스파르타 코딩 클럽 [웹개발종합반] 3주차 WIL(Week I Learned) - Python / 웹 스크래핑(크롤링) / mongoDB

3주차 Python / 웹 스크래핑(크롤링) / mongoDB
3주차에서는 Python 기본 문법들과 웹 스크래핑(크롤링) 하는 법, mongoDB 사용법을 배웠다.
Python을 어느정도 다룰 줄 알아서 Python 기본 문법 부분은 정리도 안하고 쑥쑥 넘어갔다.
웹 스크래핑(크롤링)과 mongoDB는 아예 처음 배우는 것들이었는데 파이썬 기본 문법을
좀 알아서 그런지 익숙하지가 않았던 것이지 어렵지는 않았던 것 같다.
확실히 데이터를 뽑아온다는 것이 재밌었다!
(근데 뽑아오다가 막히면 재미없음..ㅠㅠ)
가상환경(Virtual environment)
: 라이브러리를 담아두는 폴더
파이참 venv 폴더에 설치할 라이브러리들이 담긴다!
requests 패키지
import requests # requests 라이브러리 설치 필요
r = requests.get('http://openapi.seoul.go.kr:8088/6d4d776b466c656533356a4b4b5872/json/RealtimeCityAir/1/99')
rjson = r.json()
print(rjson['RealtimeCityAir']['row'][0]['NO2'])requests.get("url") 을 하면 Ajax에서 했던 것과 비슷한 결과가 나온다.
웹 스크래핑(크롤링)
beautifulsoup4 패키지 설치
웹페이지는 이미 받아 온 상태. 그 상태에서 정보를 솎아내는 게 크롤링이다.
크롤링 시 중요한 2가지
- 코드에서 요청하기 →
requests패키지 이용 - 요청돼서 가지고 온 html 중 내가 원하는 정보를 잘 솎아내기 →
beautifulsoup4이용
👉 request 로 요청하고 beautifulsoup4 로 솎아낸다!
beautifulsoup
beautifulsoup4 사용
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=pnt&date=20200303',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
print(soup)print(soup)을 하면 요청된 html이 출력된다.
requests.get의 headers 옵션 : 기본적으로 코드에서의 요청을 막아둔 사이트들이 있어서 코드가 아니라 브라우저에서 엔터친 것처럼 동작하게 해서 정보를 받아옴.
data에 요청한 정보가 들어있다.
그 정보를 beautifulsoup4 를 이용하여 soup = BeautifulSoup(data.text, 'html.parser') 형태로 저장하면 html 형태로 soup에 저장된다.
beautifulsoup 사용 방법
① select_one : 1개 반환
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=pnt&date=20200303',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
title = soup.select_one("#old_content > table > tbody > tr:nth-child(2) > td.title > div > a")#select_one("선택자") -> 선택한 태그가 출력된다. <a href ="~~">그린 북</a>
#select_one("선택자").text → 선택한 태그의 text를 가져온다. 그린 북
#select_one("선택자")["href"] → 선택한 태그의 속성(href)를 가져온다 "~~"
② select : 리스트로 여러 개 반환
<tr>...</tr> 이 여러 개인 태그를 선택하고 싶을 때
자식 요소 중 하나를 copy해서 nth-child() 없애기.
#old_content > table > tbody > tr:nth-child(3)
→ #old_content > table > tbody > tr
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=pnt&date=20200303',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
trs = soup.select("#old_content > table > tbody > tr")
for tr in trs:
a_tag = tr.select_one("td.tilte > div > a")
if a_tag is not None:
title = a_tag.text
print(title)is 는 True / False / None 같은 타입을 비교할 때 사용
MongoDB / robo 3T
mongoDB : 데이터베이스
→ 내 눈에 보이지 않게 켜진다. 컴퓨터에서 돌아가고 있지만 눈에 보이지 않는다.
robo 3T : mongoDB의 데이터를 우리 눈으로 볼 수 있게 해주는 프로그램
SQL VS NoSQL
SQL : 열과 행을 미리 정해놔야한다.
