Chapter 2 OpenCV-Python 기초 사용법
- 중요한 문법, 내용만 정리하여 설명. :11월 2일에 다시 모임.
1) 영상의 속성과 픽셀 값 참조
OpenCV 는 영상 데이터를 numpy.ndarray 로 표현
- 영상 데이터를 imread 함수를 통해 불러왔을 때
- ndim : 차원 수. 2차원이면 grayscale, 3차원이면 color 라고 생각해도 무방.
- shape : 각 차원의 크기. (h, w) : grayscale, (h, w, 3) : color 영상
- size : 전체 원소 개수
- dtype : 원소의 데이터 타입. 영상 데이터는 uint8
- imread 함수가 불러오는 데이터 타입은 uint8 이라고 가정해도 무리 없음.
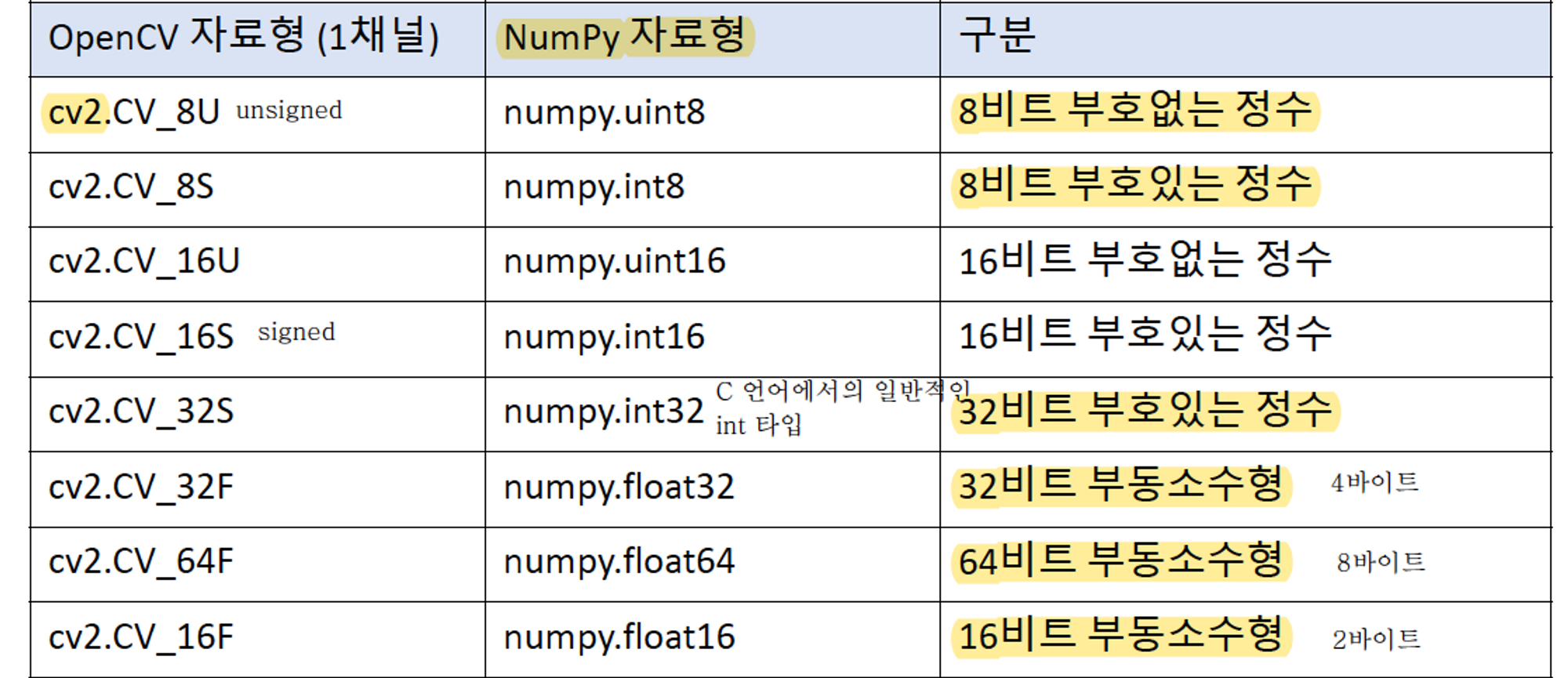
OpenCV 영상 데이터 자료형과 NumPy 자료형
- 간혹가다 opencv 에서 제공하는 함수들 중에서 자료형을 명시적으로 함수의 인자로 받는 경우가 있어서, 그런 경우에는 numpy 에 있는 자료형이 아니라 opencv 에 정의되어 있는 자료형으로 입력을 줘야 함.
- 아래를 보고 알고 있으면 됨.
영상의 속성 참조 예제
- img_info.py
import sys
import cv2
# 영상 불러오기 : imread 함수로
img1 = cv2.imread('cat.bmp', cv2.IMREAD_GRAYSCALE) # grayscale 로
img2 = cv2.imread('cat.bmp', cv2.IMREAD_COLOR) # color 로
if img1 is None or img2 is None:
print('Image load failed!')
sys.exit()
# 영상의 속성 참조
print('type(img1):', type(img1)) # numpy.ndarray 타입.
print('img1.shape:', img1.shape) # shape : (480, 640) : grayscale 로 2차원
print('img2.shape:', img2.shape) # shape : (480, 640, 3) : color 로 3차원
print('img1.dtype:', img1.dtype) # uint8
print('img1.dtype:', img2.dtype) # uint8
# 영상의 크기 참조
'''
shape 값은 (세로, 가로) 순서임. 그래서 보통 변수로 받아서 사용하고 싶은 경우 아래 코드처럼 작성하는데,
print('w x h = {} x {}'.format(w,h))
: 이런 식으로 출력하면, img2 로 받을 때는 오류가 남.
컬러라 3차원인데, 차원 수가 맞지 않아서, 그래서 영상 데이터를 불러와서
세로 크기 가로크기를 h, w 로 받기 위해서는
그냥 shape 이라고 쓰지 않고, img2.shape[:2] 이런 식으로 씀.
'''
h, w = img2.shape[:2] # 영상의 세로, 가로 크기 받아오는 일반적인 방법 기억해두기 !
print('img2 size: {} x {}'.format(w, h))
# 만약, grayscale 인지, color 인지 알고 싶으면 아래 코드로 확인하면 됨.
# if img1.ndim == 2: -> true : grayscale, false : color <- 이 코드도 가능
if len(img1.shape) == 2: # 튜플 값의 길이로도 판별 가능
print('img1 is a grayscale image')
elif len(img1.shape) == 3:
print('img1 is a truecolor image')
cv2.imshow('img1', img1)
cv2.imshow('img2', img2)
cv2.waitKey()
# 영상의 픽셀 값 참조 예제
# 픽셀 값을 참조하는 방법은, x 값을 가져다가 20, y 를 10 이라고 했을 때
# img1[y, x] 라고 하면 img1 dml (x, y) 위치-행렬 기준이므로 반대-의 픽셀값을 알 수 있음.
x = 20
y = 10
p1 = img1[y, x] # 238
p2 = img2[y, x] # [237 242 232] blue, green, red 성분임.
print(p1, p2) # 238 픽셀 값
'''
for y in range(h):
for x in range(w):
# 이런 식으로 대입을 통해 색 값을 정할 수 있음.
img1[y, x] = 255
img2[y, x] = (0, 0, 255)
'''
# 하지만 for 문을 통해 영상 데이터의 색을 변화시키는 작업은 하지 않는게 좋음
# 그 이유는 매우 느리기 때문, 가급적이면 opencv 나 numpy 에서 제공하는 방법을 이용하기.
# C언어는 위의 방법처럼 해도 됨.
# 아래 코드처럼 범위까지 지정해서 모든 픽셀값을 한번에 세팅하는 방법이 더 빠름
img1[:,:] = 255
img2[:,:] = (0, 0, 255)
cv2.imshow('img1', img1)
cv2.imshow('img2', img2)
cv2.waitKey()
cv2.destroyAllWindows()- 중요 정리
- 영상의 속성은 numpy.ndarray 타입이라는 것.
- shape 값은 (세로, 가로) 순이므로 h, w = img2.shape[:2] → 이렇게 작성해주어야 함.
- for 문으로 대입을 통한 색 값 정하기를 할 수 있지만, for 문을 이용해서 데이터의 색을 변화시키는 작업은 시간이 너무 많이 소요되므로 opencv 나 numpy 에서 제공하는 방법을 이용하기.
2) 영상의 생성, 복사, 부분 영상 추출
지정한 크기로 새 영상 생성

