
미프 연속 2주째.. 세미 빅프를 하는 느낌이다. 그리고 담주도 미프!
무려 3주간의 미프!
계속된 미니 프로젝트라 새로 알게되는 것 보다 복습할 게 더 많을 것이라 생각했지만, 정말 하면 할수록 더 새로운 인공지능 세계이다.
새로 배우는 모델들이 너무많아욧
일단 이번 프로젝트를 소개한 뒤, 새로 알게된 것들을 적어 볼 예정이다~
0. 프로젝트 소개
- 주제 : 스마트폰 센서 데이터 기반 인간 행동 인식 분류
- 사전학습 과목: 데이터 분석, 머신러닝, 딥러닝
- 데이터 출처 : UCI machine learning repository
- 데이터 구분: Tabular
- 문제 유형: 분류
- 중점 사항: 데이터 탐색, 6개 클래스 분류
1. 데이터 분석
📍 변수 중요도
변수 중요도에 집중하여 분석을 진행하였다.
이번 데이터는 563개의 매~우 많은 컬럼이 존재한다.
따라서 이를 분석하고, 중요도가 낮은 데이터는 제거하는 것이 추후 분류 성능에 영향을 미칠 수 있었다.
📍 타겟 값 분포
본 프로젝트는 이진 분류가 아닌 다중 분류로, 6개의 클래스를 나누어 분류가 진행되어야 했다. 때문에 각 클래스의 분포가 치우쳐있지 않고 고른지 확인해야 했다.
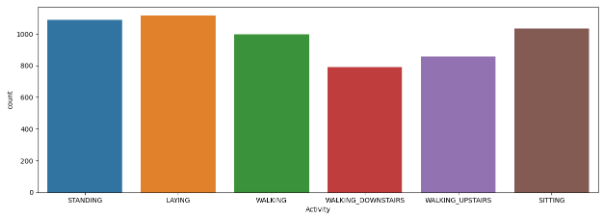
적당히 고르다!
2. 데이터 전처리
1차 데이터
이번 프로젝트엔 큰 분류의 라벨링 처리가 된 데이터와 세부적으로 라벨링된 데이터를 따로 받았다. 그 중 1차로 받은 큰 분류 라벨링 데이터는 다음과 같이 전처리하였다.
- 동적, 정적 데이터로 1차 분류
- 동적 데이터 세부 분류
- 정적 데이터 세부 분류
2차 데이터
2번째로 받은 데이터는 세부적인 라벨링이 완료된 데이터셋이었다.
✔️ 결측치도 없었고
✔️ 타겟 데이터도 분포도 일정한 편이었다.
그래서 따로 전처리가 크게 필요치 않았다! 오!예!
3. 모델링
오예가 아니였다. 데이터 전처리를 해줄게 별로 없으니 성능을 높일 수 있는 방법이 모델링뿐!!!!!😭😭😭😭😭😭
사용 모델
- LogisticRegression
- RandomForest
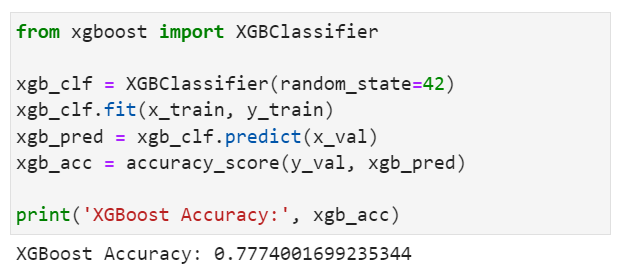
- 👑XGBoost
- lightGBM
- DecisionTreeRegressor
- catboost
💡 이 중 가장 높은 성능을 보인 모델은 XGBoost였다! 채택!
성능 향상 기법
- 하이퍼파라미터 튜닝
: RandomSearchCV로 xgboost의 하이퍼파라미터 튜닝을 진행하였다
👉 한시간 반정도 걸리는데다가 진행상황 표시 처리를 해주지 않아서 컴터 고장난줄알았다.

- 앙상블
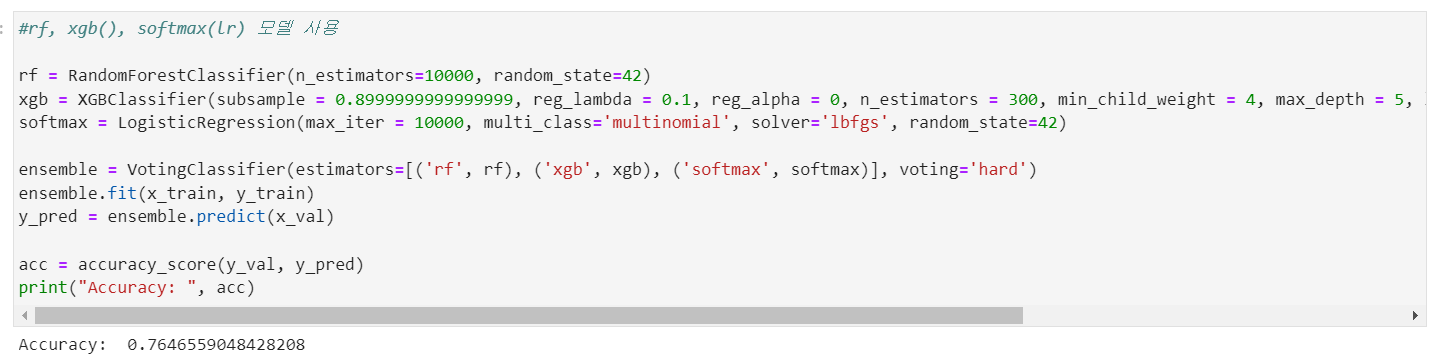
- 👑randomforest, xgboost, softmax(logisticRegressor)
- randomforest, xgboost(튜닝된 모델), logisticRegressor
- randomforest, xgboost(튜닝x 모델), logisticRegressor
그 결과, randomforest, xgboost, softmax를 앙상블한 모델의 성능이 가장 높았으나, 하이퍼파라미터 튜닝된 성능보다 낮았다.
