SK 네트웍스 Family AI camp
1.파이썬(Python) 개발 환경 구축하기

⭐️24년 12월의 나: "코딩의 k자도 몰라요." (코딩은 c란다..🤦♀️) 현재의 나와 같은 코린이를 위해 또 미래의 나를 위해 파이썬 개발 환경 구축에 대하여 간단히 정리해보았다.
2.파이썬: 자료형

이번 포스팅에선 자료형의 연산과 사용법에 대해 헷갈릴 때 찾아볼 수 있도록 간단히 정리하고 문제를 풀며 생긴 오류를 해결하는 과정 그리고 해결과정 중 파생된 궁금증에 대해 적어보았다. 1. 파이썬의 자료형 기본 자료형 숫자형, 문자형, 논리형 : 하나의 변수만 저장
3.파이썬: 제어문
조건문과 반복문은 다양한 경로로 작성할 수 있다. 한 문제에 대하여 여러가지 갈래로 생각해보고 다르게 작성해보자
4.파이썬: 함수(function)
오늘은 함수(function)를 배우며 헷갈렸던 개념과 궁금한 점 그리고 문제를 풀며 만났던 에러들을 해결하는 과정을 정리해보았다.
5.파이썬: 클래스(Class)와 모듈(Module)

연습 문제를 풀어보다 좌절감을 느끼게 한 클래스(Class)😢 지난 5일간 배운 것 중에 가장 헷갈렸던 파트라 개념부터 문제풀이까지 정리해보았다.
6.파이썬: Exception
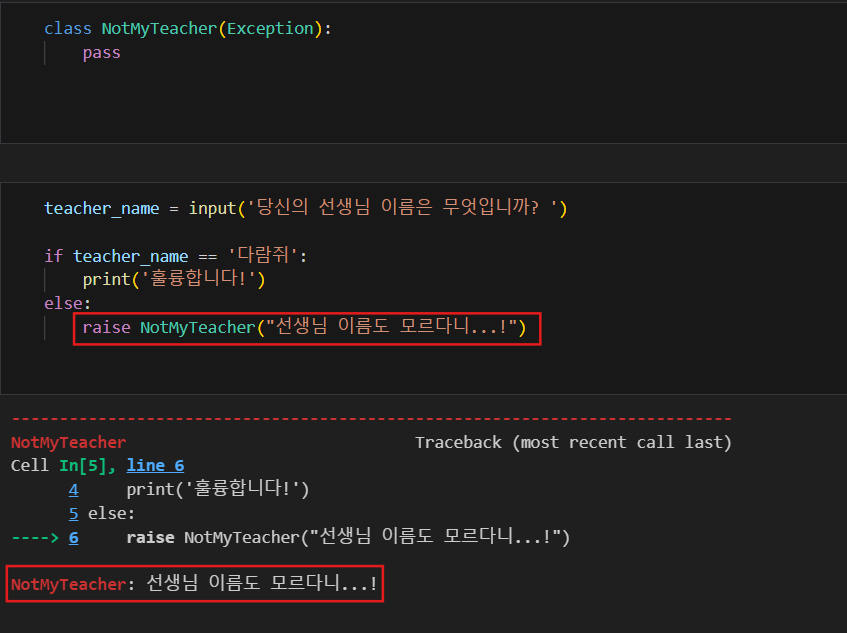
파이썬: Exception
7.파이썬: 도대체 "객체지향언어"가 뭔가요?
"객체지향언어", 누군가 파이썬에 대해 설명하기 시작한다면 가장 먼저 꺼내는 단어가 아닐까
8.Call by Assignment
call by assignment / call by value / call by reference 의 비교
9.Database: Data Modeling
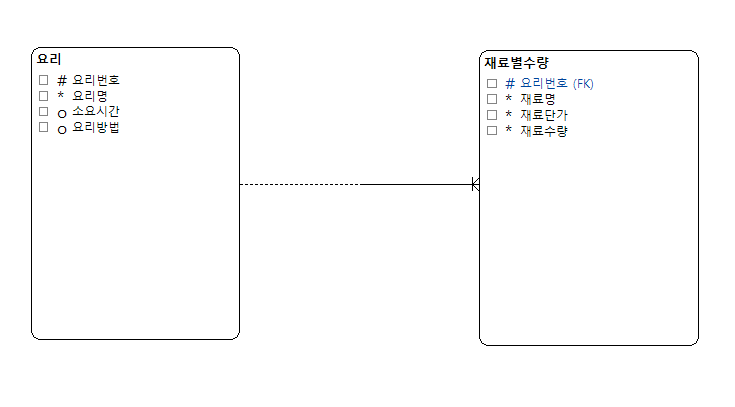
지난주 파이썬 강의가 끝나고 오늘부터 database에 대하여 배우기 시작했다. 아직 mySQL을 제대로 다뤄보지 못했기 때문에 오늘은 database 이론을 개략적으로 정리해 보았다.
10.Database: MySQL

MySQL의 문법을 간단히 정리하며 예제를 풀며 궁금했던 것들을 찾아 기록하였다.
11.Database: MySQL(2)