- 함수의 인자들
- shape : 각 차원의 크기. (h, w) 또는 (h, w, 3) : grayscale or color
- dtype : 원소의 데이터 타입. 일반적인 영상이면 numpy.uint8 지정
- arr : 생성된 영상 (numpy.ndarray)
- 참고 사항
- numpy.empty() : 임의의 값으로 초기화된 배열 생성 : 새 영상의 픽셀값을 임의의 값으로 세팅
- numpy.zeros() : 0으로 초기화된 배열을 생성
- numpy.ones() : 1로 초기화된 배열을 생성
- numpy.full() : fill_value 인자로 초기화된 배열을 생성 : 새 영상의 픽셀 값을 내가 정하는 값으로 초기화할 수 있는 함수
- img_ops.py
import numpy as np
import cv2
# 새 영상 생성하기
img1 = np.empty((240, 320), dtype=np.uint8)
# grayscale image, 가로 : 320, 세로 : 240인 크기의 영상.
# empty 로 생성했으므로 임의의 픽셀값들로 생성됨.
# 이 함수로 만든 영상 데이터는 모든 픽셀값을 다시 세팅해주는 작업 필요.
img2 = np.zeros((240, 320, 3), dtype=np.uint8)
# color image, 모든 픽셀이 0으로 설정됨
img3 = np.ones((240, 320), dtype=np.uint8) * 255
# dark gray, 모든 픽셀이 1로 채워짐. 곱하기 연산으로 색을 지정할 수 있음.
img4 = np.full((240, 320, 3), (0, 255, 255), dtype=np.uint8)
# yellow, 내가 정하는 픽셀값으로 채우는 함수
cv2.imshow('img1', img1)
cv2.imshow('img2', img2)
cv2.imshow('img3', img3)
cv2.imshow('img4', img4)
cv2.waitKey()
cv2.destroyAllWindows()
# 영상 복사
img1 = cv2.imread('HappyFish.jpg')
img2 = img1 # 이렇게 equal 연산자를 쓰게 되면 img2와 img1 은 똑같은 영상이 됨.
img3 = img1.copy() # 이런 방법도 있음.
# 위의 복사 방법 2가지의 차이는 equal 연산자를 쓰면 img2 가 img1 의 데이터를 공유하는 것.
# 참조와 같은 개념
# img1.copy() 는 변수에 말 그대로 복사를 하는 것.
#img1.fill(255)
cv2.imshow('img1', img1)
cv2.imshow('img2', img2)
cv2.imshow('img3', img3)
cv2.waitKey()
cv2.destroyAllWindows()
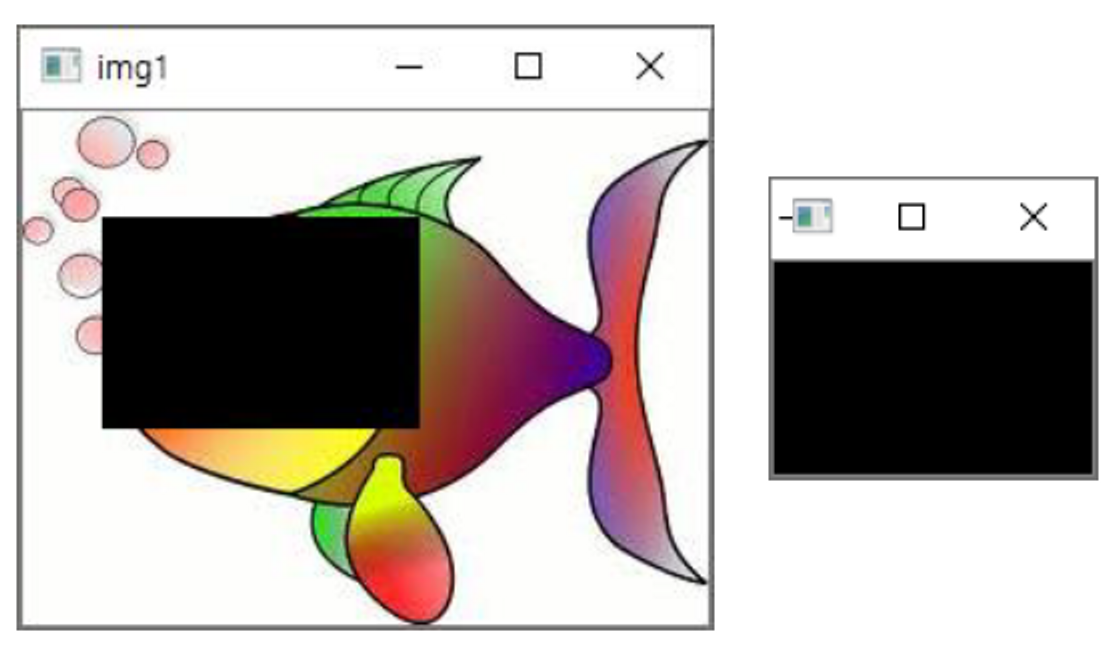
# 부분 영상 추출 : 인덱싱, 슬라이싱 방법을 쓰면 됨
# 예를 들어서 img1 에서 40번째 행부터 120번째 행까지, 30번째 열에서 150번째 열까지, img2 에다 넣고,
# .copy() 와 equal 연산자를 활용했을때, img2 을 가져다가 fill 을 하면 img1 도 함께 fill 됨 : 공유, 참조
# 그래서 인덱싱, 슬라이싱 방법으로 부분 영상을 추출할 때도 .copy() 를 하면 추출이 됨. 공유하는 것이 아님.
img1 = cv2.imread('HappyFish.jpg')
img2 = img1[40:120, 30:150] # numpy.ndarray의 슬라이싱
img3 = img1[40:120, 30:150].copy()
img2.fill(0) # img2 를 fill 했는데, img1 부분 픽셀도 바뀜.
# 이런 방법을 이용해서 영상에서 특정 부분에 대한 ROI(관심영역) 를 지정해서 처리가능
# 예를 들어, opencv 에서의 circle
cv2.circle(img2, (50,50), 20, (0,0,255),2)
cv2.imshow('img1', img1)
cv2.imshow('img2', img2)
cv2.imshow('img3', img3)
cv2.waitKey()
cv2.destroyAllWindows()- 중요 정리
- 복사 : '=' (euqal) 연산자 이용 방법과, .copy() 방법이 존재
- '=' (euqal) 연산자 이용 방법 : 복사한 데이터와 복사 대상인 데이터가 데이터를 공유하는 것임. 참조와 같은 개념
- .copy() : 참조와 같은 개념이 아닌, 복사해서 새롭게 생성한 변수에 넣는 것. 데이터를 공유하지 않음.
- 부분 영상 추출 : 인덱싱, 슬라이싱 방법 사용
-
이때도, .copy() 방법을 사용해야 함. 안 그럼 추출한 데이터를 수정하면, 원본 데이터도 추출된 위치가 수정됨.
-
- 복사 : '=' (euqal) 연산자 이용 방법과, .copy() 방법이 존재
3) 마스크 연산과 ROI
ROI
- Region of Interest, 관심 영역을 의미
- 영상에서 특정 연산을 수행하고자 하는 임의의 부분 영역을 뜻함.
마스크 연산
- OpenCV 는 일부 함수에 대해 ROI 연산을 지원하며, 이때 마스크 영상을 인자로 함께 전달 필수
- 마스크 영상은 grayscale 영상임.
- 마스크 영상의 픽셀 값이 0이 아닌 위치에서만 연산이 수행됨. → 보통 마스크 영상으로는 0 or 255 로 구성된 이진 영상을 사용함. → 0이 아닌 위치에서만 연산이 수행된다고 했을 때, 1에서 연산이 수행되면 0과 구분하기 어려운 문제 존재
마스크 연산을 지원하는 픽셀 값 복사 함수

