
SQL VIEW
VIEW : 하나 이상의 테이블들을 활용하여 사용자가 정의한 가상 테이블
VIEW 특징
- JOIN 사용을 최소화하여 편의성을 최대화
- 가상 테이블이기때문에 중복되는 열이 저장될 수 없다.
👉 : A와 B를 JOIN한 테이블을 가상 테이블로 지정할 때 A와 B의 중복되는 열은 빼고 SELECT를 해야한다. (SELECT * 을 하면 안 된다.)
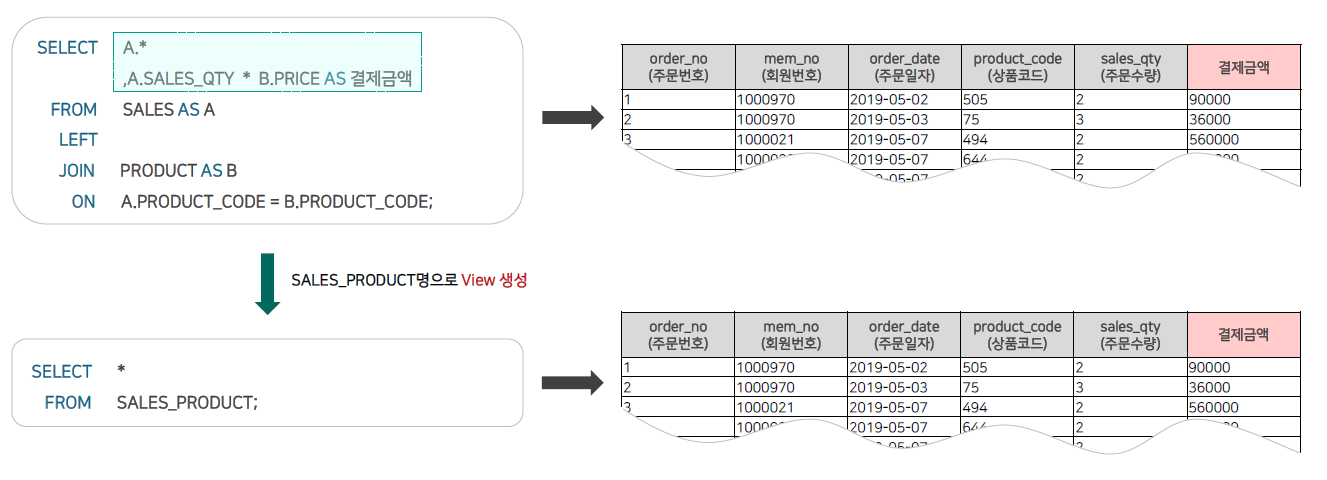
👉 : 프로그래밍 언어에서 변수를 선언하고 재사용하는 것과 같은 원리다!
1. VIEW 기본 구조
CREATE VIEW 가상테이블명 AS ~
2. VIEW 생성
/* VIEW 생성 */
CREATE VIEW SALES_PRODUCT AS
SELECT A.*
,A.SALES_QTY * B.PRICE * 1.1 AS 결제금액
FROM SALES AS A
LEFT
JOIN PRODUCT AS B
ON A.PRODUCT_CODE = B.PRODUCT_CODE;3. VIEW 수정 : CREATE를 ALTER로 바꾼 후 AS 뒤를 수정하면 된다.
/* VIEW 수정 : CREATE를 ALTER로 바꾼 후 AS 뒤를 수정하면 된다. */
ALTER VIEW SALES_PRODUCT AS
SELECT A.*
,A.SALES_QTY * B.PRICE * 1.1 AS 결제금액_수수료포함
FROM SALES AS A
LEFT
JOIN PRODUCT AS B
ON A.PRODUCT_CODE = B.PRODUCT_CODE;4. VIEW 삭제
/* VIEW 삭제 */
DROP VIEW SALES_PRODUCT;SQL Procedure
Procedure : 매개변수를 활용하여, 사용자가 정의한 작업을 저장한다.
