
이제 다운받은 모듈 등을 확인해 감성 분석 코드를 짜볼 차례인데
우선 내가 감성 분석을 진행할 엑셀 파일은 다음과 같은 열을 가지고 있다.

여기서 나는 기사 본문을 감성 분석하고 싶었다.
해당 기사의 감정적인 톤을 알고 싶었기에 ! 하지만 빅카인즈에서 다운 받은 엑셀은 기사 본문 전체가 나와있지 않고

일정 글자수 이후에는 ...으로 찍혀져있었다.
다행히 해당 기사의 URL을 같이 제공해주기에
URL을 타고 들어가서 본문 기사 전체를 크롤링하면 되겠다 !!
라는 생각을 하게 되었다.
여기서 필요한건 Python의 Selenium 패키지다.
selenium 패키지는 chromedriver를 제어하거나 원하는 정보를 얻기 위해 사용한다.
Selenium 4버전 이상에서는 크롬 드라이버를 따로 설치하지 않아도 된다고 되어있지만 ... 그걸 몰랐던 나는 다운받았다 ㅎㅅㅎ
크롬 버전을 확인 후 다운 받으면 된다.
https://developer.chrome.com/docs/chromedriver/downloads?hl=ko
크롬 버전 확인은 크롬브라우저 창 오른쪽 맨 끝 점 세 개 → 도움말 → Chrome 정보에 들어가서 확인할 수 있다
이제 파이썬 환경에 필요한 패키지를 설치해준다.
!pip install selenium관련 모듈 import
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
import time
import pandas as pdchrome 드라이버 설정
# 다운 받은 크롬 드라이버 경로 입력
chrome_driver_path = '/Users/ohchanju/Desktop/chromedriver/chromedriver'
chrome_options = Options()
chrome_options.page_load_strategy = 'eager' # 필요한 요소만 빠르게 로드
chrome_options.add_argument("--no-sandbox") # 샌드박스 모드 해제 (속도 향상)
service = Service(executable_path=chrome_driver_path)
# 크롬 드라이버 생성
driver = webdriver.Chrome(service=service, options=chrome_options)
# 파일 불러오기
df = pd.read_excel('/Users/ohchanju/Desktop/data/nursing.xlsx')
# 기사 본문을 담을 배열 생성해주기
article_texts = []
크롤링 설정
for url in df['URL']:
article_text = "본문을 찾을 수 없음" # 기본값 설정
try:
driver.get(url)
# 페이지 로딩이 완료될 때까지 기다리는 코드 (10초 설정)
time.sleep(10) # 페이지 로딩 대기
만약 chrome driver가 본문을 찾을 수 없는 경우, 추후 에러가 뜨기에 기본값을 설정해준다.
time.sleep(10)은 페이지 로딩이 완료될 때까지 기다리는 코드인데, 로딩이 생각보다 길어져 10초로 설정했다. 이는 편한대로 조절하면 된다. 대부분 3초로 하는 것 같기는 하다.
신문사별 크롤링 설정
신문사별로 어느 부분이 기사 본문인지 다르다. 컴퓨터는 이를 알아볼 수 없고 코드로 알려주어야 한다.
중앙일보로 예를 들어보겠다.
아무 기사나 하나 들어간 후 개발자 도구를 켠다. 그리고 본문에 커서를 가져다대면 어느 부분인지 뜨게 되는데
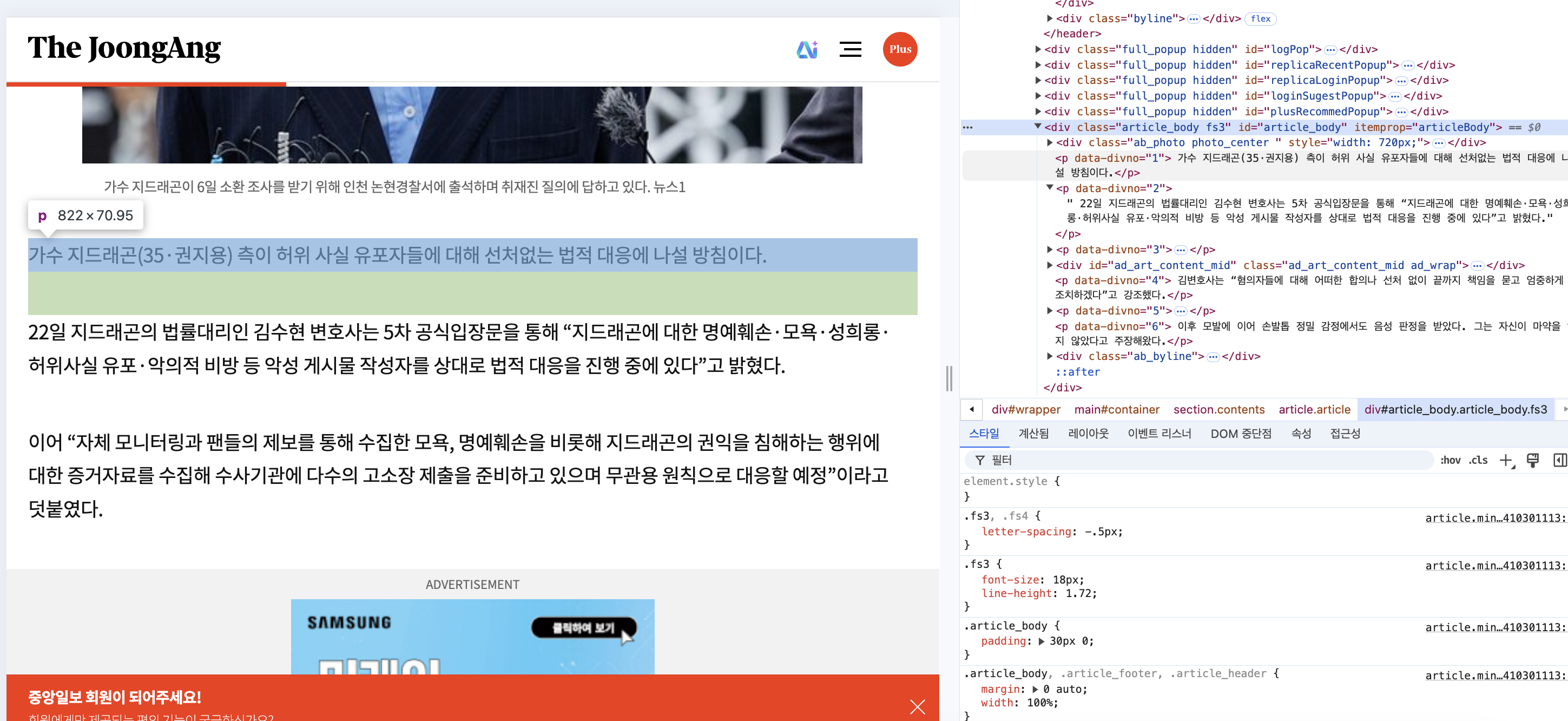
기사 본문 전체는 article_body fs3이라는 class를 가지고 글 하나하나는 p태그로 감싸져있는 것을 확인할 수 있다. 이를 p태그를 다 모아서 기사 본문을 만들어내야 하는 것이다. 코드를 봐보자.