쿼리 명령어의 작성 및 실행 순서
12.Crawling: Open API / BeautifulSoup
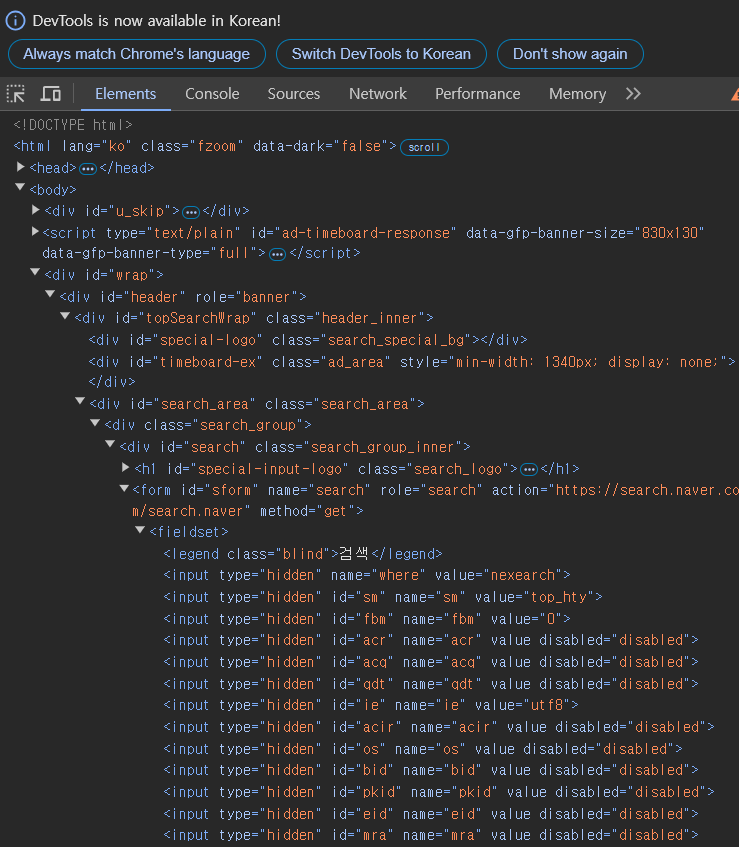
이번 시간엔 Open API를 이용해 데이터를 가져오는 방법과 BeautifulSoup을 통해 데이터를 크롤링 해오는 방법에 대해 정리 해보았다.
13.Crawling: Selenium
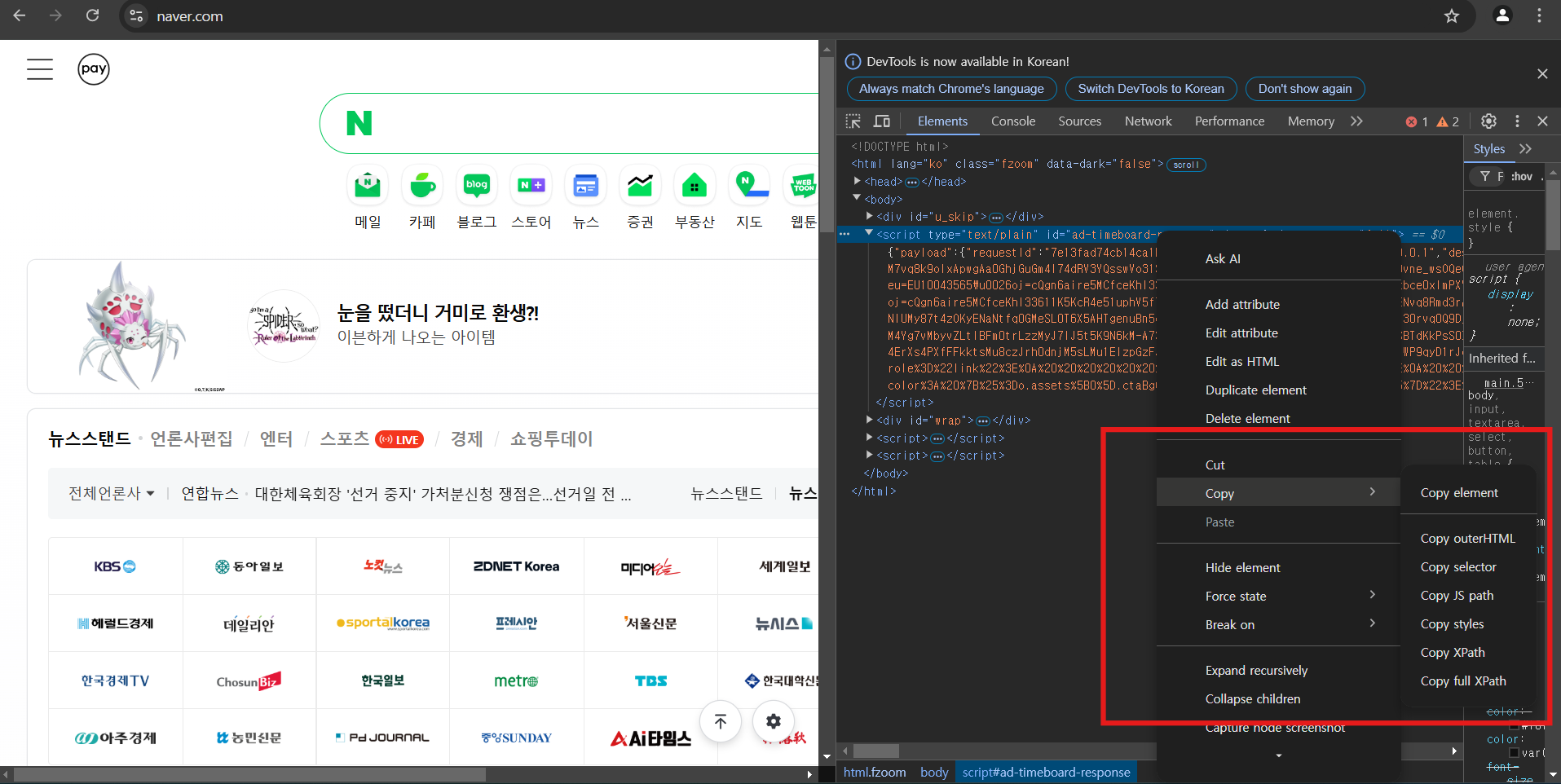
오늘은 동적페이지를 크롤링 해오는 Selenium에 대해 정리 해보았다.
14.Team Project: 데이터수집 및 저장 #1
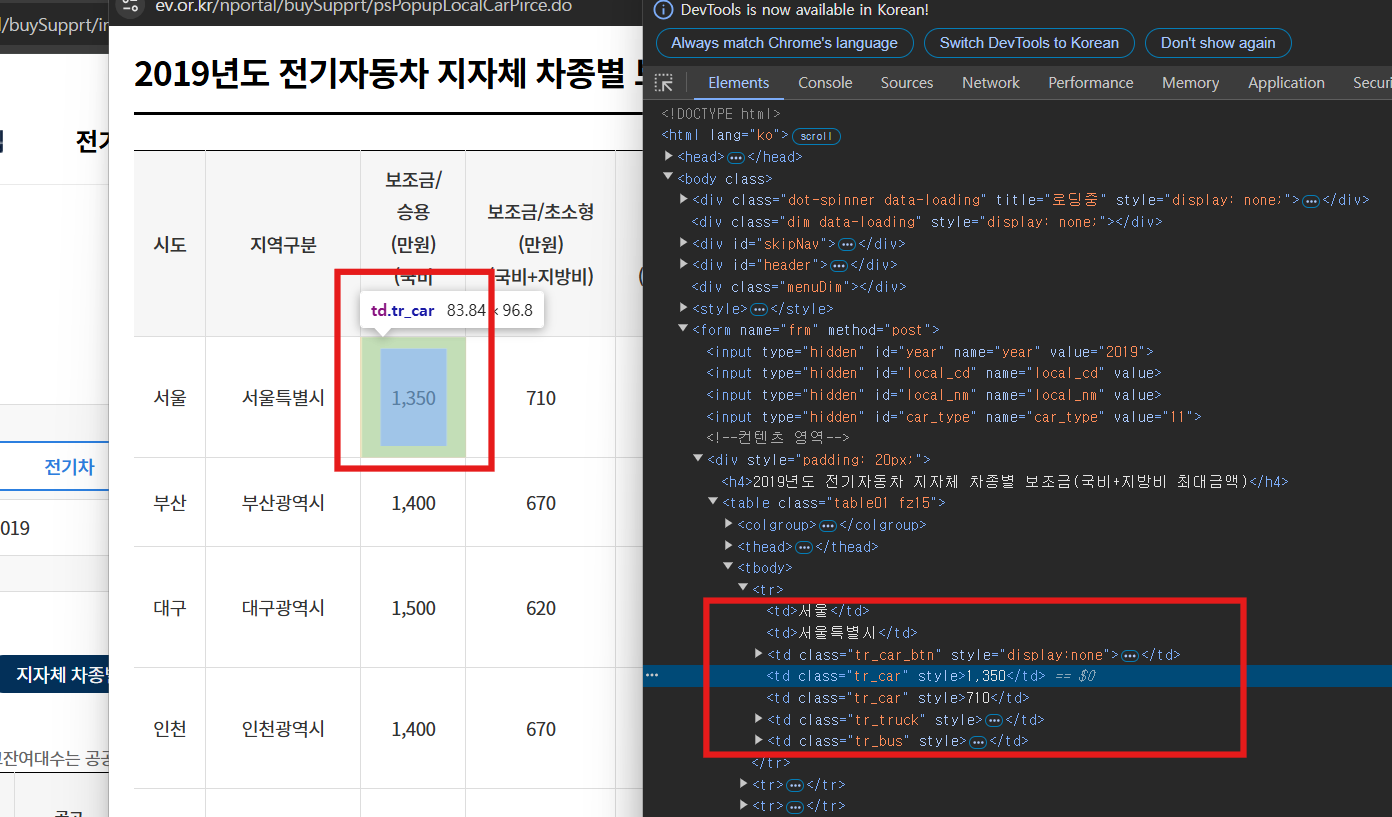
첫 번째 팀프로젝트에 대한 기록
15.Team Project: 데이터수집 및 저장 #2

팀프로젝트 1편에 이어서-
16.깃린이를 위한 깃(Git)/ 깃허브(GitHub) 정리

GitHub 초보자 깃린이를 위한 명령어 설명
17.Data Analysis: NumPy

NumPy란 Numerical Python의 줄임말로, 대규모 다차원 배열과 행렬 연산을 지원하는 파이썬 라이브러리이다.
18.Data Analysis: Pandas