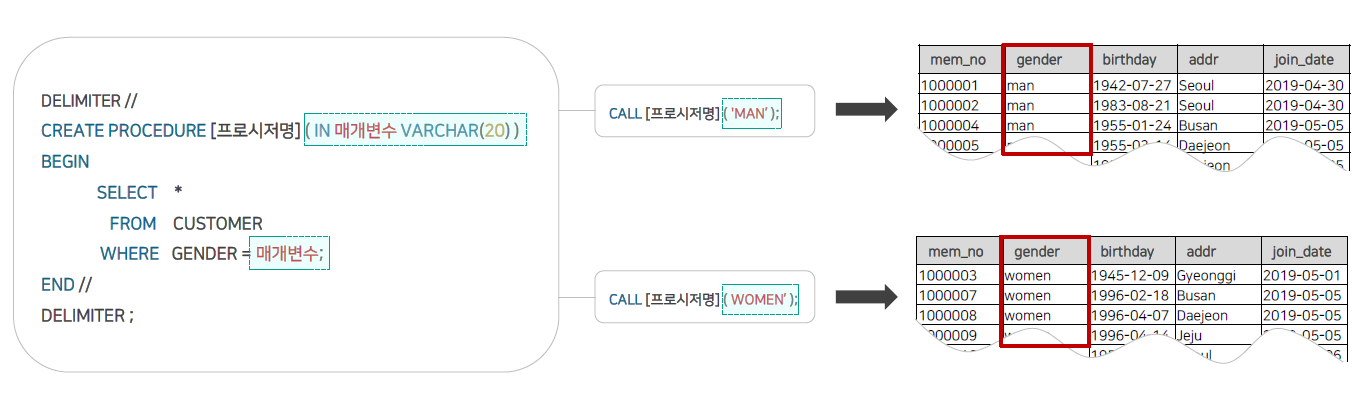
👉 : 프로그래밍 언어에서 함수를 선언하고 사용하는 것과 같은 원리이다!
1. Procedure 기본 구조
DELIMITER //
CREATE PROCEDURE 프로시저명 (IN/OUT/INOUT 매개변수명 데이터타입)
BEGIN
작업 내용
END //
DELIMITER👉 DELIMITER : 여러 명령어들을 하나로 묶어주는 역할
👉 BEGIN / END : 작업 내용의 시작과 끝에 작성
2. Procedure 실행
CALL 프로시저명 (매개변수 입력);
3. Procedure 삭제
DROP PROCEDURE 프로시저명;
4. 매개변수의 종류
- 4-1. IN 매개변수 : 매개변수를 프로시저로 전달한다.
DELIMITER //
CREATE PROCEDURE CST_GEN_ADDR_IN (IN INPUT_A VARCHAR(20), INPUT_B VARCHAR(20) ))
BEGIN
SELECT *
FROM CUSTOMER
WHERE GENDER = INPUT_A
AND ADDR = INPUT_B;
END //
DELIMITER; 👉 CST_GEN_ADDR_IN 프로시저의 기능
: INPUT_A와 INPUT_B를 매개변수로 받아서 GENDER와 ADDR이 매개변수와 일치하는 행만 조회한다.
CALL CST_GEN_ADDR_IN("MAN", "SEOUL"); 👉 : 성별이 MAN이고 거주지역이 SEOUL인 행만 조회된다.
- 4-2. OUT 매개변수 : 프로시저의 결과 값을 매개변수에 반환한다.
DELIMITER //
CREATE PROCEDURE CST_GEN_ADDR_IN (IN INPUT_A VARCHAR(20), INPUT_B VARCHAR(20), OUT CNT_MEN INT)
BEGIN
SELECT COUNT(MEM_NO)
INTO CNT_MEN
FROM CUSTOMER
WHERE GENDER = INPUT_A
AND ADDR = INPUT_B;
END //
DELIMITER; 👉 CST_GEN_ADDR_IN 프로시저의 기능
: INPUT_A와 INPUT_B를 매개변수로 받아서 GENDER와 ADDR이 매개변수와 일치하는 행의 회원수를 조회한다. 그리고 그 회원수를 CNT_MEN이라는 OUT 매개변수에 반환한다.
