SQL 활용 [1] : 다양한 연산자 및 함수

다양한 SQL 연산자
1. 비교 연산자 (다른 프로그래밍 언어와 다른 것만 기술)
- 같지 않다 : '
<>'
2. 논리 연산자
- 2-1. AND : 앞, 뒤 조건 모두 만족
SELECT *
FROM CUSTOMER
WHERE GENDER = "MAN"
AND ADDR = "Gyeonggi";👉 : 성별이 남성이고 경기지역에 사는 회원 정보만 조회
- 2-2. NOT : 뒤의 조건에 반대
SELECT *
FROM CUSTOMER
WHERE NOT GENDER = "MAN";👉 : 성별이 남성이 아닌 회원 정보만 조회
- 2-3. OR : 조건 중 하나라도 만족
SELECT *
FROM CUSTOMER
WHERE GENDER = "MAN"
OR ADDR = "Gyeonggi"; 👉 : 성별이 남성이거나 거주 지역이 경기인 회원 정보만 조회
3. 특수 연산자
- 3-1. BETWEEN a AND b : a와 b사이의 값
SELECT *
FROM CUSTOMER
WHERE YEAR(BIRTHDAY) BETWEEN 2010 AND 2011;👉 : 생일의 연도가 2010과 2011 사이인(2010, 2011) 회원 정보만 조회
※ BETWEEN에 NOT을 붙일 수도 있다.
SELECT *
FROM CUSTOMER
WHERE YEAR(BIRTHDAY) NOT BETWEEN 1950 AND 2020; 👉 : 생일의 연도가 1950과 2020 사이의 값이 아닌 회원 정보만 조회
- 3-2. IN (List) : List 값
SELECT *
FROM CUSTOMER
WHERE YEAR(BIRTHDAY) IN (2010, 2011);👉 : 생일의 연도가 2010과 2011인 회원 정보만 조회
※ 마찬가지로 IN에도 NOT을 붙일 수도 있다.
SELECT *
FROM CUSTOMER
WHERE YEAR(BIRTHDAY) NOT IN (2010, 2011);👉 : 생일의 연도가 2010과 2011이 아닌 회원 정보만 조회
- 3-3. LIKE 비교 문자열 : %의 위치에 따라 비교 문자열의 쓰임이 달라진다.
① %가 맨 뒤에 쓰일 때 : ~로 시작하는
SELECT *
FROM CUSTOMER
WHERE ADDR LIKE "D%";👉 : 거주 지역이 D로 시작하는 회원 정보만 조회
② %가 맨 앞에 쓰일 때 : ~로 끝나는
SELECT *
FROM CUSTOMER
WHERE ADDR LIKE "%N"; 👉 : 거주 지역이 N으로 끝나는 회원 정보만 조회
③ %가 양 끝에 쓰일 때 : ~를 포함하는
SELECT *
FROM CUSTOMER
WHERE ADDR LIKE "%EO"; 👉 : 거주 지역에 EO가 들어간 회원 정보만 조회
※ LIKE에도 NOT을 붙일 수 있다.
SELECT *
FROM CUSTOMER
WHERE ADDR NOT LIKE "%EO"; 👉 : 거주 지역에 EO가 들어가지 않은 회원 정보만 조회
- 3-4. IS NULL : NULL을 의미 (JOIN 시 자주 사용)
SELECT *
FROM CUSTOMER AS A
LEFT
JOIN SALES AS B
ON A.MEM_NO = B.MEM_NO
WHERE B.MEM_NO IS NULL;👉 : A와 B의 결합 테이블에서 B의 회원번호가 NULL인 회원 정보만 조회
(회원가입만 하고 구매 이력은 없는 회원들 조회)
※ IS NULL에도 NOT을 붙일 수 있다.
SELECT *
FROM CUSTOMER AS A
LEFT
JOIN SALES AS B
ON A.MEM_NO = B.MEM_NO
WHERE B.MEM_NO IS NOT NULL; 👉 : A와 B의 결합 테이블에서 B의 회원번호가 NULL이 아닌 회원 정보만 조회
(회원가입하고 주문 이력이 있는 회원들 조회)
4. 산술 연산자 (다른 프로그래밍 언어와 동일)
5. 집합 연산자 : 열 개수와 데이터 타입이 일치할 때 쓸 수 있다.