- copyTo 라는 함수는 복사하는 함수
- 이 함수는 mask 인자를 지원하기 때문에 영상의 픽셀 값의 전체를 복사하는 것이 아니라 mask 영상에서 흰 색으로 되어 있는 일부분만 복사하는 기능 제공
- 인자 설명
- src : 입력 영상
- mask : 마스크 영상. grayscale 의 마스크 영상 : 0이 아닌 픽셀에 대해서만 복사 연산 수행
- dst : 출력 영상. 만약 src 와 크기 및 타입이 같은 dst 를 입력으로 지정하면 dst 를 새로 생성하지 않고 연산을 수행. 그렇지 않으면 dst 를 새로 생성하여 연산을 수행한 후 반환함.
- dst 는 출력 영상인데, dst 는 리턴으로 받는 dst 도 있고, 인자로 받는 dst 도 있음. 근데 마스크 연산을 이용해서 일부분만 copy 하려면 dst 를 입력이자 출력의 형태로 같이 동작해야 함. 그래서 인자로서의 dst 를 주게 되면, 입력과 출력의 역할을 모두 하게 됨.
- mask_op.py
import sys
import cv2
# 마스크 영상을 이용한 영상 합성
# 지금 작업하고 싶은 것은 src 내용에서 비행기 부분만 잘라내서 dst 부분에다가 붙여넣고 싶은 것.(합성)
# 그럼 src 부분에서 mask 에 흰 색으로 되어 있는 부분만 복사해서 dst 에 합성하고 싶은 것.
src = cv2.imread('airplane.bmp', cv2.IMREAD_COLOR)
mask = cv2.imread('mask_plane.bmp', cv2.IMREAD_GRAYSCALE)
dst = cv2.imread('field.bmp', cv2.IMREAD_COLOR)
if src is None or mask is None or dst is None:
print('Image load failed!')
sys.exit()
# src 영상에서 mask 부분을 이용해서 dst 를 만들고 싶은 것.
cv2.copyTo(src, mask, dst)
'''
그런데 이 dst 를 copyTo 함수의 리턴이 되기 때문에 아래 코드처럼 작성하면 안된다는 의미
dst = cv2.copyTo(src, mask) : background 가 검정이 됨.
꼭 입력에다가 dst 를 줘야 함.
그리고 src, mask, dst 는 모두 size 도 같아야 하고, src 와 dst 는 타입도 같아야 함.
src 가 그레이스케일이면 dst 도 그레이 스케일이어야 함.
mask 는 언제나 그레이 스케일
'''
'''
# 아래 방법은 위의 코드를 numpy 에서 제공하는 불리언 인덱싱 방법임.
dst[mask > 0] = src[mask > 0]
: dst 에서 mask 픽셀값이 0보다 큰 값을 다 찾고, src 영상에서도 mask 값이 0보다 큰 값을 다 찾음
mask > 0 : 이 연산의 결과는 mask 행렬과 동일한 크기로 생성되는데, boolean 값, true or false 행렬이 반환이 됨.
그 행렬을 src 행렬에 대해서 인덱싱 하게 되면, true 가 되어 있는 픽셀만 가져올 수 있음.
그리고 그 픽셀값을 동일하게 dst 에다 세팅을 하는 것.
참조 형태로 복사하는 것.
'''
cv2.imshow('src', src)
cv2.imshow('dst', dst)
cv2.imshow('mask', mask)
cv2.waitKey()
cv2.destroyAllWindows()
# 알파 채널을 마스크 영상으로 이용
# 이런 마스크 영상을 이용한 copy 기능을 이용해서 이번에는 간단하게 투명한 png 파일을 불러와서 다른 영상에 합성하는 것을 해볼 것
src = cv2.imread('cat.bmp', cv2.IMREAD_COLOR)
logo = cv2.imread('opencv-logo-white.png', cv2.IMREAD_UNCHANGED)
# 채널이 4개짜리로 되어 있는 거라서 이를 opencv 로 불러와서 사용하려면 imread unchanged 라고 하는 플래그로 불러와야 함.
# logo 영상에서 앞의 채널 3개는 color 값이고, 마지막 채널 하나는 마스크 영상 형태로 사용할 수 있음.
if src is None or logo is None:
print('Image load failed!')
sys.exit()
mask = logo[:, :, -1]
# mask는 알파 채널로 만든 마스크 영상 : 알파 채널에서 마지막 부분만 가져와서 사용
logo = logo[:, :, :3]
# logo는 b, g, r 3채널로 구성된 컬러 영상 : 0,1,2 채널만 가져와서 쓸 것
h, w = mask.shape[:2]
crop = src[10:10+h, 10:10+w]
# logo, mask와 같은 크기의 부분 영상 추출 : 이 코드에서 crop 을 변경하면 src 도 변경됨.
cv2.copyTo(logo, mask, crop)
# 크기가 맞지 않아서, 그냥 dst 를 쓰면 안됨. dst 에서 일부분을 crop 해야 함.
#crop[mask > 0] = logo[mask > 0]
cv2.imshow('src', src)
cv2.imshow('logo', logo)
cv2.imshow('mask', mask)
cv2.waitKey()
cv2.destroyAllWindows()- 중요 정리
- 마스크 영상을 이용한 영상 합성에는 2가지 방법 존재 (cv2.copyTo or numpy 불리언 인덱싱)
- cv2.copyTo : 꼭 입력에다가 dst 를 줘야 함. → src, mask, dst 는 모두 size 도 같아야 하고, src 와 dst 는 타입도 같아야 함.
src 가 grayscale이면 dst 도 grayscale
- numpy 불리언 인덱싱 → dst 에서 mask 픽셀값이 0보다 큰 값을 다 찾고, src 영상에서도 mask 값이 0보다 큰 값을 다 찾음 → mask > 0 : 이 연산의 결과는 mask 행렬과 동일한 크기로 생성되는데, boolean 값, true or false 행렬이 반환이 됨. → 그 행렬을 src 행렬에 대해서 인덱싱 하게 되면, true 가 되어 있는 픽셀만 가져올 수 있음. → 그리고 그 픽셀값을 동일하게 dst 에다 세팅을 하는 것, 참조 형태로 복사하는 것.
- cv2.copyTo : 꼭 입력에다가 dst 를 줘야 함. → src, mask, dst 는 모두 size 도 같아야 하고, src 와 dst 는 타입도 같아야 함.
- 마스크 영상을 이용한 영상 합성에는 2가지 방법 존재 (cv2.copyTo or numpy 불리언 인덱싱)
4) OpenCV 그리기 함수
OpenCV 그리기 함수
- OpenCV 는 영상에 선, 도형, 문자열을 출력하는 그리기 함수를 제공
- 선 그리기 : 직선, 화살표, 마커 등
- 도형 그리기 : 사각형, 원, 타원, 다각형 등
- 문자열 출력
그리기 함수 사용 시 주의할 점
- 그리기 알고리즘을 이용하여 영상의 픽셀 값 자체를 변경하는 것. → 원본 영상이 필요할 시 복사본 생성하여 그리기, 출력
- 그레이스케일 영상에는 color 로 그리기 안됨. → cv2.cvtColor() 함수로 BGR 컬러 영상으로 변환 후 그리기 함수 호출
직선 그리기

