1. Stable Diffusion
해당 논문: https://arxiv.org/abs/2112.10752
모델 구조도
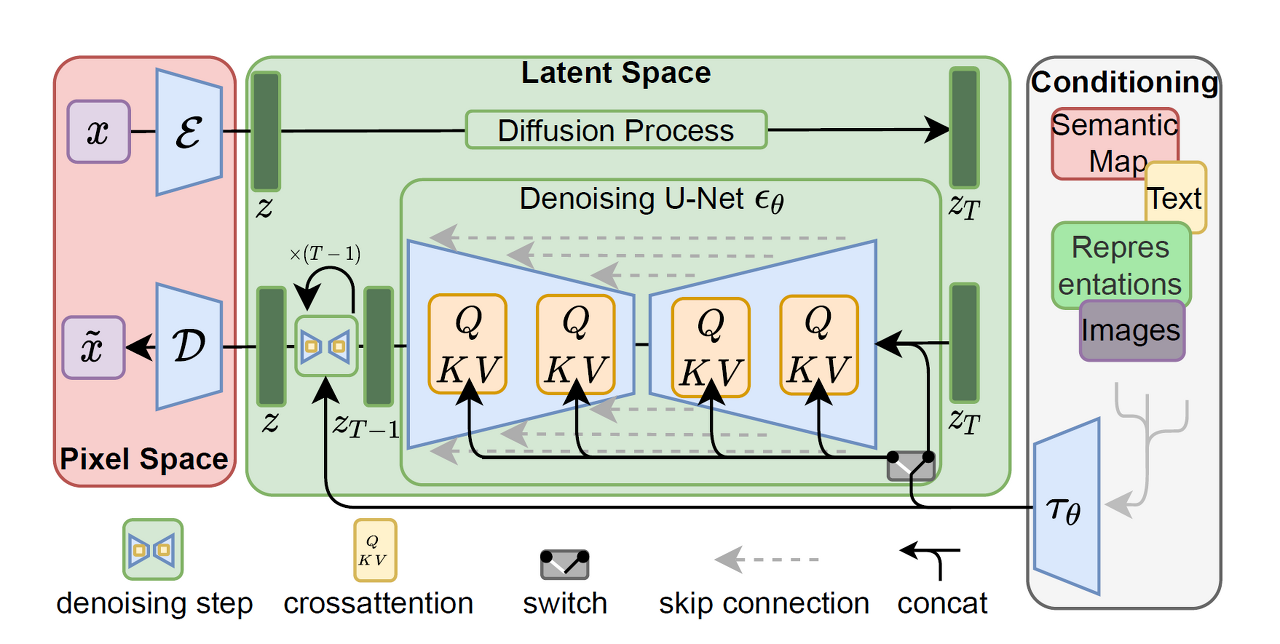
지난 시간에 이 모델 구조도를 배웠다.
우리는 이러한 구조를 변형하여 다양한 task를 수행할 수 있는 이미지 생성 모델들을 구울 수 있다.
가능한 tesk
1) text-to-image
입력된 프롬프트(텍스트)에 맞는 이미지 출력
2) super-resolution
저해상도 이미지를 고해상도 이미지로 만듦
- 기존(저해상도) 이미지 크기: 64x64
- 고해상도 이미지 크기: 256x256
👉 해야할 일: 픽셀을 16배로 채우기(늘리기)
3) inpainting
원본 이미지에서 특정 위치에 있는 사물 지우기
👉 기존 이미지에서 사물이 지워지면, 그 빈칸은 주변 픽셀을 복사해 채워진다.
위와 같은 stable diffusion 모델은 굉장히 무겁고! 용량이 커서! 성능이 너무 아주 좋은 컴퓨터가 필요하다는 부담이 있다. 또한, 출력되는 결과도 용량이 크다.
그래서 등장한!
2. Textual Inversion
해당 논문: https://arxiv.org/abs/2208.01618
- stable diffusion의 변형 모델
👍 기존 모델을 하나하나 파인튜닝하여 생기는 부담을 덜고
👍 실제 무게도 가볍게 만들 수 있도록 고안된 컨셉이다.
main idea

- sudo word: 입력되는 이미지를 특정 단어(예를 들어, )로 인식한다.