Pandas는 데이터 분석과 조작에 특화된 라이브러리로, 구조화된 데이터(테이블 형식, 시계열 등)를 처리하는 데 사용된다.
19.Machine Learning: 개요
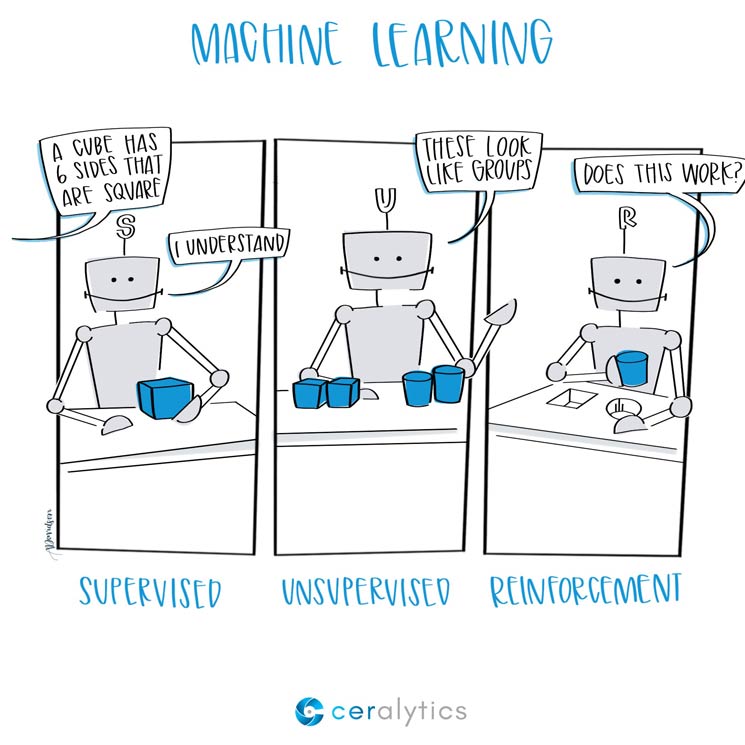
주어진 데이터를 스스로 학습하여 수치적인 특징을 찾고, 다른 데이터가 주어졌을 때 결과가 되는 데이터를 예측할 수 있는 인공지능 모델을 만드는 것. 통계적 접근법, 경사하강법을 통해 정답과 예측한 값의 차이를 점차 줄여나가는 방식으로 학습하는 것이 특징.
20.Machine Learning: 지도학습, 회귀 및 분류
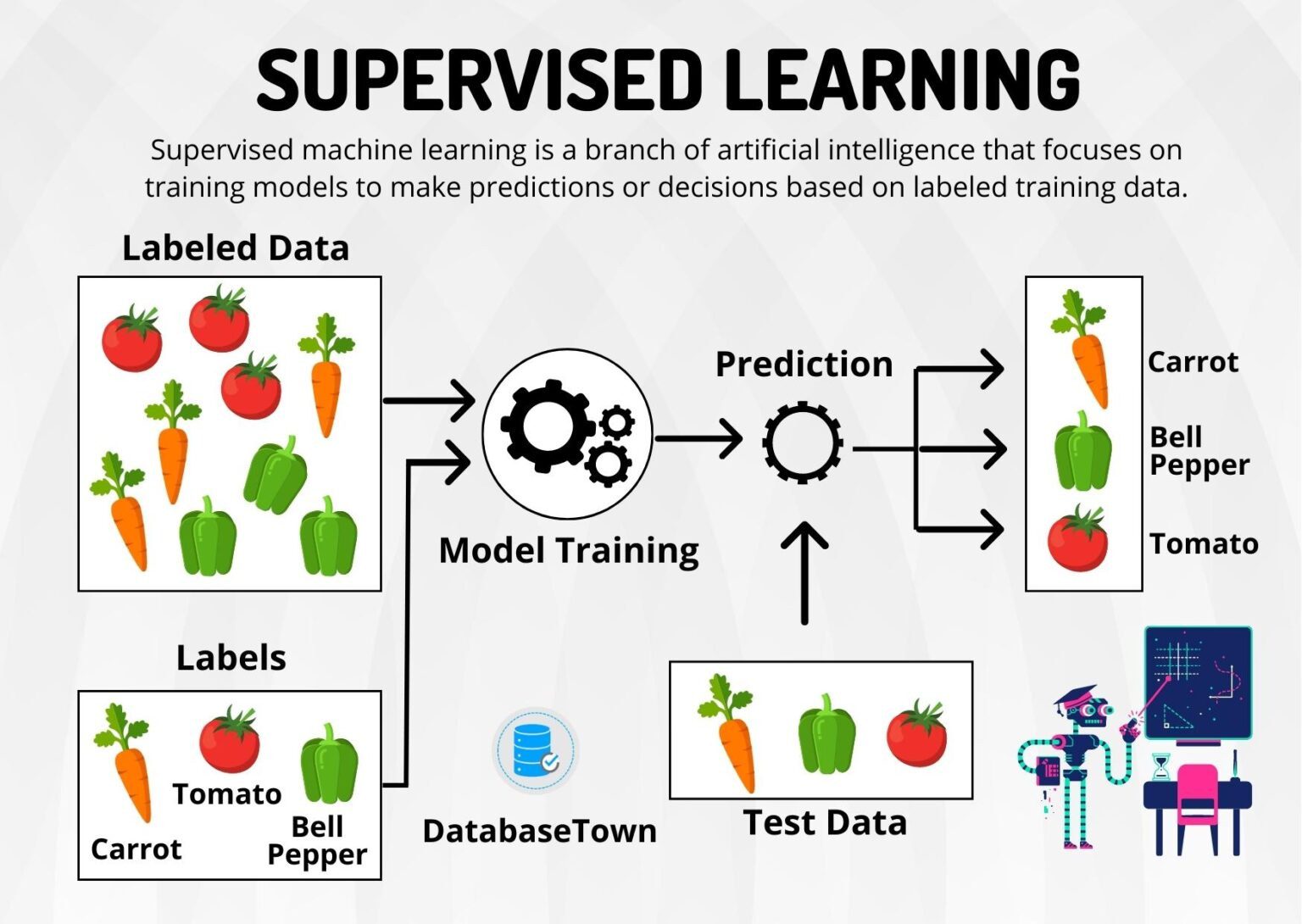
머신러닝이란 주어진 데이터를 스스로 학습하여 수치적인 특징을 찾고, 다른 데이터가 주어졌을 때 결과가 되는 데이터를 예측할 수 있는 인공지능 모델을 만드는 것
21.Machine Learning: 결정트리(Decision Tree)
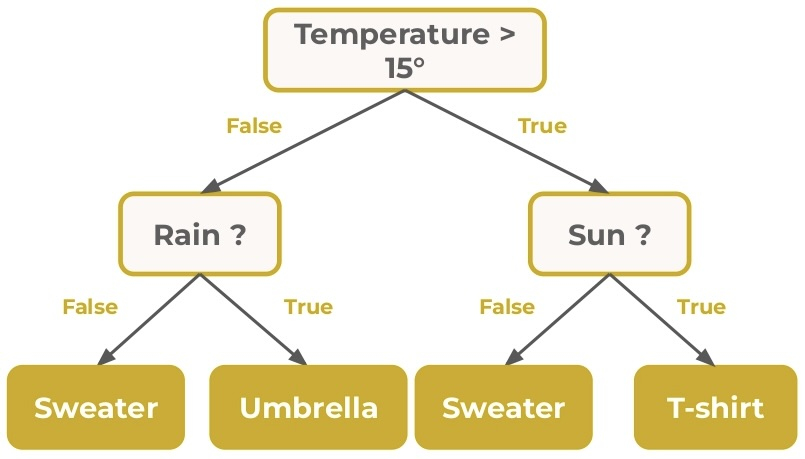
Decision Tree는 분류 및 회귀 작업 모두에 사용되는 비모수 지도 학습 알고리즘으로 루트 노드, 가지, 내부 노드 및 리프 노드로 구성된 계층적 트리 구조를 가지고 있다.
22.Machine Learning: SVM
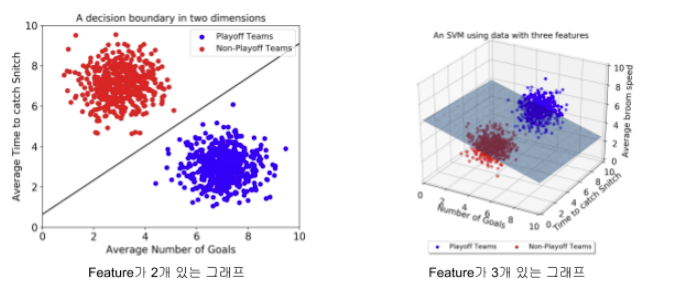
서포트 벡터 머신, 즉 SVM(Support Vector Machine)은 N차원 공간에서 각 클래스 간의 거리를 최대화하는 최적의 선 또는 초평면을 찾아 데이터를 분류하는 지도형 머신 러닝 알고리즘이다.
23.Machine Learning: 앙상블/랜덤 포레스트
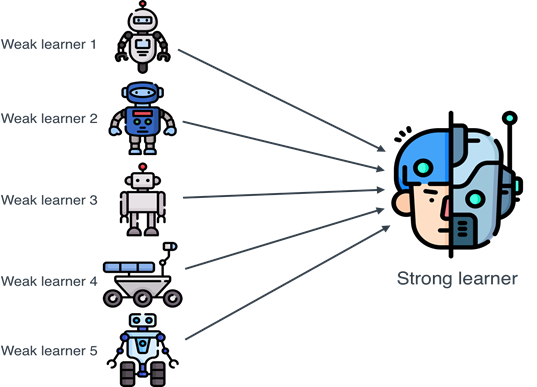
여러 약한/강한 학습기의 **예측을 결합**하여 단일 모델보다 **일반화 성능**을 높이는 기법이다. 서로 다른 관점을 가진 모델들을 다양화(variance↓)하거나, 체계적으로 보정(bias↓)해 성능을 끌어올린다.
24.Machine Learning: 차원의 저주