결론
- 사용 모델: 하이퍼파라미터 튜닝된 XGBoost
- jupyter notebook 상의 성능: 0.78
- 캐글 상의 성능(최종 결과): 0.76
- 반성: 모델링으로 성능을 높이겠다고 여기에 매달렸더니.. 추가로 전처리할 시간을 놓치고 말았다 ㅜㅜ 변수 중요도가 낮은 칼럼 제거!를! 해줘야했는데!
💡 기억하자! 성능이 낮으면 전처리로 돌아가라! 전!처!리!로!!!!
새로 알게된 것
1. automl(Automated Machine Learning)
세상에 이 좋은게있다니
나만 모내기 손으로하고 다른분들은 기계로했던거야~ 기절
개념
- 머신러닝에서 일반적으로 수행되는 일련의 과정을 자동화하는 기술
👉 데이터 전처리, 특성 추출, 모델 선택, 하이퍼파라미터 최적화 등을 자동으로 수행하여 최상의 모델을 생성
사용법
1) AutoML 프레임워크 사용
: AutoKeras, TPOT, H2O.ai
(1) AutoKeras : 케라스를 기반으로 한 오픈 소스 AutoML 라이브러리
🔻 AutoKeras를 사용한 MNIST 이미지 분류 모델 생성 코드
import autokeras as ak
from tensorflow.keras.datasets import mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
clf = ak.ImageClassifier(max_trials=10)
clf.fit(x_train, y_train)
results = clf.predict(x_test)
(2) TPOT : 파이썬 기반 오픈소스 automl
from tpot import TPOTClassifier(3) H2O.ai : 머신러닝을 위한 오픈소스 automl
import h2o
from h2o.automl import H2OAutoML2) 클라우드 기반 자동 기계학습 서비스 활용
-
Amazon Web Services (AWS) (회사명)
: SageMaker AutoPilot(서비스명) 제공 -
Google Cloud
: Cloud AutoML 제공 -
Microsoft Azure
: Azure AutoML 제공
2. WandB(Weights & Biases)
해당 사이트: https://wandb.ai/site
개념
- 더 나은 모델을 빠르게 만들 수 있게 도와주는 ML Experiment tracking tool
- 머신러닝 실험을 관리하고 시각화하기 위한 클라우드 기반 플랫폼
- 머신러닝 모델 개발 단계에서 발생하는 여러가지 문제 해결에 도움
기능
-
실험 로깅
: 실험의 하이퍼파라미터, 코드 버전, 데이터, 모델 아키텍처, 로그 및 메트릭을 자동으로 로깅하고 추적 -
시각화
: 모델 성능, 하이퍼파라미터 및 실험 로그를 시각적으로 표시하여 개발자가 실험 결과를 더 쉽게 이해하고 분석할 수 있도록 도움 -
협업
: 여러 사용자와 프로젝트에 대한 협업 가능(실험 로그 및 결과를 공유하고 논의) -
모델 탐색
: 하이퍼파라미터를 조정하거나 다른 모델 아키텍처를 시도하여 최적의 모델 탐색
🔻 일부 사용 화면(wandb의 docs - tutorial을 통해 더 자세히 확인 가능)
.
.
.
무슨 영업글같다.
3. AutoGloun
개념
- Amazon Web Services (AWS)에서 개발한 머신러닝 모델을 자동으로 튜닝하는 오픈소스 라이브러리
- 다양한 머신러닝 태스크(이진 분류, 다중 분류, 회귀, 시계열 예측 등)를 자동으로 처리 가능
기능
-
모델 선택: 각 데이터셋에 적합한 최상의 모델을 선택
-
하이퍼파라미터 튜닝: 선택된 모델의 하이퍼파라미터를 자동으로 튜닝
-
모델 앙상블: 여러 모델의 예측 결과를 결합하여 더 강력한 앙상블 모델 생성
-
변수 중요도: 모델을 학습하는 동안 각 매개 변수의 중요도를 추정하여 사용자의 모델 이해에 도움
-
자동 특성 엔지니어링: 머신러닝 모델을 위해 새로운 특성을 자동으로 생성
정리
AutoML, WandB, AutoGluon 공통점과 차이점을 통해 최종정리!
공통점
- 머신러닝 모델 개발을 위한 도구
- 모델 튜닝과 결과 시각화를 자동화
차이점
📍 AutoML : 모델 선택, 하이퍼파라미터 튜닝 자동화
📍 WandB : 머신러닝 실험 관리, 시각화
📍 AutoGluon : 머신러닝 모델을 자동으로 튜닝
다음 기회엔. 꼭 자동화도구를.꼭. 사용해야지
아 맞다 근데 당연한 말이지만 이렇게 많은 기능을 제공하는 만큼,
결과 도출에 시간이 오래걸린다고 한다.
그래서
💡 자동화 도구 최대한 초반에 사용하기
💡 빠르게 전처리로 돌아가기
잊지말자~~~ ~~
