
이번 시간엔 드디어 스테이블 디퓨젼을 배웠다~~
이미지생성모델~~ 암만봐도신기해~~~
하지만 그 전에! 강사님께서 기본지식으로 머신러닝과 생성 모델에 대해 설명해주셨다.
그래서 오늘 학습순서는~~
- 머신러닝
- 이미지 생성 모델
- stable diffusion
순으로 이루어져있었다!
1. 머신 러닝
개념
머신러닝은 크게 세 가지로 이루어진다.
- 경험(experience)에 의한 학습
- 업무(task)
- 성능(performance) 측정 지표
👉 ex. 정확도
👉 학습할수록 성능이 올라가야함! (우리가 시험을 위해 n회독 하는것처럼)
👉 올라가야. 머신러닝이라 불러줄수 있음.
이를 모두 포함해서 머신러닝을 설명하자면
🔻
머신러닝은 경험에 의한 학습(1)으로 수행한 업무(2)에 대한 성능(3) 향상을 지향하는 인공지능 학습 기법이다.
작동 원리
머신러닝은 어떻게 학습되며 결과를 낼 수 있을까?
우선 머신러닝에서의 학습은 Learning이 아니라 Training의 의미를 지닌다!!
그래서 이는 주어진 학습자료를 '공부'하기보단 '훈련'하는 느낌으로 이해할 수 있다.
구체적으로 설명하면 아래와 같다.
-
훈련을 위한 예시(데이터)들이 주어진다.
-
컴퓨터에게 데이터를 바라보는 방법(모델)과 예시(데이터)를 주면 판단을 내리는 기준(패턴)을 찾아낸다.
👉 이 때, 컴퓨터는 숫자(0,1)밖에 이해하지 못하므로, 모든 것은 수학적 기준에 의해 판단된다. -
학습을 토대로 컴퓨터가 예측한 결과를 정확도 등의 성능 측정 지표로 나타낸다.
-
틀린 정도(loss)를 확인하며 ⭐오답정리(update)⭐를 수행한다.
-
Loss를 줄여가는 방향으로 계속 학습한다.
목표
그래서 이렇게 학습하는 이유는 무엇일까? 목표가 무엇일까?
머신러닝의 목표는 예측을 잘 하는 것이다!
학습하지 않은(unseen, not-trained) 데이터에 대한 예측을 잘하는 것.
즉, 내가 학습시킨 데이터와 unseen(test) 데이터의 패턴이 비슷하도록 만드는 것이다!
예를 들어, 수능을 잘 보기 위해 이와 비슷한 형식들의 문제(모의고사 등)을 계속 푸는 것 처럼 말이다.
🪄 머신러닝의 개념과 원리 끝!
2. 이미지 생성 모델
개념
- 생성모델 = 원본 데이터의 분포를 추정하여 👉 새로운 결과물을 생성하는 모델
- 텍스트 생성 모델 = 단어의 분포를 추정하여 👉 다음 단어를 예측
- 이미지 생성 모델 = 픽셀의 분포(패턴)를 추정하여 👉 새로운 이미지 생성
Auto encoder
생성 모델에서 알아야 할 중요한 것은 auto encoder이다!
앞서 말했던 것처럼 생성 모델에는 예시로 넣을 입력값과 생성 결과물인 출력값이 있다.
이 때, 입력값이 들어가는 부분을 encoder라고 한다.
반대로 출력값이 나오는 부분은 decoder!
이 인코더와 디코더가 포함된 모델로 auto encoder가 있다~
🔻 auto encoder는 아래와 같은 순서로 작동한다.
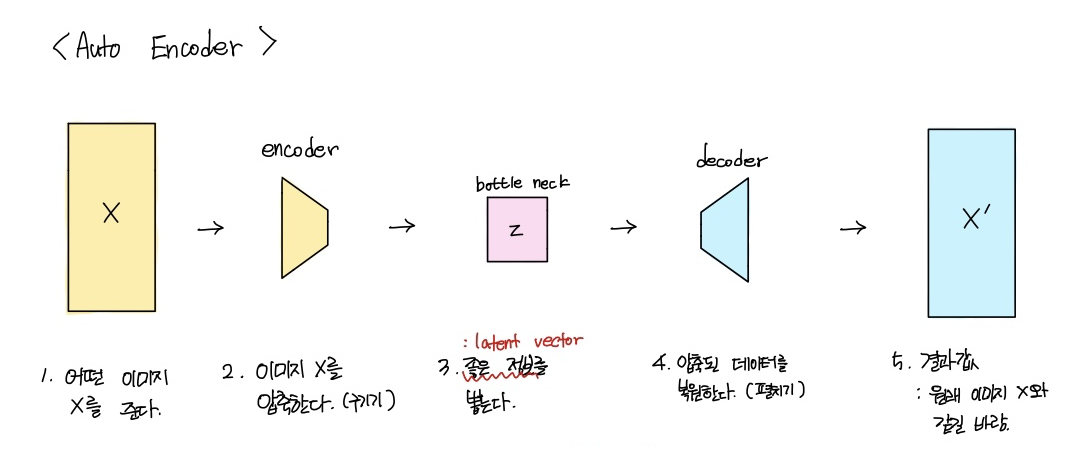
3번 과정에서 auto encoder의 목표를 찾아볼 수 있다.