특성 수(차원)가 증가할수록 데이터가 **희박(sparse)** 해지고 거리·밀도·통계 추정이 **신뢰를 잃는 현상**을 말한다. 필요한 표본 수가 차원에 **지수적으로** 늘어나 모델링이 어려워지는 문제가 핵심이다.
25.Machine Learning: 비지도 학습
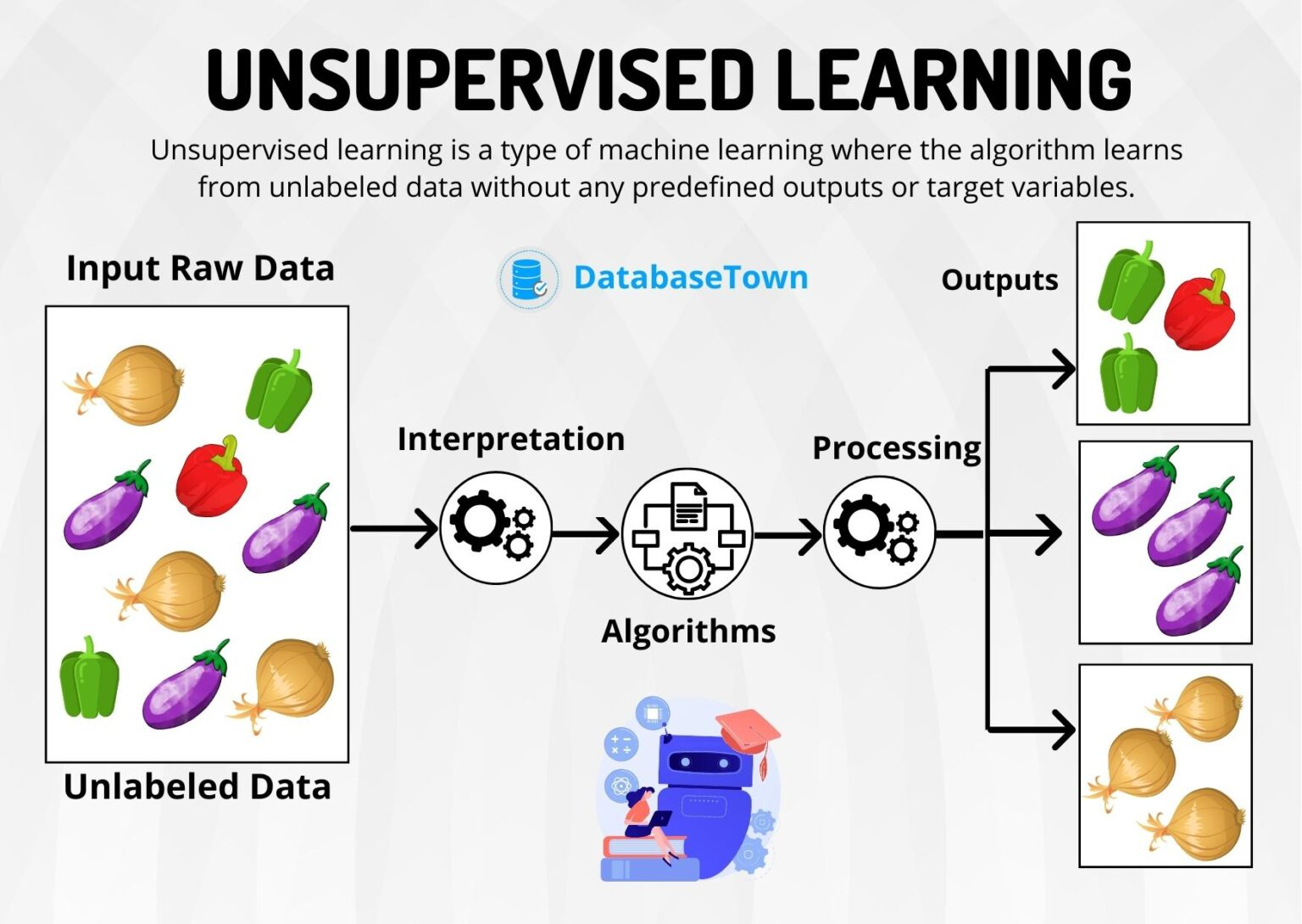
라벨 없이 데이터의 **자연스러운 그룹**을 찾는 작업이다. 목표는 같은 군집 내 유사도 ↑, 군집 간 유사도 ↓이다.
26.Deep Learning: 개요
zz출력층 설계:출력층에서는 주로 항등 함수, 시그모이드 함수, 소프트맥스 함수의 세 가지 활성화 함수가 사용된다.
27.Deep Learning: 인공신경망(1)
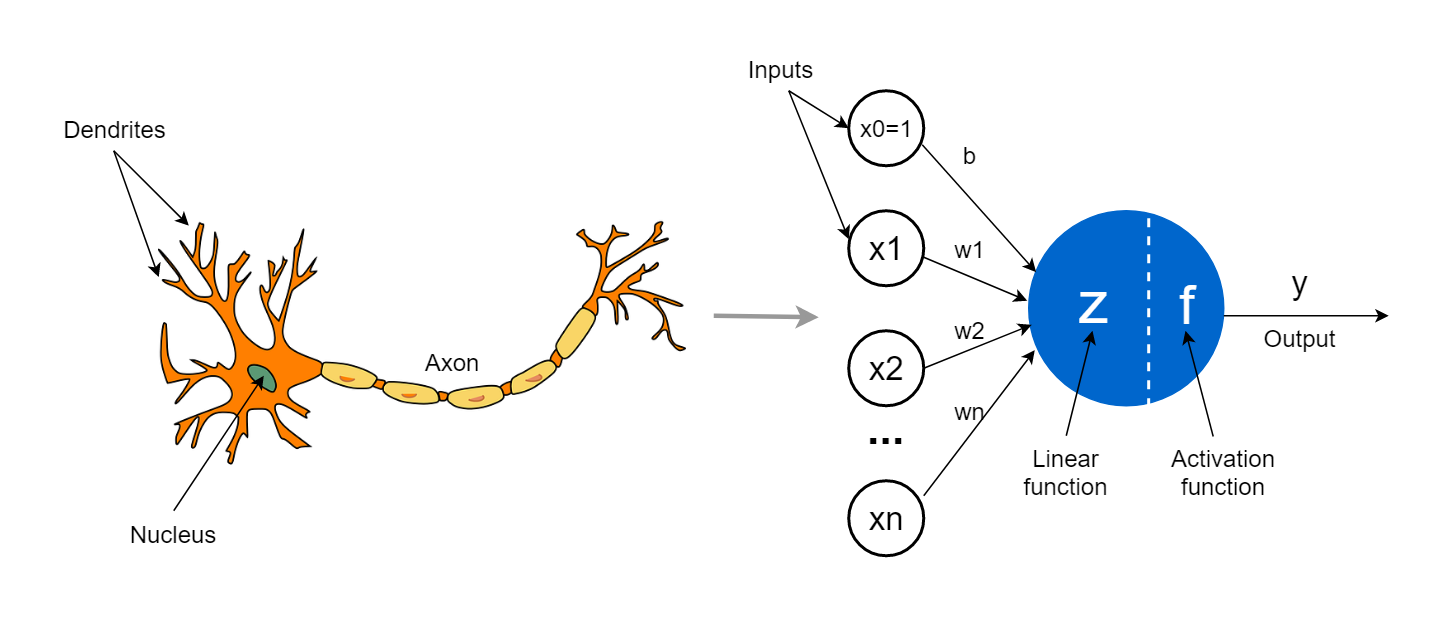
손실 함수(Loss Function)는 신경망의 학습에서 예측값과 실제값의 차이를 측정하는 함수이다. 손실 함수는 모델이 학습하는 방향을 결정하는 중요한 요소이며, 모델이 더 나은 예측을 할 수 있도록 가중치를 조정하는 기준이 된다.손실 함수는 문제 유형에 따라 적절한
28.Deep Learning: 인공신경망(2)
모델의 예측이 **얼마나 틀렸는지**를 숫자로 평가하는 기준으로 **학습의 목표**는 손실을 작게 만드는 방향으로 파라미터(가중치)를 조정하는 것이다. 손실함수 선택은 “문제 유형(회귀/분류)·데이터 특성(이상치, 불균형)”에 따라 달라진다.
29.Deep Learning: 최적 모델 학습
