
데이터 분석 도구 사용하기
-
매번 봐야하는 기술 통계값 코드 한 줄로 보기!
!pip install pandas_profiling으로 pandas_profiling을 설치하여
pandas_profiling을 이용하면 된다.from pandas_profiling import ProfileReport
profile = ProfileReport(df, title="Pandas Profiling Report")
이렇게 선언하고 profile을 입력하면 레포트가 나오게 된다.*이때 코랩에서 레포트를 보게되면 보기가 어려워서
html을 만들어서 html로 보는것이 좋다.
profile.to_file("pandas_profile_report.html")
Pandas_profiling을 이용하여 생성한 Report
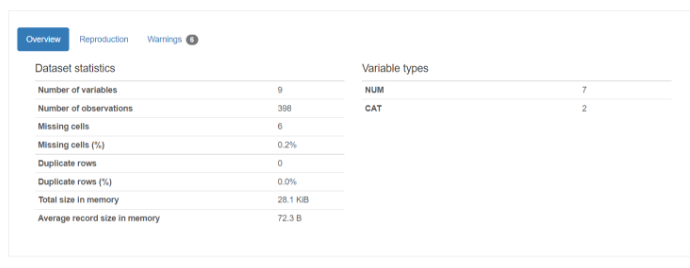
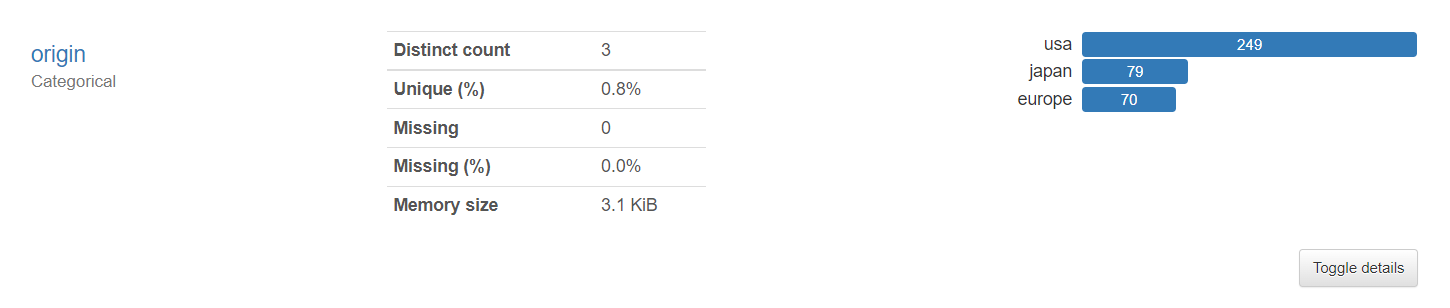
① Overview
-
Overview
1-1. Dataset statistics
-Number of variables : 전체 변수 개수 (열의 개수)
-Number of observations : 관측치의 개수 (행의 개수)
-Missing cells : 결측치 개수
-Missing cells(%) : 결측치 비율
-Duplicate rows : 중복되는 행 개수
-Duplicate rows(%) : 중복되는 행 개수 비율
-Total size in memory : 사용 메모리1-2. Variable types
-NUM : 수치형 데이터 개수
-CAT : 범주형 데이터 개수 -
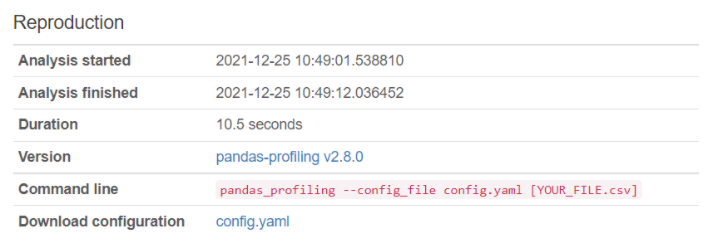
Reproduction : 레포트의 정보 (생성 날짜 등)
-
Warnings : 주의해서 봐야할 점 (그래프의 특징?)
