Transformer
예전에는 attention module이 sequence to sequence 모델의 추가적인 모델로 사용되었다면 transformer는 순수하게 attention 만으로 시퀀스를 input으로 넣고 시퀀스를 output으로 출력할 수 있는 모델이다.
기존 RNN의 작동 과정
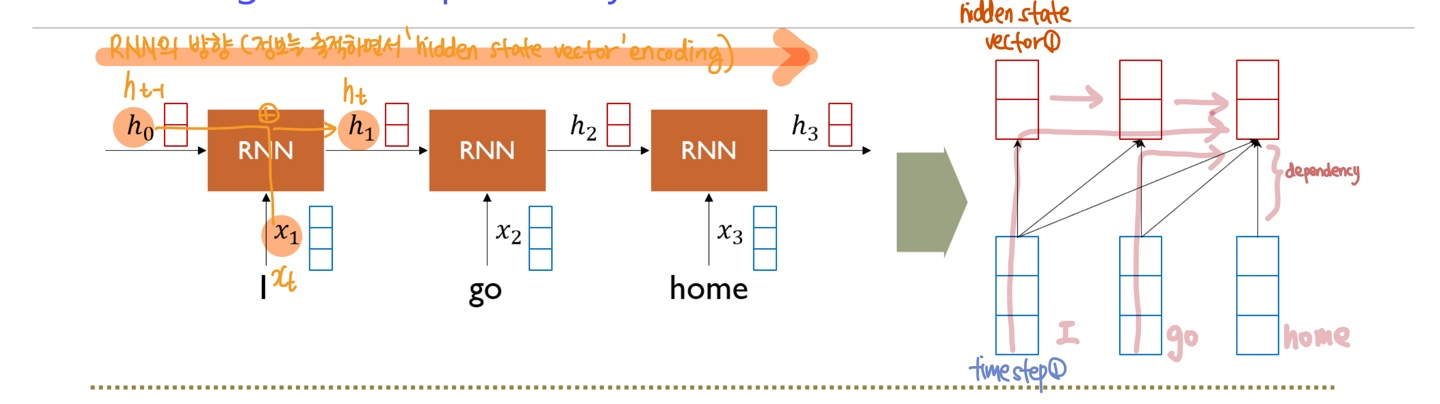
RNN에서 "I"라는 단어는 time step의 개수만큼 통과하여야 마지막까지 전달이 된다.
=> 이 과정에서 Gradient Vanishing / Exploding 문제, Long term dependency 등 멀리 있는 time step의 정보를 배달하기까지 여러 정보의 손실과 변질 등의 이슈가 존재한다.
-
RNN의 문제를 해결하려는 노력 - Bi-directional RNN
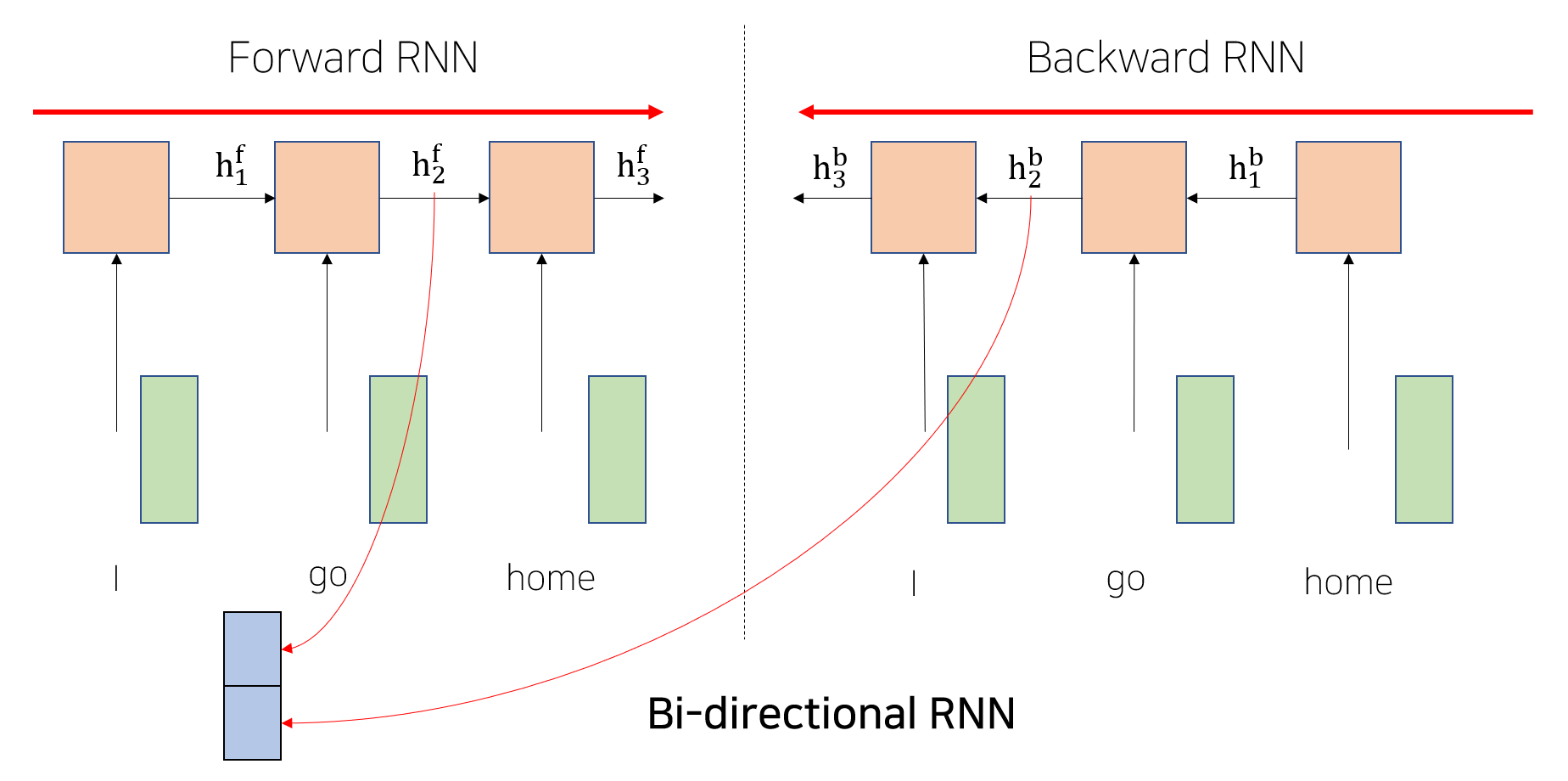
항상 왼쪽에서 오른쪽으로 흐르는 RNN의 문제를 해결하기 위해 Forward RNN의 hidden state vector와 별개의 파라미터를 가지는 또 다른 Backward RNN의 hidden state vector를 concate 시켜 전체 시퀀스를 고려한 encoding이 가능해진다.여전히 RNN은 전체 시퀀스 내의 문맥을 반영한 encoding에 한계가 있어 이를 대체하는 용도로 attention module이 사용됨
attention module의 구조와 작동 방식
 위의 그림은 "I go home" 에서 "I"의 encoding vector를 생성하는 경우다.