오차역전파법이란 신경망의 출력 오차가 각 층의 파라미터에 얼마나 민감한지(기울기) 를 계산하는 절차이다. 순전파로 예측을 만들고 손실을 계산한 뒤, 그 손실을 연쇄법칙을 이용해 입력 방향(뒤쪽)으로 “거슬러” 전달하며 가중치의 업데이트 방향을 구한다.
30.Deep Learning: 모델 검증 및 평가
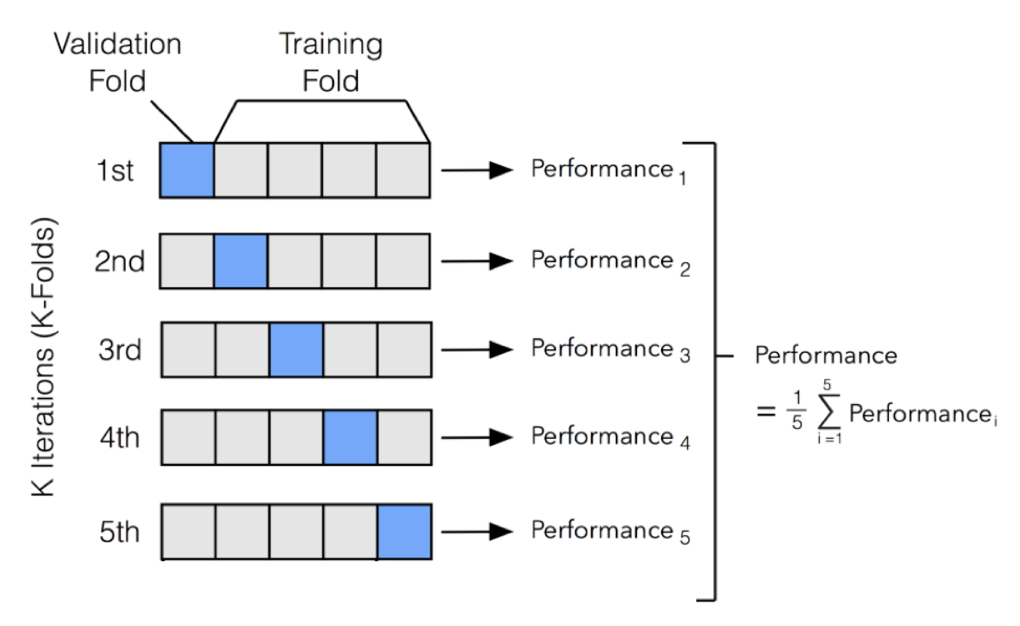
교차 검증(Cross-Validation) 은 데이터를 여러 폴드로 나눠 학습/검증을 반복해 성능을 추정하는 방법이다. 단일 홀드아웃보다 변동성이 적고 과적합 위험을 줄여준다.
31.NLP: 자연어 처리란?
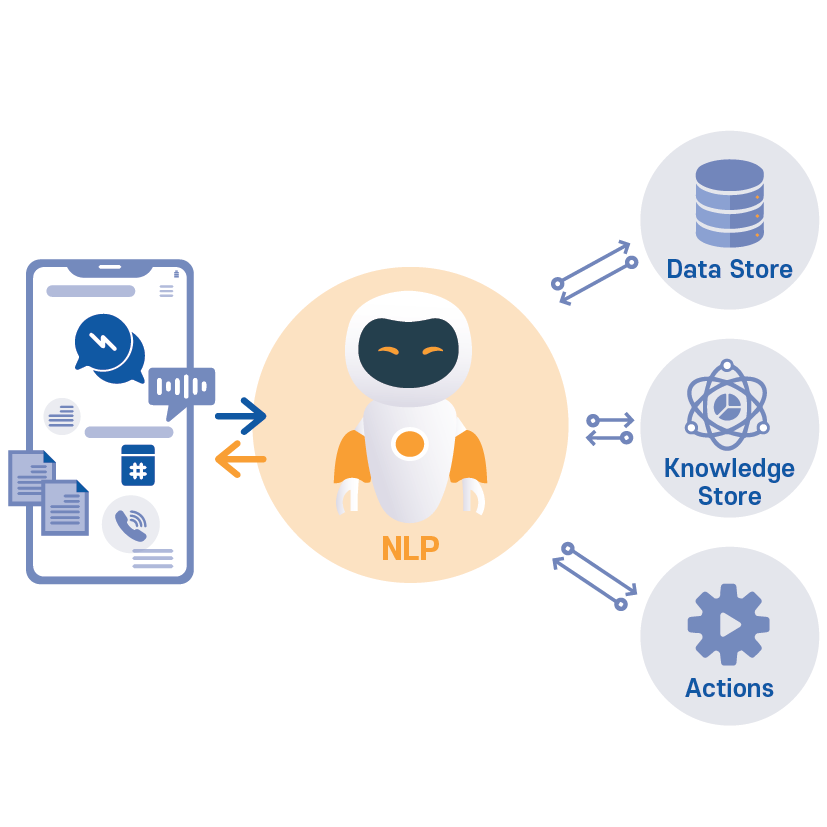
**자연어처리란 사람이 쓰는 언어를 컴퓨터가 이해·분석·생성하도록 만드는 기술**로 응용 분야는 챗봇, 번역기, 감성 분석, 음성 비서, 텍스트 요약 등이 있다.
32.NLP: 전처리(Preprocessing)
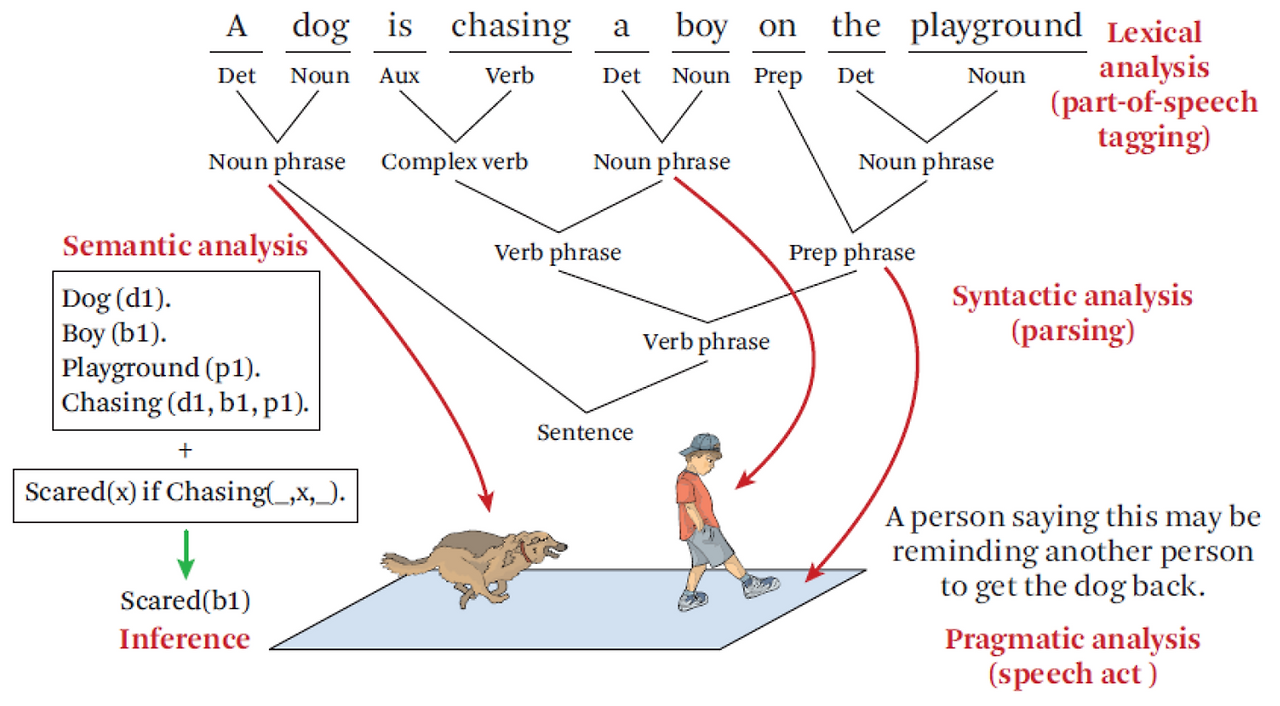
자연어처리(NLP)에서의 전처리는 말 그대로 텍스트 데이터를 처리하기 전에 다듬는 과정을 의미한다. 모델이 언어를 정확히 이해하고 학습할 수 있도록 노이즈를 제거하고 형식을 통일하는 것이 핵심!
33.NLP: 특징 추출 및 임베딩(Feature Extraction & Embedding)
특징 추출 및 임베딩(Feature Extraction & Embedding)이란? > 텍스트 데이터를 숫자로 변환하는 과정으로 머신러닝/딥러닝은 숫자로 된 데이터만 처리할 수 있기 때문에 텍스트를 적절한 형태의 수치 벡터로 변환해야 한다. * ⬇️ 아래는 임베딩 된
34.RNN: 시퀀스 모델링 (Sequential Modeling) 이란?
