
수치형 변수의 탐색적 데이터 분석
1. 히스토그램과 분포
1-1. 히스토그램 : 표로 되어 있는 도수 분포를 정보 그림으로 나타낸 것(시각화)
1-2. 도수 분포 : 표본의 다양한 산출 분포를 보여주는 목록, 표, 그래프
-
도수 분포표에 들어가는 항목은 특정 그룹이나 주기 안에 값이 발생한 빈도, 횟수를 포함하고 있으며 표본 값의 분포를 요약한다.
-
나이를 10대, 20대, 30대, 40대로 그룹화하게 되면 그룹들의 빈도수를 구할 수 있는데 이렇게 빈도수 등을 나타낸 표를 도수 분포표라고 한다.
그리고 이 표를 시각화한 것이 히스토그램
1-3. 수치형 변수의 unique값, unuique 보기
: df["mpg"].unique() -> mpg 변수의 유일값들을 보여준다. (중복 X)
: df["mpg"].nunique() -> mpg 변수의 유일값의 개수를 보여준다.
1-4. 히스토그램 그리기 : hist()를 사용하면 히스토그램을 그릴 수 있다.
df.hist() : 히스토그램이 그려지긴 하지만 위의 로그때문에 가독성이 떨어진다.
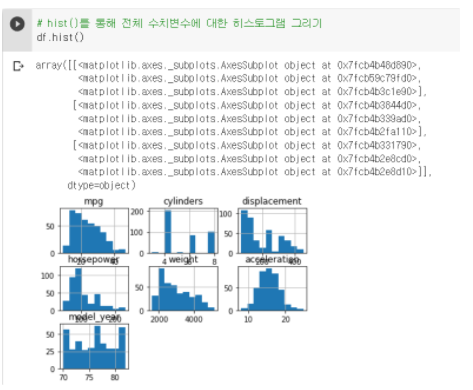
따라서 df.hist()를 따로 변수에 저장해서 출력한다.
A = df.hist() 이렇게 하면 로그가 뜨지 않고 히스토그램만 떠서 가독성이 좋다.
X축 : 값의 범위 / Y축 : 빈도수
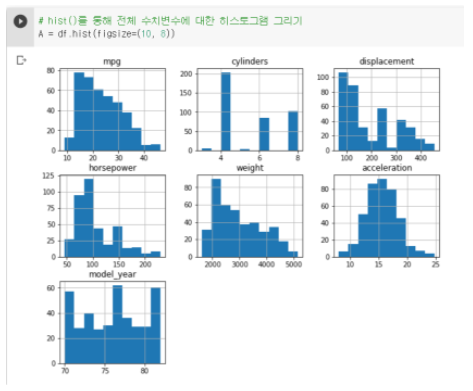
hist 안의 figsize는 표의 크기를 정하는 명령어이다.
bins는 막대 개수인데, bins로 값의 범위와 빈도수를 조절할 수 있다.
-
bins = 10일 때
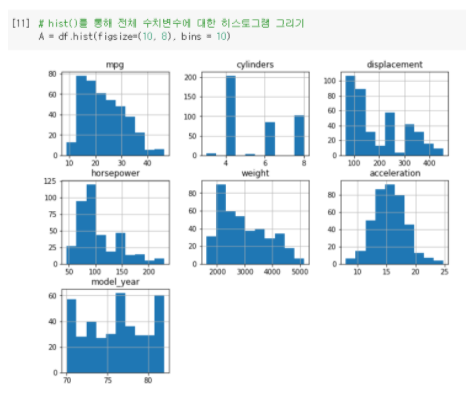
: 막대의 수가 10개로 적어서 그만큼 범위가 좁고 빈도수도 높은 것을
알 수 있다. -
bins = 50일 때
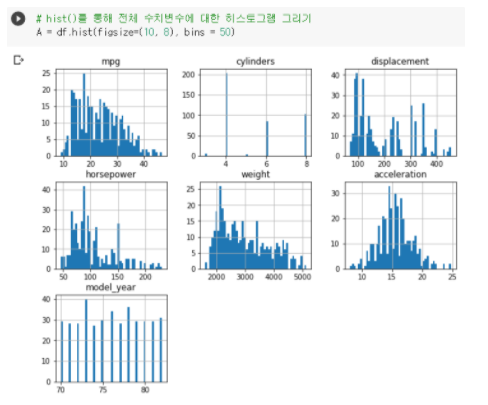
: 막대의 수가 50개로 많아서 그만큼 범위도 높고 빈도수도 적은 것을
알 수 있다.
: 막대의 수가 많아졌을때 연속된 수치 데이터를 잘 볼 수 있다.
ex) bins=10일때는 mpg와 model_year 모두 비슷한 연속된 수치데이터로 보이지만 bins=50일때 비교해보면 model_year는 mpg에 비해 덜 연속적인 것을 알 수 있다.
- 히스토그램 분석
: mpg, horsepower, weight는 연속된 수치 데이터로 볼 수 있고 앞 쪽에 값이 몰려 있다.
그러나, acceleration은 이상적인 정규 분포와 유사한 분포를 가진다.
cylinders, model_year는 값이 숫자지만 연속된 수치 데이터라기 보다는 범주형 데이터에 가깝다.
