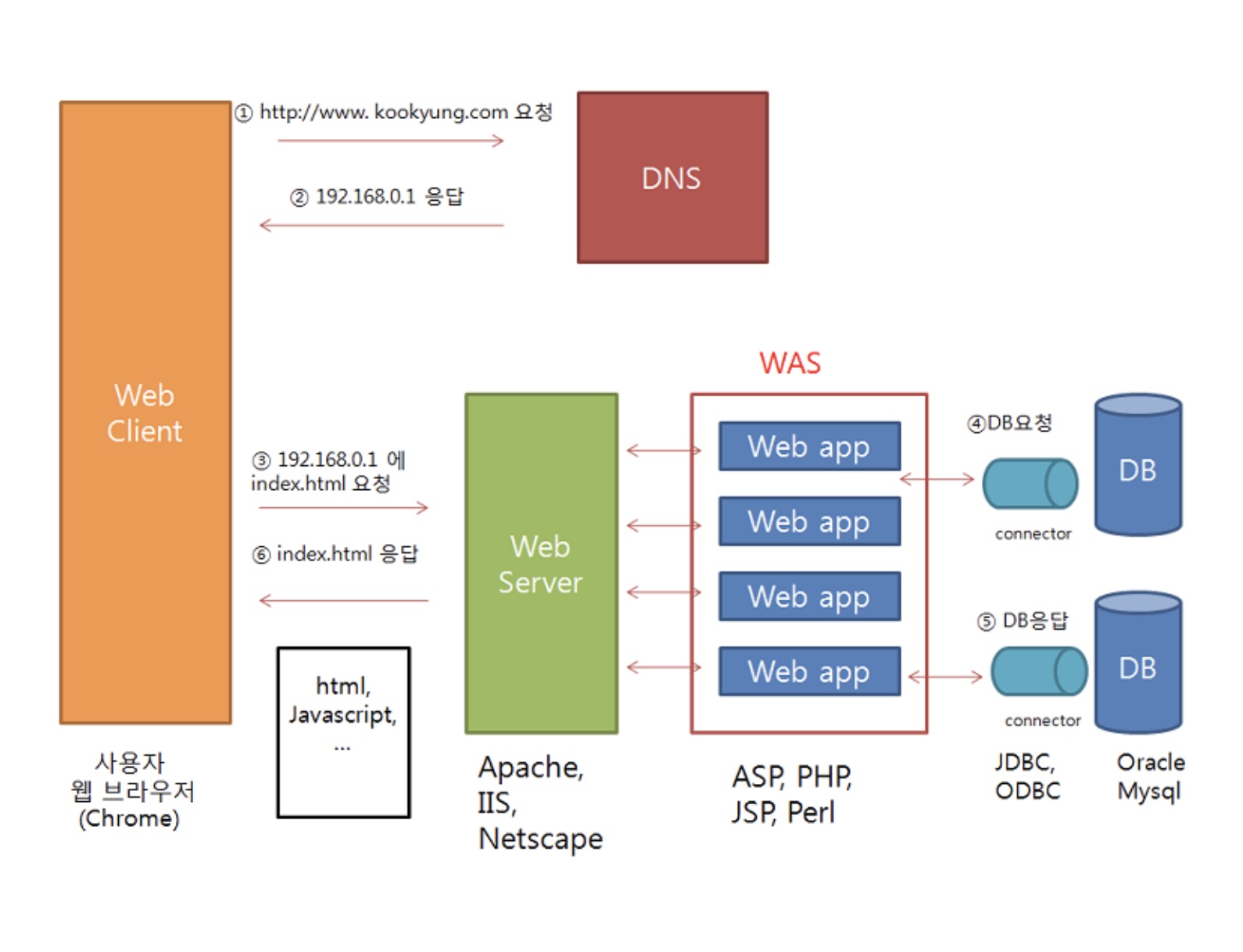
- 네이버의 경우 서버가 4개여서 Ip주소가 4개임. DNS가 이 4개의 Ip주소를 브라우저에 알려주면 브라우져는 이 중 하나의 Ip주소에다가 요청을 보냄(DNS단에서의 로드밸런싱)
- 웹 서버는 요청을 받았을 때 웹 어플리케이션 서버(WAS)의 도움이 필요한 경우(동적인 요청이나 DB연결,JSP,PHP,ASP등) WAS에 필요한 것들을 요청함(DB서버와의 연결 등 보안상의 문제가 있기 때문에 WAS는 웹서버를 통해 요청을 받음)
- WAS의 처리결과를 웹서버가 받아서 웹 서버는 브라우져에게 response를 전달
- status code
-1xx: 정보만 갖고 있는 메세지
-2xx: response 성공
-3xx: 클라이언트를 다를 URL로 리다이렉트
-4xx: 클라이언트 측 에러발생
-5xx: 서버 측 에러발생
참고: https://velog.io/@eassy/www.google.com%EC%9D%84-%EC%A3%BC%EC%86%8C%EC%B0%BD%EC%97%90%EC%84%9C-%EC%9E%85%EB%A0%A5%ED%95%98%EB%A9%B4-%EC%9D%BC%EC%96%B4%EB%82%98%EB%8A%94-%EC%9D%BC
https://velog.io/@park-moen/devcourse-study01
DNS는 TCP와 UDP 중 어떤 걸 사용할까?