정형화되어 있어서 많은 데이터가 적재된 상태에서 중간에 열을 하나 더하는 등의 동작을 하기가 힘들다.
하지만 정형화되어 있어서 데이터의 일관성이 좋고 분석에 용이하다
ex) MS-SQL / My-SQL
NoSQL : 딕셔너리 형태로 데이터를 저장한다.
자유로운 형태여서 데이터 적재에 유리하지만, 데이터 일관성이 부족하다.
ex) mongoDB
데이터 일관성
SQL 같은 경우는 적재되어 있는 데이터의 속성들이 다 비슷하다. → 데이터 일관성↑
ex) A가 주소, 전화번호를 가지면 B도 주소, 전화번호를 가짐
NoSQL 같은 경우는 적재되어 있는 데이터의 속성들이 다 다르다. → 데이터 일관성↓
ex) A가 주소, 전화번호를 가지고 있더라도 B가 가질 필요는 없음
pymongo로 DB 조작하기
기본 설정
from pymongo import MongoClient
client = MongoClient('localhost', 27017) # 내 컴퓨터의 mongoDB에 접속
db = client.dbsparta # "dbsparta"라고 하는 DB이름으로 접속1. insert : 데이터 추가
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client.dbsparta
doc = {'name':'bobby','age':21} # 데이터가 딕셔너리 형태로 쌓임
db.users.insert_one(doc) # doc에 저장된 데이터를 users에 넣는다.collection : 카테고리느낌, 하나의 분류로 묶는 것
**db.users.insert_one(doc) 의 의미**
: db 안에 users라는 collection에 doc을 insert해라!
2. find : 데이터 조회
- 2-1. find : 여러 데이터 조회
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client.dbsparta
same_ages = list(db.users.find({'age':21},{'_id':False}))
print(same_ages)<현재 데이터>
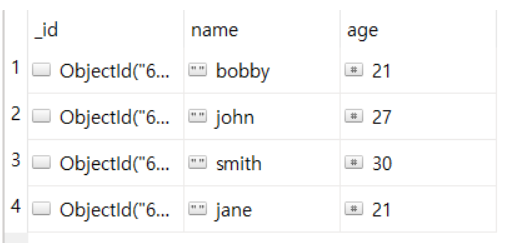
**same_ages = list(db.users.find({'age':21},{'_id':False})) 의 의미**
: db 안에 users라는 collection에 있는 “age”가 21인 행을 _id 열은 제외하고 리스트로 받아와서 same_ages에 저장해라!
따라서, print(same_ages)를 하면 [{”name” : “bobby”, “age” : 21}, {”name” : “jane”, “age” : 21}] 이렇게 출력된다.
여기서, _id 는 자동으로 생성되는 랜덤 유니크 값이다.
따라서, 데이터 조회할 때는 가독성을 위해 {"_id" : False} 로 _id 열을 제외하고 조회한다.
※ 데이터 조회할 때 조건 없이 모든 데이터를 조회하려면 find({}) 이렇게 빈 중괄호를 작성하면 된다!
- 2-2. find_one : 하나의 데이터 조회
user = db.users.find_one({"name" : bobby"}, {"_id"=False})
: name이 bobby인 데이터를 _id 열을 제외하고 가져오기
3. update : 데이터 업데이트(수정)
db.users.update_one({'name':'bobby'},{'$set':{'age':19}})
: name이 bobby인 데이터의 age를 19로 수정해라!
→ 이때 name이 bobby인 데이터가 여러개면 맨 처음 데이터만 수정된다.
이럴 때는 update_many를 사용한다.
하지만, update_many는 여러 데이터를 한 번에 바꾸기 때문에 위험해서
주로 update_one 을 사용한다!
4. delete : 데이터 삭제
db.users.delete_one({'name':'bobby'})
: name이 bobby인 데이터를 삭제해라!
delete도 delete_many 가 있지만 update_many 와 같은 이유로 위험해서 잘 사용하지 않는다.