- 인자 설명
- img : 그림을 그릴 영상, 입력이자 출력
- pt1, pt2 : 직선의 시작점과 끝점. (x,y) 튜플
- color : 선 색상 또는 밝기. (B, G, R) 튜플 또는 정수값.
- thickness : 선 두께. 기본 값은 1
- lineType : 선 타입. 3 가지 종류 존재
- shift : 그리기 좌표 값의 축소 비율. 기본 값은 0
사각형 그리기

- 첫 번째 함수 : 사각형의 대각선에 위치해 있는 두 꼭지점 좌표를 입력하게 되어 있음. 보통 pt1 에는 좌측 상단 점의 좌표, pt2 에는 우측 하단 점의 좌표를 입력. 나머지 인자는 line 함수와 비슷
- 두 번째 함수 : rec 인자가 사각형을 표현하도록 되어 있는데 rec 같은 경우는 사각형의 좌측 상단의 좌표, 사각형의 세로, 가로 크기가 들어 있는 4개의 정수값으로 구성되어 있는 튜플임.
- 인자 설명
- img : 그림을 그릴 영상
- pt1, pt2 : 사각형의 두 꼭지점 좌표. (x,y) 튜플
- rec : 사각형 위치 정보 (x,y,w,h) 튜플
- thickness : 음수(-1)를 지정하면 내부를 채움 : line 에서는 불가능
- 나머지는 앞의 line 과 유사하므로 생략
원 그리기

- 인자 설명
- center : 원의 중심 좌표. (x,y) 튜플.
- radius : 원의 반지름
- thickness : 음수(-1)를 지정하면 내부를 채움
- 나머지는 앞에서 설명했으므로 생략
다각형 그리기

- 인자 설명
- pts : 다각형 외곽 점들의 좌표 배열. numpy.ndarray 리스트 → 이 함수는 꼭지점 좌표를 입력으로 주면 되는데, 보통 꼭지점 좌표는 Numpy 의 ndarray 를 리스트 형태로 감싸서 주는 것.
- isClosed : 폐곡선 여부. True or False : True 를 주면 시작점과 끝점을 이어주고, false 를 주면 시작점 끝점 잇지 않음.
- pts : 다각형 외곽 점들의 좌표 배열. numpy.ndarray 리스트 → 이 함수는 꼭지점 좌표를 입력으로 주면 되는데, 보통 꼭지점 좌표는 Numpy 의 ndarray 를 리스트 형태로 감싸서 주는 것.
문자열 출력

- 인자 설명
- text : 출력할 문자열
- org : 영상에서 문자열을 출력할 위치의 좌측 하단 좌표. (x,y) 튜플
- fontFace : 폰트 종류.
- fontScale : 폰트 크기
- bottomLeftOrigin : True 이면 영상의 좌측 하단을 원점으로 간주. 기본값은 False
- drawing.py
import numpy as np
import cv2
# 컬러 영상을 하나 만들기, 흰색으로 채워져 있는 것.
img = np.full((400, 400, 3), 255, np.uint8)
# 직선 그리기
cv2.line(img, (50, 50), (200, 50), (0, 0, 255), 5)
# (x, y) 좌표 순서임. 즉, 가로로 150 픽셀 정도의 직선을 그리는 것, 색은 빨간색, 선 두께는 5픽셀
cv2.line(img, (50, 60), (150, 160), (0, 0, 128))
# 검 붉은 색으로 그림을 그리고 45도 아래로 그리는 형태
# 사각형 그리기
cv2.rectangle(img, (50, 200, 150, 100), (0, 255, 0), 2)
# 사각형의 좌측 상단의 좌표와 사각형의 width, hight를 제공
cv2.rectangle(img, (70, 220), (180, 280), (0, 128, 0), -1)
# 사각형의 대각성에 위치해 있는 두 꼭지점의 좌표, thinkness 를 음수로 지정하면 내부를 채우게 됨.
# 원 그리기
cv2.circle(img, (300, 100), 30, (255, 255, 0), -1, cv2.LINE_AA)
# -1 이므로 내부를 채우는 형태. 그 뒤에 lineType 은 기본 값은 8 인데,
# 이대로 설정하고 그림을 그리면 선이 거친 느낌이 있음.
cv2.circle(img, (300, 100), 60, (255, 0, 0), 3, cv2.LINE_AA)
# 다각형 그리기
pts = np.array([[250, 200], [300, 200], [350, 300], [250, 300]])
# 이 지정 방식 기억하기
# 일단, 이 pts 라고 하는 것은 네 개의 점을 2차원 행렬, numpy ndarray 형태로 만들고
# 그 다음에 이 것을 함수에 입력할 때 그냥 pts 로 입력하는 것이 아니라 [pts] 이렇게 리스트 형태로 감싸서 입력을 해야 함.
cv2.polylines(img, [pts], True, (255, 0, 255), 2)
# 대각선으로 뻗어나가는 형태의 다각형도 linetype 을 AA 로 설정하는 것이 좋음.
# 문자열 출력
text = 'Hello? OpenCV ' + cv2.__version__ # 문자열 데이터 생성
cv2.putText(img, text, (50, 350), cv2.FONT_HERSHEY_SIMPLEX, 0.8,
(0, 0, 255), 1, cv2.LINE_AA) # 문자열 출력도 AA 를 쓰는 것을 추천
cv2.imshow("img", img)
cv2.waitKey()
cv2.destroyAllWindows()- 중요 정리
- 다각형 그리기에서 pts 라고 하는 것은 네 개의 점을 2차원 행렬, numpy ndarray 형태로 만들고 그 다음에 이를 함수에 입력 시 그냥 pts 라고 입력하는 것이 아니라 [pts] 이렇게 리스트 형태로 감싸서 입력.
- 대각선으로 뻗어나가는 등의 형태의 도형이나 문자열을 그릴 때는 linetype 을 AA 로 설정하는 것이 좋음.
5) 카메라와 동영상 처리하기 1
cv2.VideoCapture 클래스
- OpenCV 에서는 카메라와 동영상으로부터 프레임(frame)을 받아오는 작업을 cv2.VideoCapture 클래스 하나로 처리함. → opencv 에서 카메라와 동영상을 다룰 때, VideoCapture 클래스 하나를 이용하여 둘 다 동시에 컨트롤 함. → open() 함수로 카메라 열기, 동영상 파일 열기를 수행. read() 함수로 현재 프레임을 받아오는 작업 등 다양한 함수 존재.
카메라 열기
- 카메라와 동영상 파일을 모두 다 open 이라는 기본 함수를 이용해서 사용하게 되는데, 일단 VideoCapture 라는 하나의 객체를 만들고 open 함수를 호출하는데, 카메라를 열 때는 정수값이 들어가고, 동영상 파일을 열 때는 파일 이름이 들어감.

- 인자 설명
- index : camera_id + domain_offset_id → index 는 정수 값인데, 이 정수값은 기본적으로 0으로 시작하는 값. → 시스템 기본 카메라를 기본 방법으로 열려면 index에 0을 전달
- apiPreference : 선호하는 카메라 처리 방법 지정
- retval : cv2.VideoCapture 객체
- index : camera_id + domain_offset_id → index 는 정수 값인데, 이 정수값은 기본적으로 0으로 시작하는 값. → 시스템 기본 카메라를 기본 방법으로 열려면 index에 0을 전달

- retval : 성공하면 True, 실패하면 False
동영상, 정지 영상 시퀀스, 비디오 스트림 열기

- 동영상 파일을 다루는 방법은 camera 처리에서 정수값이 아닌 filename 만 넘겨주면 됨.