2. 비대칭도(왜도)
- 실수 값 확률 변수의 확률 분포 비대칭성을 나타내는 지표
- 왼쪽, 오른쪽에 얼마나 치우친지 나타내는 지표
- 왜도가 음수일때는 왼쪽 부분에 긴 꼬리를 가지며, 오른쪽에 많이 분포
- 왜도가 양수일때는 오른쪽 부분에 긴 꼬리를 가지며, 왼쪽에 많이 분포
- 평균과 중앙값이 같으면 왜도는 0이다.
: 따라서, 정규분포에 가까워질수록 왜도가 0에 가깝다.
: skew를 통해 나타낼 수 있다.
df.skew()
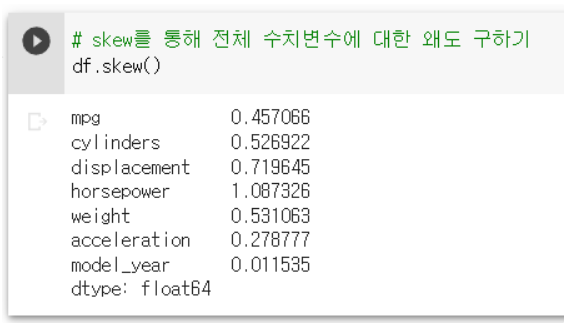
- 왜도 분석
: acceleration과 model_year가 0에 가까운 것을 알 수 있지만
히스토그램과 같이 봤을때 model_year는 값이 균등해서
정규분포에 가깝지 않다.
따라서 acceleration이 왜도가 0에 가깝고 값이 중앙값에 치우쳐져 있어서
정규분포에 가깝다.
3. 첨도
- 확률 분포의 뾰족한 정도를 나타내는 지표
- 관측치들이 얼마나 집중적으로 중심에 몰려있는지 측정 시 사용
- kurt 값이 0보다 작을 경우에는 정규분포보다 더 완만하고 납작한 분포를 가진다.
- kurt 값이 0보다 크면 정규분포보다 더 뾰족한 분포를 가진다.
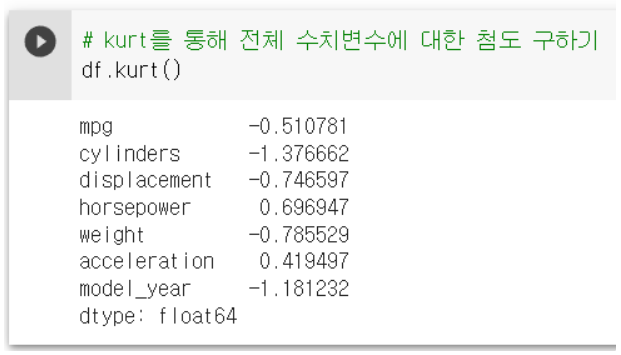
: kurt를 통해 나타낼 수 있다.
df.kurt()
4. 1개의 수치변수 시각화하기
- seaborn을 사용하여 시각화한다.
- seaborn을 사용한 시각화의 장점 : plot만 다르고 plot에 들어가는 입력값들은 다 동일해서 plot이름만 원하는 plot으로 바꿔주면 쉽게 시각화가 가능하다.
4-1. displot : 히스토그램 그래프 출력
sns.displot(data=df, x="mpg") : displot을 통해 히스토그램 그리기
-displot에 kdeplot, rug 옵션 추가
- kdeplot : 히스토그램의 밀도를 추정하여 그린 그래프
- rug : 막대 아래에 값의 빈도수를 나타내준다.
따라서 세개의 옵션을 혼합하여 그래프를 그릴 수 있다.
displot과 kde옵션 사용 -> 히스토그램과 밀도 추정 그래프 출력

- displot 분석
:mpg값은 왼쪽에 값이 몰려 있다.
kdeplot을 통해 밀도를 추정할 수 있다.
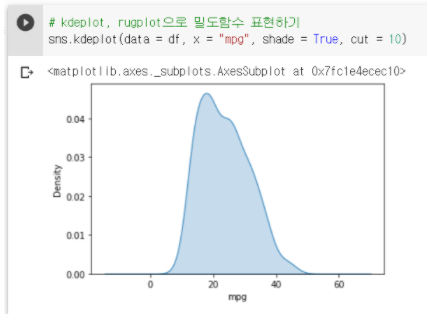
4-2. kdeplot : 밀도 추정 그래프 출력
sns.kdeplot(data=df, x="mpg") : kdeplot을 통해 밀도 추정 그래프 시각화
- kdeplot의 주요 옵션
- shade : shade = True를 하게 되면 영역을 채워서 출력해준다.
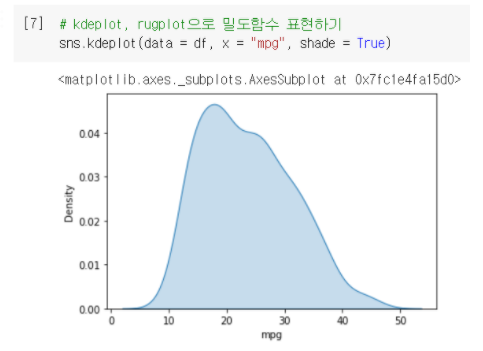
- cut : 그래프를 잘라서, 보여주는 부분(값의 범위)이 달라진다.
