
자연어처리 미니프로젝트가 시작되었다!!!
0. 프로젝트 소개
- 주제 : Aivle-edu의 1:1 문의 내용 기반 문의 유형 자동 분류기
- 사전학습 과목: 언어지능
- 데이터 출처 : aivle school 측에서 제공(직접 제작- 2기 1:1 게시판 활용)
- 데이터 구분: 텍스트
- 문제 유형: 분류
- 중점 사항: 전처리 및 분류 모델 적용
1. 데이터 분석
저번 언어지능 수업에서는 한국어 텍스트를 중점으로 분류, 생성하는 실습을 하였다. 그리고 이번에 받은 데이터 또한 한국어 데이터였지만, 코드 문의 등의 내용으로 인해 영어와 특수문자가 많이 섞여있었다!
각 데이터는 5가지로 라벨링되어 이에 맞는 분류를 수행해야 했다.
2. 데이터 전처리
매번 프로젝트를 할때마다 느끼는건데 전처리가 정말정말 오래걸린다.
프로젝트의 첫 번째 단계부터 가장 많은 시간이 투자되어 시작부터 고됨을 느끼지만, 그렇게 힘들게 전처리한 데이터를 가지고 모델링했을 때 좋은 성능을 내면 내가 진~~~짜 대견하다.
근데 문제는 좋은 성능이 안나온다.
그래서 다시 화를 가다듬고 전처리 해야할 목록 정리하기!
전처리 목록
기본적으로 전처리는 다음과 같은 순서로 이루어진다.
- 특수문자 제거
- 형태소 분석
- 품사 태깅
- 명사 추출
- 임베딩/ 벡터화
✋ 여기서 잠깐, 임베딩 vs 벡터화
- 임베딩: 단어를 벡터로 변환하는 과정(Word2Vec, GloVe, FastText)
- 벡터화: 문서(책, 논문, 웹 페이지 등)를 벡터로 변환하는 과정(Bag of Words, TF-IDF)
그리고 이 5번 단계에 적용할 방법이 제시되었다.
-
벡터화
✔ ngram -
임베딩
✔ sequence
✔ word2vec
의문1. 전처리 방법이 다른 이유
🤷♀️ 근데 여기서 의문, 왜? 왜 세 가지 방법을 다 사용해서 데이터를 내놔야하지? 굳이 왜?
그 이유는 다음과 같았다.
🙋♂️
1. 우리는 머신러닝과 딥러닝에 넣을 데이터가 필요합니다.
2. 이제 알았지만, 머신러닝과 딥러닝에는 각자 다른 방식으로 전처리된 데이터가 필요합니다.
3. 머신러닝에는 보통 벡터화된 데이터를, 딥러닝에는 임베딩된 데이터를 넣어주어야 합니다.
🙆♂️ 더 자세한 내용은 제 친구가 설명드리는 걸로 하겠습니다.


의문2. 벡터화 방법
🤷♀️ 그래 알겠다 그럼 난 이제 다른걸 몰라. 어떻게! 벡터화하는데?!
🙋♂️ n-gram 데이터로 벡터화하는 순서
- n-gram 처리
- 개념) n개 글자만큼 묶는 과정입니다. 본 프로젝트에서는 n = 2로 설정해 두 글자씩 묶었습니다.
- 효과) 이를 통해 문맥 정보를 반영하여 단어의 의미를 더 잘 파악할 수 있습니다.
n-gram은 단어의 순서만 고려한 특징을 추출하기 때문에 문장 내에서 중요한 단어를 구분하지 못할 수도 있습니다.
🔻
- tf-idf 처리
-
이를 해결하기 위해, tf-idf(Term Frequency - Inverse Document Frequency) 방법을 사용합니다.
-
개념) tf-idf는 단어의 빈도수에 따라 가중치를 부여합니다.
-
예시) 모든 문서에서 자주 등장하는 단어에는 낮은 가중치를, 특정 문서에 자주 등장하는 단어에는 높은 가중치를 부여하여 중요한 단어를 잘 구분할 수 있도록 합니다.
-
효과) 따라서, n-gram 결과에 tf-idf를 적용함으로써, 단어의 빈도수와 문서의 빈도수를 고려하여 중요한 단어를 잘 추출(벡터화)할 수 있게 됩니다.
🙋♂️ sequence 데이터를 벡터화하는 순서
휴 여기부턴 조금 수월하다.
아래와 같이 texts_to_sequences한 데이터를 패딩 처리해주면 된다.

