[논문 리뷰] NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis (ECCV 2020)
Paper review
오늘은 Neural rendering의 대표 논문, NeRF를 리뷰해보도록 하겠습니다.
아직은 그냥 번역만 한 것 같은 느낌이 강하지만 하다보면 늘겠죠..ㅎㅎ
그럼 시작합니다!
논문 정리
Motivation (선행 연구의 문제점)
- Computer vision에서 유망한 방법은 object와 scene들을 MLP의 weight에 encode하는 것으로 signed distance와 같이 3D 공간적 위치를 모양의 implicit representation으로 직접적으로 mapping한다.
그러나 이러한 방법들은 triangle meshes나 voxel grids와 같은 discrete representations를 사용하여 scene을 표현하는 기법들과 같은 정확도로 복잡한 geometry의 scene을 재현할 수 없었다. - Volumetric 기법들은 novel view synthesis에서 인상적인 결과들을 달성했지만, 더 높은 해상도의 이미지를 scale하는 그들의 능력은 그들의 discrete sampling으로 인한 부족한 시간과 공간 복잡도에 의해 근본적으로 제한된다.
- 기존의 object와 scene을 continuous 함수로 표현하기 위해 MLP를 사용하는 방법들은 discrete 방식보다 복잡한 geometry 표현이 어려웠다.
- discrete sampling 방식은 고해상도(high frequency) 표현들을 잘 표현하지 못했다.
Contributions
- 5D radiance fields (3D volumes with 2D view dependent appearance)를 입력 받아 color와 density를 출력하기 위해 network를 최적화했다.
- 우리는 기존의 volumetric 접근법들보다 현저히 더 높은 quality의 rendering을 생성할 뿐만 아니라, sampled volumetric representation들의 저장 비용의 일부만 요구하는 deep fully-connected neural network의 parameter들 내에서 continuous volume을 encoding하는 것으로 volumetric 기법이 고해상도의 이미지를 scale하지 못하는 문제를 해결했다.
- 입력 좌표에 대한 positional encoding을 통해 높은 주파수의 함수를, Hierarchical sampling을 통해 높은 주파수의 표현을 효율적으로 샘플링함.
- 고해상도의 복잡한 scene을 표현 가능
- Position과 viewpoint를 입력받아 color와 density를 출력하기 위해 network 최적화했다.
- Deep fully connected neural network의 parameter 내에서 continuous volume을 encding하여 고해상도의 이미지 scale 가능하게 했다.
- Positional encoding과 Hierarchical sampling을 통해 높은 주파수의 표현을 효과적으로 샘플링할 수 있게 되었다.
- 고해상도의 복잡한 scene을 표현 가능
Future direction
- Dynamic Scene NeRF
- Static한 환경 뿐만 아니라 dynamic한 환경에서 잘 작동해야 함
- Few-shot NeRF
- COLMAP 없이 pose estimation도 같이 이루어지도록 함
- Ex) iNeRF
Abstract
- 우리는 희소한 입력 시점들을 사용하여 연속적인 volumetric scene function에 기반하여 최적화함으로써 복잡한 scene의 novel view를 합성하여 state-of-the-art 결과를 달성한 방법을 제시함.
- 입력: single continous 5D coordinate (spatial location (x, y, z)와 viewing direction (, )
- 출력: View-point emitted radiance at spatial location, volume density
- Camera ray들을 따라 5D 좌표계를 입력 받아 전통적인 volume rendering 기법을 써서 output color와 density를 이미지에 투영함
- Volume rendering은 원래 미분 가능하므로, 우리의 표현을 최적화하기 위해 필요한 입력은 카메라 pose가 알려진 이미지 set이다.
- 우리는 복잡한 geometry와 appearance를 가진 scene의 photorealistic novel view를 rendering하기 위해 어떻게 효율적으로 neural radiance fields를 최적화하는지 묘사함.