① cut = 3일때 그래프
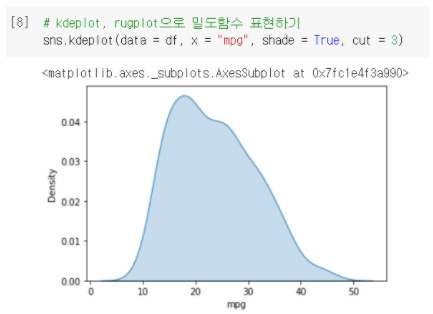
② cut = 10일때 그래프
4-3. boxplot : 사분위 값 표현, 이상치 값 표현
sns.boxplot(data=df, x="mpg") : boxplot 그리기
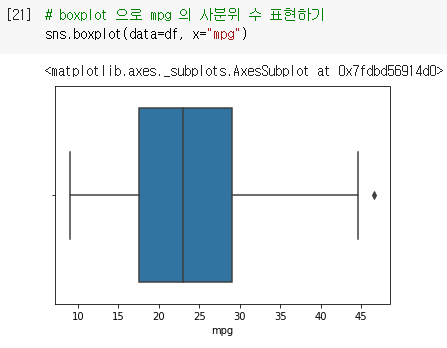
- box 안에 있는 값이 사분위 수를 의미한다.
- box 맨 왼쪽 선 : 1사분위 수
- box 중간선 : 2사분위 수 (중앙값)
- box 맨 오른쪽 선 : 3사분위 수
- 맨 끝 다이아몬드 값 : 이상치 값
-boxplot의 장점 : 사분위 수를 시각화할 수 있다.
-boxplot의 단점 : 박스 안의 값이 바뀌게 되면 박스 안에 있는 분포를 확인하기 어렵다.
-> 이러한 단점을 보완하기 위해 violinplot을 그린다!
4-4. violinplot : 사분위 수 박스와 함께 전체적인 데이터 분포 표현
sns.violinplot(data=df, x="mpg")
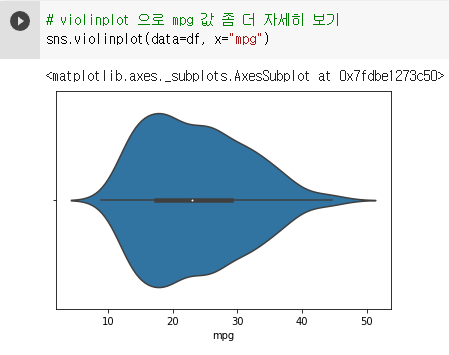
- viloinplot의 윗부분만 따로 그리면 kdeplot의 모양과 비슷하다.
- kdeplot을 마주보고 그린 것이 violinplot이므로 kdeplot보다 violinplot을 그리는 것이 더 좋다.
boxplot과 violinplot으로 전체 변수 시각화하기
sns.boxplot(data=df)
sns.violinplot(data=df)
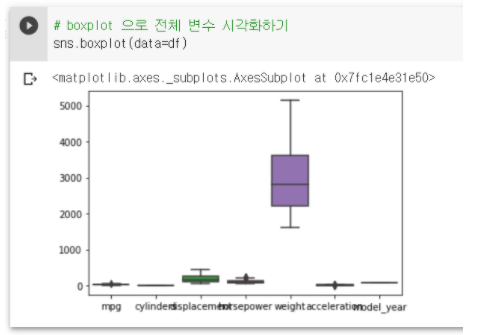
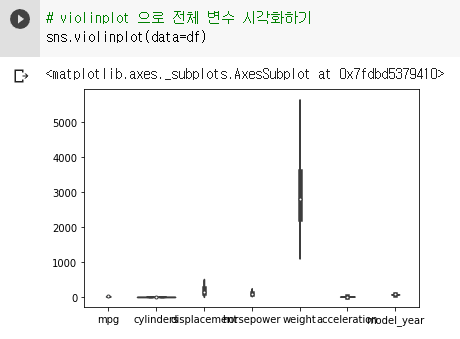
-
weight가 스케일이 너무 커서 다른 데이터들의 그래프가 제대로 그려지지 않는다.
-
이럴 때는 각각의 데이터별로 boxplot, violinplot을 그려 파악하는 것이 좋다.
-
하지만 이렇게 전체 데이터를 시각화했을 때는
각각 데이터 간의 스케일 비교가가능하다는 장점이 있다.
5. 2개 이상의 수치변수 시각화하기
5-1. scatterplot : 산점도 시각화
sns.scatterplot(data=df, x="weight", y="mpg")
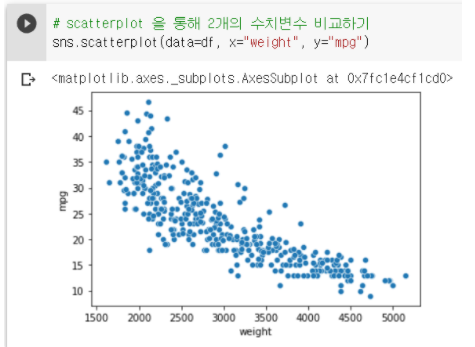
-
분석 : 무게(Weight)가 증가할수록 연비(mpg)는 점점 감소한다.