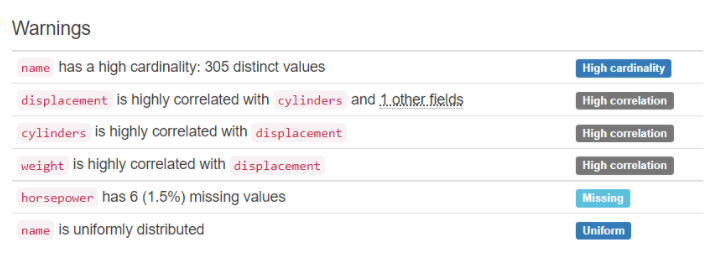
-High cardinality : cardinality(다른 값과의 관계 수)가 높은 것
-> 넓고 얕게?
-High correlation : correlation(다른 값과의 상관관계)가 높은 것
-> 좁고 깊게?
High cardinality, correlation인 데이터는 넓고 깊은 데이터
-Missing : 결측치가 있는 것
-Uniform : 값의 분포가 균일하다 -> 대부분 중복 값 없이 다른 값이 들어있다.
② Variables : 개별 변수별로 요약된 정보
-데이터 유형에 따라 요약 값이 다르다.
- 수치형 데이터인 경우
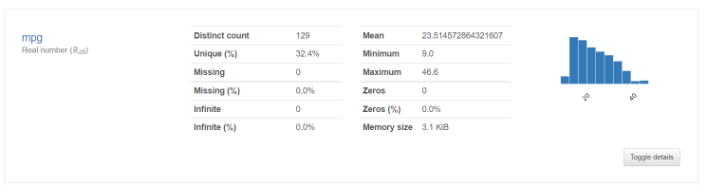
오른쪽 아래 Toggle details를 누르면 상세 요약 정보가 나온다.
2-1. Statistics
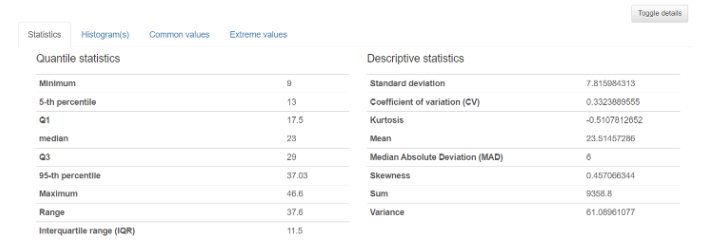
-Q1 : 1사분위 값
-median : 2사분위 값(중앙값)
-Q3 : 3사분위 값
-Standard deviation(std) : 표준편차
-Coefficient of variation(CV) : 표준편차를 평균으로 나눈 수치
-> 계수가 작을수록 평균에 가까이 분포하고 있다.
-Variance : 분산
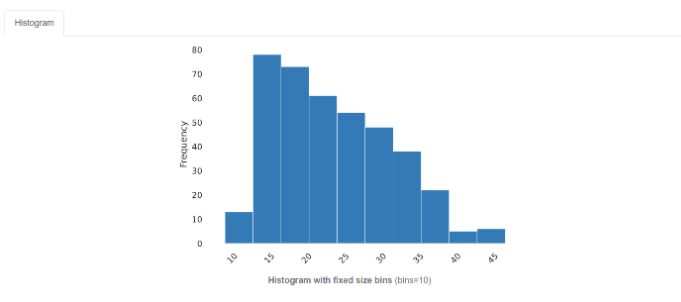
2-2. Histogram : 히스토그램을 보여준다.
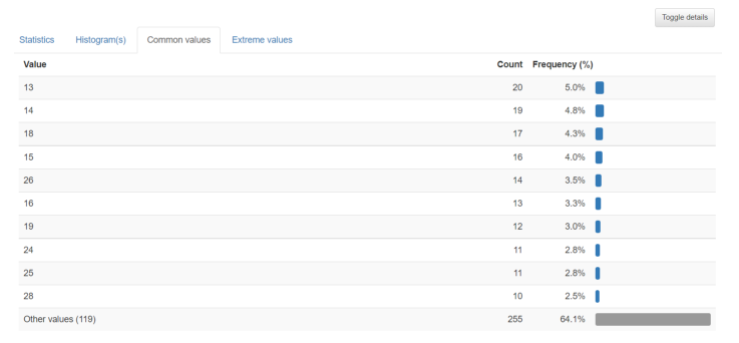
2-3. Common values : 빈도수와 최빈값을 나타내준다.