이때 OUT 매개변수를 반환한다는 의미로 INTO를 쓴다! (INTO OUT매개변수)
CALL CST_GEN_ADDR_IN_CNT_MEN_OUT("WOMEN", "INCHEON", @CNT_MEM);
SELECT @CNT_MEM; 👉 : 성별이 WOMEN이고 거주지역이 INCHEON인 회원수만 조회해서 그 값을 CNT_MEM에 반환한다.
SELECT @CNT_MEM을 해서 해당하는 회원수를 조회할 수 있다.
※ 주의할 점 : OUT 프로시저 호출 시 OUT 매개변수는 @로 호출해야한다!
(MYSQL은 변수에 @를 붙여서 선언, 호출한다)
- 4-3. INOUT 매개변수 : 매개변수를 프로시저로 전달하고 프로시저의 결과 값을 매개변수에 반환하는 IN, OUT의 성질을 둘 다 갖고 있다.
DELIMITER //
CREATE PROCEDURE IN_OUT_PARAMETER(INOUT COUNT INT)
BEGIN
SET COUNT = COUNT + 10;
END //
DELIMITER; 👉 : COUNT라는 매개변수를 입력받고 10을 더해서 COUNT 매개변수에 반환한다.
SET @counter = 1;
CALL IN_OUT_PARAMETER(@counter);
SELECT @counter; 👉 : counter라는 변수를 선언하고 매개변수로 입력하여 마지막에 counter를 조회하면 1에 10이 더해진 11을 조회한다.
SQL 데이터 마트
데이터 마트 : 분석에 필요한 데이터를 가공한 분석용 데이터
-
요약 변수 : 수집된 데이터를 분석에 맞게 종합한 변수
-
파생 변수 : 사용자가 특정 조건 또는 함수로 의미를 부여한 변수
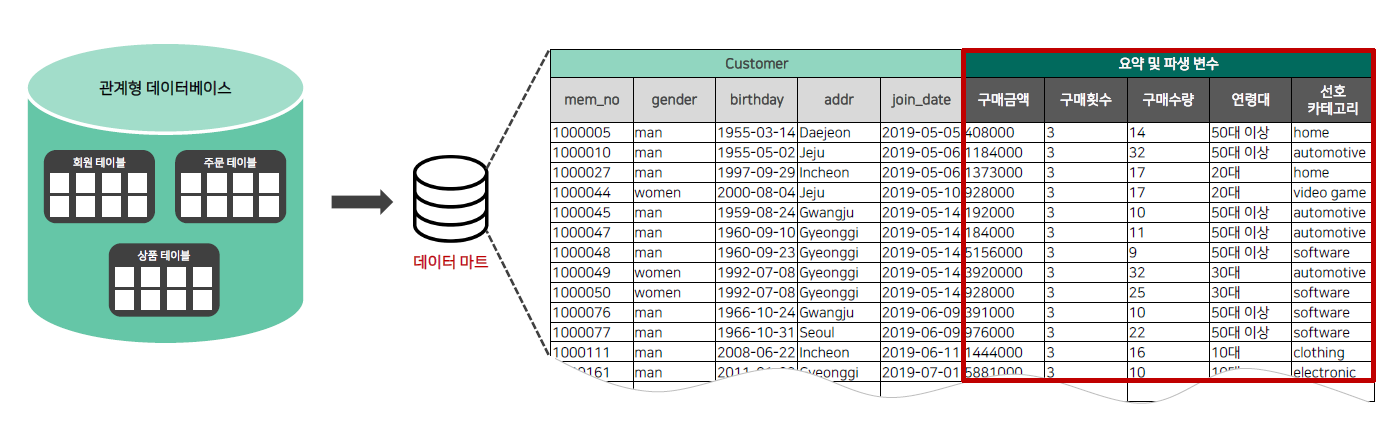
👉 : 데이터 마트의 기능이 따로 있는 게 아니라 기존 테이블에 분석이 필요한 데이터를 사용자가 추가 및 수정한 것을 데이터 마트라고 한다. (일반 테이블과 같음)
-
데이터 정합성
: 데이터가 서로 모순없이 일관되게 일치함을 나타낼 때 사용
(데이터를 가공한 마트와 기존 테이블의 데이터가 일치하는가?)