-
scatterplot 색상 다르게 하기 : hue 옵션 사용
-
hue = origin을 하면 국가별로 색상이 나뉘어 값들이 분류된다.
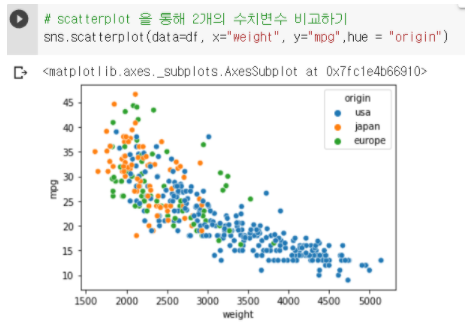
-
미국은 무게가 무거운 차들이 많이 있다.
-
일본은 무게가 가벼운 차들이 많다.
5-2.regplot : 회귀선 시각화
sns.regplot(data=df, x="weight", y="mpg")
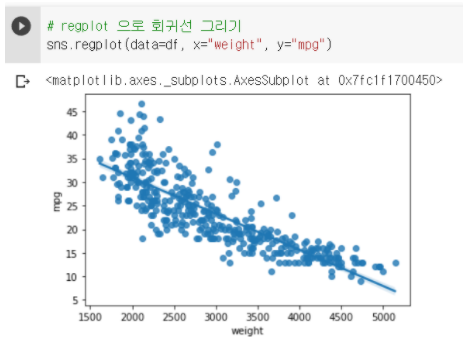
- regplot을 그리면 scatterplot에 회귀선을 추가해서 시각화해준다.
- 회귀선을 그려서 무게가 증가할수록 연비가 감소하는 것을 더 잘 볼 수 있다.
- regplot에는 hue옵션이 없어서 색상을 다르게 그리고 싶으면 lmplot을 사용한다.
5-3.residplot : 변수와 회귀선과의 잔차 시각화
- 회귀선을 기준으로 값들이 얼마나 떨어져 있는지 시각화
(회귀선이 얼마나 정확한지)
sns.residplot(data=df, x="weight", y="mpg")
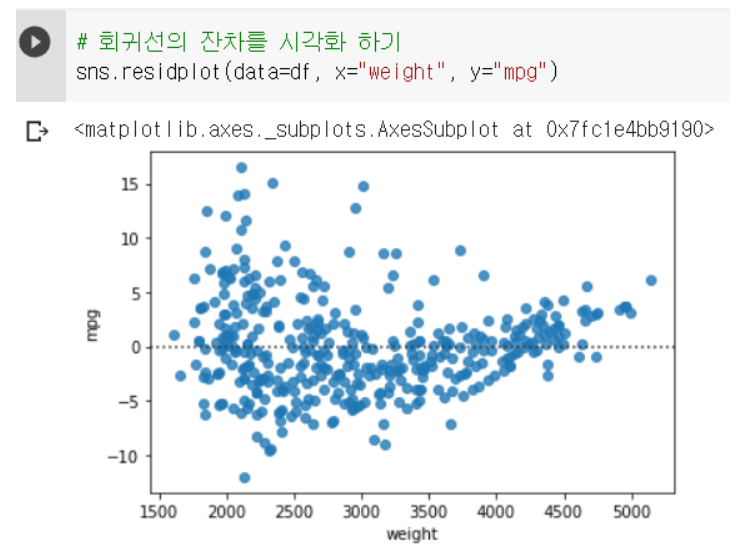
-
점선 : 회귀선으로, 기울어진 회귀선을 수평이 되게 해서
얼마나 값들이 회귀선에 떨어져 있는지 시각화 -
회귀선과 가까운 값들은 거의 0에 수렴한다.
5-4. lmplot : 회귀선 시각화 + 색상별 시각화 + 서브플롯 그리기
- lmplot에 아무 옵션이 없을 때는 regplot과 그래프가 유사하다.
① 색상별로 시각화하기 (hue 옵션 사용)
sns.lmplot(data=df, x="weight", y="mpg", hue="origin")
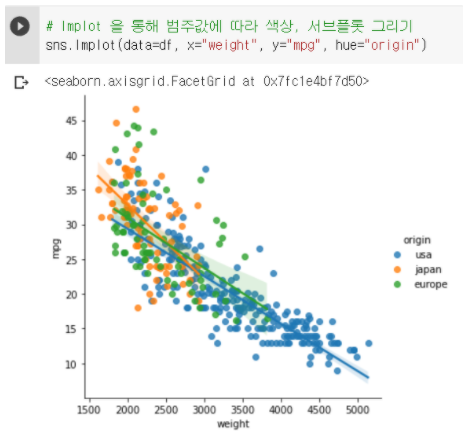
- 국가별로 다른 색상과 회귀선도 각각 그려진다.