- Neural rendering과 view synthesis에서 이전의 연구들을 압도하는 결과를 입증함
1. Introduction
- 우리는 static scene을 연속적인 5D 함수로서 제시하여 각 point(x, y, z)에서 각 direction (, )에서 발산된 radiance와 density를 출력으로 함
- 우리의 방법은 a deep fully-connected neural network를 convolutional layer 없이 최적화하여 5D 좌표를 single volume density와 view-dependent RGB color로 regress하는 함수로 표현
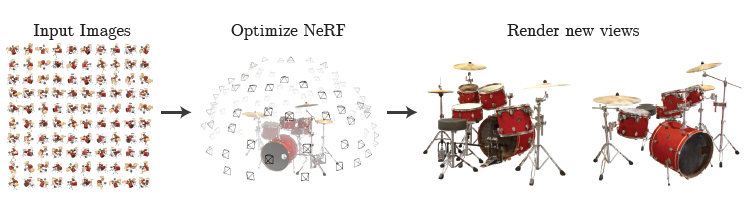
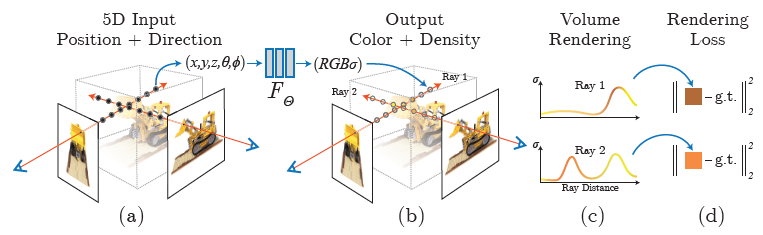
Fig. 1. We present a method that optimizes a continuous 5D neural radiancefield representation of a scene from a set of input images
Pipe line
1) Camera ray들을 scene에 발사하여 3D point들의 sampled set을 생성
2) 이 point들과 그것들의 대응하는 2D viewing direction을 neural network의 입력으로 사용하여 output color와 density 집합을 생성
3) Classical volume rendering을 사용하여 color와 density를 2D 이미지로 축적
- 이 과정은 자연적으로 미분 가능하기 때문에, 우리는 관측된 이미지와 우리의 표현으로부터 만들어진 대응하는 시점 사이의 error를 최소화하는 것에 의해 모델을 최적화하도록 gradient descent를 사용할 수 있다.
- 다수의 view에 대한 error를 최소화하는 것은 network가 높은 volume density와 정확한 color를 scene content를 포함하는 위치에 할당하는 것에 의해 일관된 scene의 model을 예측하도록 한다.
- 복잡한 scene을 위한 Neural radiance field 표현을 최적화하는 것의 기본 실행은 충분히 높은 해상도 표현으로 수렴하지 않거나 camera ray당 요구되는 sample의 수에 불충분하다.
- 우리는 입력 5D 좌표를 positional encoding으로 변환하여 MLP가 더 높은 주파수 함수를 표현할 수 있도록 하고 hierarchical sampling을 제시하여 query의 수를 줄여 높은 주파수의 scene representation을 적절하게 sampling한다.
- 우리의 접근법은 volumetric representations의 장점을 물려받아 복잡한 real-world geometry와 appearance를 표현할 수 있고 투영된 이미지를 사용하여 gradient-based optimization에 적합하다.
- 특히 우리의 방법은 높은 해상도로 복잡한 scene을 모델링할 때 discretized voxel grids의 prohibitive storage cost를 극복했다.
- 우리의 기술적 contribution들은 다음과 같다.
- 복잡한 geometry와 materials를 가진 연속적인 scene들을 5D neural radiance fields로서 표현하는 접근법으로 기본적인 MLP network로 parameterize됨
- Classical volume rendering 기법들에 기반한 미분 가능한 rendering 과정으로 우리는 standard RGB 이미지들로부터 이 표현들을 최적화한다.
- 이는 MLP의 capacity를 visible scene content와 함께 space에 할당하는 hierarchical sampling을 포함
- 입력 5D 좌표를 높은 차원의 space로 mapping하는 a positional encoding은 우리가 neural radiance fields를 high-frequency scene content로 표현하도록 성공적으로 최적화할 수 있게 해준다.