article_body = driver.find_element(By.CSS_SELECTOR, 'div.article_body.fs3')
paragraphs = article_body.find_elements(By.TAG_NAME, 'p')
article_text = '\n'.join([p.text for p in paragraphs])driver가 div 태그의 article_body의 fs3을 css selector로 선택하고 이를 driver_body에 담는다.
이후 driver_body의 p태그를 선택하고, 이들을 다 합쳐서(join) article_text에 담는다.
내가 선택한 언론사는 총 5개였기에 금방 할 수 있었다. 코드는 다음과 같다.
if 'joongang.co.kr' in url:
try:
article_body = driver.find_element(By.CSS_SELECTOR, 'div.article_body.fs3')
paragraphs = article_body.find_elements(By.TAG_NAME, 'p')
article_text = '\n'.join([p.text for p in paragraphs])
except Exception:
pass
elif 'chosun.com' in url:
try:
article_body = driver.find_element(By.CSS_SELECTOR, 'section.article-body')
paragraphs = article_body.find_elements(By.TAG_NAME, 'p')
article_text = '\n'.join([p.text for p in paragraphs])
except Exception:
pass
elif 'khan.co.kr' in url:
try:
article_body = driver.find_element(By.CSS_SELECTOR, 'div.art_body')
paragraphs = article_body.find_elements(By.TAG_NAME, 'p')
article_text = '\n'.join([p.text for p in paragraphs])
except Exception:
pass
elif 'hani.co.kr' in url:
try:
article_body = driver.find_element(By.CSS_SELECTOR, 'div.article-text')
paragraphs = article_body.find_elements(By.TAG_NAME, 'p')
article_text = '\n'.join([p.text for p in paragraphs])
except Exception:
pass
elif 'donga.com' in url:
try:
article_body = driver.find_element(By.CSS_SELECTOR, 'section.news_view')
article_text = article_body.text
except Exception:
pass
except Exception:
pass
# 각 URL에 대해 결과를 추가
article_texts.append(article_text)
driver.quit()
# 데이터프레임에 추가
df['기사 본문'] = article_texts
new_file_path = '/Users/ohchanju/Desktop/data/nursing_with_articles.xlsx'
df.to_excel(new_file_path, index=False)
print(f"크롤링한 기사 본문을 {new_file_path}에 저장했습니다!")
생성된 기사 본문을 엑셀로 다운까지 받아주었다.
이제 다음 글에서는 크롤링한 기사 본문으로 감성 분석을 진행해보겠다 !!

멋져요 !