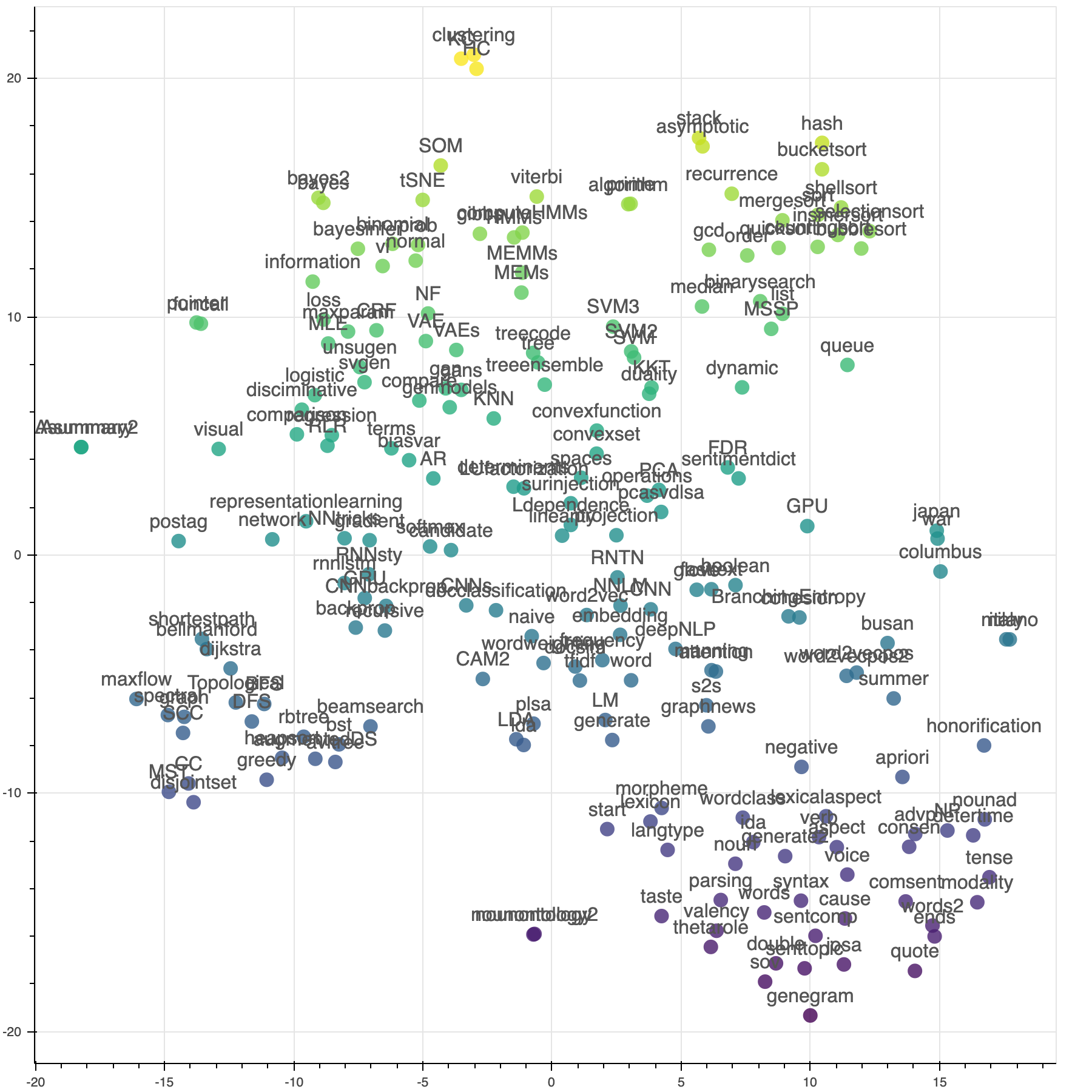
특징 추출 및 임베딩(Feature Extraction & Embedding)이란?
텍스트 데이터를 숫자로 변환하는 과정으로 머신러닝/딥러닝은 숫자로 된 데이터만 처리할 수 있기 때문에 텍스트를 적절한 형태의 수치 벡터로 변환해야 한다.
⬇️ 아래는 임베딩 된 단어의 시각화
이미지 출처: https://heung-bae-lee.github.io/
1. Bag of Words (BoW)
단어 등장 횟수를 기반으로 문장을 벡터화하는 방식으로 단어의 순서와 의미를 고려하지 않고 단순 빈도만을 반영한다.