② 서브플롯 그리기 (col 옵션 사용)
sns.lmplot(data=df, x="weight", y="mpg", hue="origin", col="origin")
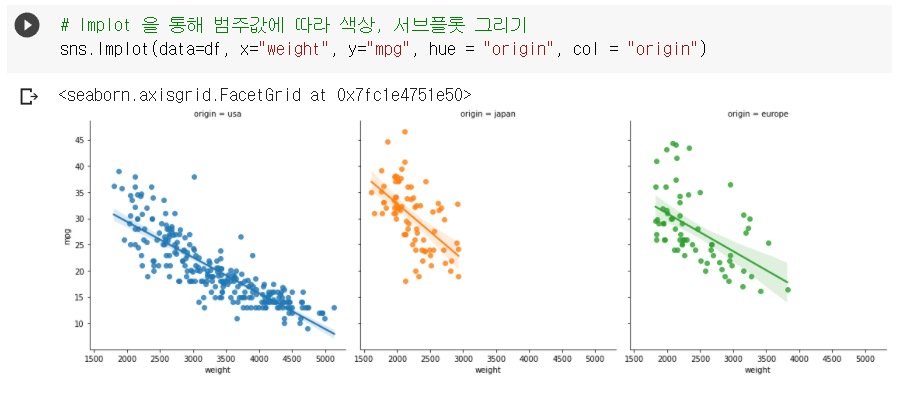
- 서브플롯 : 국가별로 플롯이 다르게 그려짐
∴ lmplot을 사용하면 scatterplot의 회귀선과 색상표현, 서브플롯을 표현할 수 있다.
5-5. jointplot : scatterplot + 히스토그램 시각화
sns.jointplot(data=df, x="weight", y="mpg")
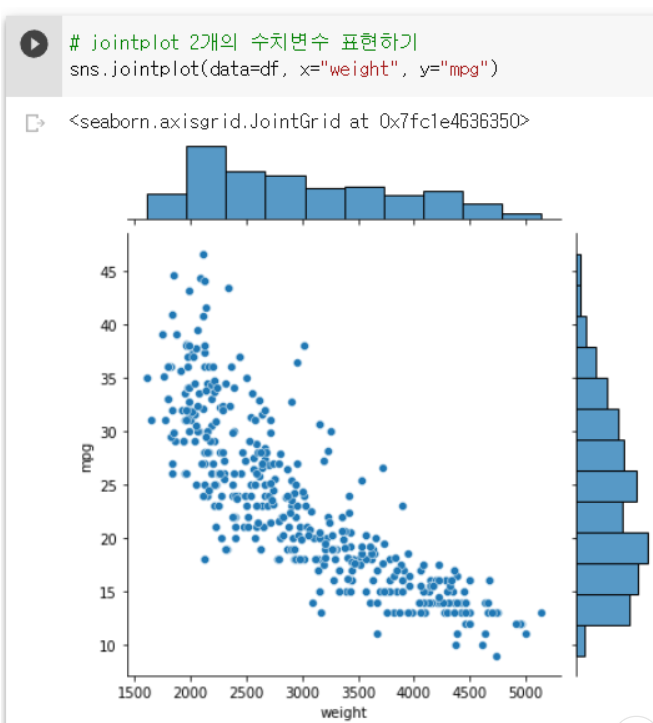
-
scatterplot을 그리고 해당되는 변수의 히스토그램을 같이 그려준다.
-
jointplot에서 kind옵션을 사용하면 그래프를 다르게 그릴 수 있다.
(기본값은 scatterplot)
sns.jointplot(data=df, x="weight", y="mpg", kind="reg")
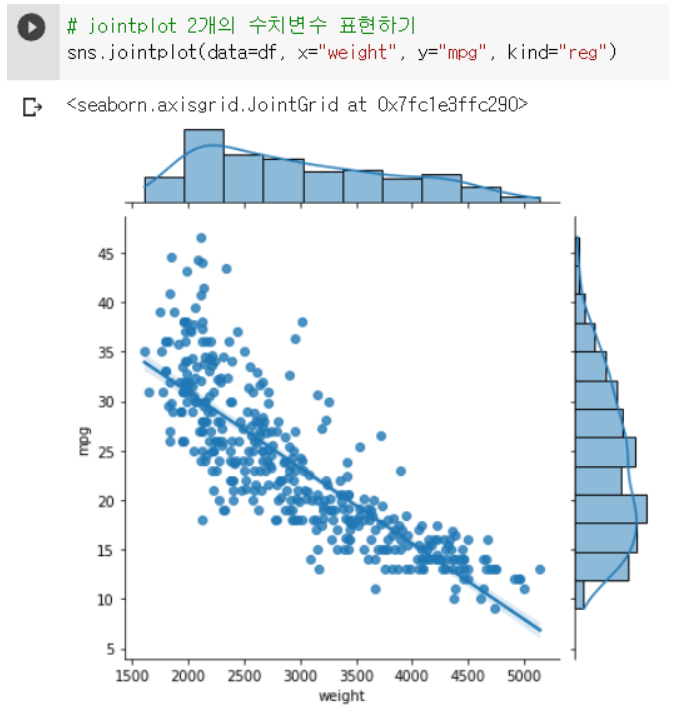
-
jointplot으로 regplot을 그려 회귀선과 히스토그램을 시각화했다.
5-6. pairplot : 모든 수치 데이터에 대해 짝을 지어서 시각화해준다.
- 장점 : 전체적인 수치 데이터에 대해 시각화할 수 있다.