- 우리는 우리의 neural radiance field 방법이 sampled volumetric representations를 예측하는 deep convolutional networks를 학습하는 연구 뿐만 아니라 neural 3D representations에 맞는 연구들을 포함하여 state-of-the-art view synthesis 방법들을 양적으로 그리고 질적으로 압도하는 것을 보여준다.
- 이 논문은 최초의 연속적인 neural scene representation을 표현하며 이는 자연 환경에서 캡쳐된 RGB 이미지들로부터 실제 object들과 scene들의 high-resolution photorealistic novel view들을 생성할 수 있게 해준다.
2. Related Work
- Computer vision에서 유망한 방법은 object와 scene들을 MLP의 weight에 encode하는 것으로 signed distance와 같이 3D 공간적 위치를 모양의 implicit representation으로 직접적으로 mapping한다.
- 그러나 이러한 방법들은 triangle meshes나 voxel grids와 같은 discrete representations를 사용하여 scene을 표현하는 기법들과 같은 정확도로 복잡한 geometry의 scene을 재현할 수 없었다.
Neural 3D shape representations
- 최근의 연구들은 연속적인 3D shape들의 xyz좌표들을 signed distance function들과 occupancy fields로 mapping하는 deep networks를 최적화하는 것에 의해 level이 정해지는 연속적인 3D shape의 implicit representation을 조사했다.
- 그러나 이러한 모델들은 ShapeNet과 같은 합성 3D shape datasets로부터 얻어진 ground truth 3D geometry에 접근의 필요성에 의해 제한되었다.
- 이어지는 연구들은 neural implicit shape representation들이 2D 이미지들만 사용하여 최적화되도록 하는 미분 가능한 rendering 함수를 형성하는 것에 의해 ground truth 3D shape의 필요성을 완화함.
- 우리는 5D radiance fields (3D volumes with 2D view-dependant appearance)를 encode하기 위해 networks를 최적화하는 전략을 보여주었다.
View synthesis and image-based rendering
- View의 dense sampling이 주어졌을 때, photorealistic novel view는 간단한 light field sample interpolation 기법들을 사용하여 재구성될 수 있다.
- Image reprojection에 기반한 Gradient-based mesh optimization은 자주 어려움을 겪었는데 그 이유는 local minima나 loss land-scape의 poor conditioning 때문이다. 게다가, 이 전략은 최적화 전에 초기화로서 제공되는 fixed topology를 가진 template mesh를 요구하므로 제한이 없는 real-world scene들에 대해서는 가능하지 않다.
- 다른 방법들은 입력 RGB 이미지들로부터 높은 품질의 photorealistic view synthesis의 task를 다루기 위해 volumetric representations을 사용
- Volumetric approach들은 복잡한 모양과 재질을 표현할 수 있고 gradient-based 최적화에 잘 맞으며 시각적으로 덜 방해하는 인공물을 mesh-based method들보다 덜 생성함.
- Volumetric 기법들은 novel view synthesis에서 인상적인 결과들을 달성했지만, 더 높은 해상도의 이미지를 scale하는 그들의 능력은 그들의 discrete sampling으로 인한 부족한 시간과 공간 복잡도에 의해 근본적으로 제한된다.
- 더 높은 해상도의 이미지들을 rendering하는 것은 3D 공간의 더 세밀한 sampling을 요구
- 우리는 기존의 volumetric 접근법들보다 현저히 더 높은 quality의 rendering을 생성할 뿐만 아니라, sampled volumetric representation들의 저장 비용의 일부만 요구하는 deep fully-connected neural network의 parameter들 내에서 continuous volume을 encoding하는 것으로 이 문제를 피했다.
3. Neural Radiance Field Scene Representation
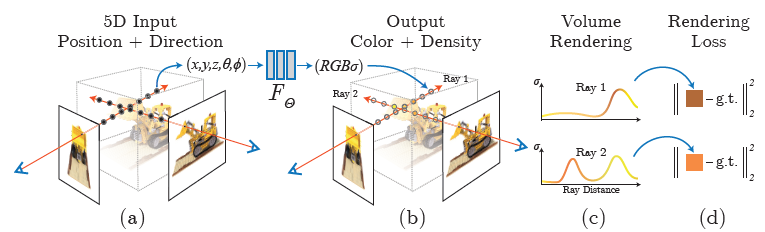
Fig 2: An overview of our neural radiance field scene representation and differntiable rendering procedure
- 우리는 연속적인 scene을 입력이 3D location x= (x, y, z)와 viewing direction (theta, phi), 그리고 출력이 발산된 색깔 c = (r, g, b), 그리고 volume density sigma인 5D vector-valued function으로 표현한다.