-SALES_2019 테이블 : SALES 테이블에서 주문일자가 2019년인 회원만 조회한 테이블
-SALES 행 개수 : 3115개
-SALES_2019 행 개수 : 1235개
- UNION : 2개 이상 테이블의 중복된 행들을 제거하여 집합한다.
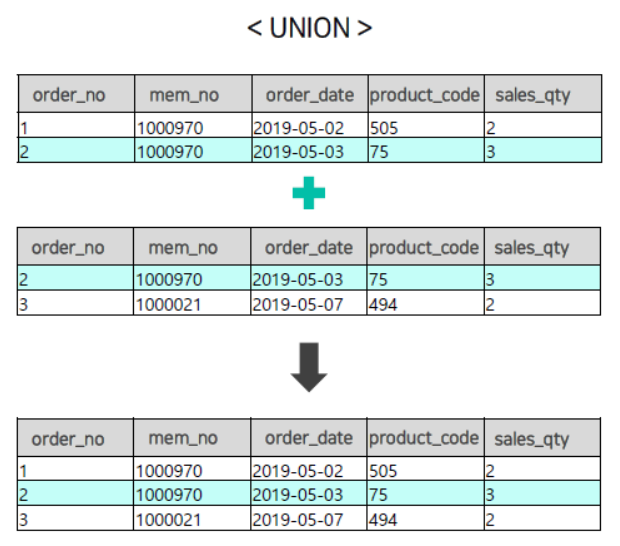
SELECT *
FROM SALES_2019
UNION
SELECT *
FROM SALES; 👉 : UNION은 두 테이블 사이에 작성되어야 한다.
👉 : SALES의 행 개수인 3115개의 행이 조회가 된다.
(SALES_2019의 행이 다 SALES와 중복되기 때문에 제거하고 조회된다.)
- UNION ALL : 2개 이상 테이블의 중복된 행들을 제거하지 않고 집합한다.
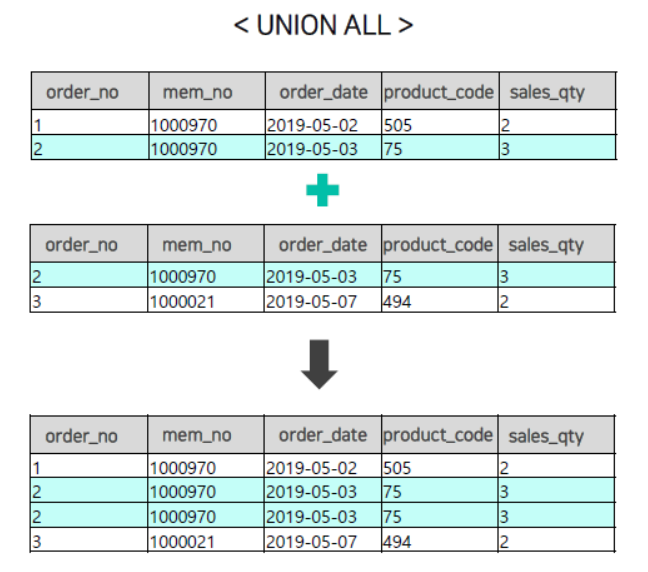
SELECT *
FROM SALES_2019
UNION ALL
SELECT *
FROM SALES;👉 : UNION ALL은 두 테이블 사이에 작성되어야 한다.
👉 : 중복 제거가 되지 않기 때문에 3115 + 1235 = 4350행이 조회된다.
다양한 SQL 함수
: 특정 규칙에 의해 새로운 결과 값으로 반환하는 명령어
1. 단일 행 함수
👉 : 모든 행에 대해 각각 함수가 적용되어 반환된다.
👉 : 함수들을 중첩해서 사용 가능하다.