- 이 단어로 새로운 이미지를 만들어 준다!
잡담) 벨로그에서 수식 쓰는 법을 알았다. $로 수식의 앞뒤를 감싸면된다 오호~
참고) https://velog.io/@d2h10s/LaTex-Markdown-%EC%88%98%EC%8B%9D-%EC%9E%91%EC%84%B1%EB%B2%95#-%ED%91%9C-table
과정
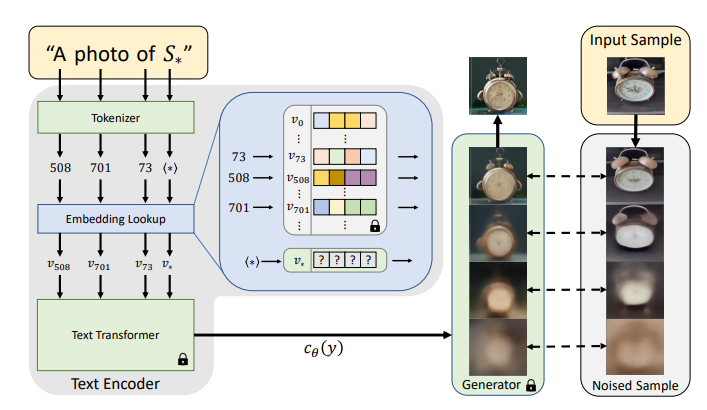
- '의 오래된 시계' 라는 텍스트 입력
- 토큰화
- 텍스트 임베딩
📍 여기서, 학습된 디퓨전 모델은 '오래된','시계'의 의미는 알지만 가상 언어 'S_*'에 대한 의미는 모른다.
🔻
따라서 S의 의미를 처음에 넣은 input image로 채워준다.
🔻
그렇게 되면 S를 벡터화 시킨 V에 diffusion 처리된 input image에서 얻은 정보가 반영된다.
와악 이부분 어려워서 10번은 넘게 돌려본것같다. 너무 어려워
장점
- 원본 모델을 추가학습 할 필요가 없다.
- 즉, 별도의 파인튜닝이 필요없다.
cf. Hyper-Network
textual inversion과~
-
공통점: 일부를 tuning할 수 있는 기법
-
차이점
: (t.i.) 데이터 입력으로 정보를 주지 않고
(h.n.) 모델 안에 새 신경망을 집어 넣어 모델 자체가 새로운 데이터를 학습할 수 있게 함
hyper network의~
-
장점: 기존 stable diffusion 모델은 frozen되고, hyper network만 학습되어 적은 리소스로 학습 가능
-
단점: textual inversion보다 성능이 안좋음
[추가정보] civitai
- 링크: https://civitai.com/
- ai 모델 공유 플랫폼
- textual inversion이 궁금하면 검색해서 모델 사용 결과를 볼 수 있음!
그런데 아무래도 파인튜닝하지 않는 textual inversion은 성능이 좀~ 아쉬웠다고 한다. 그래서 등장한!!
3. LoRA
해당 논문: https://arxiv.org/abs/2106.09685
sd를 사용하자니~ 너무 무겁고
ti를 사용하자니~ 성능이 별로라
고심끝에 찾은 모델인 LoRA! sd보다 가볍고 ti보다 성능이 좋다고 한다.
이 모델에 대해서 잘 몰랐지만 인공지능 오픈채팅방에서 정말 잊을만하면 언급되는 모델이어서 내적친밀감이 있다.
정보의 우주속에 살고 있어서 따로 알아볼 생각을 못했는데 설명을 들으니 왜 인기쟁이였는지 알것같다.
LoRA는 원래 LLM에 해당하는 모델이었는데 stable diffusion에 적용되었다.
과정
모델 구조도는 다음과 같다.

핵심 기법
- metrics factorization
: 원본 행렬을 비슷한 두 개의 작은 행렬(주황색 부분)로 쪼개는 작업
🪄 두 개의 작은 행렬을 통해 원본을 표현할 수 있게 되어 더 적은 메모리가 든다.