- 단점 : 시간이 오래걸린다 -> 일부 샘플을 추출해서 샘플로 그리기
df_sample = df.sample(100) : 100개만 추출해서 그리기
sns.pairplot(data=df_sample, hue = "origin")
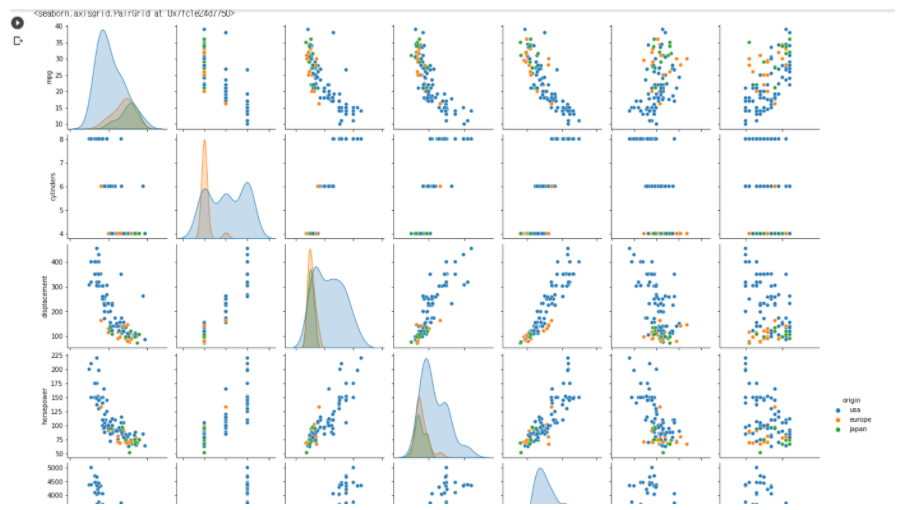
-
cylinder 데이터는 끊어진 데이터라는 것을 알 수 있어서 범주형 데이터에 가깝다.
-
양의 상관관계(기울기가 양수) / 음의 상관관계(기울기가 음수)를 알 수 있다.
-
기울기가 뚜렷하지 않고 상관관계가 명확하지 않은 데이터들도 있다.
* pairplot은 sample을 뽑아서 그린 후 전체 데이터 관계에 대해 파악한 후
자세히 보고 싶은 데이터만 scatterplot 같은 세부 plot으로 그리기!
5-7. lineplot : 선형 그래프 시각화
sns.lineplot(data=df, x="model_year", y="mpg")
-
model_year에 따라 mpg값이 어떻게 변하는지 선형으로 알 수 있다.
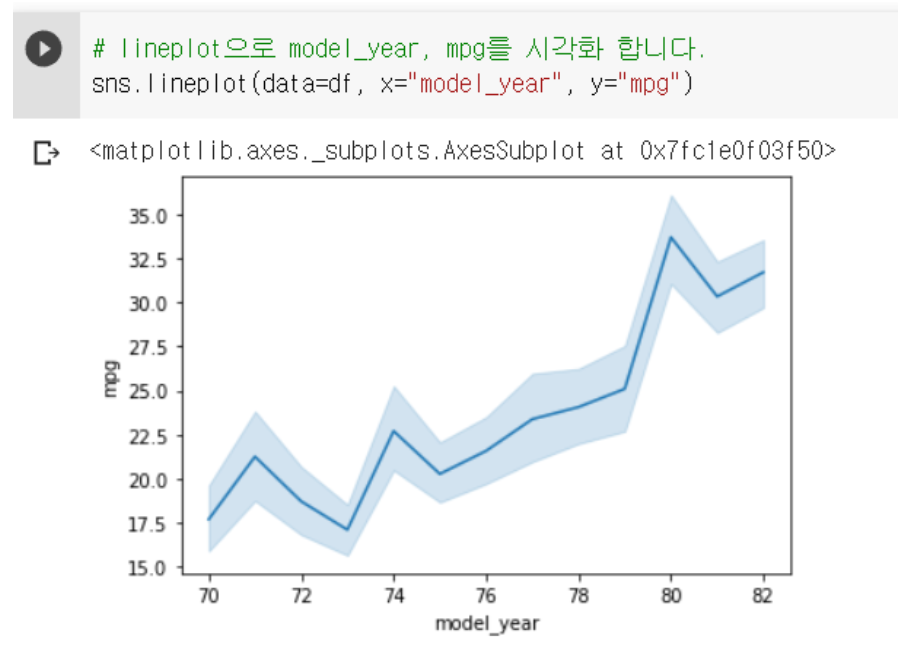
-
lineplot의 그려지는 값의 기본값은 mean(평균)으로, model_year에 따른
mpg의 평균을 그려준다. -
색칠된 영역은 ci로, cofidence interval(신뢰구간)이다.
-
ci는 샘플링을 해서 구하기 때문에 시간이 오래걸려서 없애는 게 좋다.