-
1-1. 숫자형 함수
- ① ABS(숫자) : 절댓값 반환
👉 : 200을 반환SELECT ABS(-200);
- ② SQRT(숫자) : 제곱근 값 반환
👉 : 3을 반환SELECT SQRT(9);
- ③ ROUND(숫자, N) : N 기준으로 반올림 값 반환(N번째 자리까지 반올림)
👉 : 2.2를 반환SELECT ROUND(2.18, 1);
- ① ABS(숫자) : 절댓값 반환
-
1-2. 문자형 함수
-
① LOWER(문자) / UPPER(문자) : 소문자 / 대문자 변환
SELECT LOWER("AB");
SELECT UPPER("ab");👉 : ab와 AB를 반환
-
② LEFT(문자, N) / RIGHT(문자, N) : 왼쪽 / 오른쪽부터 N만큼 문자 반환
SELECT LEFT("APPLE", 2);
SELECT RIGHT("APPLE", 2);👉 : AP와 LE를 반환
-
③ LENGTH(문자) : 문자수 반환
SELECT LENGTH("AB");
👉 : 2를 반환 (문자 개수)
-
-
1-3. 날짜형 함수
-
① YEAR / MONTH / DAY : 연 / 월 / 일 반환
SELECT YEAR("2022-01-11");
SELECT MONTH("2022-01-11");
SELECT DAY("2022-01-11");👉 : 연도인 2022 / 월인 1 / 일인 11을 반환한다.
-
② DATE_ADD(날짜, INTERVAL + 숫자 + 더할 기준) : INTERVAL만큼 더한 값을 반환
SELECT DATE_ADD("2022-01-11", INTERVAL 1 MONTH)
👉 : INTERVAL이 1달이므로 2022년 1월 11에서 1달을 더한 2022년 2월 11일을 반환한다.
-
③ DATEDIFF(날짜A, 날짜B) : 날짜A - 날짜B의 일 수 반환
SELECT DATEDIFF("2022-12-31", "2022-12-01");
👉 : 2022년 12월 31일과 2022년 12월 1일의 기간인 30일을 반환한다.
-
-
1-4. 형변환 함수
-
① DATE_FORMAT(날짜, 형식) : 날짜의 형식을 변환
SELECT DATE_FORMAT("2022-01-11", "%m-%d-%y");
SELECT DATE_FORMAT("2022-01-11", "%M-%D-%Y")👉 : m : 월 / d : 일 / y : 연도를 의미하고, 소문자는 숫자 형태로 반환 / 대문자는 문자 형태로 반환된다.
👉 : 01-11-2022 / December-31st-2022 로 반환된다. -
② CAST(형식a AS 형식b) : 형식 a를 형식 b로 변환
SELECT CAST(”2022-01-11 12:00:00” AS DATE);
👉 : 2022-01-11 12:00:00을 년월일 형식인 DATE로 변환했으므로 2022-01-11이 반환된다.
-
-
1-5. 일반 함수
-
① IFNULL(A, B) : A가 NULL이면 B를 반환, NULL이 아니면 A를 그대로 반환한다.
SELECT IFNULL(NULL, 0);
SELECT IFNULL("KSH", 0);👉 : 처음 값이 NULL이므로 0을 반환 / 처음 값이 NULL이 아니므로 KSH를 반환
-
② CASE 함수 : 여러 조건별로 반환값 지정
/* CASE WHEN [조건1] THEN [반환1] WHEN [조건2] THEN [반환2] ELSE [반환3] END : 조건1 만족 -> 반환1 / 조건2 만족 -> 반환2 / 나머지 -> 반환3 */ SELECT * ,CASE WHEN GENDER = "MAN" THEN "남성" ELSE "여성" END FROM CUSTOMER;👉 : 성별이 남자면 남성을 반환하고, 아니면 여성을 반환
-
2. 복수행 함수
👉 : 여러 행들이 하나의 결과 값으로 반환된다.
👉 : 주로 GROUB BY 절과 함께 사용된다.
- 2-1. 집계함수
SELECT COUNT(ORDER_NO) AS 구매횟수 /* 행수 */
,COUNT(DISTINCT MEM_NO) AS 구매자수 /* 중복제거된 행수 */
,SUM(SALES_QTY) AS 구매수량 /* 합계 */
,AVG(SALES_QTY) AS 평균구매수량 /* 평균 */
,MAX(ORDER_DATE) AS 최근구매일자 /* 최대 */
,MIN(ORDER_DATE) AS 최초구매일자 /* 최소 */
FROM SALES; - 2-2. 그룹함수
- WITH ROLLUP : GROUP BY 열들의 소계, 합계까지 조회
(소계 : 맨 왼쪽 그룹별 합 / 합계 : 모든 행의 합)
- WITH ROLLUP : GROUP BY 열들의 소계, 합계까지 조회
SELECT YEAR(JOIN_DATE) AS 가입연도
,ADDR
,COUNT(MEM_NO) AS 회원수
FROM CUSTOMER
GROUP
BY YEAR(JOIN_DATE)
,ADDR
WITH ROLLUP; 👉 : 맨 왼쪽 그룹 : YEAR 그룹이므로 YEAR 그룹의 회원수 합계와, 모든 행의 합계가 반환된다.