이미지를 단지 압축만 하는 것이 아니라, 좋은 정보만 압축하는 z를 만드는 것이다!
💡 이때, 좋은 정보란 input image를 압축했을 때 복원이 잘 되는 정보를 의미한다.
-> (압축된 값을 펼쳤을(복원했을) 때 원본과 똑같으면 👍👍👍)
💡 또한 압축은 기존 정보를 뽑아내는 것이 아닌 이를 활용해 새로운 벡터를 만드는 작업이다.
VAE(Variational AutoEncoder)
auto encoder의 목표에 방향성을 더한 모델이다.
즉, 좋은 정보 압축에 prior(특정 방향성, 가이드)를 추가로 넣어 인코딩하는 방식이다.
auto encoder에 비해 더 복잡한 연산의 이미지 생성 및 보간이 가능하다.
📍 prior 예시
- input 이미지
- 텍스트
- 원하는 스타일 등의 추가정보
GAN(Generative Adversarial Network)
그 이후에 나온 모델로 GAN이 있다.
오늘 주제는 GAN이 아니기 때문에, 특징만 간단히 짚고 넘어가도록 하겠다.
좋은 정보를 압축하는 것이 목표인 auto encoder에 비해,
GAN은 원본과 같은 이미지를 생성하는 것이 목표이다. 따라서, 그러한 이미지가 만들어졌을 때 학습이 완료된다!
지금까지의 특성들을 활용해서 stable diffusion의 모델인 Latent Diffusion Model이 등장하였다!
3. Stable Diffusion
main idea
크기가 크지 않은 고퀄리티의 이미지를 빠르게 생성할 수 없을까?
solution
main idea를 만족하기 위해 사용한 솔루션은 auto encoder였다.
auto encoder로 이미지를 압축(compression)하여 원본 이미지 크기를 줄여 가볍게 만든것이다!
그래서 기존 이미지 생성 모델은 무게가 무거워 일반 컴퓨터에서는 돌릴 수 없었는데, stable diffusion이라는 이미지 생성 모델은 경량화가 이루어져 코랩에서도, 일반 노트북 등에서도 충분히 돌릴 수 있게 되었다!
Latent Diffusion Model
그러한 짱디퓨전 모델을 더 자세하게 살펴보자!
동작 원리
latent diffusion model의 근간이 되는 diffusion model의 원리는 다음과 같다.
- 아래 사진(1)과 같이 원본 이미지에 노이즈를 추가한다.

- 복원과정을 수행하면서 노이즈 사이에서 필요한 정보만을 추출한다. 그리고 완성!
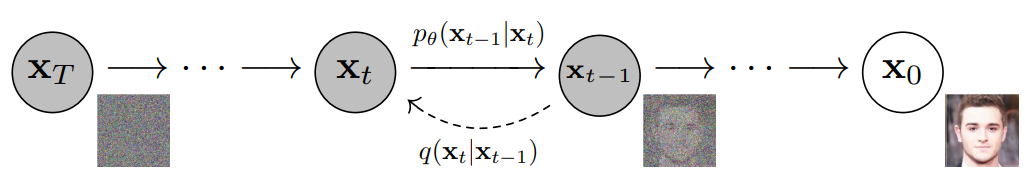
구조
위에서 소개한 diffusion model의 속도가 느리다는 것을 보완해 나온 모델이 바로 latent diffusion model이다.