- 우리는 방향을 3D Cartesian unit vector d로 표현한다.
- 우리는 이 연속적인 5D scene representation을 MLP network
로 근사하고 이것의 입력 5D 좌표를 그것의 대응하는 volume density와 directional emitted color로 mapping시키기 위해 weights 를 최적화한다.
4. Volume Rendering with Radiance Fields
- 우리의 5D neural radiance field는 volume density와 공간에서 각 point의 directional emitted radiance로서 scene을 표현한다.
- 우리는 전통적인 volume rendering으로부터 얻은 공식들을 사용하여 scene을 지나는 ray의 색깔을 생성한다.
- The volume density 는 location x에서 극소 particle에서 끝나는 ray의 미분 가능성으로서 해석된다.
- Near과 far bound가 과 인 Camera ray r(t) = o + t(d)의 The expected color C(r)은 다음과 같다.
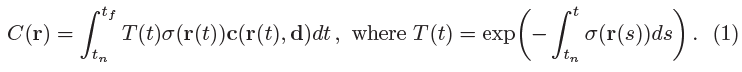
- The function T(t): the accumulated transmittance along the ray from to t.
- Ray가 으로부터 t까지 어떤 다른 particle과도 부딪히지 않고 진행할 확률
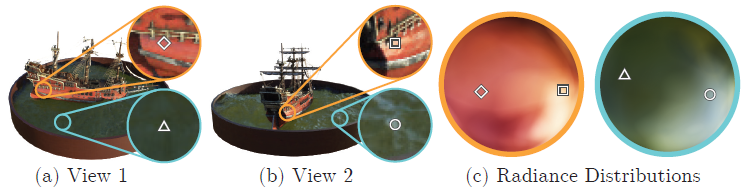
Fig. 3: A visualization of view-dependant emitted radiance.

Fig 4. View dependence emitted radiacne와 passing out input coordinates through a high-frequency positional encoding을 보여줌
- Fig 4: View dependence를 제거
- 모델이 spectacular reflection을 재생성하는 것을 막음
- Fig 4: No positional encoding
- High frequency geometry and texture를 표현하는 모델의 능력을 급격히 감소시킴
5. Optimizing a Neural Radiance Field
- 우리는 고해상도의 복잡한 scene들을 표현할 수 있게 해주는 2가지 향상을 도입했다.
- 입력 좌표에 대한 Positional encoding
- MLP가 높은 주파수의 함수들을 표현할 수 있게 해줌.
- Hierarchical sampling procedure
- 높은 주파수의 표현을 효율적으로 샘플링하게 해줌.
- 입력 좌표에 대한 Positional encoding
5.1. Positional encoding
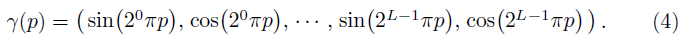
- 연속적인 입력 좌표들을 더 높은 차원의 공간으로 mapping하는데 이 함수를 사용하여 MLP가 더 쉽게 더 높은 주파수의 함수로 근사할 수 있게 한다.
5.2. Hierarchical volume rendering
- 우리는 "coarse"와 "fine"의 2가지 network를 동시에 최적화했다.
- Coarse network: 샘플들이 volume의 연관된 part들에 치우쳐져 있음.
- Fine network: visible content가 있을 것으로 기대되는 영역에 더 많은 샘플들을 할당함
5.3. Implementation details
- 우리는 각 scene에서 분리된 neural continuous volume representation network를 최적화함.
- 이것은 scene의 캡쳐된 RGB 이미지들의 데이터셋, 대응하는 camera poses, intrinsic parameters, 그리고 scene bounds를 요구한다.
