
저는 졸업 프로젝트로 '코소롱'이라는 사투리 책 & 오디오북 어플리케이션을 만들고 있습니다.
표준어 텍스트가 들어오면 이를 제주 방언으로 번역하여 e-book을 만들고, 이를 제주 사투리를 살려 발화하는 서비스입니다.
구현을 위해 저희 팀은 기계번역과 음성합성으로 조를 나눠 학습시키고 있습니다.
저는 그 중 음성합성 조에서 열심히 삽질을 하고 있는데요.
궁극의 삽질이라고 할 수 있는 학습 데이터를 전처리하는 과정을 함께 알아봅시다!
1. Tencent GCC(GPU Cloud Computing) 사용하기
먼저 많은 양의 데이터를 학습시키기 위해서 학교에서 지원받은 Tencent의 GCC를 사용하고자 합니다.
Tencent에서 instance를 만든 뒤 Terminal 접속한 뒤,
pip3 설치
sudo apt-get update
sudo apt-get install python3-pip -yCUDA 설치
설치파일 다운받기
curl -O http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64/cuda-repo-ubuntu1604_8.0.61-1_amd64.deb
sudo dpkg -i ./cuda-repo-ubuntu1604_8.0.61-1_amd64.deb
sudo apt-get update
sudo apt-get install cuda-9-0설치되었는지 확인
nvidia-smicuDNN 설치
설치파일 다운받기
sudo sh -c 'echo "deb http://developer.download.nvidia.com/compute/machine-learning/repos/ubuntu1604/x86_64 /" >> /etc/apt/sources.list.d/cuda.list'
sudo apt-get update
sudo apt-get install libcudnn7-dev딥러닝 관련 기타 라이브러리 설치
pip3 install tensorflow-gpu torch torchvision keras
pip3 install jupyter sklearn matplotlib seaborn pandasjupyter notebook 설정
configuration file 생성하기
jupyter notebook --generate-config~/.jupyter/ 폴더 안에 config 파일 열기
vi ~/.jupyter/jupyter_notebook_config.py설정 수정하기
c = get_config()
c.NotebookApp.ip = '000.000.000.000'
c.NotebookApp.open_browser = False
c.NotebookApp.port = 1111-
000.000.000.000 위치에는 Tencent에서 할당받은 외부 IP 입력하기
-
1111은 방화벽을 만들 때 설정한 포트 입력하기
주피터 실행하기
jupyter notebook --ip=0.0.0.0 --port=1111 --allow-root웹 브라우저 상에서 000.000.000.000:1111 의 주소 형태로 입력하면 주피터 노트북에 접속 가능!
주피터에서 torch 패키지를 이용해서 GPU를 쓸 수 있는지 확인쓰

이제 GPU 쓸 준비 끝!
2. 학습 데이터 수집하기
https://www.kaggle.com/bryanpark/jejueo-single-speaker-speech-dataset
제주 사투리를 학습시키기 위해 위의 데이터를 사용하고자 합니다.
이 JSS(Jejueo Single Speaker Speech)는 총 10,000개의 문장, 13시간 47분 분량의 데이터입니다.
제주어 단일 화자의 발화 음성 오디오와 화자가 말한 내용을 옮겨 적은 텍스트로 구성되어있습니다.
3. 음성 데이터 전처리하기
스크립트는 데이터셋을 만드신 분께서 이미 완벽하게 만들어주셨기 때문에 저는 음성에 좀 더 손을 대볼 것입니다.
음성 데이터 또한 이미 잘 구축되어있지만 더 좋은 데이터를 캐내기 위해서 앞뒤의 공백을 제거하고, 음성의 Sampling Rate을 변경하고자 합니다.