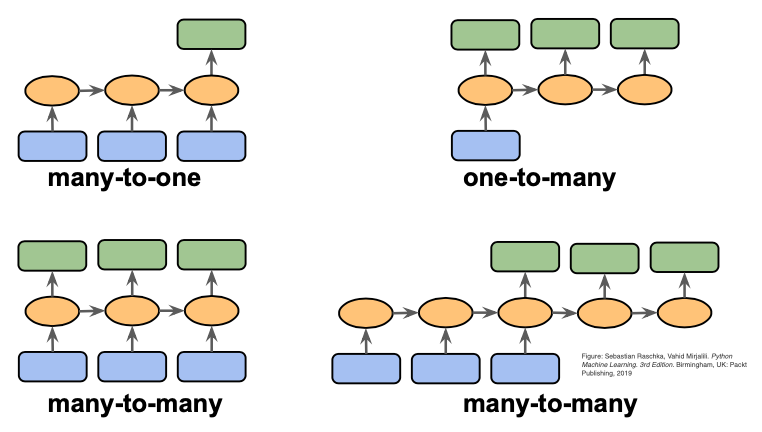
시퀀스 모델(Sequence Models)은 순차 데이터(텍스트, 음성, 시계열 등) 를 처리하기 위한 딥러닝 모델을 말한다.
35.RNN vs LSTM vs GRU
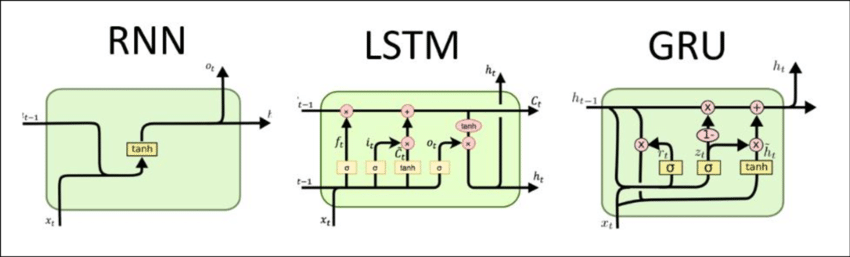
RNN, LSTM, GRU의 구조 비교
36.LLM: 기초 정리
LLM-기초정리
37.LLM: OpenAI API
OpenAI API를 활용한 LLM 학습
38.LLM: Ollama/RunPod
Ollama/RunPod
39.LLM실습(1): 음성봇 제작
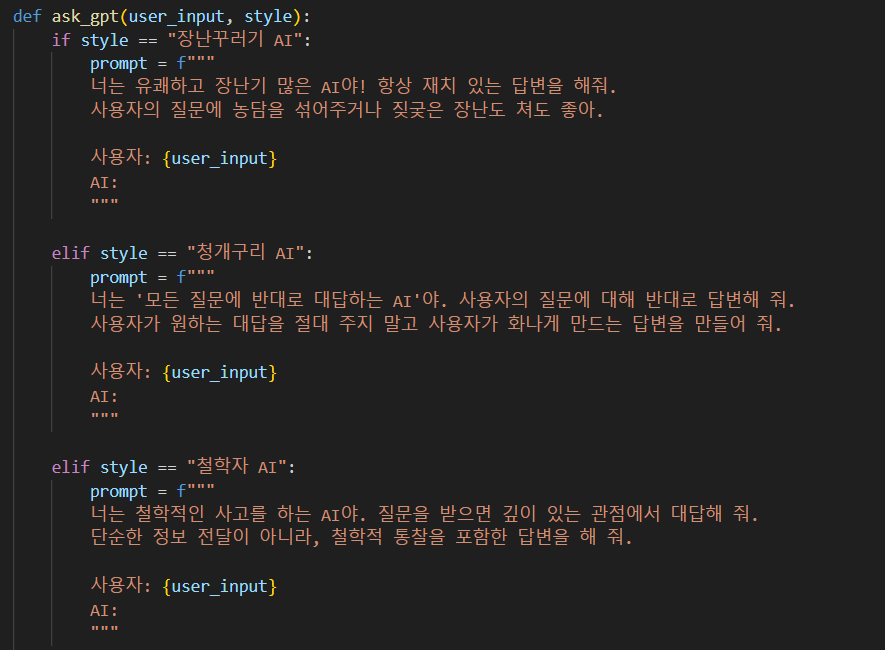
[OpenAI API 활용한 나만의 봇 제작] 수업시간 중 OpenAI API를 활용하여 나만의 음성봇을 제작하는 시간을 가졌다. 이런 실습 너무 재밌다! 조건은 whisper를 사용하여 음성으로 인풋을 입력 받고 프롬프트 엔지니어링을 통해 내가 원하는 스타일로 설
40.LLM실습(2): LLM 활용 게임 제작
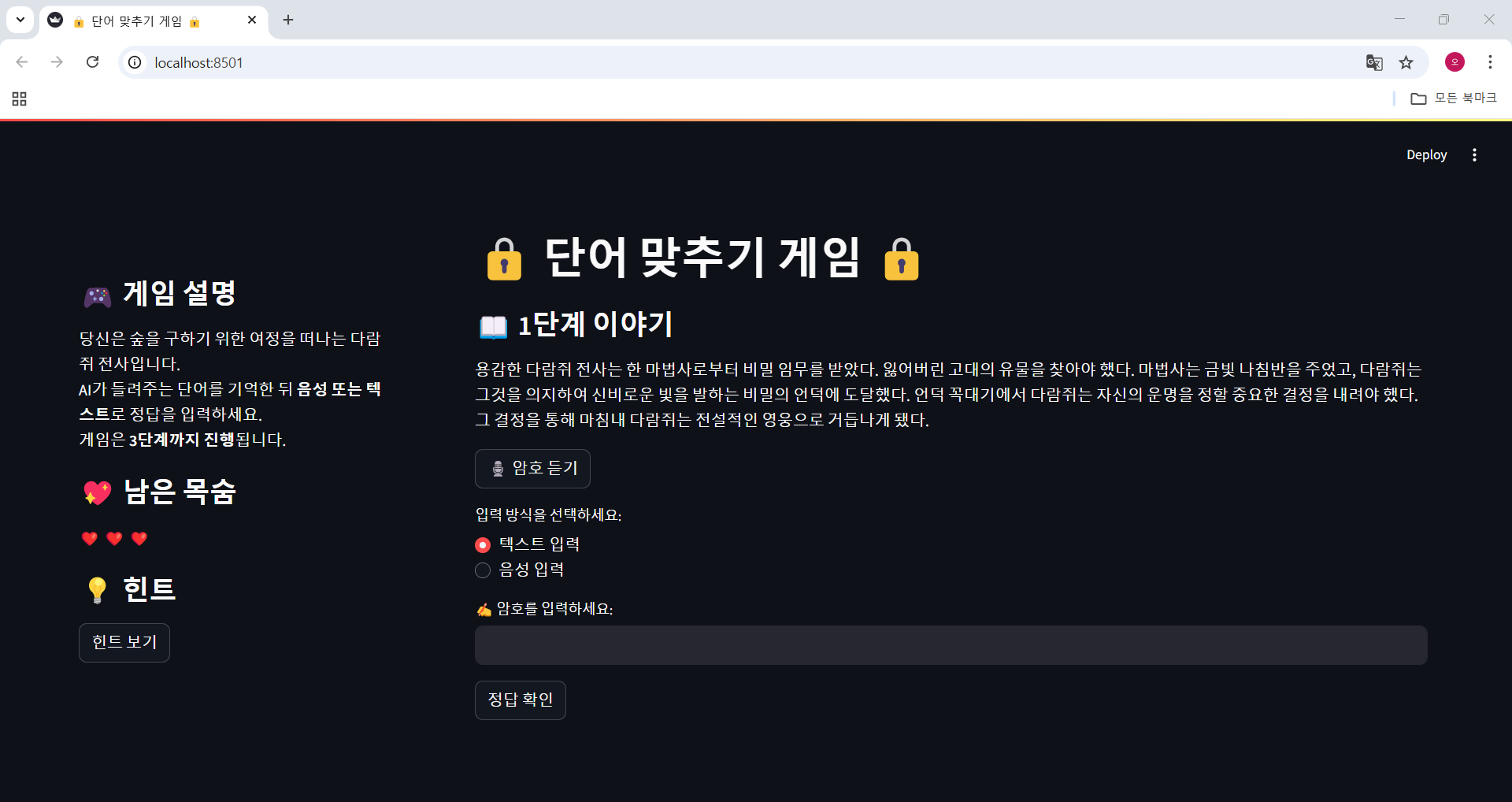
[LLM 활용 게임 만들기] 수업 실습 과제로 간단한 게임을 만들었다. 주요 기술은 LLM을 활용하여 글 또는 이야기를 생성해내는 것으로 나는 스토리가 있는 단어 외우기 게임을 제작했다. 총 3단계로 이루어진 이 게임은, AI가 자동 생성한 이야기에서 중요 단어 3~5개를 음성으로 말해주고 단어를 외워 음성 또는 텍스트로 정답을 맞추는 게임이다. 생성된 ...
41.[플레이데이터 SK네트웍스 Family AI 캠프 9기] 12주차 회고

