
감성 분석 시각화 드가보자~~
⚠️ 지난편에 이어서 진행되는 편이기에 지난 코드들이 다 선행되어있어야 한다!
히스토그램
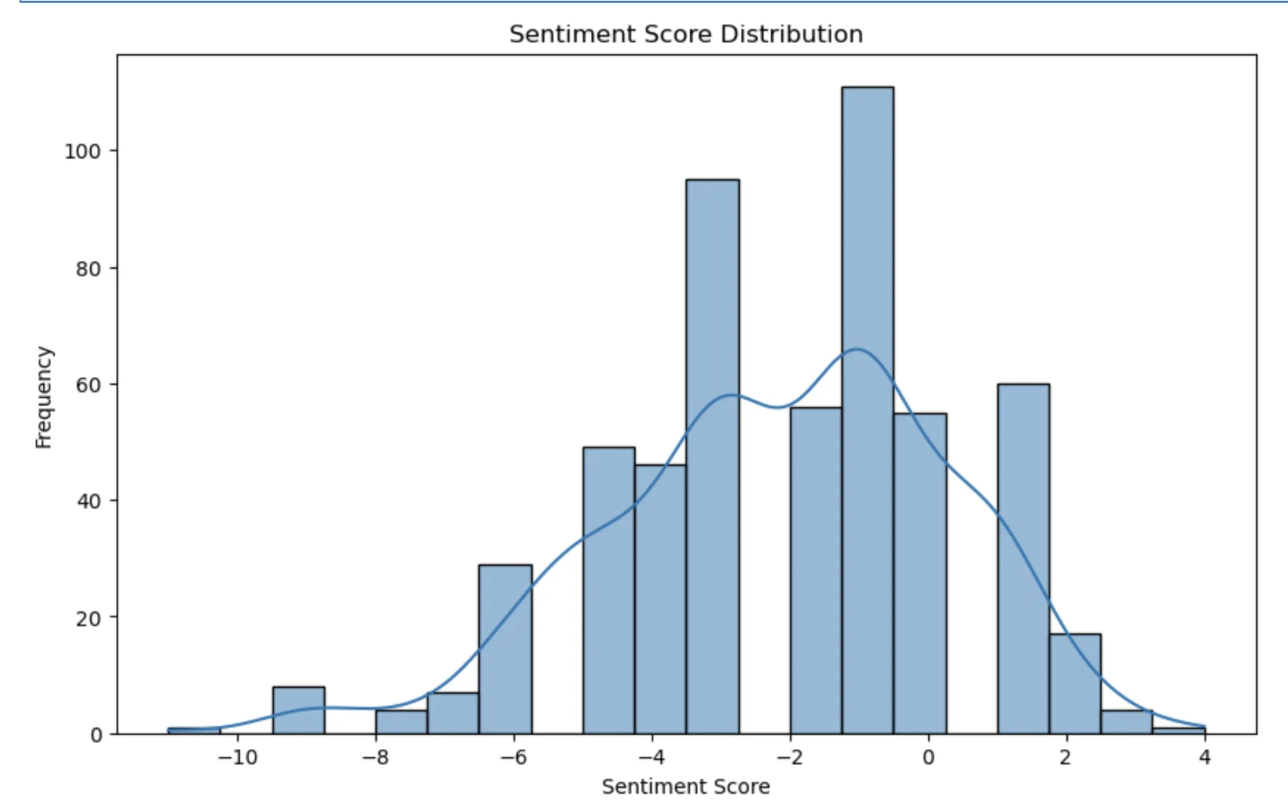
우선, 히스토그램으로 나타내보겠다!
matplotlib.pyplot과 seaborn 라이브러리를 사용해 줄 것이다.
matplotlib.pyplot 라이브러리는 python에서 흔하게 쓰이는 시각화 라이브러리로 간단한 데이터 시각화와 커스터마이징이 가능하다.
seaborn 라이브러리는 matplotlib를 기반으로 하는 데이터 시각화 라이브러리다. Matplotlib보다 더 보기 좋은 스타일로 꾸며준다.
코드는 다음과 같다.
import matplotlib.pyplot as plt
import seaborn as sns
# 새로운 그림(figure) 객체를 생성하고, 가로 10인치, 세로 6인치 크기로 설정
plt.figure(figSize = (10, 6))
# 히스토그램(seaborn의 histplot) 생성
# 데이터 프레임의 sentiment 열을 데이터로 사용
# bins=20은 히스토그램을 20개의 구간으로 나누어 표시, kde=True는 데이터 분포를 부드럽게 시각화
sns.histplot(df['sentiment'], bins=20, kde=True)
# 그래프 제목 생성
plt.title('Sentiment Score Distribution')
# x축 라벨 설정
plt.xlabel('Sentiment Score')
# y축 라벨 설정
plt.ylabel('Frequency')
plt.show()그럼 결과가 이렇게 나온다.