- retval : 성공하면 True, 실패하면 False
비디오 캡쳐가 준비되었는지 확인

- 카메라, 비디오 파일 등이 정상적으로 열렸는지 체크 : True or False
프레임 받아오기

- 리턴으로 retval, image 리턴 됨
- retval : 성공하면 True, 실패 시 False
- image : 현재 프레임 (numpy.ndarray)
카메라, 비디오 장치 속성 값 참조 : 코드에서 자세히 설명
카메라 처리 예제
- camera_in.py
import sys
import cv2
# 카메라 열기, 클래스 객체 생성
cap = cv2.VideoCapture(0) # 아래의 open 함수를 열지 않아도 생성자 함수로 열 수 있음.
#cap.open(0)
# open 을 하고 나서는 cap.isOpend 를 통해 정상적으로 열렸는지 확인하는 것이 좋음.
if not cap.isOpened():
print("Camera open failed!")
sys.exit()
# 카메라 프레임 크기 출력, 카메라 프레임 크기를 알고 싶으면 이런 함수를 사용해서 알아볼 수 있음.
# 이 get 함수에는 다양한 속성 값 존재 ppt 참고
print('Frame width:', int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))) # 가로 크기
print('Frame height:', int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))) # 세로 크기
# 다만, 이 get 이라는 함수가 리턴하는 타입이 무조건 실수형 double 타입으로 리턴을 해주기 때문에
# int 타입으로 변환해서 변수에 대입하는 게 좋은 경우도 있음.
# set 함수로 카메라 프레임의 크기를 설정할 수 있지만, 카메라와 호환이 되어야 함.
# cap.set(cv2.CAP_PROP_FRAME_WIDTH, 640)
# 카메라 프레임 처리 : while 문으로 프레임을 계속 받아오는 작업
while True:
ret, frame = cap.read() # 프레임을 받아오는 함수. 기억하기 !
# 이 read() 함수에서 중요한 것은 리턴되는 형식임.
# 이 함수는 현재 프레임을 그대로 반환하는 것이 아니라 현재 프레임을 제대로 받아왔는지를 확인하는 boolean 타입의 값도 같이 리턴해줌.
# 그래서 이 함수를 하나의 변수로만 받게 되면 그 변수에는 ndarray 가 저장되는 것이 아니라 true or false 값이 저장됨.
# 그래서 이 함수를 받아올 때는 변수 두 개로 받아와야 함.
if not ret: # ret 가 false 면 break 되도록
break
# 이 부분부터는 동영상에서 프레임을 받아오고, frame 변수에 들어간 상태임
# 그럼 여기서 frame 이라는 정지영상을 처리하는 코드를 작성할 수 있음.
# 예를 들어, 동영상에서 윤곽선을 추출하는 함수 중 canny 함수가 있음 : 나중에 배울 것
edge = cv2.Canny(frame, 50, 150)
# inversed = ~frame # 반전
cv2.imshow('frame', frame) # 프레임을 화면에 보이는 함수
cv2.imshow('edge', edge)
# cv2.imshow('inversed', inversed)
if cv2.waitKey(10) == 27:
# 앞에서는 정지 영상 출력할 때는 waitkey 함수에 인자를 주지 않았지만, 여기서는 줘야 함.
# 10초 기다리고, 그 다음에 다음 프레임을 받아오도록 설정하는 것임.
# 근데 코드를 if 를 쓰지 않고 그냥 작성하게 되면
# while 을 빠져나올 방법이 없기 때문에 if 문을 통해 waitKey 가
# 반환한 값이 27일 경우에 (ESC 키를 눌렀을 때)
# break 를 통해 빠져나오는 것.
break
# 빠져나온 다음에는 cap 을 release 하고
cap.release()
cv2.destroyAllWindows() # 모든 창 닫기- 중요 정리
- ret, frame = cap.read() # 프레임을 받아오는 함수. 기억하기 ! → 이 함수는 현재 프레임을 그대로 반환하는 것이 아니라 현재 프레임을 제대로 받아왔는지를 확인하는 boolean 타입의 값도 같이 리턴해줌. 그래서 이 함수를 하나의 변수로만 받게 되면 그 변수에는 ndarray 가 저장되는 것이 아니라 true or false 값이 저장됨. 그래서 이 함수를 받아올 때는 변수 두 개로 받아와야 함.
- cv2.waitKey(10) == 27 → 앞에서는 정지 영상 출력할 때는 waitkey 함수에 인자를 주지 않았지만, 여기서는 줘야 함. 10초 기다리고, 그 다음에 다음 프레임을 받아오도록 설정하는 것임. 근데 코드를 if 를 쓰지 않고 그냥 작성하게 되면 while 을 빠져나올 방법이 없기 때문에 if 문을 통해 waitKey 가 반환한 값이 27일 경우에 (ESC 키를 눌렀을 때) break 를 통해 빠져나오는 것.
- ret, frame = cap.read() # 프레임을 받아오는 함수. 기억하기 ! → 이 함수는 현재 프레임을 그대로 반환하는 것이 아니라 현재 프레임을 제대로 받아왔는지를 확인하는 boolean 타입의 값도 같이 리턴해줌. 그래서 이 함수를 하나의 변수로만 받게 되면 그 변수에는 ndarray 가 저장되는 것이 아니라 true or false 값이 저장됨. 그래서 이 함수를 받아올 때는 변수 두 개로 받아와야 함.
동영상 처리 예제
- video_in.py : camera_in 과 유사하므로 생략
import sys
import cv2
# 비디오 처리 코드는 카메라 처리 코드에서 파일 이름만 입력으로 넣어주면 되는 것.
# 비디오 파일 열기 : filename 입력
cap = cv2.VideoCapture('video1.mp4')
# 비디오가 잘 열렸는지 확인
if not cap.isOpened():
print("Video open failed!")
sys.exit()
# 비디오 프레임 크기, 전체 프레임수, FPS 등 출력
print('Frame width:', int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)))
print('Frame height:', int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)))
print('Frame count:', int(cap.get(cv2.CAP_PROP_FRAME_COUNT)))
fps = cap.get(cv2.CAP_PROP_FPS)
print('FPS:', fps)
delay = round(1000 / fps)
# 비디오 매 프레임 처리
while True:
ret, frame = cap.read()
# 동영상 처리에서 아래의 if 문이 실행된다는 건 동영상 파일의 마지막 부분을 가져와서 더 이상 가져올 frame 이 없을 때 실행되는 것.
if not ret:
break
edge = cv2.Canny(frame, 50, 150)
#inversed = ~frame # 반전
cv2.imshow('frame', frame)
cv2.imshow('edge', edge)
#cv2.imshow('inversed', inversed)
if cv2.waitKey(delay) == 27:
break
cap.release()
cv2.destroyAllWindows()6) 카메라와 동영상 처리하기2
cv2.VideoWriter 클래스
- OpenCV 에서는 cv2.VideoWriter 클래스를 이용하여 일련의 프레임을 동영상 파일로 저장할 수 있음.
- 일련의 프레임은 모두 크기와 데이터 타입이 같아야 함
Fourcc (4-문자 코드, four character code)
- fourcc 코드는 네 개의 문자로 구성된 코드이고, 어떤 압축 방식을 사용할 것인지를 나타내는 것임.
- 아래와 같은 코덱들을 사용할 때는 코덱을 사용할 수 있는 환경이 구축되어야 함.