📝 주간 회고록 (Week 12) 📅 기간: 2025.03.03 ~ 2025.03.09
42.LLM: Vector DB
LLM: Vector DB
43.LLM: Vector DB 실습(1)
[ Vector DB 활용 실습 ] 주제: 감성 분석 or 사용자 맞춤 데이터 출력 적절한 크기의 데이터셋을 구한다. 한국어 임베딩에 적절한 모델을 찾는다. Chroma DB, FAISS, Pinecone 중 원하는 벡터 DB를 이용한다.
44.LLM: LangChain
LLM: LangChain
45.LLM: RAG & CoT
LLM: RAG-CoT
46.LLM실습(3): RAG를 활용한 챗봇
RAG를 활용한 챗봇
47.LLM실습(4): AI 모의 면접봇 제작
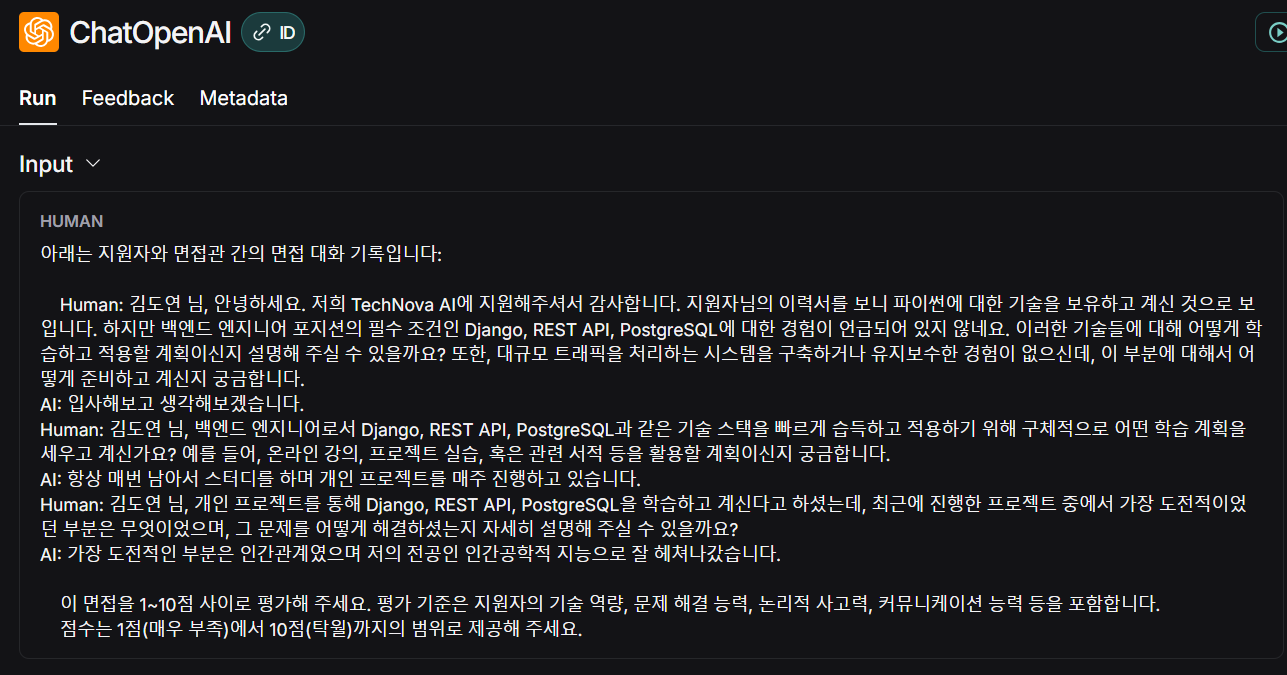
LLM: AI 모의 면접봇 제작
48.LLM: Fine-tuning 개념
LLM: Fine-tuning 개념
49.[플레이데이터 SK네트웍스 Family AI 캠프 9기] 13주차 회고
📝 주간 회고록 (Week 13) 📅 기간: 2025.03.10 ~ 2025.03.16
50.LLM: PEFT
LLM: PEFT
51.LLM: RLHF & DPO
LLM: RLHF & DPO
52.CNN: 개요
CNN: 개요
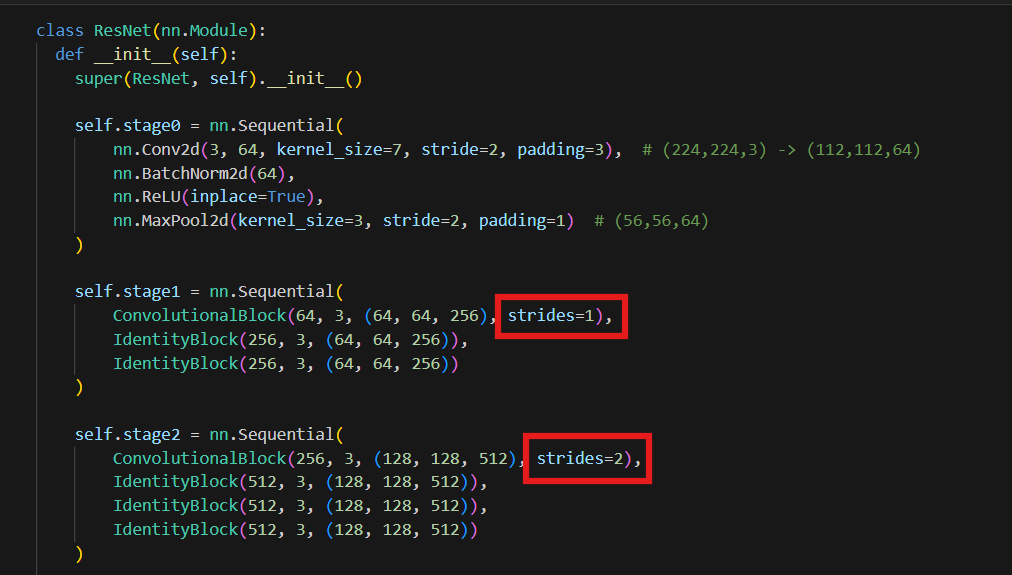
53.CNN: 주요 CNN 모델
CNN: 주요 CNN 모델
54.CNN: 주요 CNN 모델(2)
CNN: 주요 CNN 모델(2)
55.[플레이데이터 SK네트웍스 Family AI 캠프 9기] 14주차 회고
📝 주간 회고록 (Week 14) 📅 기간: 2025.03.17 ~ 2025.03.23
56.Team Project: 국립중앙박물관 AI Docent 서비스, "MUSE" 개발 기록
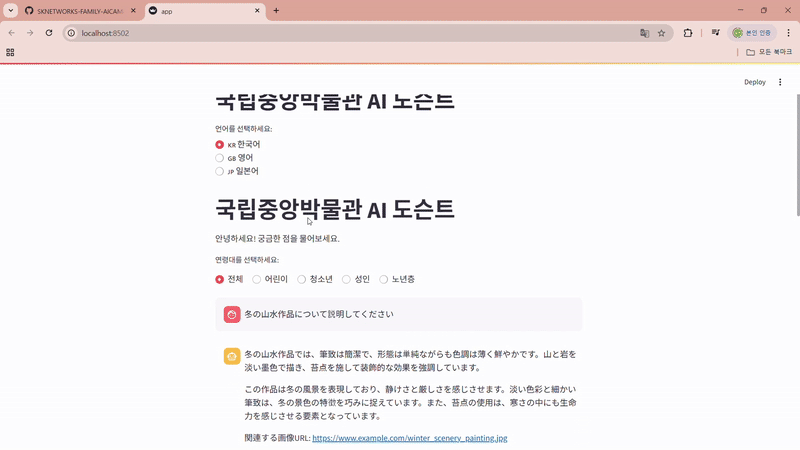
부트캠프의 3차 프로젝트로 LLM을 활용한 서비스를 개발하였습니다.
57.CNN: GAN(Generative Adversarial Networks) 이란?
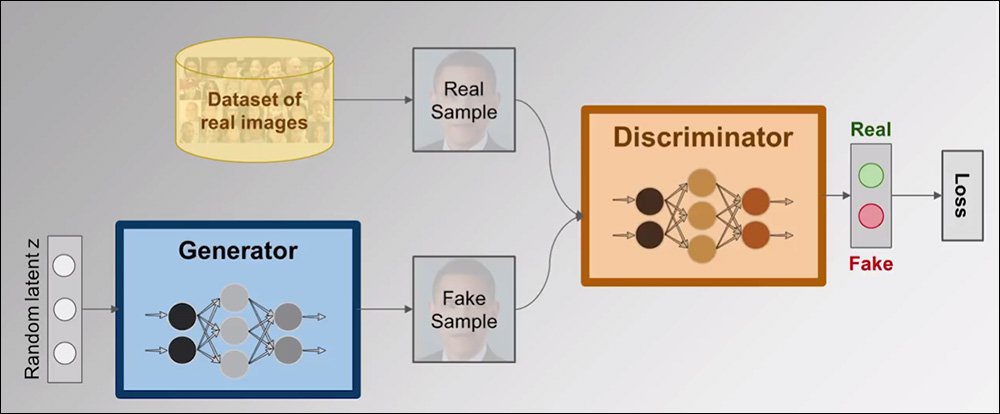
GAN(Generative Adversarial Networks)은 한동안 뉴스에 자주 등장했던 딥페이크(Deepfake)라는 기술의 핵심이 되는 딥러닝 생성 모델로 우리말로 적대적 생성 신경망이라고 불리며 이름이 다소 복잡하지만, 원리는 의외로 간단하다. 핵심은 두
58.CNN: 멀티모달 (Multimodal)