워드클라우드
워드 클라우드 형식으로도 시각화해보자!
!pip install WordCloud 를 먼저 수행해주어야 한다.
워드 클라우드를 생성하기 위해 우선, 글자 수 2개 이상인 것만 추출해준다.
글자 수 2개 이상만 추출
# 시각화 가보자고 ~~
tokenized_tex = [mecab.morphs(token) for token in tokens] # mecab을 이용해 재토큰화
total_token = [token for word in tokenized_tex for token in word if len(token) > 1 ] # 글자수 2개 이상만 추출전 게시물에서 정의해주었던 tokens를 이용해준다.
tokens에는 1차원 배열로 바뀐 형태소 형태의 기사 본문이 들어있다.
유의미한 워드클라우드 시각화를 위해 글자수 2개 이상만 추출한다. 아무래도 형태소로 분리하기 때문에 1개의 글자수도 포함하면 의미없는 조사 등이 많이 추출될 수 있기 때문이다.
빈도수 계산
워드클라우드는 빈도수에 따라 글자 크기가 달라지기에 글자의 빈도수를 계산해 줄 필요가 있다. 이를 위해 Counter() 함수를 사용한다.
from collections import Counter
# 토큰화된 형태소의 빈도수 계산
token_counter = Counter(total_token)
# 단어와 빈도수를 딕셔너리 자료료 바꾸서 key(단어)과 values(빈도수)를 데이터프레임으로 저장
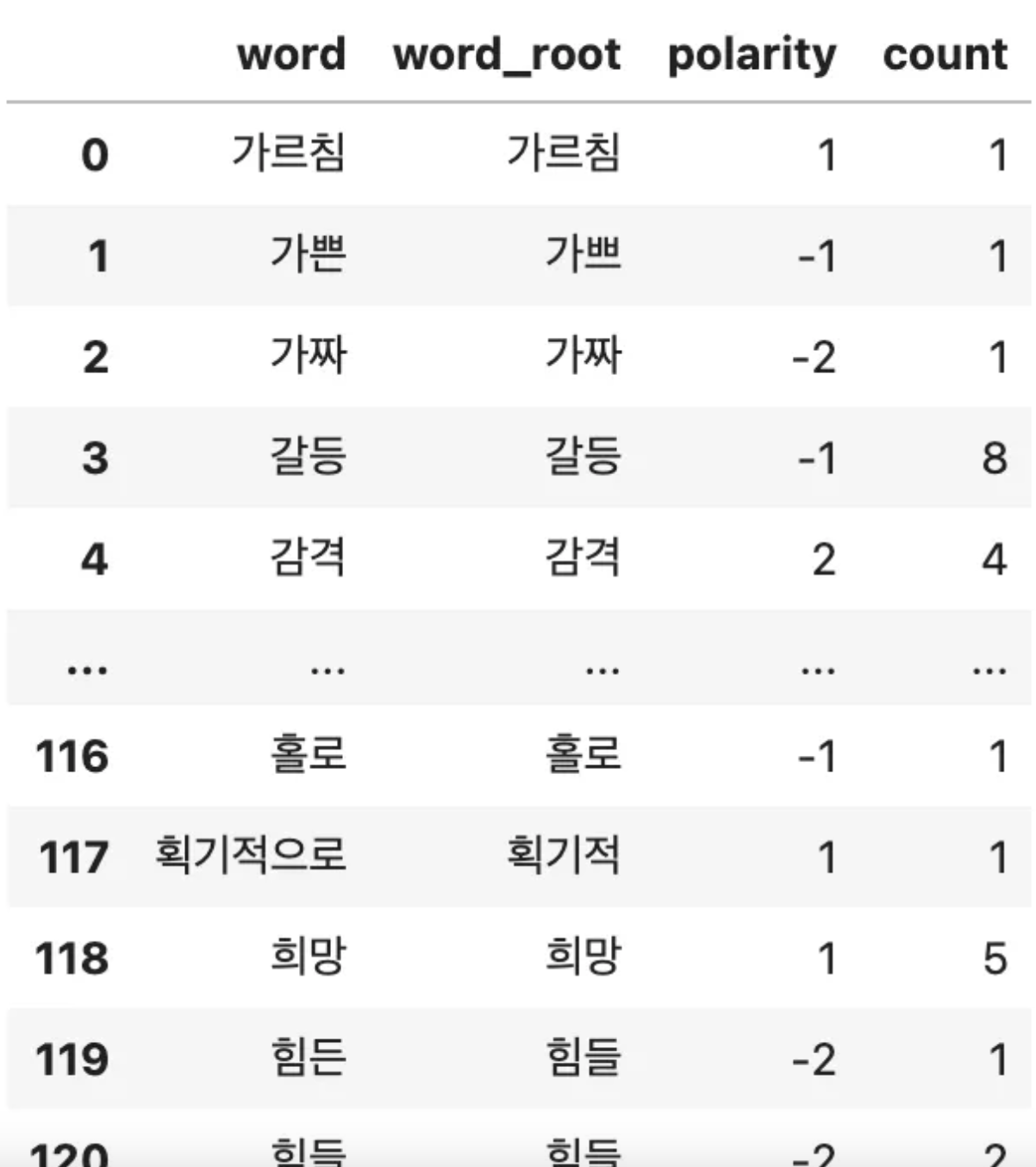
count_tokens = pd.DataFrame(dict(token_counter).items(),columns=['word','count'])
count_tokens그럼 이렇게 한 눈에 보기 편하게 나온다!

이렇게 토큰화된 단어와 빈도수를 계산했다면 이제 각각의 단어를 감성 사전에 포함되어 있는 단어와 매칭 작업을 해야 한다.
⚠️ 이 역시 이전 글에서 knu 감성 사전을 다운받아 데이터 프레임 형태로 만든 상태(sentiword_dic으로 정의했었다!)를 전제로 진행한다!
이전에 만든 감성 사전 데이터프레임(sentiword_dic)을 왼쪽에, 단어 빈도수 데이터프레임(count_tokens)를 오른쪽에 합쳐서(merge) 데이터프레임을 만들면 자동으로 단어 매칭이 된다.
이때 how='inner'는 양쪽 모두에 공통으로, on = 'word'는 단어만을 의미한다.
즉, 감성 사전 데이터프레임과 단어 빈도수 데이터프레임을 합칠 때 서로 겹치는 단어만 필터링해서 새로운 데이터프레임(sentword_df)을 만드는 것이다.
sentword_df = pd.merge(left=sentiword_dic, right=count_tokens, how='inner',on='word')
sentword_df그럼 이런 결과가 나온다.
폰트 설정
이제 폰트 설정과 한글 설정이 필요하다