저장을 위한 동영상 파일 열기

- 인자 설명
- filename : 비디오 파일 이름 : 저장할 비디오 파일 이름
- fourcc : fourcc 코덱 형식
- fps : 초당 프레임 수 : 현재 프레임과 다음 프레임의 시간 간격
- frameSize : 프레임 크기 (width, height) 튜플
- isColor : 컬러(True), 그렇지 않으면(False) : grayscale 영상을 저장하려고 하면 동영상 저장이 안됨.
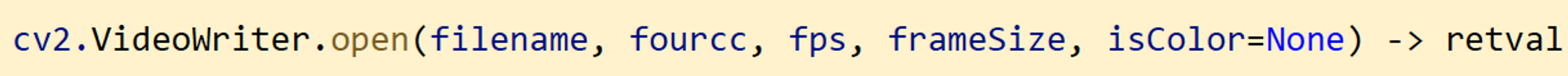
- 성공하면 True 실패하면 False
비디오 파일이 준비되었는지 확인

- 성공하면 True, 실패하면 False
프레임 저장하기

- write 를 이용하여 ndarray 형식의 image 를 받아서 저장하면 됨.
웹 카메라 입력을 동영상으로 저장하기
import sys
import cv2
cap = cv2.VideoCapture(0) # 기본 카메라 열기
# 예외 처리
if not cap.isOpened():
print("Camera open failed!")
sys.exit()
# 카메라 프레임 크기 확인
w = round(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
h = round(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
fps = cap.get(cv2.CAP_PROP_FPS)
# 카메라마다 값이 정상적으로 넘어오기도 하고 아니기도 하는데, 보통 초다 30프레임 넘어옴
fourcc = cv2.VideoWriter_fourcc(*'DIVX')
# *'DIVX' == 'D', 'I', 'V', 'X', 정수값을 리턴함.
delay = round(1000 / fps)
# fps 를 이용해서 현 프레임과 그 다음 프레임의 시간 간격을 계산하기 위한 값.
# VideoWriter 객체 생성
out = cv2.VideoWriter('output.avi', fourcc, fps, (w, h))
# output.avi 의 영상을 fourcc 코덱으로, fps 의 초당 프레임으로,
# (w,h) 의 프레임 크기로, 컬러로 저장하겠다는 의미
# 예외 처리 : 정상 열기 확인
if not out.isOpened():
print('File open failed!')
cap.release()
sys.exit()
while True:
ret, frame = cap.read()
if not ret:
break
#inversed = ~frame
edge = cv2.Canny(frame, 50,150)
#out.write(edge) # 이건 저장되지 않음.
# 왜냐하면 edge 는 그레이 스케일 형식으로 리턴이 되기 때문에, color 로 설정하면 저장되지 않음.
# edge 를 저장하고 싶다면 edge 를 color 로 변환해줘야 함.
edge_color = cv2.cvtColor(edge, cv2.COLOR_GRAY2RGB)
out.write(frame)
# VideoWriter 은 영상 데이터만 저장함 소리 데이터는 저장하지 않음.
out.write(edge_color)
# 눈으로 봤을 때는 edge 그레이스케일이나 컬러나 같음. 하지만 꼭 변환해줘야 저장이 됨.
cv2.imshow('edge', edge)
cv2.imshow('frame', frame)
#cv2.imshow('inversed', inversed)
if cv2.waitKey(delay) == 27:
break
cap.release()
out.release()
cv2.destroyAllWindows()- 중요 정리
- out.write(edge) # 이건 저장되지 않음. → 왜냐하면 edge 는 그레이 스케일 형식으로 리턴이 되기 때문에, color 로 설정하면 저장되지 않음. edge 를 저장하고 싶다면 edge 를 color 로 변환해줘야 함.
- VideoWriter 은 영상 데이터만 저장함 소리 데이터는 저장하지 않음.
- out.write(edge) # 이건 저장되지 않음. → 왜냐하면 edge 는 그레이 스케일 형식으로 리턴이 되기 때문에, color 로 설정하면 저장되지 않음. edge 를 저장하고 싶다면 edge 를 color 로 변환해줘야 함.
7) 키보드 이벤트 처리하기
키보드 입력 대기 함수
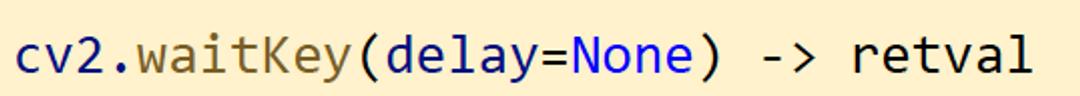
- 인자 설명
- delay : 밀리초 단위 대기 시간. delay ≤ 0 이면 무한히 기다림. 기본값은 0
- retval : 눌린 키 값(아스키 코드) 키가 눌리지 않으면 -1
키보드에서 'i' or 'I' 키를 누르면 영상을 반전하는 프로그램
- keyboard.py : 이 부분은 앞에서도 다루었기 때문에 설명 생략
import sys
import numpy as np
import cv2
img = cv2.imread('cat.bmp', cv2.IMREAD_GRAYSCALE)
# 예외 처리
if img is None:
print('Image load failed!')
sys.exit()
cv2.namedWindow('image') # 윈도우 생성
cv2.imshow('image', img) # 화면 출력
while True:
keycode = cv2.waitKey()
# 이런 식으로 사용자가 입력한 리턴 값과 내가 종료 키로 지정하고 싶은 키를 비교해서 종료하도록 하는 것.
# 이 기능을 이용해서 영상 반전의 키를 inverse, I 키를 이용해서 기능을 추가하는 코드
if keycode == ord('i') or keycode == ord('I'):
# ord 는 아스키 코드 값으로 변환해주는 것.
img = ~img # 반전, 비트 반전 연산자임. 반전 연산자는 아니지만,
# unsigned charater 에서는 비트를 반전하겠다는것이
# 픽셀 값을 255에서 뺀 것과 동일한 형태로 동작하기 때문에 이를 자주 이용함.
cv2.imshow('image', img)
elif keycode == 27: # 종료 키 esc
break
cv2.destroyAllWindows()8) 마우스 이벤트 처리하기
마우스 이벤트 콜백함수 등록 함수
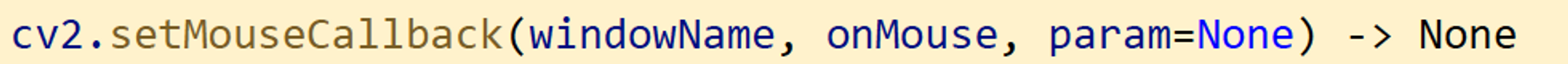
- 이 함수는 내가 띄운 opencv 창에서 발생한 어떤 마우스 이벤트를 가져다가 내가 처리하고 싶다는 것.
- 콜백 함수를 등록할테니 마우스 이벤트가 발생하면 내가 만든 콜백함수를 실행하는 형태로 동작함.
- 인자 설명
- windowName : 마우스 이벤트 처리를 수행할 창 이름
- onMouse : 마우스 이벤트 처리를 위한 콜백 함수 이름
- 마우스 이벤트 콜백함수는 특정 형식 존재 : 바로 다음에 설명
- param : 콜백 함수에 전달할 데이터
마우스 이벤트 처리 함수(콜백 함수) 형식
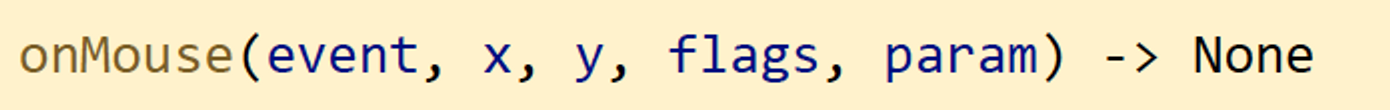
- 인자 설명
- event : 마우스 이벤트 종류. ex) 마우스 왼쪽/오른쪽 클릭, 마우스 움직임 등
- x : 마우스 이벤트가 발생한 x 좌표
- y : 마우스 이벤트가 발생한 y 좌표
- flags : 마우스 이벤트 발생 시 상태 ex) 마우스 클릭 시 내가 컨트롤 키를 눌렀다던가 등
- param : cv2.setMouseCallback() 함수에석 설정한 데이터
마우스 이벤트 처리 함수의 event, flags 인자는 강의 자료 참고
마우스를 이용한 그리기 예제
- mouse.py
import sys
import numpy as np
import cv2
oldx = oldy = -1
def on_mouse(event, x, y, flags, param):
# on_mouse 함수 : 이 함수의 인자 중에 사용하지 않는 것이 있어도 꼭 적어줘야 함.
# global img : Circle 그리는 것.
global img, oldx, oldy
if event == cv2.EVENT_LBUTTONDOWN: # 마우스 왼쪽 버튼이 눌려지는 경우
oldx, oldy = x, y
print('EVENT_LBUTTONDOWN: %d, %d' % (x, y)) # 좌표 출력
elif event == cv2.EVENT_LBUTTONUP: # 마우스 왼쪽 버튼이 떼어지는 경우
print('EVENT_LBUTTONUP: %d, %d' % (x, y)) # 좌표 출력
elif event == cv2.EVENT_MOUSEMOVE:
# 이벤트 : 마우스가 움직일 때 : 엄청나게 많이 발생함.
if flags & cv2.EVENT_FLAG_LBUTTON:
# 엄청나게 많이 발생하는 이벤트를 flags 인자를 통해(특정 키보드 키 등) 제어. 키보드 + 마우스 동시에
# flags == cv2.EVENT_FLAG_LBUTTON 으로 하면 안됨. 그럼 특정 키보드를 눌렀을 때 동작이 안됨.
# & 연산자를 쓰면 위의 LBUTTON 이벤트가 1이기 때문에 flags 의 마지막 비트가 1로 세팅이 되어 있는 가 를 보는 형태로 작성하는 것이 좋음.
'''
cv2.circle(img, (x,y), 5, (0,0,255), -1)
cv2.imshow('image', img)
'''
# 이전 좌표와 현재 좌표(x,y) 로 그리기.
cv2.line(img, (oldx, oldy), (x, y), (0, 0, 255), 4, cv2.LINE_AA) # 선 그리기. 그림 그리기
cv2.imshow('image', img)
oldx, oldy = x, y
# line 말고도 circle 함수로 간단하게 그리는 방법도 있음 : 점으로 그리는 느낌. (강의 참고)
# 단, Circle 은 마우스를 빠르게 움직이면 점 형태로 끊김.
# 흰색 창 띄우기 : 컬러형태의 : RGB 값이 모두 255 이므로 흰색
img = np.ones((480, 640, 3), dtype=np.uint8) * 255
cv2.namedWindow('image')
# setMouseCallback 함수를 호출하는 위치가 중요함.
# 이 함수는 windowName 이라는 창이 이미 떠있는 상태에서 호출해야 하기 때문에, namedWindow 함수가 실행되어서 창이 떠 있는 상태
# 또는 cv2.imshow 함수가 호출이 된 이후에 호출되어야 함.
cv2.setMouseCallback('image', on_mouse, img) # on_mouse 라는 함수 생성
cv2.imshow('image', img)
cv2.waitKey()
cv2.destroyAllWindows()- 중요 정리
- setMouseCallback 함수를 호출하는 위치가 중요함.
→ 이 함수는 windowName 이라는 창이 이미 떠있는 상태에서 호출해야 하기 때문에, namedWindow 함수가 실행되어서 창이 떠 있는 상태 또는 cv2.imshow 함수가 호출이 된 이후에 호출되어야 함. - on_mouse 함수 : 이 함수의 인자 중에 사용하지 않는 것이 있어도 꼭 적어줘야 함.
- setMouseCallback 함수를 호출하는 위치가 중요함.
9) 트랙바 사용하기
트랙바(Trackbar) 란?
- 프로그램 동작 중 사용자가 지정한 범위 안의 값을 선택할 수 있는 컨트롤
- OpenCV 에서 제공하는 (유일한?) 그래픽 사용자 인터페이스 : 운영체제 별 각각의 컨트롤을 일정하게 하기 어려워서 GUI 기능 거의 없음.
트랙바 생성 함수