- 기본적으로 UDP를 사용하지만 특정상황에서는 TCP를 사용해서 안정성을 더 보장한다.(DNS는 연결상태를 유지할 필요가 없기도하고, 신뢰성보다는 빠른응답이 더 중요하기때문)
- UDP의 패킷은 512바이트보다 클 수 없기 때문에 이보다 큰 패킷 사용시 TCP를 사용
(나중에 더 공부하기)
DNS쿼리 과정에서 손실이 발생하면?
- DNS는 각 패킷의 체크섬 값을 계산해서 데이터 무결성을 검사하고 데이터가 손상된 것을 감지하면 수신 측에서 패킷을 폐기한다.
- DNS 클라이언트는 요청에 대한 응답을 일정시간 내에 받지 못하면 재시도한다. DNS 서버도 마찬가지로 응답을 일정시간 내에 보낼 수 없으면 재시도한다.
DNS 레코드 타입
- DNS 레코드는 DNS에 저장되는 정보의 타입이다.
- A 타입: 도메인과 Ipv4주소를 매핑,일대일대응일 필요 없음
ex) naver.com과 121.53.105.234 매칭, naver.com에 121.53.105.234, 121.22.10.202 이렇게 두 개를 매칭시킬 수도 있다.(실제로 네이버는 서버를 4개 운영한다) - AAAA타입: 도메인과 Ipv6주소를 매핑,마찬가지로 일대일대응일 필요 없음
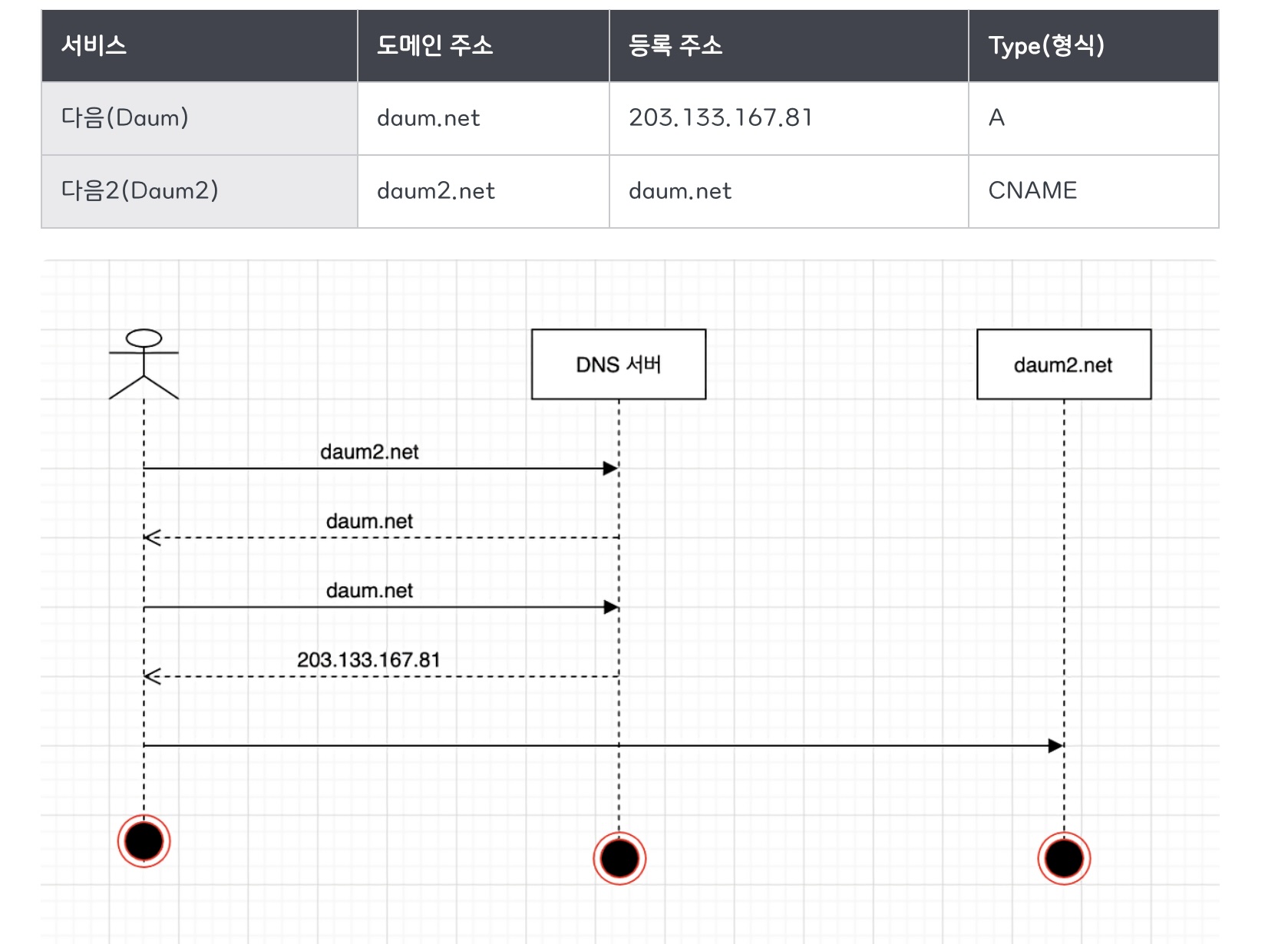
- CNAME타입: 도메인과 또 다른 도메인 주소를 매핑
ex) daum2.net을 daum.net과 매핑
참고: https://win100.tistory.com/360
Web server와 Web Application Server의 차이
- 웹 서버는 클라이언트의 요청에 대해 html문서 같은 정적 콘텐츠를 전달해주기 위한 목적이 크고, 웹 에플리케이션 서버는 동적인 요청을 처리해주기 위한 목적이 크가.
- 웹 서버는 클라리언트가 url을 주소창에 입력하면 http 요청을 받아들여 html문서 같은 정적인 콘텐츠를 사용자에게 전달해주는 게 주 목적
- 웹 에플리케이션 서버는 웹서버에서 할 수 있는 대부분의 기능이 제공되고 웹서버와 마찬가지로 http기반으로 동작한다. 서버사이드 코드를 처리할 수 있어