: ci = None으로 없앨 수 있다.
sns.lineplot(data=df, x="model_year", y="mpg", ci=None)
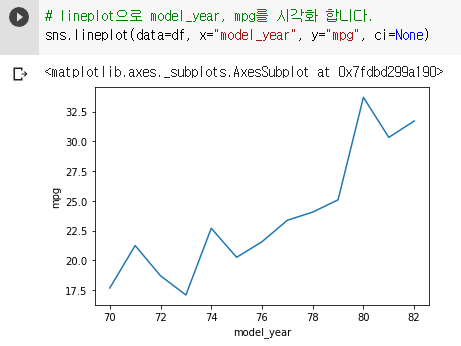
5-8. replot : 수치형 변수에 대한 서브플롯 그릴 때 사용
-
rel : relation의 약자로, 수치 데이터 간의 관계를 표현할 때 쓴다는 의미
-
기본적으로 scatterplot 형태로 표현된다.
sns.relplot(data=df, x="model_year", y="mpg", hue="origin", col="origin")
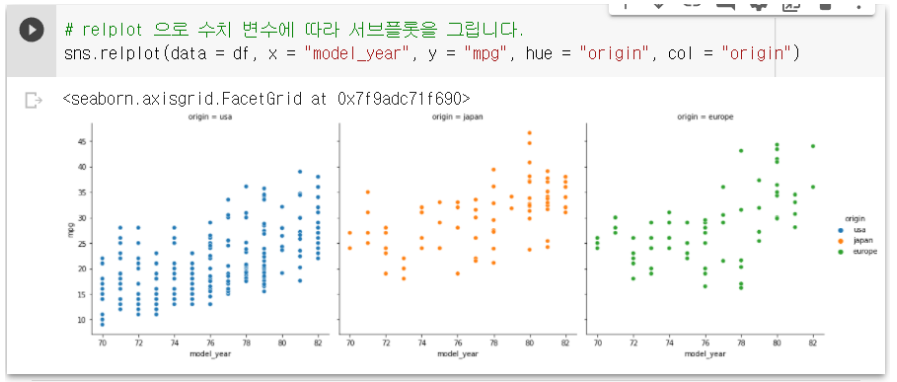
-
이때 kind 옵션을 통해 scatterplot이 아니라 lineplot을 그릴 수 있다.
sns.relplot(data=df, x="model_year", y="mpg", hue="origin", col="origin", kind="line", ci=None)
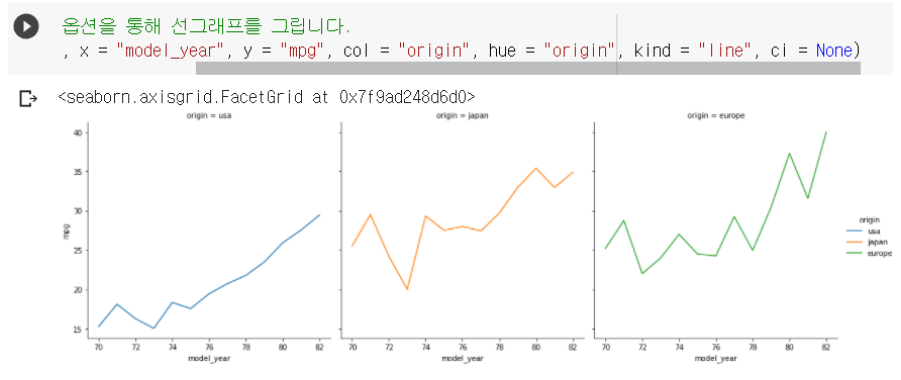
6. 상관분석 / 상관관계
-
두 변수간에 선형적, 비선형적 관계를 갖고 있는지를 분석하는 방법
-
상관관계의 정도를 파악하는 상관계수는 두 변수간의 연관 정도를 나타낼 뿐
인과관계를 설명하는 것은 아니다.
: 인과관계는 회귀분석을 통해 확인할 수 있다.
-
상관계수
- 1에 가까우면 양의 상관관계
- -1에 가까우면 음의 상관관계
- 0에 가까우면 무시될 수 있는 선형관계
- 완전히 동일하면 +1 / 반대방향으로 완전히 동일하면 -1 / 전혀 다르면 0이다.
-
상관계수 구할때 : corr() 사용
df.corr()
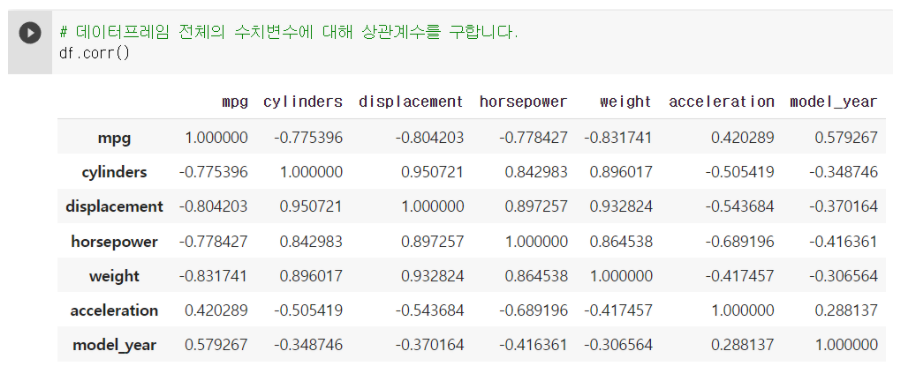
: -1~1 사이의 값을 가진다. 대각선은 자기 자신이므로 1의 값을 가진다.