🪄 적은 메모리(계산량)로 원본과 비슷한 이미지 예측 가능
👉 머신러닝, 추천시스템에 자주 활용됨
💡 강사님께서 civitai에서 LoRA 모델을 보여주셨는데 144메가밖에 안하고 완성된 이미지의 퀄리티가 증~말 높다.
이렇게 좋다는 로라에도 발전의 기회가 주어졌다.
이것도~ 아쉬운 점이 있었던 것이다.
성능은 정말 좋았지만 프롬프트 하나에 값을 넣다보니 단어 반영의 정확도가 떨어졌다고 한다. 그래서 또~
4. ControlNet
해당 논문: https://arxiv.org/abs/2302.05543
✋ 내가! 원하는! 이미지를 정말 정!확!히! 출력하기 위해서 출력 템플릿을 넣을수는 없을까?
🪄해서 나온 모델이다.
그래서 컨트롤넷의 input은 두 가지이다.
input
- prompt(text)
- prompt를 통해 생성하고싶은 이미지 템플릿
ex. 사람의 손그림, 설계도, 스켈레톤, depth map 등
아래는 controlnet을 사용한 예시이다.
프롬프트에 생각보다 하찮은 템플릿을 넣어줘도 잘 동작하는 것을 볼 수 있다.
완성된 사진도 좋은데 개인적으로 손그림이 너무 귀여워욧

또 다른 예시이다. 이건 그냥 귀여워서 가져왔다!

👍 이러한 이미지 템플릿을 통해 내가 원하는 각도, 컨셉, 모양 등을 확실히 정할 수 있다!
논문 11페이지부터 보면 더 다양한 입출력값을 살펴볼 수 있다.
학습 원리
-
zero convoluaion
: 이미지 생성 영역에 대한 정보를 수치값으로 고정 -
위 고정값에 원하는 조건(이미지 정보) 추가
-
조건을 반영한 이미지 생성!
5. VAE(Variational Auto Encoder)
해당 논문: https://arxiv.org/abs/1312.6114
VAE는 stable diffusion의 컨셉을 처음 제시하였다.
- stable diffusion의 컨셉
: 아무 정보가 없는 input을 넣으면 특정 과정을 거쳐 내가 원하는 정보가 담긴 출력값 생성
그래서 VAE의 목표 또한 sd의 컨셉과 비슷하다.
목표
랜덤 노이즈(input x)를 넣으면 원하는 이미지 생성하기
역할
필터 또는 조정된 정보 역할
학습 과정
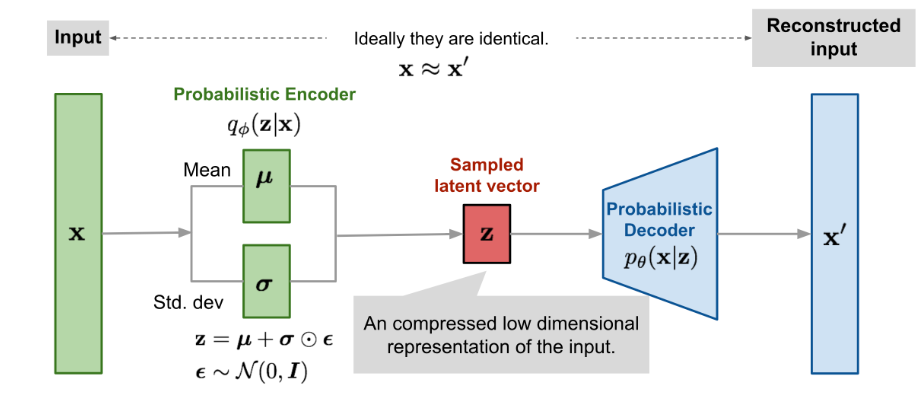
-
input data x를 넣는다.
-
입력된 이미지에서 좋은 feature(패턴)를 뽑아낸다.(목표)
👉 좋은 feature는 숫자 형태로, 그림에서 z를 의미한다. 이를 latent vector라고 부른다.
👉 즉, 좋은 latent vector를 뽑는 것이 학습 목표라 할 수 있다. -
vae가 학습이 되면 아래 확률 분포와 같은 결과를 얻을 수 있다.