서 동적인 요청을 처리할 수 있고 주로 데이터베이스 서버와 함께 수행한다. - 웹 에플리케이션 서버가 웹 서버의 기능도 할 수 있는데 그럼 웹 서버는 왜 쓰는 거냐? 부하를 덜기 위해서 웹 에플리케이션 서버는 동적 요청에 집중하고 정적인 요청은 웹 서버에서 담당하게 해서 서버의 부하를 줄일 수 있다.
- 웹 서버도 CGI(웹 서버에서 프로그램을 동작시키기 위한 방법을 정의한 프로그램)라는 인터페이스를 통해서 동적인 요청을 처리할 수 있다.(그렇지만 비효율적이다.)
참고: https://story.pxd.co.kr/1647
URL,URI,URN
-
우선, URL과 URN은 URI에 포함되는 개념이다
-
URI: 인터넷에서 자원을 식별할 수 있는 문자열을 의미한다. 그리고 특정 형식을 따르는 URL과 URN은 URI의 한 종류이다. 인터넷에 있는 각 자원마다 유일해야한다.
-
URL: scheme:hosts:url-path:query 의 형태를 가짐
http://www.google.com:80/search?q=JavaScript 이면
-scheme: 통신 방식(프로토콜)을 결정한다. 일반적인 웹 브라우저에서는 http(s)를 사용.(http://)
-hosts : 웹 서버의 이름, 도메인, IP를 사용하며 주소를 나타낸다.(www.google.com:80)
-url-path : 웹 서버에서 지정한 루트 디렉토리부터 시작하여 웹 페이지, 이미지, 동영상 등이 위치한 경로와 파일명을 나타낸다.(/search)
-query : 웹 서버에 보내는 추가적인 질문이다 (?q=JavaScript)
참고: https://hanamon.kr/%EB%84%A4%ED%8A%B8%EC%9B%8C%ED%81%AC-%EA%B8%B0%EB%B3%B8-url-uri-urn-%EC%B0%A8%EC%9D%B4%EC%A0%90/ -
URN: 이름으로 리소스를 특정하는 URI
-리소스 접근방법(프로토콜)과 웹 상에서의 위치가 표시되지 않음
-리소스 자체에 부여된 영구적이고 유일한 방법이고 변하지 않음
-실제 자원을 찾기위해 URN을 URL로 변환해서 사용함