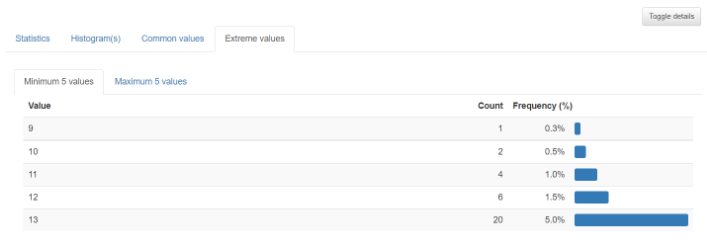
2-4. Extreme values : 이상치 값을 나타내준다. (너무 크거나 너무 작은 값)
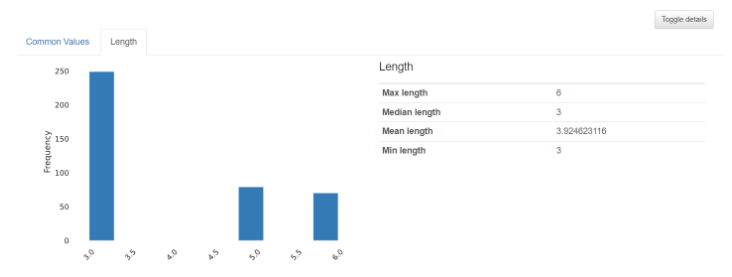
- 수치형 데이터인 경우
: 히스토그램 대신 빈도수를 나타내는 그래프로 나타내고 요약값 종류도 적다.
수치형 데이터와 마찬가지로 오른쪽 아래 Toggle details를 누르면 상세 요약 정보가 나온다.
2-1. Common values : 빈도수와 최빈값을 나타내준다.

2-2. Length : 문자 길이를 그래프로 나타내준다.
③ Interactions
: 두 개의 변수가 어느정도의 상관관계를 가지는지 알려주는 지표
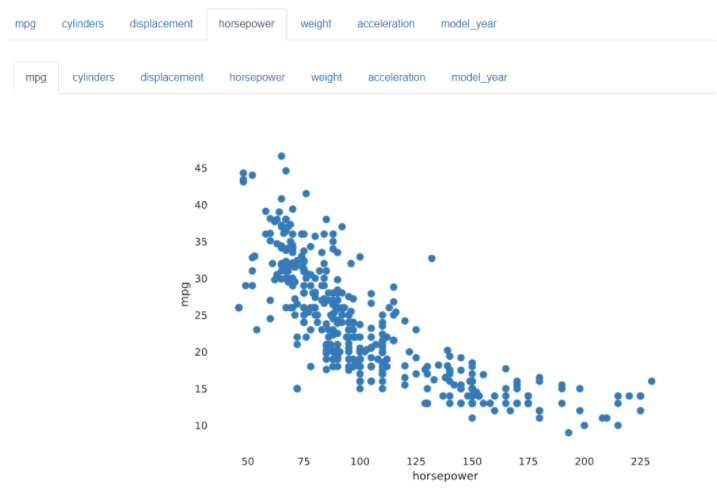
mpg : 연비 / horsepower와의 상관관계
: 우하향 그래프로, horsepower가 증가하면 연비가 떨어진다는 것을 알 수 있다.
