
데이터 분석 EDA 라이브러리
pandas : 데이터 분석
NumPy : 수치 계산
scikit learn : 머신러닝
Tensorflow / Pytorch : 딥러닝
matplotlib / Seaborn : 데이터 시각화
1. NumPy
-파이썬의 과학 컴퓨팅을 위한 기본 패키지
-계산 속도가 빠르다
2. Pandas
-파이썬의 대표적인 데이터 분석 도구
-파이썬에서 쓸 수 있는 엑셀과 유사한 도구
- pandas의 대표적인 데이터 타입
① DataFrame : 표 형태의 데이터 - 행렬구조(행, 열) / 2차원
② Series : DataFrame에서 하나의 행, 열을 가져왔을 때 Series라 부른다.
-> 벡터구조, 1차원
3. Matplotlib
-파이썬의 대표적인 시각화 도구
-사용법이 복잡하다
4. Seaborn
-Matplotlib를 사용하기 쉽게 만든 것
-통계적인 연산 제공
Pandas 기초와 데이터 요약
1. import를 사용해서 pandas / seaborn 불러오기
import pandas as pd
import seaborn as sns
✔ 엑셀을 사용하여 데이터 분석을 할 수 있는데 pandas를 사용하는 이유?
① 다양한 포맷의 파일들을 pandas를 통해 자유롭게 읽어올 수 있다.
② 엑셀은 데이터를 불러올 수 있는 개수가 제한적이고 속도가 느린 편이다.
③ 파일 용량이 크더라도 빠르게 처리가 가능하다.
2. Seaborn에 내장되어 있는 데이터셋 불러오기
2-1. 직접 불러오기(seaborn 이용)
sns.load_dataset("mpg")
: seaborn에 내장되어 있는 mpg(연비) 데이터셋을 불러오게 된다.
df = sns.load_dataset("mpg")
: 불러온 mpg 데이터셋을 df라는 변수에 저장 (재사용하기 위해)
2-2. pandas로 불러오기
df = pd.read_csv("raw데이터 경로")
: raw데이터 경로를 pandas가 불러오게 되는데 이 데이터셋을 df라는 변수에 저장
-
pandas 데이터 정보 함수 여러가지
① shape : 행과 열의 수를 나타내준다.
: df.shape - mpg.csv(데이터셋)의 행과 열의 수를 나타내준다.
👉 (398, 9) 출력 : mpg 데이터셋의 행은 398, 열은 9② index : index만 보기 (index = 행번호, 행 번호만 보기)
: df.index - mpg 데이터셋의 index의 값을 보여준다.③ columns : columns값만 보기 (columns = 열, 열의 값만 보기)
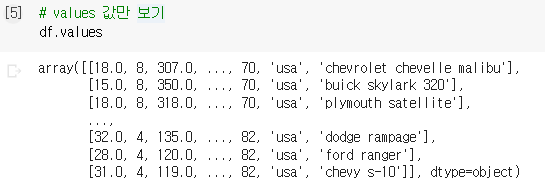
: df.columns - mpg 데이터셋의 columns의 값을 보여준다.④ values : values만 보기 (values = 하나의 행에 해당하는 여러 열의 값들)
: df.values : mpg 데이터셋의 values를 보여준다.
⑤ dtypes : 데이터 타입만 보기
: df.dtypes : mpg 데이터셋의 데이터 타입을 보여준다.
(float : 실수형 / int : 정수형 / object : 범주형)
3.데이터셋 일부만 가져오기
먼저, 전체 가져오는 방법 : sns.load_dataset("mpg")
-> 위에서 df라는 변수에 저장했으므로 df로 가능
3-1. head : 위의 n개 항목만 가져오기
df.head() : 위의 5개 항목 가져오기 (기본값 = 5)
df.head(3) : 위의 3개 항목 가져오기
3-2. tail : 아래의 n개 항목만 가져오기
df.tail() : 아래의 5개 항목 가져오기 (기본값 = 5)
df.tail(2) : 아래의 2개 항목 가져오기
3-3. sample : 랜덤으로 일부 추출
df.sample() : 랜덤 데이터 1개 추출 (기본값 = 1)
df.sample(3) : 랜덤 데이터 3개 추출
- 만일, 값은 처음에 랜덤으로 가져오고 한 번 가져온 값을
똑같이 계속 가져오고 싶을때는?
