
GraphQL은 무엇일까?
GraphQL은 웹에서 데이터를 주고받기 위해 사용하는 질의 언어(Query Language)이자, 서버와 클라이언트 간의 통신을 위한 실행 환경입니다.
클라이언트가 필요한 데이터를 직접 요청하면, 서버가 그에 맞는 데이터를 정확히 반환하는 것이 핵심입니다. 이를 통해 불필요한 데이터를 가져오는 문제를 해결하고, 효율적인 데이터 통신을 가능하게 합니다.
또한, 우리가 아는 또다른 질의 언어인 SQL(Structured Query Language)과 이름이 비슷하여 혼동하실 수 있지만 두가지는 사용법이 아주 다릅니다.
SQL은 데이터베이스 내의 데이터를 관리하고 조작하는 언어인 반면, GraphQL은 API 통신을 위해 클라이언트가 원하는 데이터를 서버에 요청하는 언어입니다.
즉, SQL은 데이터베이스에, GraphQL은 웹 API에 초점을 맞춥니다.
GraphQL의 등장 배경
GraphQL의 등장 전, 웹과의 통신은 주로 REST API를 통해 이루어졌는데 REST API에는 필요 이상의 정보를 반환하는 과다 조회, 그리고 필요한 정보를 얻기 위해 여러번 요청해야하는 불완전 조회라는 한계점이 있었습니다.
그래서 “클라이언트가 원하는 데이터를 정확히 요청하고 서버는 필요한 것만 반환하자”라는 발상에서 페이스북이 2012년에 개발한 데이터 질의 언어가 바로 GraphQL입니다.
REST API의 한계점
Over-fetching (과다 조회)
REST API는 정해진 엔드포인트에서 정해진 데이터를 모두 가져옵니다. 예를 들어, 사용자의 이름만 필요한데도 이메일, 주소, 전화번호 등 모든 정보를 가져와야 하는 문제가 발생합니다. 이는 불필요한 데이터 전송으로 네트워크 비용을 낭비하게 합니다.
예를 들어 사용자의 이름을 조회하려고 할 때, REST API는 GET /users/1 라는 요청을 보내게 되고 서버는 아래와 같이 사용자의 모든 정보를 반환합니다.
# 서버 응답
{
"id": 1,
"name": "오백",
"email": "ohback@example.com",
"address": {
"street": "한글로 500",
"city": "서울"
},
"phone": "010-5000-5000"
}Under-fetching (불완전 조회)
원하는 데이터를 모두 가져오려면 여러 번의 API를 호출해야 하는 문제입니다.
예를 들어, 사용자의 게시글 목록과 정보를 가져오려면 GET /users/1 와 GET /posts/101 를 각각 호출해야 합니다. 이로 인해 클라이언트 측에서 여러 번의 요청과 응답을 처리해야 하는 번거로움이 생깁니다.
요청 1: 사용자 정보를 가져옵니다.
GET /users/1
# 요청 1의 서버 응답
{
"id": 1,
"name": "오백",
"postIds": [101, 102]
}요청 2: 사용자의 게시글(101) 정보를 가져옵니다.
GET /posts/101
# 요청 2의 서버 응답
{
"id": 101,
"title": "GraphQL 시작하기",
"content": "GraphQL은 데이터 질의 언어입니다."
}요청 3: 사용자의 게시글(102) 정보를 가져옵니다.
GET /posts/102
# 요청 3의 서버 응답
{
"id": 102,
"title": "REST vs GraphQL",
"content": "REST API와 GraphQL의 차이점은?"
}이렇게 사용자의 이름(name)만 필요한데도, 이메일, 주소, 전화번호 등 불필요한 데이터가 모두 전송되어 데이터 낭비로 이어진다거나, 사용자의 이름과 게시글 제목을 한 번에 가져오고 싶지만 두 번의 별도 API 요청을 해야 되기에 클라이언트 측에서 여러 번의 통신을 처리해야 한다는 비효율적 측면이 있습니다.