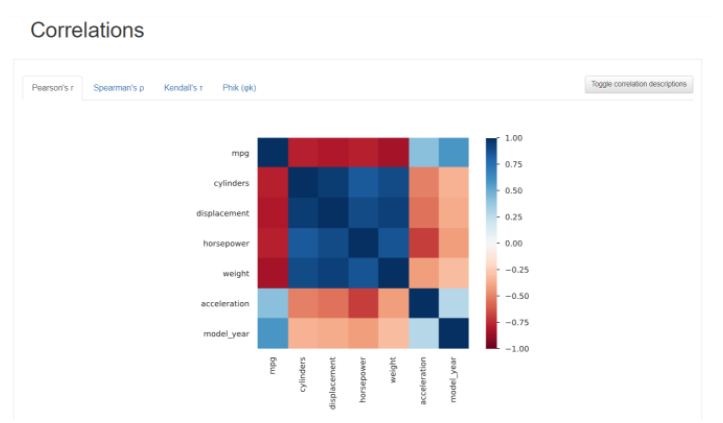
④ Correlations : 변수끼리의 상관계수 지표
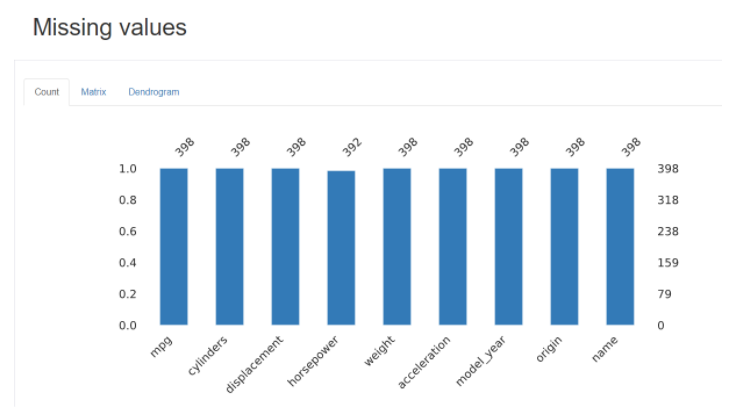
⑤ Missing values : 결측치를 시각화
⑥ Sample : 값들의 예시들을 나열
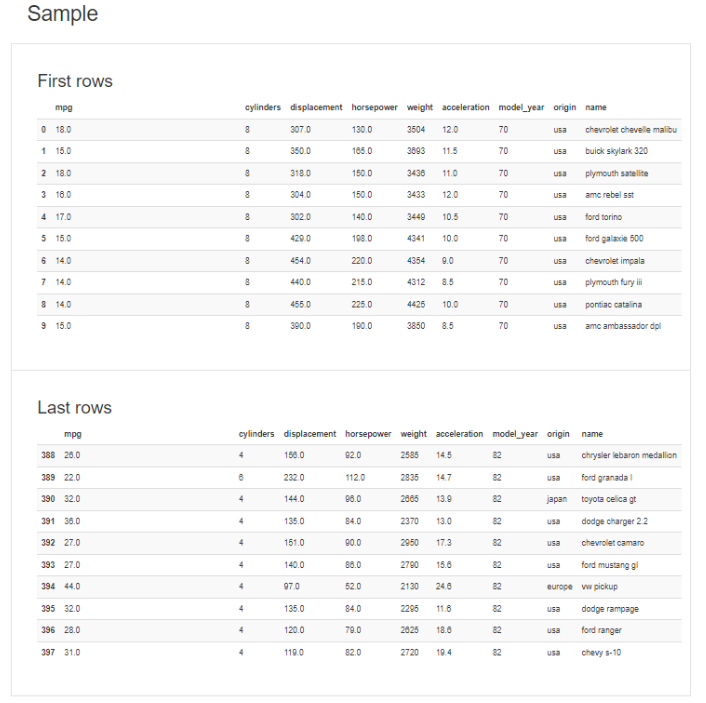
-> head와 tail 함수로 볼 수 있었던 것들을 나열해준다.
추상화된 라이브러리(pandas_profiling, ...) 사용 목적(장/단점)
이렇게 pandas_profiling을 사용하여 데이터의 요약 정보를 보는 것은
데이터가 작을 때, 적당할 때 좋은 방법이다.
라이브러리를 사용하여 큰 데이터를 보게 되면
요약하는 데에(레포트 만드는 데에) 시간이 오래걸린다.
∴ 큰 데이터는 샘플 데이터들로 라이브러리를 사용하여 레포트를 만들어서
전체적인 데이터셋의 흐름만 보는 것이 좋다.
출처 : 네이버 부스트코스 '모두를 위한 데이터 사이언스'
12월 25일에 배웠던 것인데 지금 정리하니 상당히 내용이 새롭게 느껴진다.
처음에 배울 때는 레포트 안의 용어들이 익숙하지 않았었는데
지금 기초를 조금 다 배우고 난 상태로 보니까 좀 익숙해져 있어서 신기했다.
