부트캠프의 3차 프로젝트로 LLM을 활용한 서비스를 개발하였습니다.
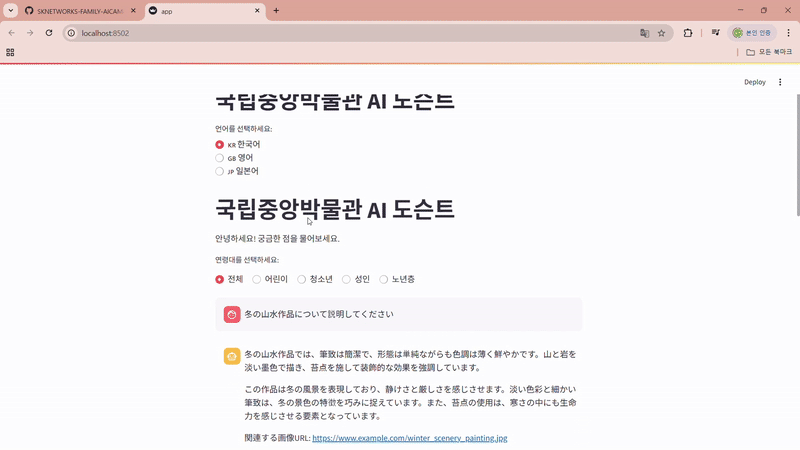
저희 팀의 주제는 국립중앙박물관의 다국어 AI 도슨트 서비스인데요,
지난 몇 년간 외국인 관광객이 계속해서 늘어나는 추세이고, 그 중 국립중앙박물관은 필수 관광지 중 한 곳으로 선정될 만큼 관광지로써의 인기가 상당합니다. 하지만 현재 국립중앙박물관에는 AI 도슨트 서비스가 없어 국내/외 방문객의 편의를 돕고자 개발하게 되었습니다.
프로젝트의 목표는..
- 전시품 설명에 특화된 질의응답형 챗봇 서비스 개발
- 다국어 지원을 통한 관람객 접근성 및 경험 향상
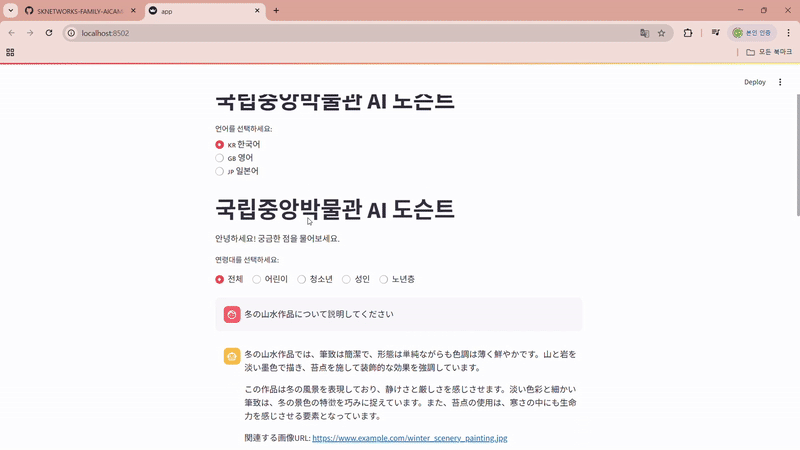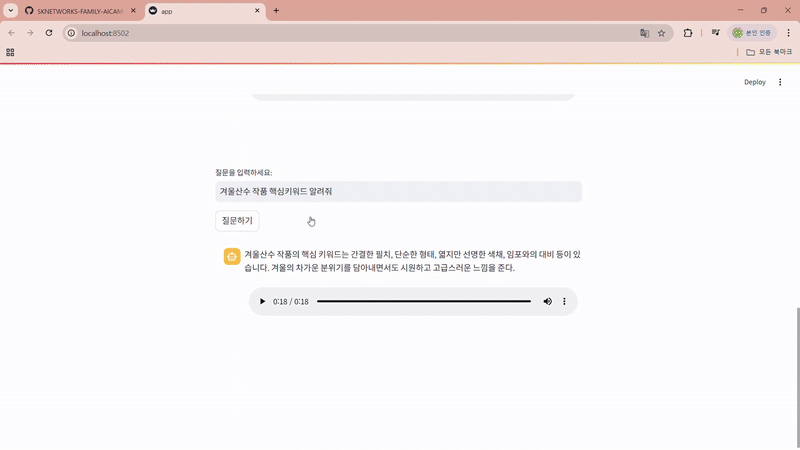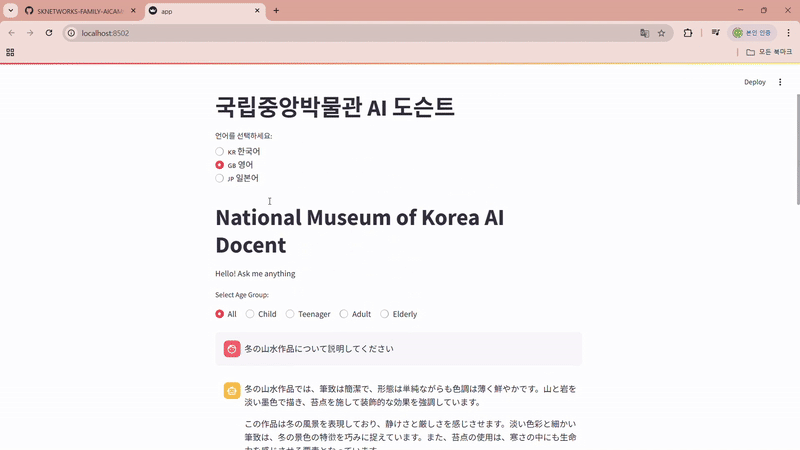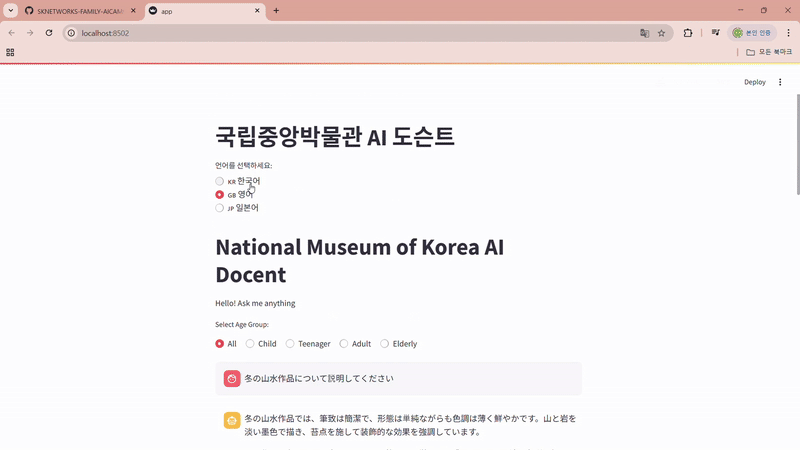
- 음성 기반의 전시품 설명 기능 제공
- 자연어 처리 기반의 연령 맞춤형 콘텐츠 제공
프로젝트는 다음과 같이 진행했어요,
1. 데이터 수집 및 전처리
- 데이터는 국립중앙박물관에 API를 요청하여 수집하였습니다.
- "박물관"의 특성상
한자/외국어/특수문자등이 많아 한글과 숫자 외에 문맥의 이해도를 저해하는 문자는 모두 제거하였습니다.
2. LLM 모델 비교
베이스 모델로 llama3.2와 qwen2.5를 선택하였고, 두 모델에 같은 데이터셋으로 파인튜닝 후, 동일한 파라미터를 적용하여 응답을 비교하였고, 최종적으로 qwen2.5 모델을 선정하였습니다.
3. 문장 단위 Chunking
벡터 DB 구축 시, 초기에는 유물의 전체 설명을 하나의 문서로 데이터를 저장하였지만, 문서 단위가 너무 길어져서 검색 정확도가 저하되는 문제가 있었습니다. 이를 해결하기 위해, 아래 사진과 같이 설명을 문장 단위로 청킹하고 하나의 유물에 대해 "유물 - 설명1", "유물 - 설명2" 형식으로 재구성 하였습니다.