위의 그림은 "I go home" 에서 "I"의 encoding vector를 생성하는 경우다.
-
encoding vector 구하는 방법
-
I x I, I x go, I x home 과 같이 I에 대해 모든 단어의 내적을 통한 유사도를 구한다.
-
이 유사도를 softmax를 통과해 가중치(0.2,0.1,0.7)를 구한다
-
입력 벡터와 가중치를 곱한 가중 평균을 통해 결과적으로 "I"벡터의 encoding vector를 구한다.
=> x1이 decoder의 hidden state vecotr라고 생각할때 encoder의 hidden state vector도 "I go home"으로 decoder와 동일하게 된다.
결과적으로, decoder와 encoder로 구별되는 것이 아니라 동일한 입력 벡터 set을 가지고 atttention이 가능하다는 측면에서 이를 self-attention 모듈이라고 부른다.
-
문제점
이 과정에서 "I" 벡터가 decoder의 hidden state vector로 쓰였을 때, 자기 자신과 내적될 경우에 다른 벡터와 내적했을때 보다 훨씬 큰 가중치가 도출된다. 그렇게 encoding을 수행하면 vector들도 자기 자신의 원래 정보만을 주로 포함하고 있는 벡터로 나오게 될 것이다.=> 이러한 가장 기본적인 형태의 attention의 작동과정을 더 유연하게 확장해서 문제점을 개선하는 모델을 만들었다.
서로 다른 역할을 수행하는 입력 벡터
Query : 주어진 벡터들 중 어떤 벡터를 가져올지 기준이 되는 벡터 (ex. "I"의 encoding vector를 구하기 위해서는 "I"가 Query 벡터)
Key : 유사도를 구하기 위해 Query와 내적이 되는 재료 벡터 (ex. "I", "go", "home")
Value : query와 key의 내적을 통해 나온 유사도를 softmax 취하여 가중평균을 적용할 재료 벡터 (ex. "I", "go", "home")
-
결국 한 시퀀스를 attention을 통해 encoding 하는 과정에서 각 벡터들이 query, key, value로 작동하고 있다.
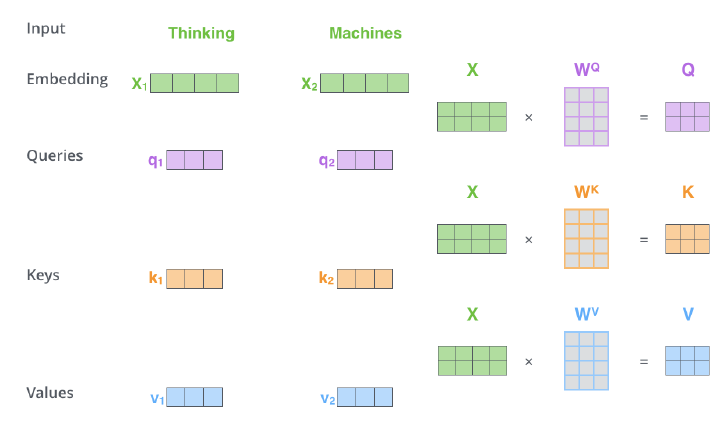
동일한 set의 벡터("I","go","home")에서 출발했다고 해도 각 역할에 따라 서로 다른 형태로 변환될 수 있도록 해주는 linear transform matix (Wq, Wk, Wv)가 각각 따로 정의되어 있다. 이를 통해 같은 벡터 내에서 세가지 역할이 공유되는 제한적인 형태가 아니라 query, key, value일때 서로 다른 벡터로 변환될 수 있는 확장된 형태가 만들어지게 된다.
=> 결과적으로 RNN에서 발생하던 Long temr dependency와 달리 내적으로 도출된 가중치에 따라 아무리 멀리 있는 단어도 쉽게 가져올 수 있다. 또한, attention과 달리 다른 내적의 가중치보다 "I" (자기 자신)의 가중치가 더 작을 수 있게 된다.(실제 계산될 때는 key에서 나온 가중치가 매칭되는 value 벡터가 있어야 하기 때문에 둘의 개수는 동일해야 한다.)