3. 윈도우 함수
👉 : 행과 행간의 관계를 정의하여 결과 값을 반환한다. (순위, 누적집계 등)
👉 : ORDER BY로 행과 행간의 순서를 정하며, PARTITION BY로 그룹화 가능
- 3-1. 순위 함수
/* ROW_NUMBER : 동일한 값이라도 고유한 순위 반환 (1,2,3,4,5,...) */
/* RANK : 동일한 값이면 동일한 순위 반환 (1,2,3,3,5,...) */
/* DENSE_RANK : 동일한 값이면 동일한 순위 반환
(+ 하나의 등수로 취급) (1,2,3,3,4,...) */
/* 기본 구조 */
/* 윈도우 함수() OVER (ORDER BY 기준이 되는 열 ASC OR DESC); */
/* 1번 CASE : PARTITION BY 없을 때*/
SELECT ORDER_DATE
,ROW_NUMBER() OVER (ORDER BY ORDER_DATE ASC) AS 고유한_순위_변환
,RANK() OVER (ORDER BY ORDER_DATE ASC) AS 동일한_순위_변환
,DENSE_RANK() OVER (ORDER BY ORDER_DATE ASC) AS 동일한_순위_변환_하나의등수
FROM SALES;
/* 2번 CASE : PARTITION BY 있을 때 */
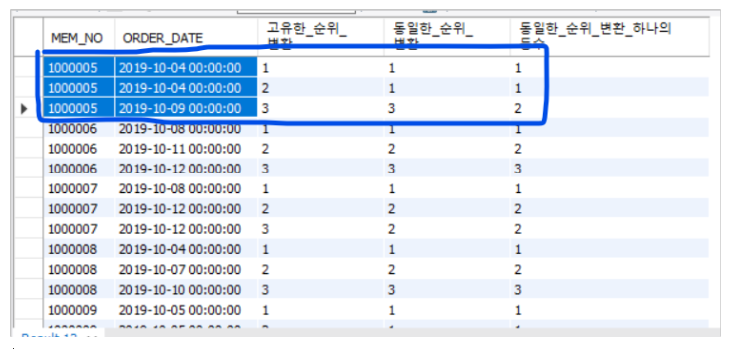
SELECT MEM_NO
,ORDER_DATE
,ROW_NUMBER() OVER (PARTITION BY MEM_NO ORDER BY ORDER_DATE ASC) AS 고유한_순위_변환
,RANK() OVER (PARTITION BY MEM_NO ORDER BY ORDER_DATE ASC) AS 동일한_순위_변환
,DENSE_RANK() OVER (PARTITION BY MEM_NO ORDER BY ORDER_DATE ASC) AS 동일한_순위_변환_하나의등수
FROM SALES; 👉 : 1번 CASE - 모든 행에 대한 연속된 순위가 반환된다.
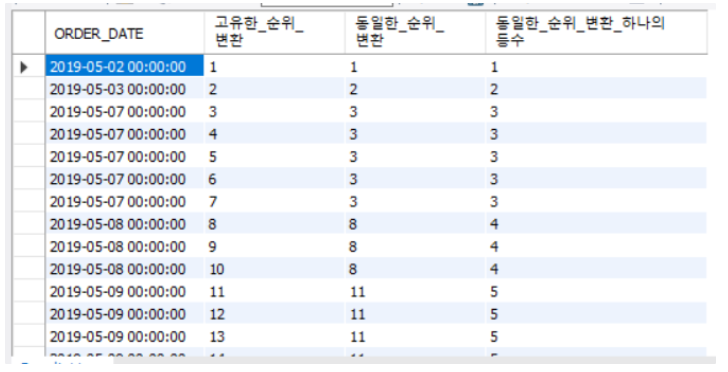
👉 : 2번 CASE (PARTITION BY) - 회원번호별로 순위가 나눠서 반환된다.