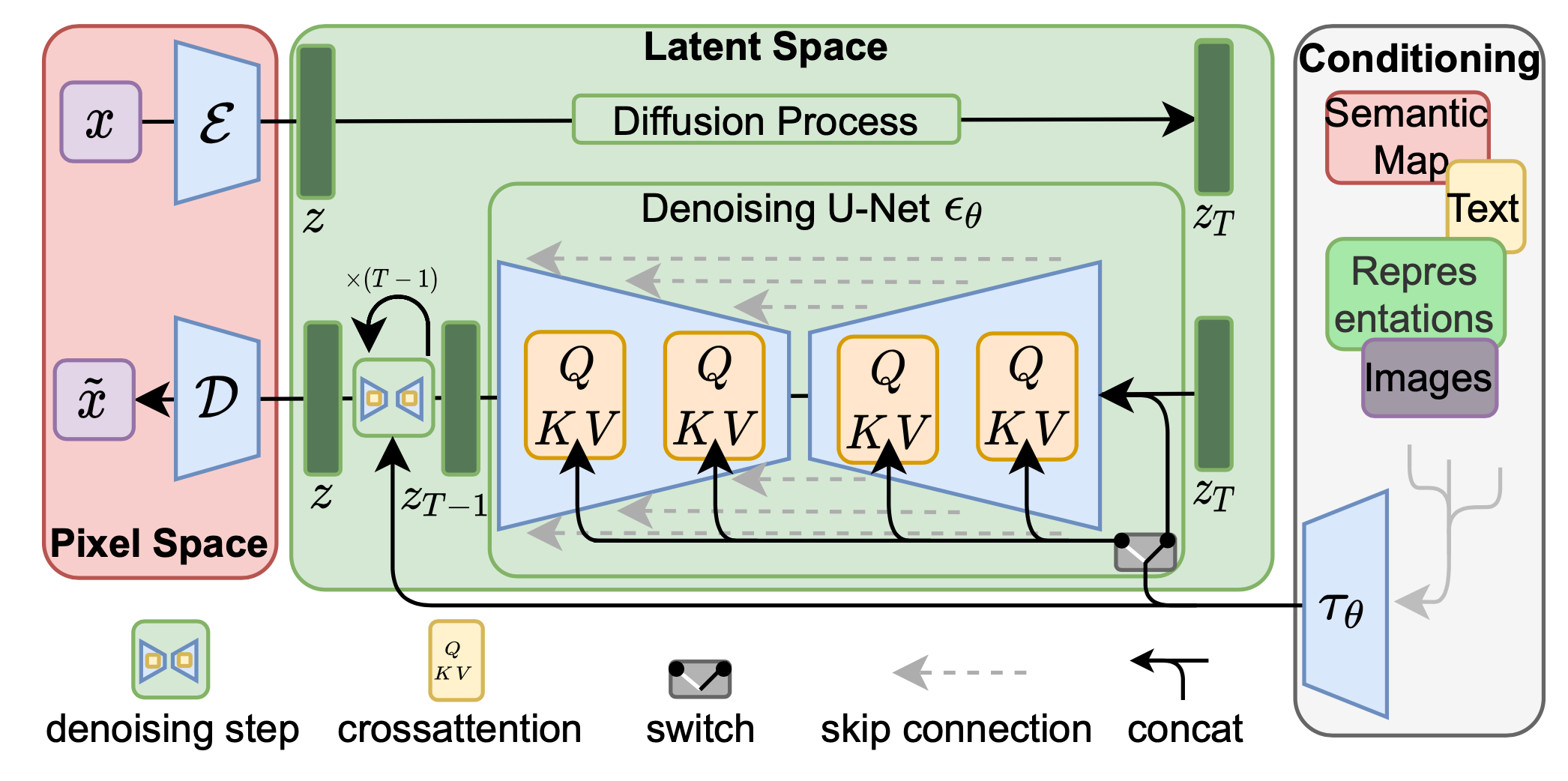
이 구조(2) 의 위와 아래를 나누어 볼 수 있다. 정방향으로 가는 부분부터 살펴보겠다.
-
encoder
: pixel space의 윗부분인 인코더에 데이터를 넣어 압축한다. -
노이즈 추가
: 인코딩된 데이터가 diffusion process를 거친 후, random noise가 더해진 데이터가 된다. -
variation
: 텍스트나 이미지 등 원하는 스타일의 가이드를 제공한다. -
denoising
: 이제 역방향으로 진행되는 과정을 살펴보자. u-net에서 노이즈를 제거하는 작업을 진행한다. -
decoder
: 디코더를 통해 우리가 원하는 이미지를 출력한다.
💡 따라서, random noise가 추가된 이미지를 가지고 condition에 맞는 이미지로 잘 뽑아내는 것이 stable diffusion의 목표라고 할 수 있다!
[출처]
강의: https://event-us.kr/pgdai/event/58478
(1) https://www.assemblyai.com/blog/diffusion-models-for-machine-learning-introduction/
(2) https://lilianweng.github.io/posts/2021-07-11-diffusion-models/