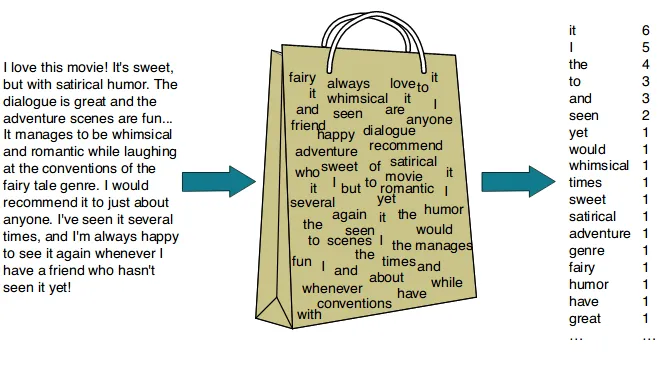
이미지 출처: https://velog.io/@aelle/
1-1. BoW 동작 방식
- 문서에서 등장하는 모든 단어를 나열하여 단어 사전(vocabulary)을 만들고
- 각 문서를 해당 단어 사전을 기준으로 벡터로 변환
- 특정 문서에서 단어가 등장하면 해당 단어의 값(빈도수)을 증가 시킴
| 문장 | "나는" | "사과를" | "좋아한다" | "바나나를" | "싫어한다" |
|---|---|---|---|---|---|
| 나는 사과를 좋아한다 | 1 | 1 | 1 | 0 | 0 |
| 나는 바나나를 좋아한다 | 1 | 0 | 1 | 1 | 0 |
| 나는 바나나를 싫어한다 | 1 | 0 | 0 | 1 | 1 |
# 예시 문장
문장 1: "나는 밥을 먹었다"
문장 2: "나는 공부를 했다"
→ 단어 사전: ["나는", "밥", "먹었다", "공부", "했다"]
# BoW 벡터
문장 1: [1, 1, 1, 0, 0]
문장 2: [1, 0, 0, 1, 1]1-2. BoW의 특징
BoW는 문서를 단어별 빈도 벡터로 변환하는 방식이라, 적어도 띄어쓰기 기준의 토큰화는 필요하지만 BoW 자체는 형태소 분석을 강제하지 않음 (단순한 단어 나열 가능)
예: "나는 사과를 좋아해" → ["나는", "사과를", "좋아해"]
- 장점: 단순하고 구현이 쉬우며, 빠르게 적용 가능
- 단점: 단어 순서와 의미를 고려하지 않고, 문서 길이가 길어지면 벡터 차원이 커짐 (희소 행렬)
2. TF-IDF (Term Frequency-Inverse Document Frequency)
TF-IDF는 단순한 단어 빈도를 기반으로 한 BoW를 보완한 방법이다.
2-1. TF-IDF 동작 방식

*이미지 출처: https://www.kdnuggets.com/
1) TF(Term Frequency): 특정 문서에서 해당 단어가 얼마나 자주 등장하는지?
2) IDF(Inverse Document Frequency): 해당 단어가 전체 문서에서 얼마나 희귀한지?
3) TF-IDF 값 계산: TF × IDF를 곱하여 흔한 단어의 가중치를 낮추고 중요한 단어의 가중치를 높임
2-2. TF-IDF의 특징
문서에서 특정 단어가 얼마나 중요한지 수치화하고, 자주 등장하는 단어는 가중치를 낮추고, 특정 문서에서만 자주 나오는 단어의 가중치를 높임
예를 들어, "나는", "그리고" 같은 단어는 거의 모든 문서에서 등장하기 때문에 IDF 값이 낮아지고, 특정 문서에서만 자주 등장하는 단어(예: "딥러닝", "자연어")는 IDF 값이 높아진다.
- 장점: 단순 빈도수 기반보다 중요한 단어를 잘 추출할 수 있음
- 단점: 여전히 단어 순서를 고려하지 않음
3. 단어 임베딩(Word Embedding)
단어 임베딩은 BoW나 TF-IDF처럼 단순 빈도 기반 방법의 한계를 보완하기 위해 등장한 기법이다.
이 방식은 단어를 고정된 크기의 실수 벡터로 변환하며, 단어 간의 의미적 유사성을 수치적으로 표현할 수 있도록 구성되었다.
3-1. Word2Vec (CBOW, Skip-gram)
Word2Vec은 단어 간 문맥을 활용하여 비슷한 의미의 단어를 가까운 벡터 공간에 위치하도록 학습하며,
대표적으로 CBOW(Continuous Bag of Words)와 Skip-gram 두 가지 구조가 존재한다.
- CBOW: 주변 단어들을 이용해 중심 단어를 예측
- Skip-gram: 중심 단어로 주변 단어를 예측
예시:
"king" - "man" + "woman" ≈ "queen"
→ 단어 간 관계를 벡터 연산으로 표현 가능
| 단어 | 벡터(예시) |
|---|---|
| king | [0.5, 0.3, -0.2, ...] |
| queen | [0.6, 0.35, -0.25, ...] |
| apple | [0.1, 0.8, -0.6, ...] |
| banana | [0.15, 0.85, -0.65, ...] |
→ king과 queen / apple과 banana가 유사한 의미를 가지므로, 유사한 위치에 벡터화됨
- 장점: 단어 간 의미를 반영할 수 있음
- 단점: 학습이 필요하며, 많은 데이터가 필요할 수 있음
3-2. GloVe (Global Vectors for Word Representation)
GloVe는 Word2Vec과 유사하지만, 학습 방식이 다름.