GraphQL을 사용한 해결 예시
GraphQL은 이러한 문제를 해결하기 위해 클라이언트가 요청하는 데이터의 구조를 직접 정의하여 요청한 필드(name, title)만 포함된 데이터를 한 번의 요청으로 가져올 수 있도록 했습니다.
# GraphQL 요청
query {
user(id: "1") {
name
posts {
title
}
}
}# 서버 응답
{
"data": {
"user": {
"name": "오백",
"posts": [
{
"title": "GraphQL 시작하기"
},
{
"title": "REST vs GraphQL"
}
]
}
}
}위처럼 userID == 1인 name과 posts{title} 를 찾는 요청 보내면 데이터 낭비 없이 요청한 정보만을 반환합니다.
(*참고로 GraphQL은 콤마(,)를 쓰지 않고 들여쓰기와 중괄호{}로 구조를 구분합니다.)
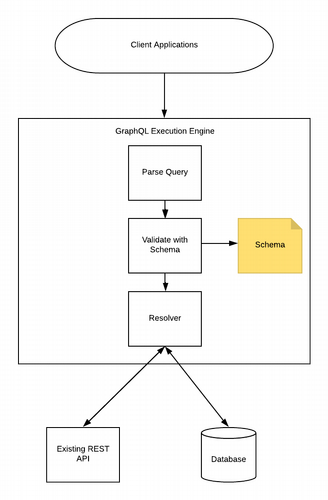
GraphQL의 핵심 요소
그렇다면 GraphQL은 어떤 요소로 구성되어 있을까요?
GraphQL은 Schema (스키마) Query (쿼리) Resolver (리졸버) 이렇게 3가지 핵심 요소로 이루어져 있습니다.
출처: https://opensource.com
Schema (스키마):
API에서 제공하는 데이터의 타입과 구조를 정의하는 청사진입니다.
마치 설계도처럼, 클라이언트가 어떤 데이터를 요청할 수 있는지 명확하게 알려줍니다.
# 데이터 타입 및 구조 정의
type User {
id: ID!
name: String
posts: [Post]
}
type Post {
id: ID!
title: String
content: String
}
type Query {
user(id: ID!): User
}Query (쿼리):
클라이언트가 서버에 데이터를 요청할 때 사용하는 질의입니다.
원하는 필드(데이터 항목)를 선택하여 계층적으로 작성합니다.
# 쿼리 보내기
query {
user(id: "1") {
name
posts {
title
}
}
}Resolver (리졸버):
서버에서 쿼리를 받아 실제로 데이터를 찾아오는 함수입니다.
데이터베이스나 다른 API에서 데이터를 가져와 클라이언트의 요청에 맞게 조합하여 반환합니다.
// 간단한 더미 데이터베이스를 가정합니다.
const users = [
{ id: '1', name: '오백' },
{ id: '2', name: '오천' }
];
const posts = [
{ id: '101', title: 'GraphQL 시작하기', content: 'GraphQL은...', authorId: '1' },
{ id: '102', title: 'REST vs GraphQL', content: '두 방식의 가장 큰 차이...', authorId: '1' },
{ id: '201', title: '데이터 분석 입문', content: '데이터 분석은...', authorId: '2' }
];
// 리졸버 맵 객체를 정의합니다.
const resolvers = {
Query: {
user: (parent, args, context, info) => {
// args.id를 사용하여 해당 사용자를 찾습니다.
return users.find(user => user.id === args.id);
}
},
User: {
// User 타입의 'posts' 필드에 대한 리졸버입니다.