- 3-2. 집계 함수(누적)
👉 : 집계 함수에 ORDER BY를 추가해서 누적한다.
/* 1번 CASE : PARTITION BY 없을 때 */
SELECT ORDER_DATE
,SALES_QTY
,"-" AS 구분
,COUNT(ORDER_NO) OVER (ORDER BY ORDER_DATE ASC) AS 누적_구매횟수
,SUM(SALES_QTY) OVER (ORDER BY ORDER_DATE ASC) AS 누적_구매수량
,AVG(SALES_QTY) OVER (ORDER BY ORDER_DATE ASC) AS 누적_평균구매수량
,MAX(SALES_QTY) OVER (ORDER BY ORDER_DATE ASC) AS 누적_가장높은구매수량
,MIN(SALES_QTY) OVER (ORDER BY ORDER_DATE ASC) AS 누적_가장낮은구매수량
FROM SALES;
/* 2번 CASE : PARTITION BY 있을 때 */
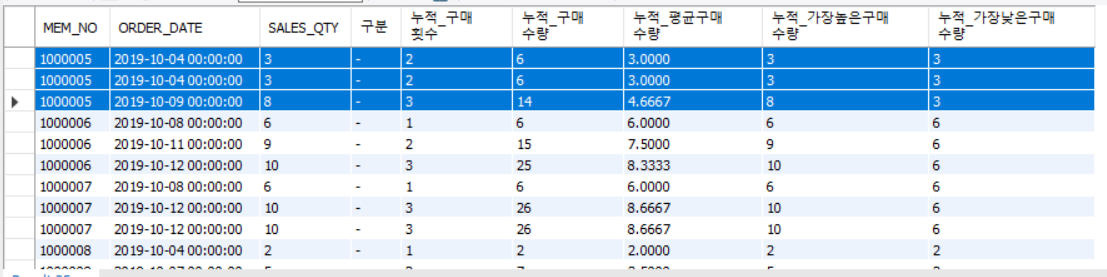
SELECT MEM_NO
,ORDER_DATE
,SALES_QTY
,"-" AS 구분
,COUNT(ORDER_NO) OVER (PARTITION BY MEM_NO ORDER BY ORDER_DATE ASC) AS 누적_구매횟수
,SUM(SALES_QTY) OVER (PARTITION BY MEM_NO ORDER BY ORDER_DATE ASC) AS 누적_구매수량
,AVG(SALES_QTY) OVER (PARTITION BY MEM_NO ORDER BY ORDER_DATE ASC) AS 누적_평균구매수량
,MAX(SALES_QTY) OVER (PARTITION BY MEM_NO ORDER BY ORDER_DATE ASC) AS 누적_가장높은구매수량
,MIN(SALES_QTY) OVER (PARTITION BY MEM_NO ORDER BY ORDER_DATE ASC) AS 누적_가장낮은구매수량
FROM SALES;
👉 : 1번 CASE - 모든 행에 대해 계속 누적된다.
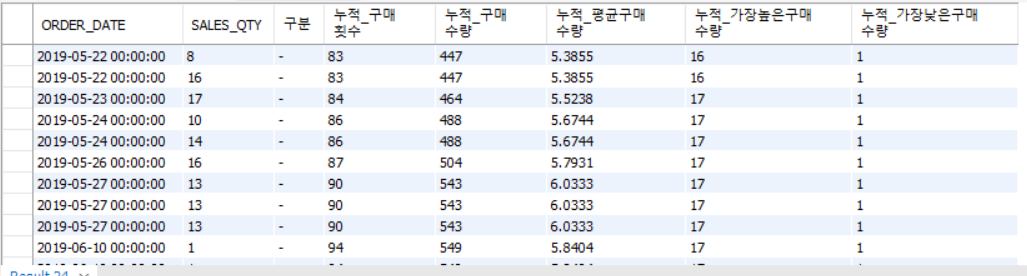
👉 : 2번 CASE (PARTITION BY) - 회원번호별로 누적되어서 반환된다.