: df.sample(3, random_state="숫자")
👉random_state 옵션을 쓰게 되면 숫자가 random_state의 숫자가 같을 때
항상 같은 데이터가 나오게 된다. (데이터는 랜덤으로 뽑힌 상태)
4. 요약하기
info 사용
df.info() : 요약정보 보여준다.

👉 index(행번호) / 열 개수 / 열 값 / 데이터 개수 / 데이터 타입 / 메모리 차지
데이터의 개수가 다 398개인데 horsepower만 392개로 결측치가 존재한다는 것을
확인 가능하다.
5. 결측치 확인
info로도 분석하여 결측치를 확인할 수 있지만 더 확실하게 결측치를 확인하는 방법이 있다.
5-1. 결측치 수 확인
isna / isnull로 결측치 확인 가능
df.isna() / df.isnull() : True인 값이 결측치이다.
df.isnull().sum() : df.isnull()에서 출력되는 값들의 합계
df.isnull().sum()을 했을 때 1이상이 나오면
True가 포함된 것이므로 결측치가 있는 열이고, 몇 개가 있는지 알 수 있다.
5-2. 결측치 비율 확인
df.isnull().mean() : 결측치 비율 확인 함수
df.isnull().mean() * 100 : 백분위로 확인 가능
6. 기술통계 확인
describe : 기술통계 확인 함수
df.describe
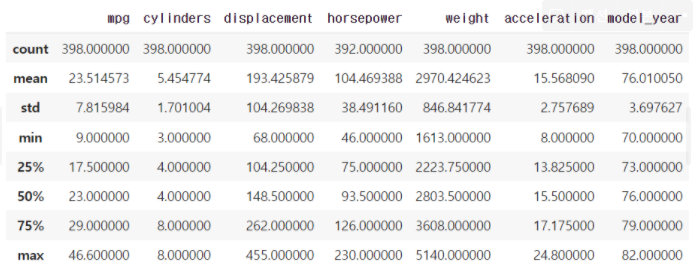
count(빈도수) / mean(평균값) / std(표준편차) / min(최솟값) /
25% / 50% / 75% / max(최댓값) 확인 가능
-> 수치형 데이터만 표현된다. 범주형 데이터(object)는 표현이 안 된다.
- 범주형 데이터에 대해서도 요약을 보고 싶으면 include = "object" 옵션 추가
df.describe(include="object)
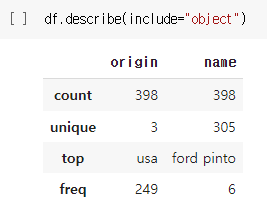
-> 수치형 데이터와 같이 표시되는 것이 아니라 object 값만 따로 표시된다.
수치형 데이터와 지표가 다르다.
: count(빈도수) / unique(중복을 제거한 유일값) /
top(최빈값) / freq(최빈값에 대한 빈도수)
7. Series 만들기 (행 또는 열만 불러오기)
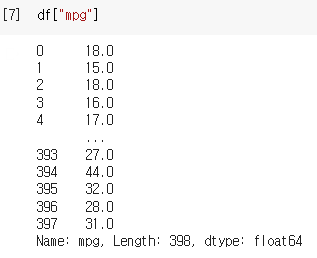
df["mpg"] : mpg 열만 가져오기
df 자체는 DataFrame인데 여기서 df["mpg"]로 열만 가져오게 되면
1차원 형태로 불러와서 구조가 Series가 된다.