// user(부모) 객체를 인자로 받아 해당 사용자의 게시글을 필터링합니다.
posts: (parent, args, context, info) => {
return posts.filter(post => post.authorId === parent.id);
}
}
};Resolver (리졸버) 작동 원리:
- 클라이언트가
query { user(id: "1") { name posts { title } } }를 요청합니다. - GraphQL 서버는 먼저
Query.user리졸버를 실행합니다. user리졸버는args.id가"1"이므로,users배열에서id가"1"인 사용자 객체({ id: '1', name: '오백' })를 찾아서 반환합니다.- GraphQL은 이 사용자 객체의
posts필드가 요청되었음을 확인하고,User.posts리졸버를 실행합니다. User.posts리졸버는parent인자로user리졸버가 반환한{ id: '1', name: '오백' }객체를 받습니다.posts리졸버는parent.id('1')를 사용해posts배열에서authorId가'1'인 게시글들을 필터링하여 반환합니다.- 최종적으로 GraphQL 서버는 이 모든 결과를 조합하여 클라이언트에게 필요한 데이터만 포함된 JSON 응답을 보냅니다.
이처럼 리졸버는 쿼리의 각 필드에 대한 데이터 처리 로직을 담당하며, 복잡한 데이터 관계를 효율적으로 처리할 수 있게 해줍니다.
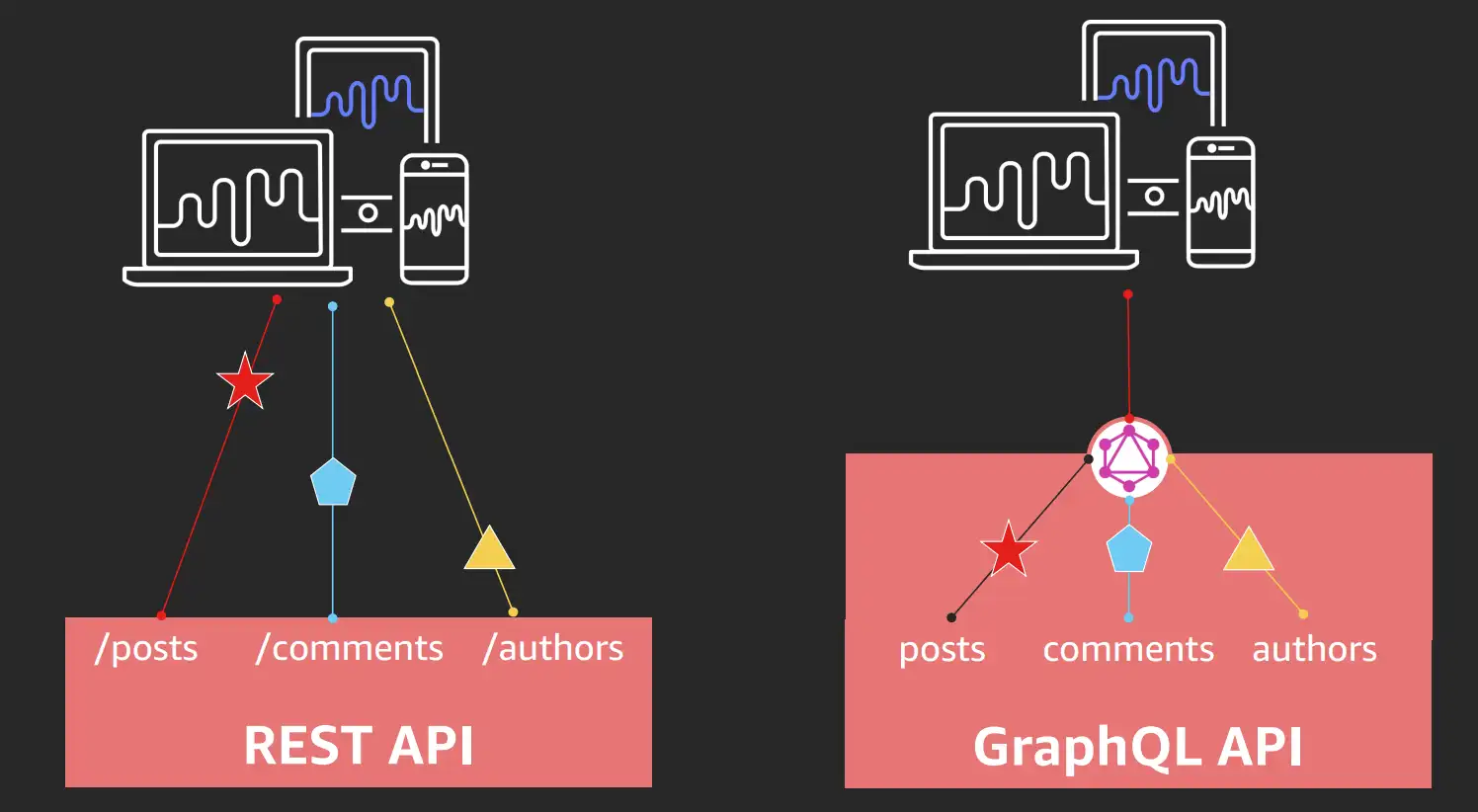
GraphQL vs REST API: 장단점 비교하기
출처: https://josipmisko.com
GraphQL
- 구조: 단 하나의 엔드포인트(
POST /graphql)를 사용합니다. - 특징: 단일 엔드포인트를 사용하며, 클라이언트가 원하는 데이터 구조를 쿼리 형태로 요청합니다.
- 장점:
- 효율적인 데이터 요청: 필요한 데이터만 가져와 네트워크 트래픽을 줄입니다.
- 유연성: 클라이언트가 데이터 구조를 직접 정의하여 개발이 용이합니다.
