DB의 index란
검색을 빠르게 하기 위한 자료구조, 컬럼의 값을 사용하여 항상 정렬된 상태를 유지
(예를 들어, employee 테이블이 있다면 department가 index가 될 수 있다.)
DB의 index의 자료구조
MYsql innoDB에서는 B+tree같은 변형 B-tree로 이루어져 있다.
참고: https://velog.io/@chanyoung1998/B%ED%8A%B8%EB%A6%AC (B트리)
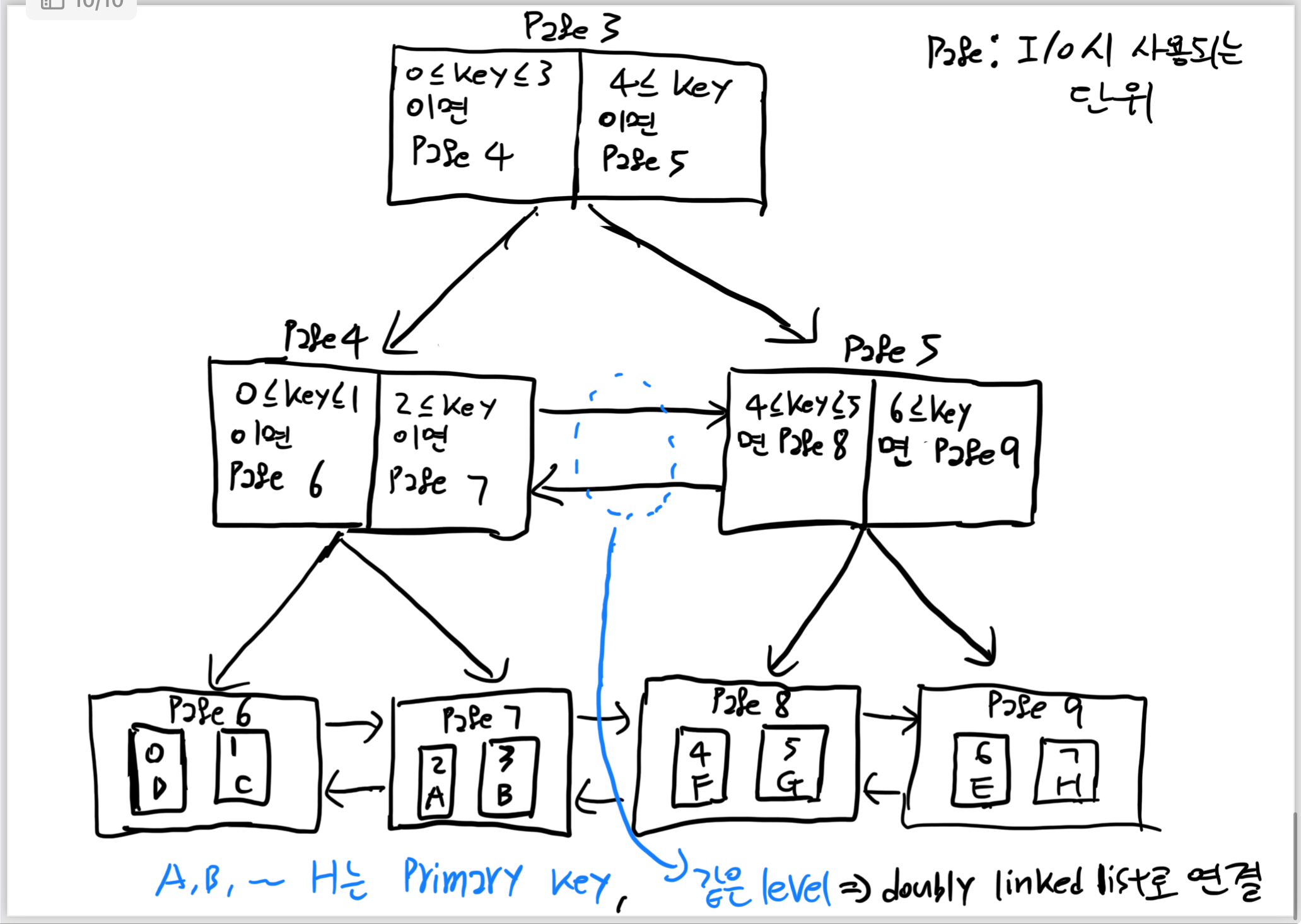
Index를 이용한 검색
- secondary index를 이용해 데이터의 PK를 찾음
- PK를 이용해 row를 찾음
의 구조.
아래는 B+트리를 이용해
secondary index(0~7, 사진에서 key = index, 실제 DB에서는 department등 컬럼값)를 통해
데이터의 PK(A~H, 실제 DB에선 ID 등 Primary key)를 찾는 1번 과정이다.
이를 통해 PK를 찾으면 PK를 가지고 다시 한 번 B+트리를 이용해 데이터를 찾는다
Index를 이용한 검색의 장점
만약 index를 이용하지 않으면 테이블을 처음부터 끝까지 다 뒤져야한다 -> 디스크 IO작업이 훨씬 늘어나 성능저하가 발생
Index를 이용한 검색의 단점
인덱스를 관리하기 위해 DB의 약 10%에 해당하는 저장공간이 필요하다.
인덱스를 관리하기 위해 추가 작업이 필요하다.(index 업데이트,삭제 등)
인덱스를 잘못 사용할 경우 오히려 성능이 저하되는 역효과가 발생할 수 있다.
(만약 테이블의 25퍼센트 이상의 데이터 조회시 인덱스를 이용하지 않는 것이
효율적이다.)
출처: https://mangkyu.tistory.com/96 [MangKyu's Diary:티스토리]

해줘잉...