한글 워드 클라우드를 생성하기 위해서는 한글 폰트 설치가 필요하다. 만약 있다면 해당 폰트 경로로 작성해주면 된다.
import matplotlib as mpl
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
a
# 높은 해상도로 폰트 주변이 흐릿하게 보이는 것을 방지
%config InlineBackend.figure_format = 'retina'
# 폰트 설정 필요함 (안해주면 네모네모병에 걸림)
fontpath = '폰트 경로작성'
font_name = fm.FontProperties(fname=fontpath, size=10).get_name()
# matplotlib가 사용할 글꼴 변경
plt.rc('font', family=font_name)색상 설정도 해준다.
import matplotlib as mpl
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
color_to_words = {
'orange': list(sentword_df.loc[sentword_df.senti_cat == "부정", "word"]),
'navy': list(sentword_df.loc[sentword_df.senti_cat == "긍정", "word"])}
default_color = "grey"
class simpleGroupedColorFunc(object):
def __init__(self, color_to_words, default_color):
self.word_to_color = {word: color
for (color, words) in color_to_words.items()
for word in words}
self.default_color = default_color
def __call__(self,word, **kwargs):
return self.word_to_color.get(word, self.default_color)
세부 설정까지 해주고 나면
import matplotlib.pyplot as plt
from wordcloud import WordCloud
simple_color_func = simpleGroupedColorFunc(color_to_words, default_color)
wc = WordCloud(font_path='/Users/ohchanju/workspace/LINENOW-Web/src/assets/fonts/Pretendard-Medium.ttf', scale=2.0, max_font_size=250, color_func = simple_color_func,
background_color="white").generate_from_frequencies(token_counter)
plt.figure(figsize = (16, 16))
plt.imshow(wc)
plt.axis("off")
짜잔 이런 결과가 나온다!
이렇게 워드클라우드로도 만들 수 있다.
참고 문헌