말뭉치 전체에서의 단어 동시 등장 빈도(co-occurrence matrix)를 기반으로 벡터를 학습하며, 통계 기반으로 구성됨.
- 장점: 전체 데이터에 대한 전역적 통계를 반영함
- 단점: 희소 행렬 처리에 비용이 발생할 수 있음
3-3. FastText
FastText는 Word2Vec과 달리 단어를 문자 단위 n-gram으로 분해하여 학습함.
예: "apple" → ["ap", "pp", "pl", "le"]
따라서 FastText는 훈련되지 않은 단어라도 부분 단위로 벡터화 가능하다는 장점이 있음.
→ 신조어, 오타, 희귀 단어 처리에 유리함
4. 사전 학습 기반 임베딩 (Pre-trained Language Model Embedding)
기존의 Word2Vec, GloVe, FastText 등은 고정된 단어 벡터를 사용하며, 문맥에 따라 단어 의미가 달라지는 경우를 반영하지 못하는 한계가 존재한다.
예시:
"사과를 먹었다"의 사과 → fruit
"사과했다"의 사과 → apology
→ 기존 임베딩은 두 경우 모두 같은 벡터로 표현됨
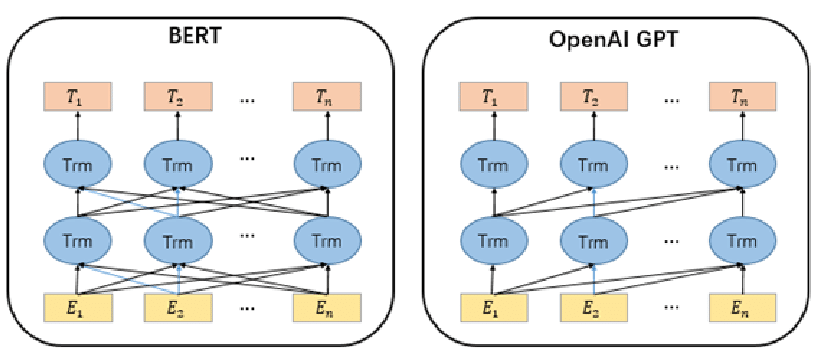
이미지 출처: https://www.researchgate.net/
이 문제를 해결하기 위해 문맥(Context)을 반영할 수 있는 언어 모델 기반 임베딩이 등장하였는데, 대표적으로 BERT, GPT, RoBERTa, T5 등이 있으며, 대부분 Transformer 구조를 기반으로 구성되었다.
4-1. BERT (Bidirectional Encoder Representations from Transformers)
BERT는 문장의 양방향 문맥을 동시에 고려하여 단어의 의미를 벡터화한다. Word2Vec처럼 고정된 벡터가 아니라, 위치와 주변 단어에 따라 벡터가 달라지는 구조로 되어 있다.
예시:
"나는 사과를 먹었다" → [사과] → [과일 의미의 벡터]
"나는 사과했다" → [사과] → [행동 의미의 벡터]
→ 같은 단어라도 문맥에 따라 다른 벡터가 생성됨
- 장점: 문맥 반영 가능, 의미 표현력 우수
- 단점: 계산 비용이 큼, 구조 복잡
4-2. GPT (Generative Pre-trained Transformer)
GPT는 BERT와 달리 문장 왼쪽 → 오른쪽 방향의 문맥만 반영하는 언어 생성 모델로 자연어 생성 태스크에서 주로 사용되며, Embedding vector도 문맥에 따라 동적으로 생성된다. GPT 계열(LLaMA, GPT-3.5, GPT-4 등)은 일반적인 문장 표현뿐 아니라, 대화 맥락까지 반영 가능한 벡터 생성이 가능하다.
4-3. 사전 학습 임베딩의 특징
| 항목 | 내용 |
|---|---|
| 입력 단위 | 토큰 (서브워드) |
| 벡터 구조 | 문맥에 따라 동적으로 변함 |
| 문장 수준 표현 | 가능 (문장 전체의 의미 벡터 추출 가능) |
| 모델 크기 | 큼 (수억~수십억 파라미터) |
| 활용 예시 | 문장 분류, 질의응답, 요약, 추천, 검색 등 |
5. 임베딩 기법 비교 & 결론
| 기법 | 문맥 반영 | 특징 | 벡터 타입 | 토큰 단위 |
|---|---|---|---|---|
| BoW / TF-IDF | ✖ | 단순 빈도 기반 | 희소(sparse) | 단어 |
| Word2Vec / GloVe | △ | 의미 유사성 반영 | 고정(dense) | 단어 |
| FastText | △ | 부분 일반화 가능 | 고정(dense) | 문자 n-gram |
| BERT / GPT | ✔ | 문맥 완전 반영 | 동적(dense) | 서브워드 |
결론: 사전 학습 모델 임베딩은 문맥까지 고려할 수 있다는 점에서 기존 임베딩보다 훨씬 강력하며, 현대 NLP의 기본 인프라로 자리잡고 있다.