🙋♂️ word2vec하는 순서
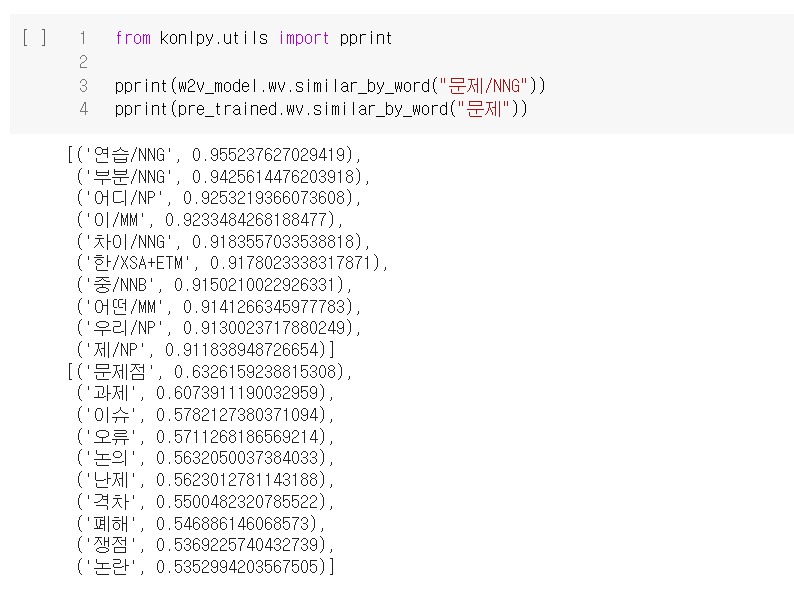
word2vec은 강사님께서 제공해주신 코드를 참고하였다.
gensim의 word2vec을 사용하였다.
결과는 아래와 같다.
와~ 와!!!! 전처리가 끝났다!!!!!!!!!!! 프로젝트 총 기간이 5일이었는데, 그 중 4일을 전처리했다.
3. 모델링
조별 프로젝트였고 나는 머신러닝 모델링을 맡았다.
사용 모델
👑 1. Logistic Regression
가장 높은 성능을 보였다!!

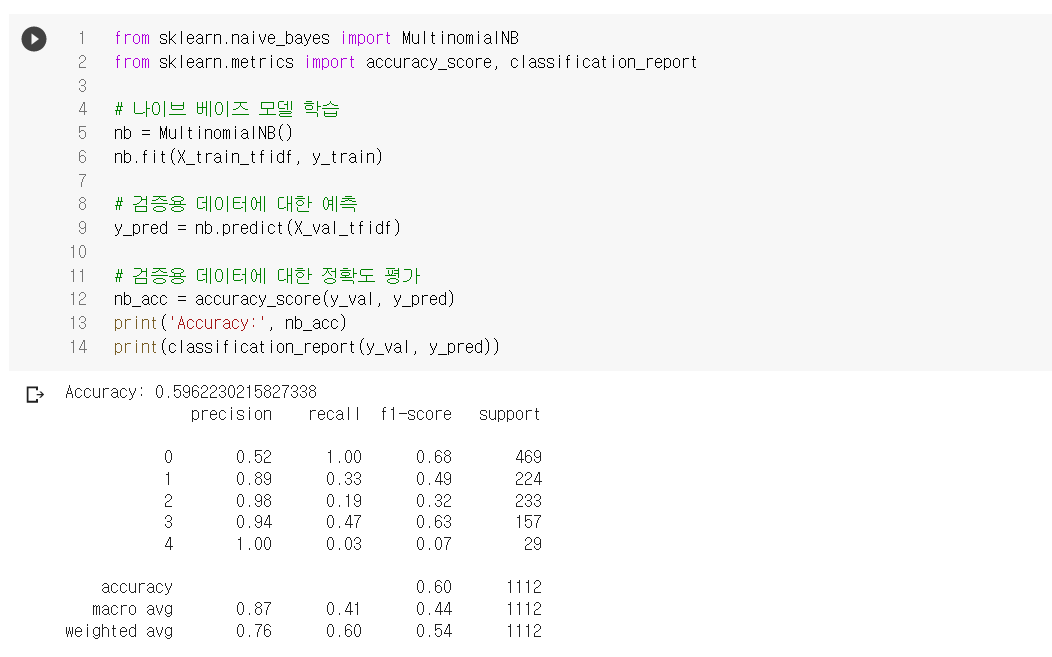
2. Naive Bayesian
3. Randomforest

하이퍼파라미터 튜닝
가장 성능이 잘 나온 Logistic Regression 모델을 RandomsearchCV로 튜닝하였더니 0.01.......0.01 올랐다.....
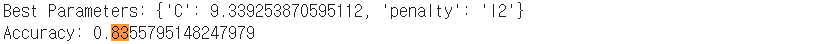
캐글 제출 마감시간이 얼마 남지 않아 더이상 튜닝을 진행하지 못하고 일단 냈다.
근데 그 결과!

ㄱㄱㅑ ㅇㅏㄱ
원래 캐글 제출하면! 주피터나 코랩에서 돌렸을때보다 0.1은 더 낮게 나와서 기대도안했는데!! 튜닝했을때보다 더 높게 나와줬다!!! 고마워 짱글~~~
느낀점1
캐글 두번밖에 안해봤지만 정말 0.01, 0.001의 성능이 너무 소중하다. 비슷한 팀들의 성능을 보면 정말 미세한 차이로 순위가 결정되기 때문이다. 뒤에서 봐야 순위권에 드는 성적이지만은 그래도 조금이라도 높아졌다는게 해피다~
느낀점2
위에서 전처리 4일동안했다고 했는데 사실 굳이 따지자면 전처리 5일에 모델링 3시간 정도라 할 수 있을 것 같다. 모델링 성능이 더이상 안높아져서 다시 전처리로 돌아갔기 때문이다...ㅎㅎㅎㅎㅎ 지금 블로그 적는 것도 전처리 2시간걸렸고 모델링 정리는 30분도 안걸렸다.
⚡정말 전처리의 중요성과 힘을 잔뜩 느낀 프로젝트였다.