4. RAG용 데이터 추가 전처리
문맥 이해도 및 정보 손실 최소화를 위하여 불필요한 특수문자만 최소한으로 제거하고 의미 있는 한자와 괄호 등은 유지한 형태로 데이터를 재구성 한 뒤, 두 데이터셋을 비교하였고, 후자를 사용했을 때, 질문과 관련된 정보 검색도가 눈에 띄게 향상 되었습니다.
5. 외부 지식 검색 (Wikipedia)
실제 사용자가 질의하는 내용 중 내부 문서에 존재하지 않는 작품이나 정보도 빈번히 발생할 수 있음을 고려하여, 외부 지식 검색 agent를 구성하였습니다.
6. 임베딩 모델 변경
처음에는 박물관 데이터의 특성상 한국어에 대한 이해도가 높은 모델이 요구되어 서울대에서 만든 snunlp/KR-SBERT-V40K-klueNLI-augSTS 모델을 사용하였습니다.
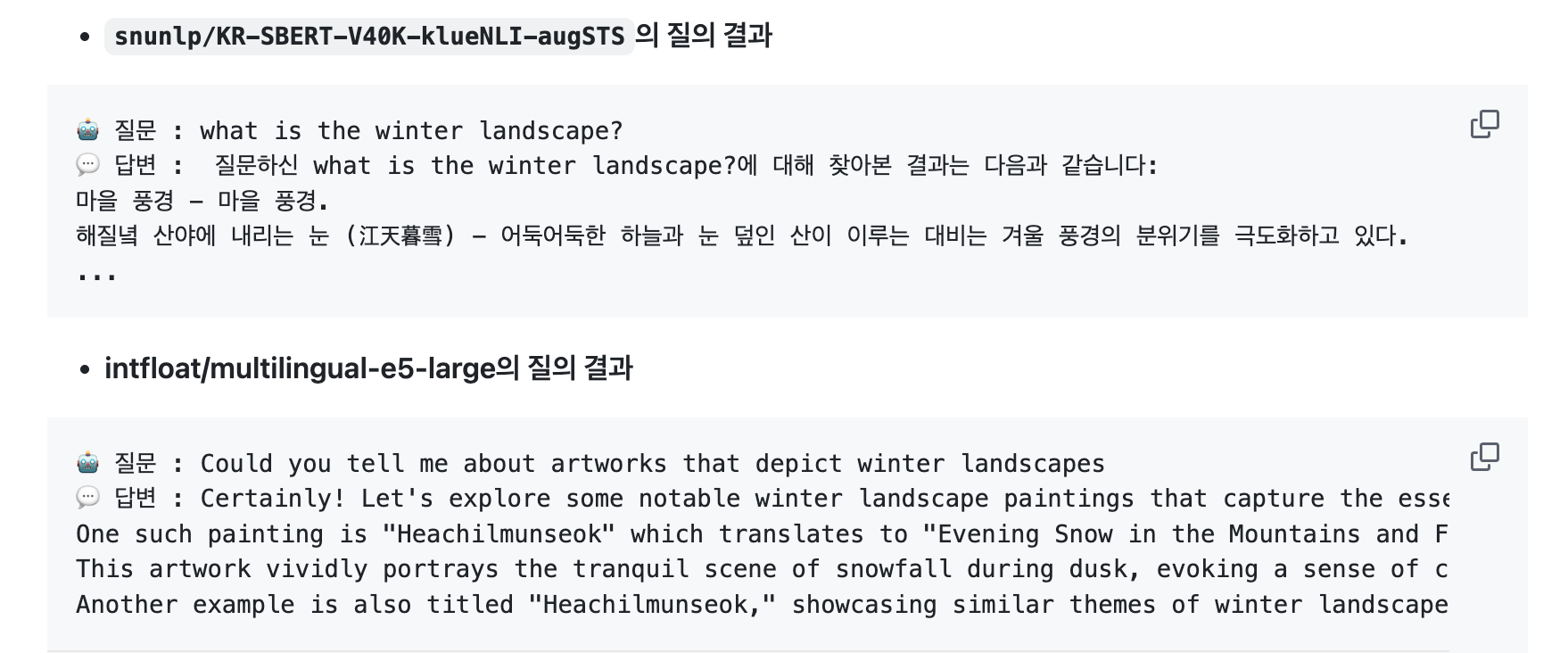
그러나 테스트 결과, 다국어 질의에 대한 응답 정확도가 낮다는 한계가 있었고, 이에 따라 한국어 이해도는 충분하면서도 다국어를 폭넓게 지원하는 intfloat/multilingual-e5-large로 비교/변경하였습니다.