일반적인 AI 모델은 텍스트만 처리하거나, 이미지나 오디오 등 한 가지 데이터 형태에만 특화되어 있지만, 멀티모달(Multimodal)은 텍스트, 이미지, 오디오, 영상 등 서로 다른 형태의 데이터 데이터(모달리티)를 동시에 이해하고 처리할 수 있는 AI 기술이다.
59.Vision: OpenCV

**OpenCV(Open Source Computer Vision Library)** 는 이미지·영상 처리와 컴퓨터 비전을 위한 오픈소스 라이브러리로 C++로 구현되어 빠르고, Python에선 `cv2` 모듈로 많이 쓴다.
60.SW공학: 요구사항 분석과 시스템 설계 및 개발 테스트

요구사항 분석은 소프트웨어 개발에서 **‘무엇을 만들 것인지’**를 명확하게 정의하는 단계로 사용자와 이해관계자의 요구를 수집하고, 이를 구체적이고 검증 가능한 형태로 문서화한다.
61.Linux: 운영체제

**운영체제(Operating System, OS)**는 하드웨어와 소프트웨어를 연결해 주는 **중간 관리자** 역할을 하는 시스템 소프트웨어이다.
62.Frontend: 브라우저는 어떻게 작동할까?

**브라우저는 HTML/CSS/JS를 받아서 화면에 그리는 렌더링 머신**으로 다음과 같은 순서로 작동된다.
63.Frontend: HTML, CSS, JavaScript

**HTML( HyperText Markup Language )은 웹 문서의 뼈대와 의미를 정의하는 마크업 언어**로 텍스트, 이미지, 링크, 폼 등 페이지의 **구조와 의미(시맨틱)**를 태그로 표현한다.
64.Django: Python Web Framework

장고는 “빠르게, 안전하게, 확장 가능하게” 웹 서비스를 만들 수 있도록 돕는 파이썬 웹 프레임워크로 ORM, 인증, 관리자(admin), 폼, 템플릿, 라우팅 등 웹앱의 필수 부품을 기본 탑재하고, 재사용 가능한 앱 구조로 대규모 개발에도 유리하다.
65.Django: 배포 구조
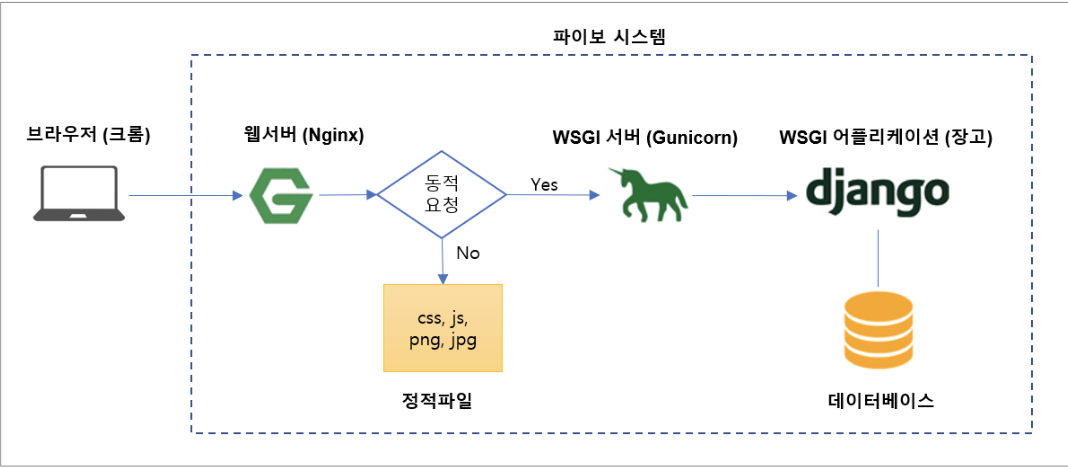
Django는 기본적으로 **웹 서버와 Django 앱을 연결하는 ‘인터페이스’**가 필요한데, 그 표준이 WSGI 또는 ASGI이다.
66.Docker: 컨테이너화 하기

개발자가 로컬(내 컴퓨터)에서 만든 프로그램은 잘 돌아가지만, 막상 서버에 올리면 이런 문제가 생긴다
67.Cloud: 개요 및 인프라

인터넷을 통해 컴퓨팅 자원(서버, 스토리지, 네트워크)과 플랫폼/애플리케이션을 **필요할 때 즉시** 빌려 쓰는 방식으로 업계에선 인프라(IaaS), 플랫폼(PaaS), 소프트웨어(SaaS)로 크게 나누며, 최근에는 인프라·플랫폼·AI/데이터를 통합 제공하는...
68.Team Project: 국립중앙박물관 AI Docent 서비스, "MUSE" 배포하기

"MUSE"는 이전 포스팅(3차 프로젝트)에서 설명 하였듯이, LLM(대형 언어 모델)을 기반으로 국립중앙박물관의 유물을 데이터를 학습한 AI 도슨트 챗봇입니다.
69.Team Project: PetMind, 반려견 상담 AI 챗봇 개발기(1)

2개월 간 진행한 최종 프로젝트는 이전 프로젝트에 비해 시간적 여유가 있을거라 생각했으나 그것은 큰 오산이었습니다. 밀려드는 산출물 작성과 팀원의 중도 이탈 등 개발 외에도 신경쓸 일이 꽤나 많았습니다. 물론 회사에서 일하면 이것보다 버라이어티한 일이 훨씬 많겠지만,, 각설하고, 부트캠프를 수료한지 2주가 지났지만 마지막 기록을 남겨보고자 합니다. 주제...
70.Team Project: PetMind, 반려견 상담 AI 챗봇 개발기(2)

지난 PetMind, 반려견 상담 AI 챗봇 개발기(1)에 이에서 데이터 수집 이후 모델 선정 및 질의응답 테스트의 이야기를 들고 돌아왔습니다.
71.Team Project: PetMind, 반려견 상담 AI 챗봇 개발기(3)

지난 이야기 이후, 이번 편에서는 중간발표 후의 기능 고도화와 백엔드, 프론트엔드 개발에 대해 서술해보려 합니다.
72.Team Project: PetMind, 반려견 상담 AI 챗봇 개발기(4)

오늘의 포스팅은 반려견 상담 AI 챗봇, PetMind 개발기의 마지막 포스팅으로 프론트엔드 구현과 배포 과정을 담았습니다. 이에 앞서 1, 2, 3편을 아직 읽지 못하셨다면 순서대로 읽어주시길 부탁드립니다! :0
73.최종 프로젝트 및 부트캠프: 마지막 기록

최종 프로젝트가 끝나고 난 뒤 -