- 실제 data로부터 ground truth camera poses, intrinsics, 그리고 합성 데이터의 경계를 예측하기 위해 COLMAP structure-from-motion 패키지 사용
- 각 최적화 iteration에서, 우리는 데이터셋의 모든 픽셀 집합으로부터 랜덤으로 camera ray들의 batch를 샘플링하며 coarse network에서 samples와 fine network에서 samaple들을 query하기 위해 hierarchical sampling을 따른다.
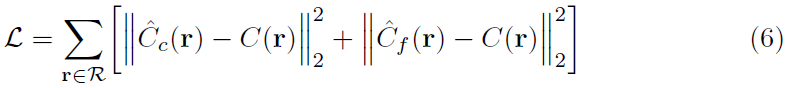
- , 과 은 각각 gound truth, coarse volume predicted, fine volume predicted RGB colors for ray 을 의미함
- 우리의 실험에서 batch size는 4096rays이고 coarse volume에서 개의 additional coordinate들이 각각 샘플링되며 fine volume에서 개의 additional coordinate들이 샘플링된다.
6. Results
- 우리는 우리의 방법이 이전의 연구를 압도함을 양적으로 그리고 질적으로 보였고 우리의 디자인 선택을 평가하기 위한 광범위한 ablation study를 제공함
6.1. Datasets
Synthetic renderings of objects
- 우리는 먼저 Table 1의 "Diffuse Synthetic 360"와 "Realistic Synthetic 360" 같이 2개의 물체 합성 rendering 데이터셋에 대한 실험 결과를 보였다.

Table 1: Our method quantitatively outperforms prior work on datasets of both synthetic and real images.
Real images of complex scenes
- 우리는 roughly forward-facing 이미지들에 대해 complex real-world scene들에 대한 결과를 보여주었다.
- Table 1에서 LLFF가 살짝 더 나은 LPIPS 성능을 보였지만 우리의 방법은 더 나은 multiview consistency를 달성했고 모든 baseline들보다 더 적은 artifact들을 생성했다.
6.2. Comparisons
- 우리의 모델을 평가하기 위해 우리는 view synthesis에서 top-performing 기법들에 대해 우리의 모델을 비교했다.
Neural Volumes (NV)
- NV는 구분되는 background 앞의 bounded volume 안에 있는 object의 novel view를 합성한다.
- 개 샘플들의 분리된 RGB voxel grid와 개 샘플들의 3D warp grid를 예측하는 3D convolutional network를 최적화한다.
- 이 알고리즘은 warped voxel grid를 통과하는 camera ray들을 쏘는 것에 의해 novel view를 생성한다.
Scene Representation Networks (SRN)
-
연속적인 scene을 각 좌표를 feature vector로 대응시키는 MLP에 의해 implicit하게 정의된 불투명한 표면으로 표현한다.
-
그들은 3D 좌표가 ray를 따라 next step size를 예측하는 3D 좌표에서의 feature vector를 사용하는 것에 의해 scene representation을 통과하는 ray를 발사하도록 Recurrent neural network를 학습시킨다.
-
Final step에서의 feature vector는 표면의 point에 대한 single color로 decode된다.

Fig.5: Comparisons on test-set views for scenes from our new synthetic dataset generated with a physically-based renderer. -
Fig5에서 우리의 방법은 ship의 rigging(그물), 레고의 gear와 treads(바퀴 같은 것), 마이크의 빛나는 stand와 mesh grille, 그리고 Material의 non Lambertian reflectance와 같은 geometry와 appearance의 fine detail을 복구할 수 있었다.
-
LLFF: 마이크 stand와 Material의 물체 edge에서 banding artifacts를 보였으며 Ship의 돗대와 레고 안쪽에서 ghosting artifact를 보임
-
SRN: 모든 경우에 대해 흐릿하고 왜곡된 rendering을 생성
-
Neural Volumes: 마이크의 망, 레고의 기어의 detail을 포착하지 못했고 배의 rigging의 geometry를 회복하는데 완전히 실패함

Fig.6: Comparisons on test-set views of real world scenes.
- Fig.6에서 우리의 방법은 LLFF보다 fine geometry를 더 일관성있게 표현할 수 있었다.