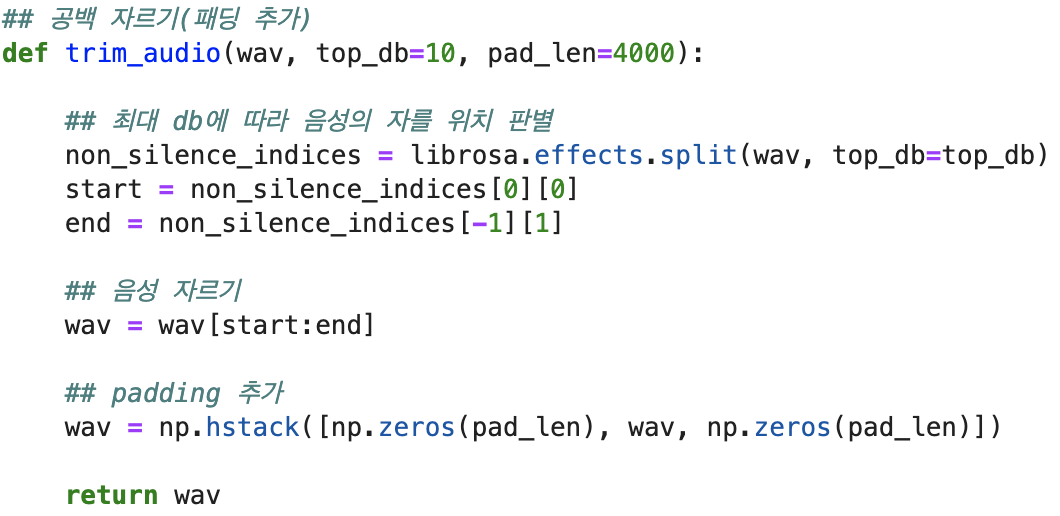
먼저 공백을 자르도록 하겠습니다.
최대 db을 기준으로 음성을 자를 위치를 판별하고, 음성을 자릅니다.
하지만 너무 타이트하게 앞뒤 공백을 자르면 모델을 학습시켰을 때, 가장 앞에 나오는 소리를 묵음처리할 가능성이 있기 때문에 적당한 padding을 추가해줍니다.
이를 구현한 함수입니다.
샘플 데이터로 확인해보겠습니다.
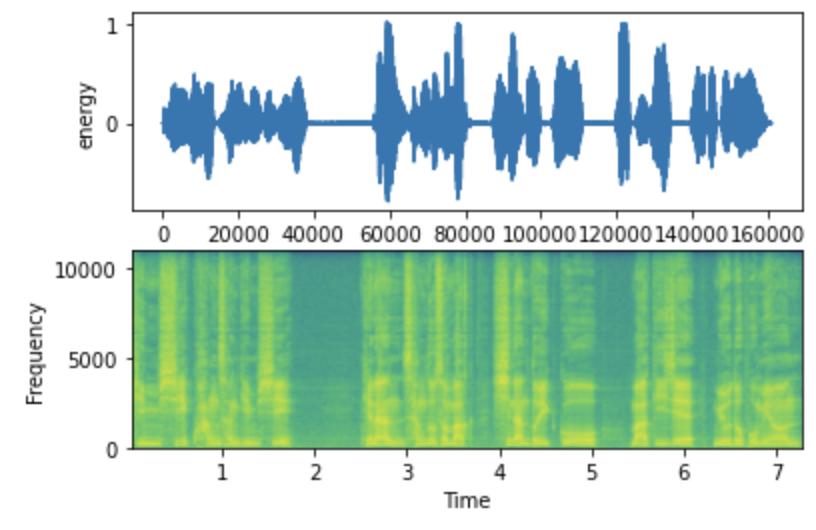
위는 Trim 코드 사용 전의 음성입니다.
살펴보니 앞뒤로 공백이 전혀 없이 바로 오디오가 나오는 것을 볼 수 있습니다.
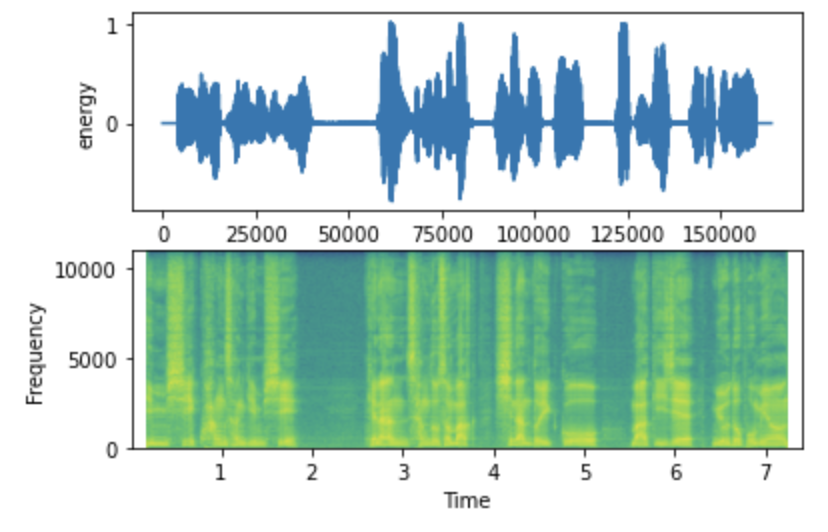
그리고 Trim 코드 사용 후의 음성입니다.