-
데이터 정합성 판단 기준
1.데이터 마트의 회원 수의 중복은 없는가?
SELECT COUNT(MEM_NO)
,COUNT(DISTINCT MEM_NO)
FROM CUSTOMER_MART; 👉 : DISTINCT는 중복을 제거하므로 COUNT(MEM_NO)와 COUNT(DISTINCT MEM_NO)를 조회하여 개수가 같으면 현재 데이터 마트에 중복이 없는 것이다.
2.데이터 마트의 회원 수의 중복은 없는가?
: 데이터 마트로 만든 변수의 값과 기존 테이블에 존재하는 변수의 값을 비교해서 같으면 오류가 없는 것이다.
/* 현재 데이터 마트에서 회원(1000005)의 구매정보 */
/* 구매금액 : 408000 / 구매횟수 : 3 / 구매수량 : 14 */
/* 기존 테이블의 값 체크 */
SELECT SUM(A.SALES_QTY * B.PRICE) AS 구매금액
,COUNT(A.ORDER_NO) AS 구매횟수
,SUM(A.SALES_QTY) AS 구매수량
FROM SALES AS A
LEFT
JOIN PRODUCT AS B
ON A.PRODUCT_CODE = B.PRODUCT_CODE
WHERE MEM_NO = "1000005" 👉 : 기존 테이블과 데이터 마트에서 회원의 구매금액, 구매횟수, 구매수량이 다 맞으면 오류가 없는 것이다.
3.데이터 마트의 구매자 비중(%)의 오류는 없는가?
/* 회원(CUSTOMER)테이블과 주문(SALES)테이블의 회원번호를 LEFT JOIN */
SELECT *
FROM CUSTOMER AS A
LEFT
JOIN (
SELECT DISTINCT MEM_NO
FROM SALES
) AS B
ON A.MEM_NO = B.MEM_NO; 👉 : MEM_NO에 NULL값이 조회되면 구매자가 아닌 것이다.
/* 구매 여부 추가 */
SELECT *
,CASE WHEN B.MEM_NO IS NOT NULL THEN "구매"
ELSE "미구매" END AS 구매여부
FROM CUSTOMER AS A
LEFT
JOIN (
SELECT DISTINCT MEM_NO
FROM SALES
) AS B
ON A.MEM_NO = B.MEM_NO; 👉 : CASE 함수를 사용하여 구매여부 열이 추가되고 구매, 미구매로 표현된다.
이 코드를 FROM절 서브쿼리로 넣어서 회원수를 집계하면 구매자 비중을 구할 수 있다.
SELECT 구매여부
,COUNT(MEM_NO) AS 회원수
FROM (
SELECT A.* // A와 B가 중복 열이 있으므로 SELECT *은 X
,CASE WHEN B.MEM_NO IS NOT NULL THEN "구매"
ELSE "미구매" END AS 구매여부
FROM CUSTOMER AS A
LEFT
JOIN (
SELECT DISTINCT MEM_NO
FROM SALES
) AS B
ON A.MEM_NO = B.MEM_NO;
) AS A
GROUP
BY 구매여부;이러한 기존 테이블의 데이터가 데이터 마트에서 동일한지 비교
SELECT *
FROM CUSTOMER_MART
WHERE 구매금액 IS NULL; // 미구매자
SELECT *
FROM CUSTOMER_MART
WHERE 구매금액 IS NOT NULL; // 구매자👉 : 조회되는 행의 개수가 위에서 구한 기존 데이터의 구매자수, 미구매자수와 동일하면 오류가 없는 것이다.
하... SQL 너무 어렵다... 생소하기도 하고 너무 어려운 걸 배운 것 같다,,