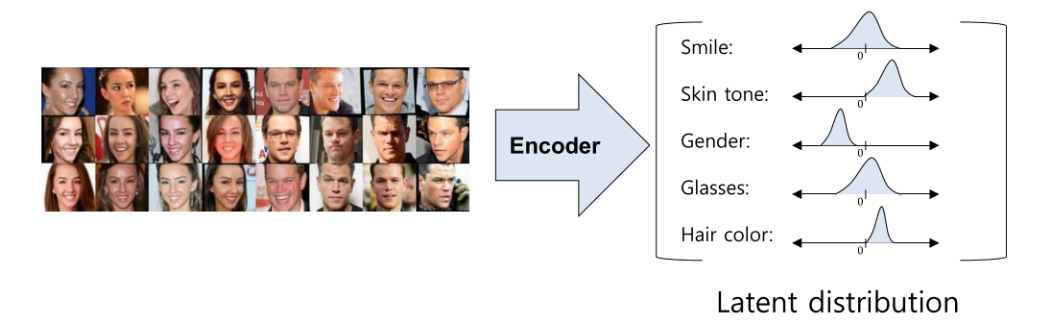
-
이 분포를 이용해 내가 원하는 정보를 만들어낼 수 있다!
실습 - stable diffusion webui
stable diffusion webui로 이미지를 만드는 실습이 진행되었다!