확실히 앞뒤로 약간의 padding이 들어가 듣기에 더 편하다고 느낄 수 있었습니다.
저는 전처리 후 Tacotron2와 WaveGlow를 사용하여 TTS를 구현할 것입니다.
Tacotron2는 기본적으로 22050 Sampling Rate에서 동작하기 때문에 Sampling Rate을 이와 같이 변경하였습니다.
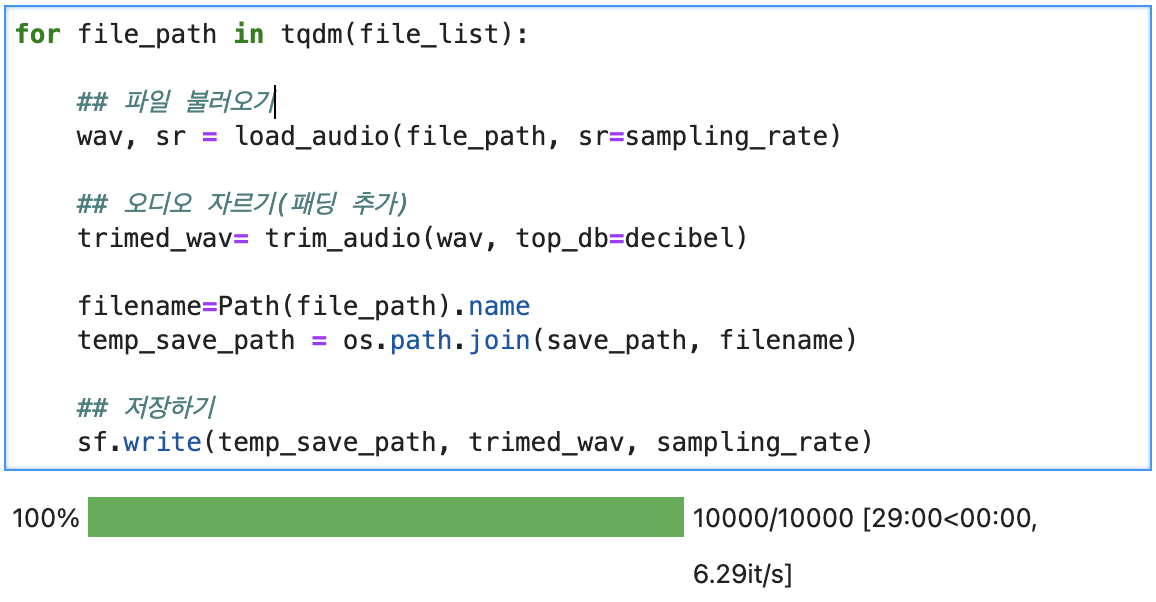
위의 과정을 토대로 전체 데이터를 전처리하였습니다.
시간은 29분 정도로 오래 걸리지는 않았습니다.
뭔가 신기하더군요..
4. 학습 정보 파일 만들기
이제 Tacotron2에 전달할 학습 정보 파일을 만들어 보겠습니다.
이는 음성 파일의 위치와 음성 발화 스크립트로 구성된 병렬 데이터입니다.
예시는 다음과 같습니다.
/Users/Desktop/Capstone/JSS/jss_trim/1.wav|예, 그건 한 칠백년 전에 이제 그 설촌이 시작이 되었다고 헙니다.
/Users/Desktop/Capstone/JSS/jss_trim/2.wav|예. 칠백년 전에 설촌이 뒈엇는데 이제 그루후에 이제 성씨들이 여러 성씨들이 많이 와가지고 현재는 ᄒᆞᆫ 팔십여 성씨. 경 뒈서마씀.
/Users/Desktop/Capstone/JSS/jss_trim/3.wav|예. 그러면은 칠백년부터 허는데 설촌할 때 어떤 성씨들이 헷덴 말도 이신가마씨?
이러한 구성으로 학습데이터와 검증데이터를 만들어줍니다.

여러분 시력을 조심하십쇼.
저는 이 과정에서 많이 잃었습니다...
이렇게 Tacotron2 학습 전까지의 데이터 전처리 과정을 함께 알아보았습니다.
다행스럽게도 양질의 데이터셋을 찾아서 수월하게 전처리를 마칠 수 있었습니다.
저는 빨리 글을 올리고 Tacotron2를 돌려보러 갈 것입니다.
아주 기대가 됩니다..

재미있게 잘 읽었어요~