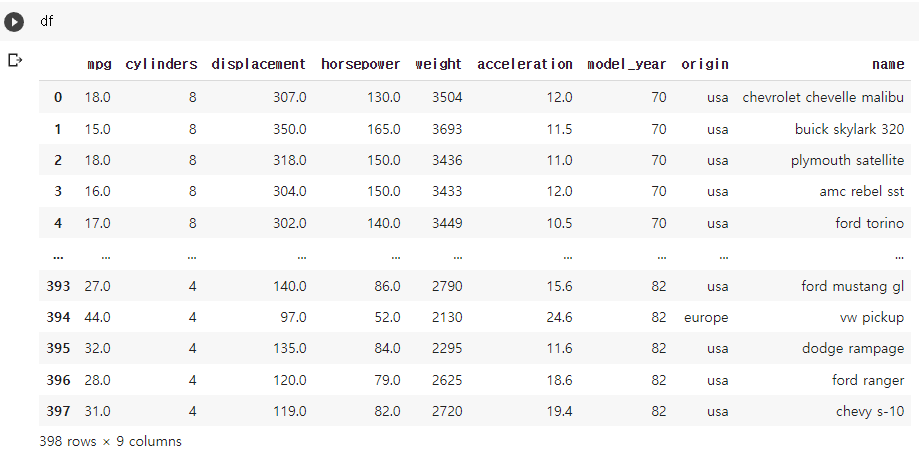
8. DataFrame 만들기 (데이터 전체 출력)
앞쪽에서 했던 것처럼 df로 불러오면 전체 데이터를 불러오게 되는데,
전체 데이터는 행과 열로 이루어져 있어 DataFrame으로 불러오게 된다.
9. 열 색인하기 (가져오고 싶은 열 가져오기)
df["name"] : name 열을 시리즈 형태로 가져오기
df[["name","origin"]] : name열과 origin열 가져오기
여러 개의 열을 가져오고 싶으면 열을 대괄호로 한번 더 묶어줘야한다.
-> df["name","origin"]을 하게 되면 name과 origin을 두 개의 열이 아니라
하나의 열로 인식해서 오류가 나게 된다.
-
대괄호 1개, 2개의 차이
1개의 열을 가져올 때 대괄호 1개 사용 : 시리즈 형태로 가져온다.
2개의 열을 가져올 때 대괄호 2개 사용 : 데이터 프레임 형태로 가져온다.이때, 1개의 열을 가져올 때 대괄호를 2개 사용해서 가져오면
데이터 프레임 형태로 가져올 수 있다!
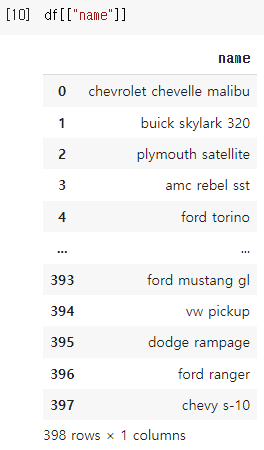
👉열이 "name"열 하나지만 대괄호를 2개 사용하여 데이터 프레임 형태로 출력됨
10. 행 색인하기 (가져오고 싶은 행 가져오기)
loc 함수 사용 (locate 의미)
10-1. 하나의 행 가져올 때
df.loc[0] : 0번째 행을 가져온다는 의미
10-2 . 두 개 이상의 행을 가져올 때
df.loc[0, 1] : 에러 발생
행도 열과 마찬가지로 대괄호를 사용하여 가져와야한다.
👉 df.loc[[0,1]]
-
loc를 사용하여 행, 열 동시에 가져오기
-1쌍의 행, 열 가져오기
df.loc[0,"name"] : 이때는 대괄호를 1개만 써도 된다.-여러 쌍의 행, 열 가져오기
여러 개의 행과 열을 각각 대괄호로 묶고 전체를 대괄호로 묶기
① 두 개의 행, 하나의 열 가져올 때 : df.loc[[0,1], ["name"]]② 두 개의 행, 두 개의 열 가져올 때 : df.loc[[0,1], ["name","origin"]]