💡automatic1111 버전의 sd webui를 사용하였다.
깃허브: https://github.com/AUTOMATIC1111/stable-diffusion-webui
코랩: https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb
🔻만들어지는 과정
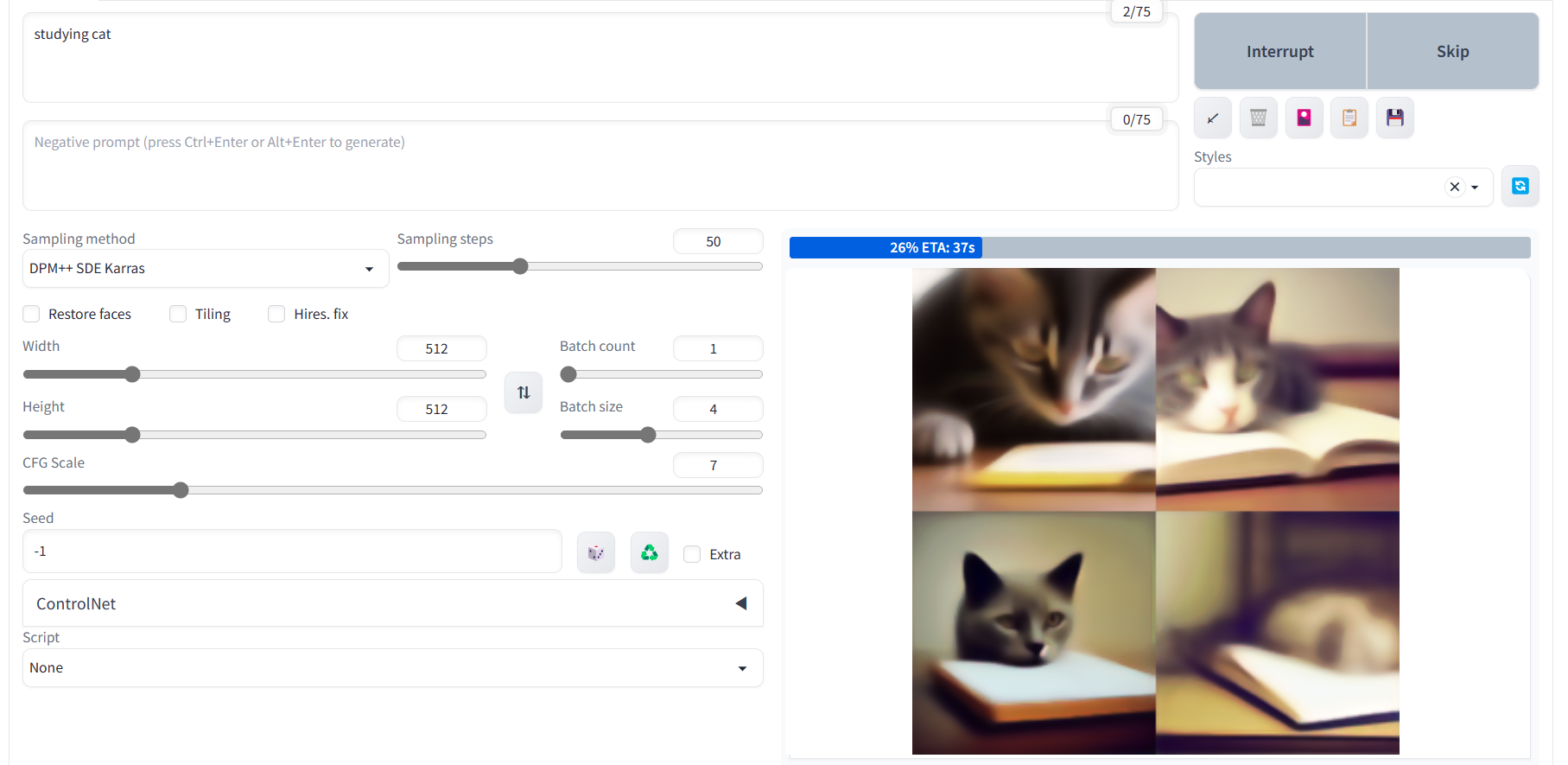
⌛
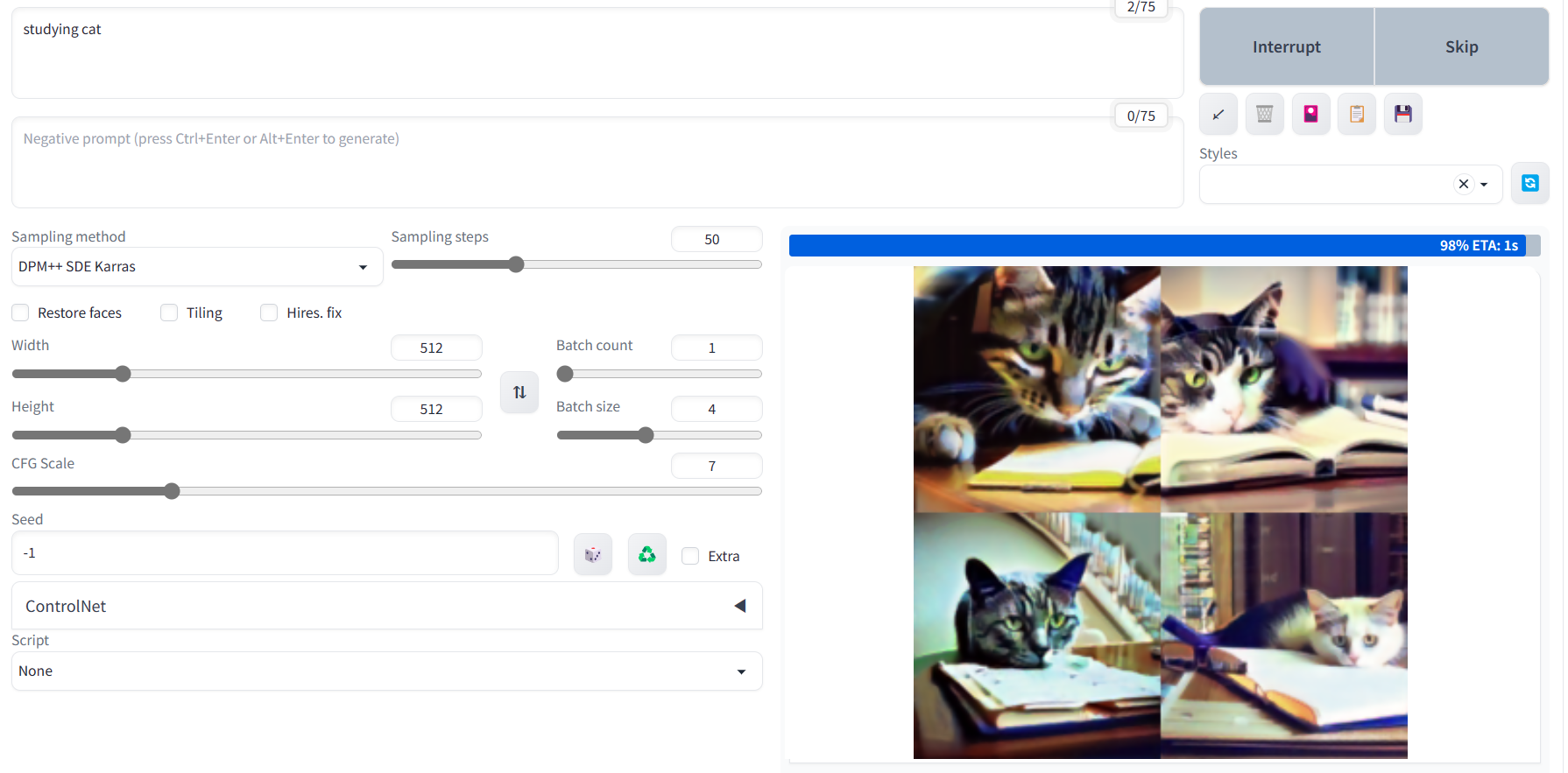
⌛
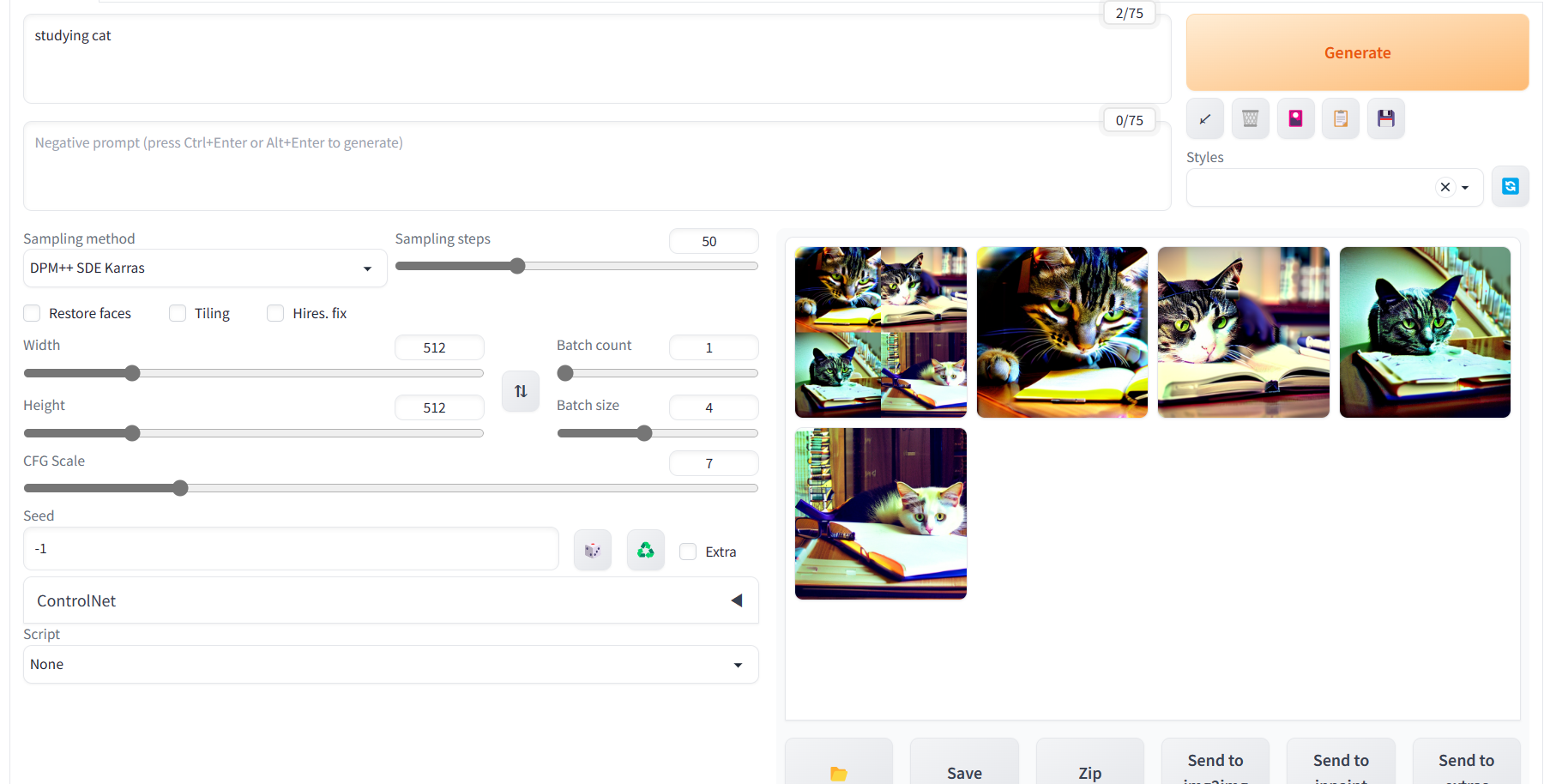
짠! 몇차례를 거쳐 studying cat이 완성되었다!