7. 시스템 프롬프트 개선
임베딩 모델을 변경한 후에도 다국어 질문에 대해 입력값과 출력값의 언어가 매칭되지 않는 경우가 발생하는 등의 문제를 개선하기 위해 수차례 시스템 프롬프트를 변경하였습니다.
주요 변경사항:
- 한/영/일 시스템 프롬프트 분리 적용: 입력 언어를 자동으로 감지하여 해당 언어로 자연스럽게 응답할 수 있도록 설계함.
- 출처 기반 응답: 불확실하거나 내부 문서에 존재하지 않는 정보에 대해서는 '정보를 드릴 수 없습니다' 등의 표현으로 정직하게 응답하도록 설정함.
- 문장 중복 출력 방지: 동일한 문장이 반복되지 않도록 프롬프트 내 중복 방지 조건을 반영함.
- 할루시네이션 개선: 허구의 정보를 생성하지 않도록 응답 규칙을 강화하고, 실제 근거 기반으로 답변하도록 유도함.
- 연령별 설명 테마 강화: 연령대별 이해 수준과 언어 스타일을 고려한 맞춤형 설명 기능을 구현하기 위해 사용자 연령대(예: 아동/청소년/성인)에 따른 맞춤형 프롬프트를 작성함.
8. 그 밖에..
- 모델 응답에 관한 파라미터인
top_p, temperature,max_new_token와 문서 검색시 유사도 임계값인SIMILARITY_THRESHOLD를 조정하여 최적의 파라미터 값으로 세팅하였습니다. - 추가적으로 응답의 정확도 향상을 위하여
beam_search와Re-ranking을 시도하였으나 오히려 문서 검색 성능이 저하되어 기존 세팅 유지하였습니다.
느낌점 및 개선점
이번 프로젝트를 통해 프롬프트 엔지니어링은 간단하지만 강력한 LLM 사용 방법이란 것을 다시금 깨달았다. 그리고 여러 모델을 비교하는 과정에서 모델별 구조가 다르다는 것을 배울 수 있었다. 또한, 런팟에 모델을 올려 질의를 하는 과정에서 패키지 호환 문제가 계속 발생해서 팀원들이 큰 스트레스를 받았었는데, 이런 과정들을 통해 가상환경과 패키지 버젼 일치에 대한 중요성을 또 한 번 배우게 되었다. 그 외 우리는 프로젝트의 개선점에 대해서도 정리해보았다.
-
외국어 데이터셋 구축
현재 모델은 다국어 임베딩 모델과 다국어 시스템 프롬프트로 외국어 질의에 자연스럽게 응답할 수는 있으나, 외국어로 입력된 질문이 벡터 DB 내 한글 기반 문서와 완벽히 매칭되지 않는 문제가 존재합니다. 이를 해결하기 위해, OpenAI API를 활용하여 외국어 번역 데이터셋을 추가하는 등의 방법으로 외국어 응답을 개선하려 합니다. -
유물 데이터 추가 확보
현재 유물 데이터는 약 7,000건 수준으로, 특정 질의에 대해 정보가 누락되는 경우가 발생합니다. 이를 보완하기 위해 전국 박물관 데이터를 추가 수집하고,
RAG 성능 향상을 위한 문서 다양성과 양적 확장을 지속적으로 추진할 예정입니다. -
이미지 추가 제공
현재 시스템은 작품 설명과 함께 이미지 URL을 제공하지만, 유효하지 않은 URL을 포함하는 사례가 반복적으로 발생하여, 향후에는 작품 이미지가 설명과 함께 페이지 상에 바로 시각화되도록 개선할 예정입니다.
아래 영상을 클릭하시면 해당 프로젝트 GitHub로 이동합니다.
많은 피드백 부탁드립니다!! ⬇️⬇️⬇️