- 인자 설명
- trackbarName : 트랙바 이름
- windowName : 트랙바를 생성할 창 이름.
- value : 트랙바 위치 초기값
- count : 트랙바 최댓값, 최솟값은 항상 0
- onChange : 트랙바 위치가 변경될 때마다 호출할 콜백 함수 이름 → 트랙바 이벤트 콜백 함수는 다음 형식을 따름
→ pos 인자는 트랙바의 버튼이 위치한 정수값을 인자로 전달onChange(pos) → None
트랙바를 이용한 그레이스케일 레벨 표현
- trackbar.py
import numpy as np
import cv2
def on_level_change(pos): # 트랙바 이벤트 콜백 함수
value = pos * 16
# 이런 식으로 설정하면 pos 값이 0일 때는 0, 1일 때는 16. 즉, 16 간격으로 형성됨.
if value >= 255: # 마지막 pos 값이 256 이 되면, 0으로 바뀌기 때문에 이렇게 if 문 생성
value = 255
# 위의 if 의 기능을 numpy 에서 제공하는 함수(아래 코드)를 활용해도 됨.
# value = np.clip(level, 0, 255) # 최소, 최대 값을 설정하는 함수
img[:] = value
cv2.imshow('image', img)
# createTrackbar 함수는 namedWindow, imshow 함수 위에다가 생성하면 안됨.
# : 창이 생성된 이후에 사용해야 함.
img = np.zeros((480, 640), np.uint8) # grayscale 형식의 영상
cv2.namedWindow('image')
# 트랙바가 가리키고 있는 위치에 해당하는 grayscale 값을 화면에 보여주는 작업
# graysclae 값을 0 ~ 255 로 트랙바에 나타내면 트랙바는 작은데 값이 커지기 때문에
# 그 값을 16 간격으로 해서 나타낼 것 : 16 간격으로 grayscale 값이 증가하게끔.
cv2.createTrackbar('level', 'image', 0, 16, on_level_change)
# level : 트랙바 이름, image : 트랙바를 생성할 창 이름,
# 0 : 트랙바 위치 초기값, 16 : 트랙바 최댓값
# on_level_change : 트랙바 위치가 변경될 때마다 호출할 콜백 함수 이름.
cv2.imshow('image', img)
cv2.waitKey()
cv2.destroyAllWindows()- 중요 정리
- createTrackbar 함수는 namedWindow, imshow 함수 위에다가 생성하면 안됨.
: 창이 생성된 이후에 사용해야 함.
- createTrackbar 함수는 namedWindow, imshow 함수 위에다가 생성하면 안됨.
10) 연산 시간 측정 방법
- 컴퓨터 비전은 대용량 데이터를 다루고, 일련의 과정을 통해 최종 결과를 얻으므로 매 단계에서 연산 시간을 측정하여 관리할 필요가 있음.
OpenCV에서는 TickMeter 클래스를 이용하여 연산 시간을 측정