튜닝되지 않은 모델을 그대로 써서 초반엔 기이하고 불쾌한골짜기같은 이미지만 잔뜩 만들어졌는데, sampling step을 늘리고 몇번 재실행시켰더니 좀더... 꽤나 괜찮은 이미지들이 만들어졌다.
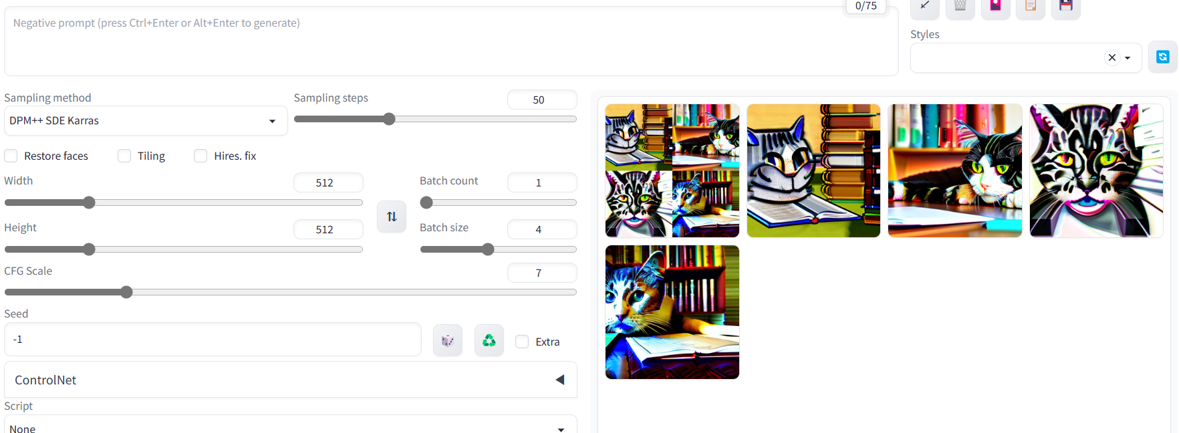
초반엔 이런...늑김으로다가 생성되었었다. 이게 고양이니까 그래도 괜찮은데,,, 저런느낌으로 사람이 생성돼서 정말 기절할뻔했다.
🪄
한달가량의 chatgpt & stable diffusion 수업이 끝났다.
진짜! 재밌다!
초등학교때 2023년정도 되면 날으는 자동차가 있을 줄 알았다.
그런데 그런건 전혀 만들어지지 않았지만~
이 인공지능의 발전만큼은 날으는 자동차느낌으로다가 놀랍고 대단하고 매우 미래스럽다.
상상했던 기술이 현실이 됐어~~
수업을 들으면서 기술들이 다 융합해서 생겨났구나? 싶었다.
이게 완전 좋은 기회라고 생각한다.
다른분들이 다 만들어놓은 모델에 숟가락얹기!
물 론 그 숟가락얹기도 매우 어렵겠지만은 그래도 이건 기회다~
이제 앞으로는 이론에 더해 코드실습까지 알아봐야겠다!!
[출처]
