데이터베이스
1.RDB와 NOSQL의 차이

rdb는 엄격하게 정의된 schema에 기반한 테이블 구조를 가지고, nosql은 테이블형식이 아닌 비정형데이터를 저장할 수 있다.따라서 rdb는 데이터의 중복이 없기 때문에 데이터 update가 많을 때 유리하고, nosql은 update시 중복된 데이터의 값을 모두
2.스프링 프로젝트와 Mysql 데이터베이스 연동
원래 h2 데이터베이스와 연동했던 스프링 프로젝트를 Mysql 데이터베이스로 옮겨주려고 했다.Mysql은 설치되어 있는 상황이었고, 이미 instance도 있었다. https://growth-coder.tistory.com/111 을 참조해서 진행했다.buil
3.데이터베이스의 index
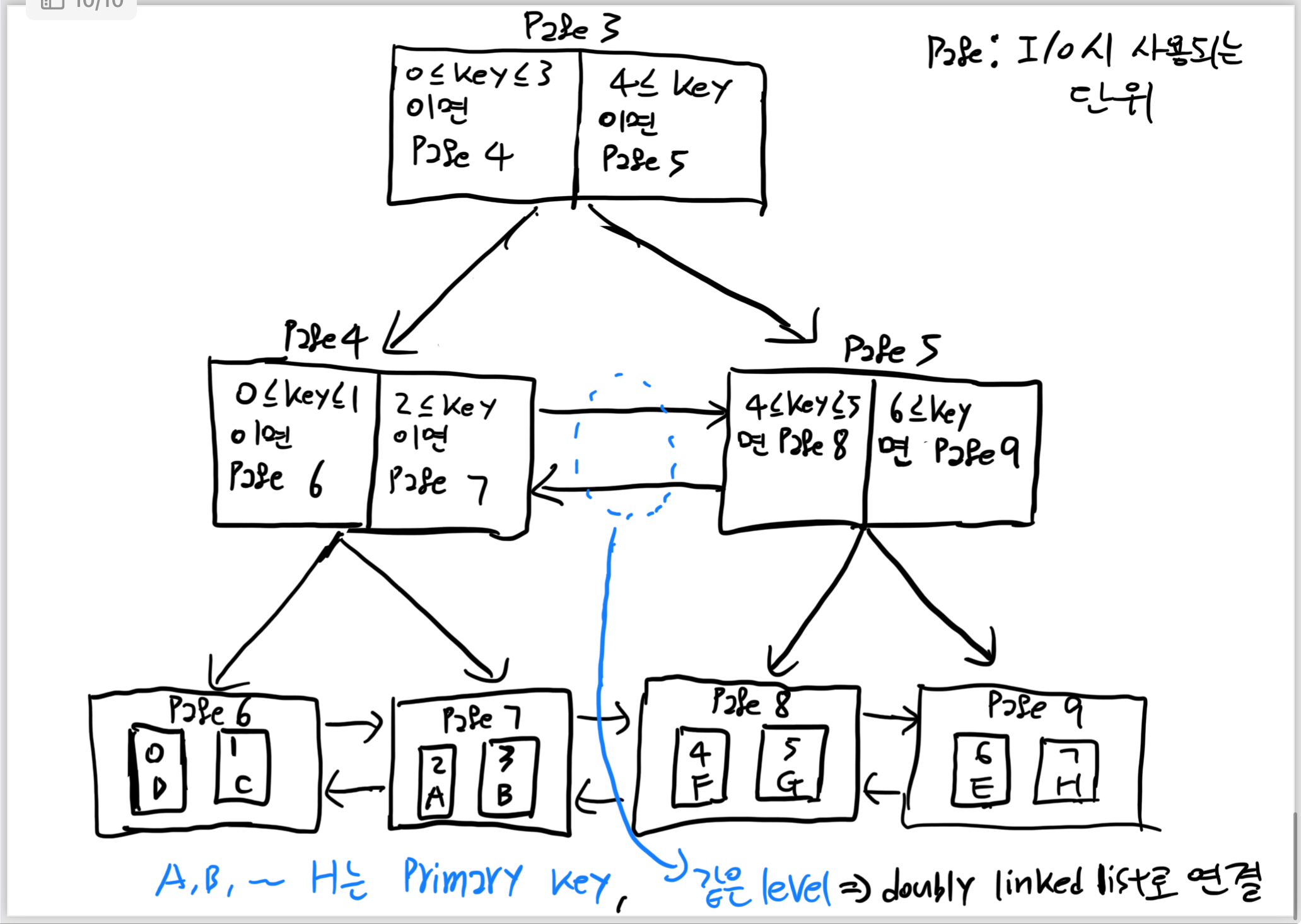
검색을 빠르게 하기 위한 자료구조, 컬럼의 값을 사용하여 항상 정렬된 상태를 유지(예를 들어, employee 테이블이 있다면 department가 index가 될 수 있다.)MYsql innoDB에서는 B+tree같은 변형 B-tree로 이루어져 있다.참고: http
4.sql 실행순서
SQL 실행순서 , select문에서 sql의 실행순서1.from,join2.where3.group by4.having5.select6.order by
5.having은 개별행이 아니라 그룹화된 결과에 적용된다.
having은 group by 뒤에 group by에 의해 그룹화된 결과에 대해 적용된다. where처럼 개별 행에 적용되는 것이 아니다.예시를 보자.🎯 부서별 평균 급여가 5000 이상인 부서만 조회하기여기서 HAVING은 부서에 의해 그룹화된 각각 부서그룹에
6.GROUP BY에 명시하지 않은 열은 다중행 함수 없이 SELECT문에 들어갈 수 없다.
문제 상황다음과 같은 orders 테이블이 있다고 가정하자.order_id customer product price1 A Apple 1002 A Banana 2003 B Apple 1504 B Banana 2505 B Apple 300이제 고객(customer)별 총