- Fern의 잎들이나 T-rex의 skeleton ribs와 railing에서 볼 수 있음. - 또한 부분적으로 가려진 영역들을 정확하게 재구성한다.
local Light Field Fusion (LLFF)
- LLFF는 잘 sample된 photorealistic novel view들을 생성하기 위해 디자인되었다.
- 이것은 직접적으로 구분된 frustum-sampled RGB grid를 예측하기 위해 학습된 3D convolutional network를 사용한다. 그리고 nearby MPIs를 novel viewpoint로 구성하고 섞는 것에 의해 novel view를 생성한다.
6.3. Discussion
- 우리는 모든 시나리오에서 각 scene(NV 그리고 SRN)의 구분된 network를 최적화하는 baseline들을 압도했다.
- 게다가 우리의 전체 학습 데이터셋으로서 입력 이미지들을 사용하면서 LLFF와 비교했을 때 질적으로 그리고 양적으로 우월한 rendering을 생성했다.
- SRN 방법은 매우 smooth된 geometry와 texture를 생성하고 view synthesis의 표현적인 power는 각 camera ray의 depth와 color를 선택하는 것에 의해 제한된다.
- LLFF는 입력 view들 사이에 disparity의 64 픽셀을 넘지 않는 "sampling guideline"을 제공하며 view들 사이에 400-500 픽셀들을 포함하는 합성 데이터셋에서 정확한 geometry를 예측하는데 자주 실패한다.
- 게다가, LLFF는 다른 view들을 생성하기 위해 다른 scene representation들을 섞어서 perceptually-distracting inconsistency를 야기한다.
- 가장 큰 tradeoff는 시간과 공간이다.
- 모든 compared single scene 방법들은 각 scene을 학습시키는데 적어도 12시간이 걸렸다.
- 반면에, LLFF는 작은 입력 데이터셋을 10분 안에 다룰 수 있다.
- 그러나 LLFF는 모든 입력 이미지에 대해 큰 3D voxel grid를 생성하며 거대한 stoage requirements를 초래한다.
- 우리의 방법은 network weight를 위해 5MB만 요구함.
6.4. Ablation studies
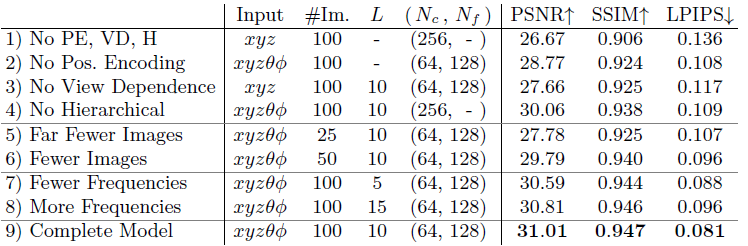
Table 2: An ablation study of our model.
- Positional encoding, View dependence, Hierarchical sampling을 없애면서 비교
7. Conclusion
- 우리의 연구는 object들과 scene을 연속적인 함수로 표현하기 위해 MLP를 사용하는 이전의 연구들의 단점을 직접적으로 다룸.
- 우리는 scene들을 5D neural radiance fields로 표현하는 것(volume density와 view-dependent emitted radiance as a function of 3D location and 2D viewing direction을 출력하는 MLP)이 이전의 지배적인 접근법인 deep convolutional networks를 학습시켜 discretized voxel representation을 출력하는 방법보다 더 나은 rendering을 생성함을 증명했다.
- Future works의 또다른 방향은 해석가능성으로 voxel grids와 meshes와 같은 sampled representation들은 rendered view와 failure mode들의 기대되는 quality에 대해 추론할 수 있게 해주지만 이 문제들을 deep neural network의 weight에서 scene을 해석할 때 이 문제들을 분석하는 것은 분명하지 않다.
- 우리는 우리의 연구가 복잡한 scene들이 실제 object들과 scene들로부터 최적화된 neural radiance fields로 구성될 수 있는 실제 세계 이미지에 기반을 둔 graphics pipeline을 향해 발전하도록 만들 것이라 믿는다.
그렇게 값진 정보를 공유해 주셔서 감사합니다. 더 많은 글을 읽을 수록 기대됩니다!