-
상관계수 시각화할때 : heatmap 사용
: sns.heatmap(df.corr(), annot=True, cmap="coolwarm", vmax=1, vmin=-1)
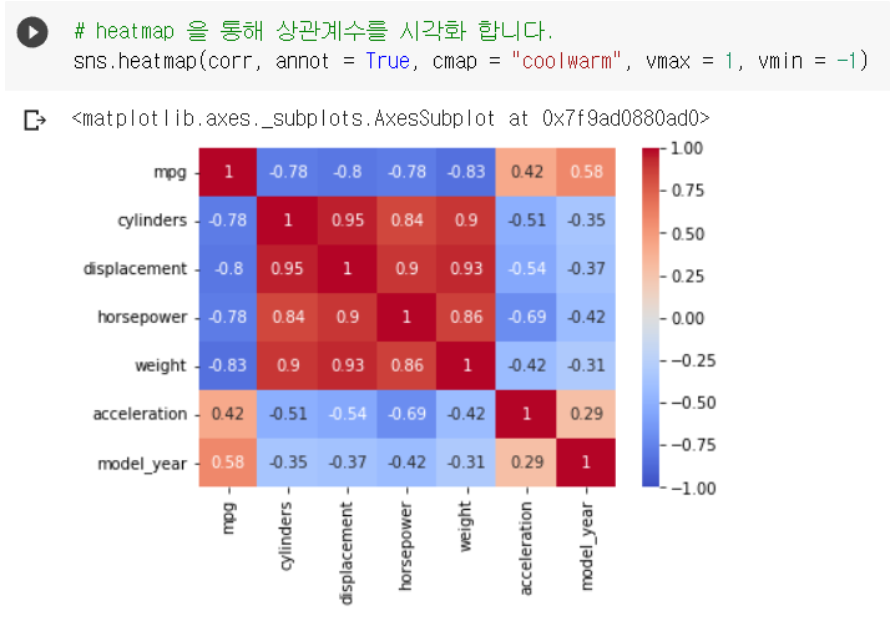
① annot : 값 표시 (False면 네모 안에 값이 표시가 안 된다.)
② cmap : 박스의 색깔 테마 (print(plt.colormaps()) 에서 테마 종류 알 수 있다.)
③ vmax : 맨 오른쪽 막대의 최댓값
④ vmin : 맨 오른쪽 막대의 최솟값
-> 자기 자신의 값도 나오고 대칭되는 값도 나와서 가독성이 떨어진다.
*가독성이 좋은 heatmap 만들기 (mask 옵션 사용)
1. 먼저, 자기 자신인 대각선 값, 대칭되는 값을 지우기 위해 행렬을 만든다.
2. corr = df.corr() 선언
3. np.ones_like(corr)
(np.ones_like(x) : x와 크기만 같은 1로 이루어진 array 생성)
4. mask = np.triu(np.ones_like(corr)) 선언
(np.triu : matrix를 상삼각행렬로 만드는 numpy math : 그림보고 이해하기)
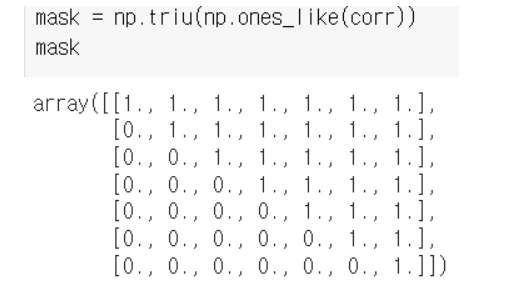
5. heatmap 그릴 때 mask 옵션에 mask 넣기 (mask = mask)
sns.heatmap(corr, annot=True, cmap="coolwarm", vmax=1, vmin=-1, mask = mask)
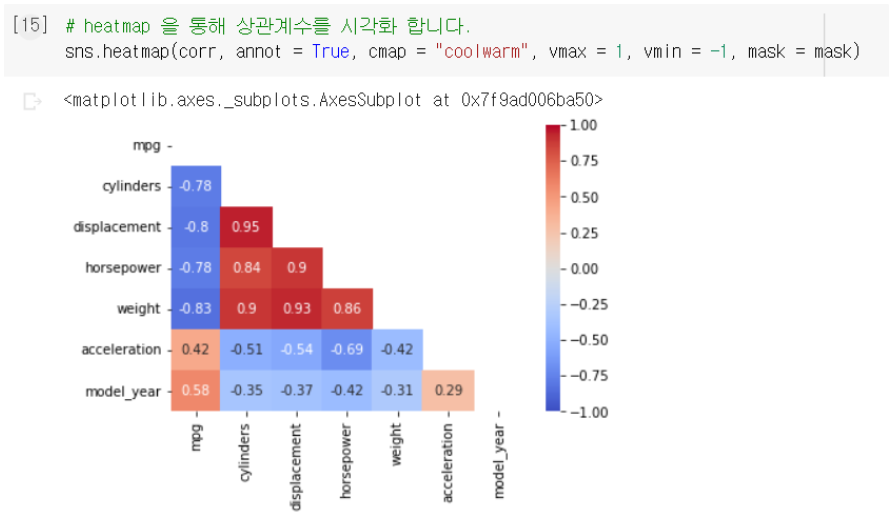
-
자기 자신 값도 없어지고 대칭되는 값도 없어져서 가독성이 좋다.
-
cylinders와 displacement는 0.95로 1에 가까운 상관계수를 가지고 있어서 양의 상관관계를 가진다.
-
weight와 mpg는 -1에 가까운 상관계수를 가지고 있어서
음의 상관관계를 가진다. -
acceleration과 model_year는 0.29로 가장 0에 가까워서 거의 상관이 없다.