- tm : cv2.TickMeter 객체
- 멤버 함수
- tm.start() : 시간 측정 시작
- tm.stop() : 시간 측정 끝
- tm.reset() : 시간 측정 초기화
- tm.getTimeSec() : 측정 시간을 초 단위로 반환
- tm.getTimeMilli() : 측정 시간을 밀리 초 단위로 반환
- tm.getTimeMicro() : 측정 시간을 마이크로 초 단위로 반환
특정 연산의 시간 측정 예제
- time_check.py
import sys
import time
import numpy as np
import cv2
img = cv2.imread('hongkong.jpg') # 영상 열기
if img is None:
print('Imange load failed')
sys.exit()
tm = cv2.TickMeter() # 객체 생성
tm.reset()
tm.start()
t1 = time.time() # 이런 방법으로 측정 가능
edge = cv2.Canny(img, 50, 150) # 시간을 재고 싶은 함수 위 아래로 start, stop 함수를 호출
# 이 연산을 한번만 측정하지 말고, 20번 100번 정도 시행해서 평균적인 속도를 측정하는 것이 좋음.
tm.stop()
ms = tm.getTimeMilli() # 측정한 시간 변수에 저장.
print('time:', (time.time() - t1) * 1000)
print('Elapsed time: {}ms.'.format(tm.getTimeMilli()))- 중요 정리
- 시간을 재고 싶은 함수 위 아래로 start, stop 함수를 호출
11) 실전 코딩 : 동영상 전환 이펙트
- video_effect.py
import sys
import numpy as np
import cv2
# 두 개의 동영상을 열어서 cap1, cap2로 지정
cap1 = cv2.VideoCapture('video1.mp4')
cap2 = cv2.VideoCapture('video2.mp4')
# 예외 처리
if not cap1.isOpened() or not cap2.isOpened():
print('video open failed!')
sys.exit()
# 두 동영상의 크기, FPS는 같다고 가정함
# 각각 동영상의 전체 프레임 수를 변수로 저장해놓기.
frame_cnt1 = round(cap1.get(cv2.CAP_PROP_FRAME_COUNT))
frame_cnt2 = round(cap2.get(cv2.CAP_PROP_FRAME_COUNT))
fps = cap1.get(cv2.CAP_PROP_FPS)
effect_frames = int(fps * 2)
# 첫 번째 동영상의 끝부분 2초, 두 번째 동영상의 앞 부분 2초가 겹쳐져서 합성이 되게끔 작업하기 위해
'''
실제 구현은 앞 부분 동영상에서 뒷 부분에 있는 48 프레임과 뒤 부분 동영상에서 앞 부분에 있는 48 프레임을
합성하는 코드만 작성하면 됨.
'''
print('frame_cnt1:', frame_cnt1)
print('frame_cnt2:', frame_cnt2)
print('FPS:', fps)
delay = int(1000 / fps)
w = round(cap1.get(cv2.CAP_PROP_FRAME_WIDTH))
h = round(cap1.get(cv2.CAP_PROP_FRAME_HEIGHT))
fourcc = cv2.VideoWriter_fourcc(*'DIVX')
# 출력 동영상 객체 생성
out = cv2.VideoWriter('output.avi', fourcc, fps, (w, h))
# 기본적으로 동영상 2개 받아서 이어서 붙이는 코드 먼저 작성.
# 1번 동영상 복사
for i in range(frame_cnt1 - effect_frames): # 프레임 수 변수를 이용해서 for 문으로
# 뒤에 48 프레임 정도 남겨두고 앞 부분은 그대로 output 동영상에 저장이 됨.
ret1, frame1 = cap1.read()
# 예외 처리
if not ret1:
print('frame read error!')
sys.exit()
out.write(frame1)
print('.', end='')
cv2.imshow('output', frame1)
cv2.waitKey(delay)
# 1번 동영상 뒷부분과 2번 동영상 앞부분을 합성
for i in range(effect_frames): # 여기서는 합성하는 구간인데,
# 이 합성하는 구간에서는 1번 동영상 프레임도 가져오고, 2번 동영상 프레임도 가져오기 때문에
# 아래 코드 두 개로 작성해야 함.
ret1, frame1 = cap1.read()
ret2, frame2 = cap2.read()
if not ret1 or not ret2:
print('frame read error!')
sys.exit()
# 합성하는 과정
# 합성은 전체 프레임에서 앞부분의 일부분을 자르고, 그리고 뒷 부분의 일부분을 잘라서 이어 붙이는데,
# 그럼 i 가 0 ~ effect_frames 형태로 증가하기 때문에 이것을 이용해서
# dx 라고 하는 어느 위치까지 잘라낼 것인지, 잘라내기 위한 그 위치를 dx 라고 정의를 하고,
# 전체 크기를 w 라고 정의 해놓고, (위에서) w 를 effect_Frames 로 나누면 가로가 약 27개 픽셀 단위로 해서 잘리는데
# 그리고 여기에다가 곱하기 i 를 하면 그 단위로 증가하게끔.
dx = int(w / effect_frames) * i
# 그리고 프레임을 하나 만드는데, frame 은 np.zeros 를 이용해서 컬러 영상을 만들고
frame = np.zeros((h, w, 3), dtype=np.uint8)
#이 프레임 영상에서 세로 부분은 전체, 가로는 0~dx 까지를 frame2 의 0 ~ dx 까지를 가져오고,
#그리고 frame 영상에서 y 좌표는 전체, dx ~ w 까지를 frame 1 에서 전체에서 dx ~ w 까지를 받아 옴.
frame[:, 0:dx, :] = frame2[:, 0:dx, :]
frame[:, dx:w, :] = frame1[:, dx:w, :]
# 위의 두 코드로 frame 영상이 구성한 것.
# 만약 합성을 디졸브 형태로 하고 싶다면,
# 두 개의 영상에 대해서 가중치 합을 계산해야 함.
'''
가중치 합을 계산하는데, 처음에는 첫 번째 동영상에 대한 가중치를 높이다가,
점점 시간이 지나면서 두 번째 동영상에서 가져온 프레임에 대한 가중치를 높이는 형태로 코드를 작성하면 됨.
'''
# alpha + (1-alpha) = 1 이 되어야 함.
#alpha = 1.0 - (i / effect_frames) : i 가 0일 때 alpha 는 0이 되어야 함. 그래서 이 코드로.
#frame = cv2.addWeighted(frame1, 1 - alpha, frame2, alpha, 0)
'''
frame1 에서 1-alpha 만큼의 비중을 가져오고, frame2 에서 alpha 만큼의 비중을 가져오고,
감마라는 인자는 추가적으로 더해줄 필요가 없으므로 0으로 놓으면
이 결과를 가져다가 frame 에다가 그대로 대입을 하면 디졸브 합성이 됨.
'''
out.write(frame)
print('.', end='')
cv2.imshow('output', frame)
cv2.waitKey(delay) # 영상 전환을 조금 더 빠르게 하고 싶다면 delay 값을 낮추면 됨/
# 2번 동영상을 복사 : 두번째 동영상 뒷부분을
for i in range(effect_frames, frame_cnt2):
# effect_frames ~ frame_cnt2 (마지막 프레임) 까지
ret2, frame2 = cap2.read()
if not ret2:
print('frame read error!')
sys.exit()
out.write(frame2)
print('.', end='')
cv2.imshow('output', frame2)
cv2.waitKey(delay)
print('\noutput.avi file is successfully generated!')
cap1.release()
cap2.release()
out.release()
cv2.destroyAllWindows()
# 이 프로그램에서 가장 주의 깊게 봐야 하는 부분은 가운데 합성 부분임.
# 중간에 2초 가량만 합성하면 되므로, 계산 부분만 잘 하면 됨.- 중요 정리
- 여기서는 합성하는 구간인데이 합성하는 구간에서는 1번 동영상 프레임도 가져오고, 2번 동영상 프레임도 가져오기 때문에 아래 코드 두 개로 작성해야 함.
- 합성하는 과정
- 합성은 전체 프레임에서 앞부분의 일부분을 자르고, 그리고 뒷 부분의 일부분을 잘라서 이어 붙이는데, 그럼 i 가 0 ~ effect_frames 형태로 증가하기 때문에 이것을 이용해서 dx 라고 하는 어느 위치까지 잘라낼 것인지, 잘라내기 위한 그 위치를 dx 라고 정의를 하고, 전체 크기를 w 라고 정의 해놓고, (위에서) w 를 effect_Frames 로 나누면 가로가 약 27개 픽셀 단위로 해서 잘리는데 그리고 여기에다가 곱하기 i 를 하면 그 단위로 증가하게끔.
출처 : 패스트캠퍼스 <OpenCV를 활용한 컴퓨터비전과 딥러닝>

포기하지 않는 백엔드 개발자 5nam입니다.