- 자동 문서화: 스키마를 통해 API 문서가 자동으로 생성됩니다.
- 단점:
- 서버 구현 복잡성: 스키마와 리졸버를 설계하고 관리해야 합니다.
- 캐싱 어려움: 단일 엔드포인트 방식이라 캐싱 전략이 복잡합니다.
- 성능 문제: 복잡한 쿼리가 서버에 부하를 줄 수 있습니다.
REST API
- 구조: 여러 개의 엔드포인트(
GET /users/1,GET /users/1/posts)가 존재합니다. - 특징: URL(URI)과 HTTP 메서드(GET, POST, PUT, DELETE)를 조합하여 리소스를 다룹니다.
- 장점:
- 구현이 단순: 웹의 표준 기술(HTTP)을 사용하므로 이해하고 구현하기 쉽습니다.
- 캐싱 용이: URL 기반으로 캐싱이 가능하여 효율적입니다.
- 단점:
- 비효율적 통신: Over-fetching 및 Under-fetching 문제가 발생합니다.
- 여러 번의 요청: 복잡한 데이터를 가져오기 위해 여러 번 요청해야 합니다.
결론
GraphQL과 REST API는 각각의 장단점이 뚜렷하므로, 프로젝트의 상황과 요구사항에 맞게 선택하는 것이 가장 좋습니다.
- REST API는 엔드포인트가 명확하고 구조가 단순해 소규모 프로젝트나 고정된 데이터 구조를 다룰 때 적합합니다. 웹 브라우저나 CDN 캐싱을 적극적으로 활용해야 하는 경우에도 좋은 선택입니다.
- GraphQL은 데이터 관계가 복잡하거나, 다양한 클라이언트(웹, 모바일, IoT 등)가 각각 다른 데이터를 필요로 할 때 매우 효과적입니다. 특히, API의 진화가 잦고 유연한 개발이 필요한 경우에 빛을 발합니다.
그러므로 어떤 기술이 '더 좋다'고 단정하기보다는, 프로젝트의 특성을 이해하고 가장 효율적인 방법을 선택하는 현명한 판단이 필요합니다.
참고자료
F-Lab: https://f-lab.kr
Kakao Tech: https://tech.kakao.com
Blog1: https://velog.io/@jangwonyoon
Blog2: https://americanopeople.tistory.com
