Deep Learning for DeepFakes Creation and Detection
딥페이크의 기술적인 내용과 딥페이크로 인한 개인정보 침해를 방지하기 위한 딥페이크 탐지 기술의 개발과 연구
Types of Facial Manipulations
: 얼굴을 조작하는 것에 대한 내용, Facial Manipulations 는 얼굴을 조작하는 기술의 총 명칭
- In the last two decades, interest in virtual face manipulation has rapidly increased : 최근 20년 동안 컴퓨터 그래픽 기술이 많이 발전하면서 가상의 얼굴 manipulation 이 많이 발전해왔음.
- Being categorized into four different groups : 이런 Facial Manipulation 기술을 4가지로 나누어서 생각할 수 있음.
- Face Synthesis : 아예 존재하지 않던 가상의 얼굴을 만들어서 그 얼굴을 이용하여 합성하는 방법
- Facial Attributes : 기존에 존재하던 얼굴에서 특정한 속성만 바꾸는 방법 ex) 안경을 쓰지 않고 있던 얼굴에 안경을 씌우거나 등
- Facial Expression : 표정을 바꾸는 것
- Face Swap : 서로 다른 얼굴을 교체하는 기법, 흔히 알려진 딥페이크가 Face Swap 에 속한 것임
- Face Synthesis : 아예 존재하지 않던 가상의 얼굴을 만들어서 그 얼굴을 이용하여 합성하는 방법
Type 1) Face Synthesis
- Creating entire non-existent faces, using Generative Adversarial Networks (GANs)
-
Using GANs such as the StyleGAN

-
Face Synthesis 는 얼굴을 새롭게 만드는 걸 의미함
-
다시 말해서 아예 존재하지 않던 사람의 얼굴을 새로 만들어 내는 것임.
-
흔히, Generative Adversarial Networks, GAN 이라고 하는 기술이 사용됨
-
이 GAN 은 기존에 인물에 대한 사진을 굉장히 많이 가지고 있으면 그 인물 사진으로 트레이닝을 시켜서 사람의 이미지가 가지고 있는 특징들을 잘 분석해서 실제로 존재할 법한 이미지를 새롭게 만들어 내는 기술로서 사용됨.
-
https://arxiv.org/pdf/1406.2661.pdf : 이 논문 읽어보면 더 자세히 알 수 있음.
-
StyleGAN 으로 더 고해상도의 사진을 만들어낼 수 있음. 게다가 StyleGAN 은 모델이 배포가 잘 되어 있기 때문에 다양한 얼굴 이미지를 만들어 볼 수 있음.
-
GAN, Cycle GAN 등도 같이 읽어보면서 StyleGAN 도 같이 읽어보면 좋을 거 같음.
-
Type 2) Facial Attributes
-
Modifying some attributes of the face such as the color of the hair or the skin
-
Using GANs such as the StarGAN

-
Facial Attributes 는 사람의 얼굴에 존재하는 특정한 속성들을 추가하거나 삭제하는 등의 작업을 의미함.
-
Type 3) Facial Expression
-
Modifying the facial expressiong of the person
-
Transferring the facial expressiong of one person to another person
-
Source : victim person
-
Target : reference person

-
Facial Expression 은 말 그대로 얼굴의 표정을 변경하는 등의 작업임.
-
어떤 사람의 표정을 임의로 조작을 해서 변경하는 기법임.
-
논문 마다 Source, Target 용어를 다르게 설정함. 근데 일단 Source 가 피해자이고, Target 은 reference person 이라고 보면 됨
-
실제로 짓지 않은 표정들을 지은 것처럼 변경하는 등의 침해 사례가 나타나고 있음
-
실제로 하지 않은 말까지 한 것처럼하는 개인정보 침해 사례가 발생할 수 있음.
-
Face Synthesis 오바마 영상에서는 오바마가 특정 말을 하는 것처럼 하는 영상을 볼 수 있는데, 그 영상이 Facial Expression 에 속하는 것임.
-
Facial Expression 과 다음에 배울 Face Swap 이 우리가 알고 있는 딥페이크임.
-
Face2face, Syntehesizing Obama 논문 읽어보는 걸 추천
-
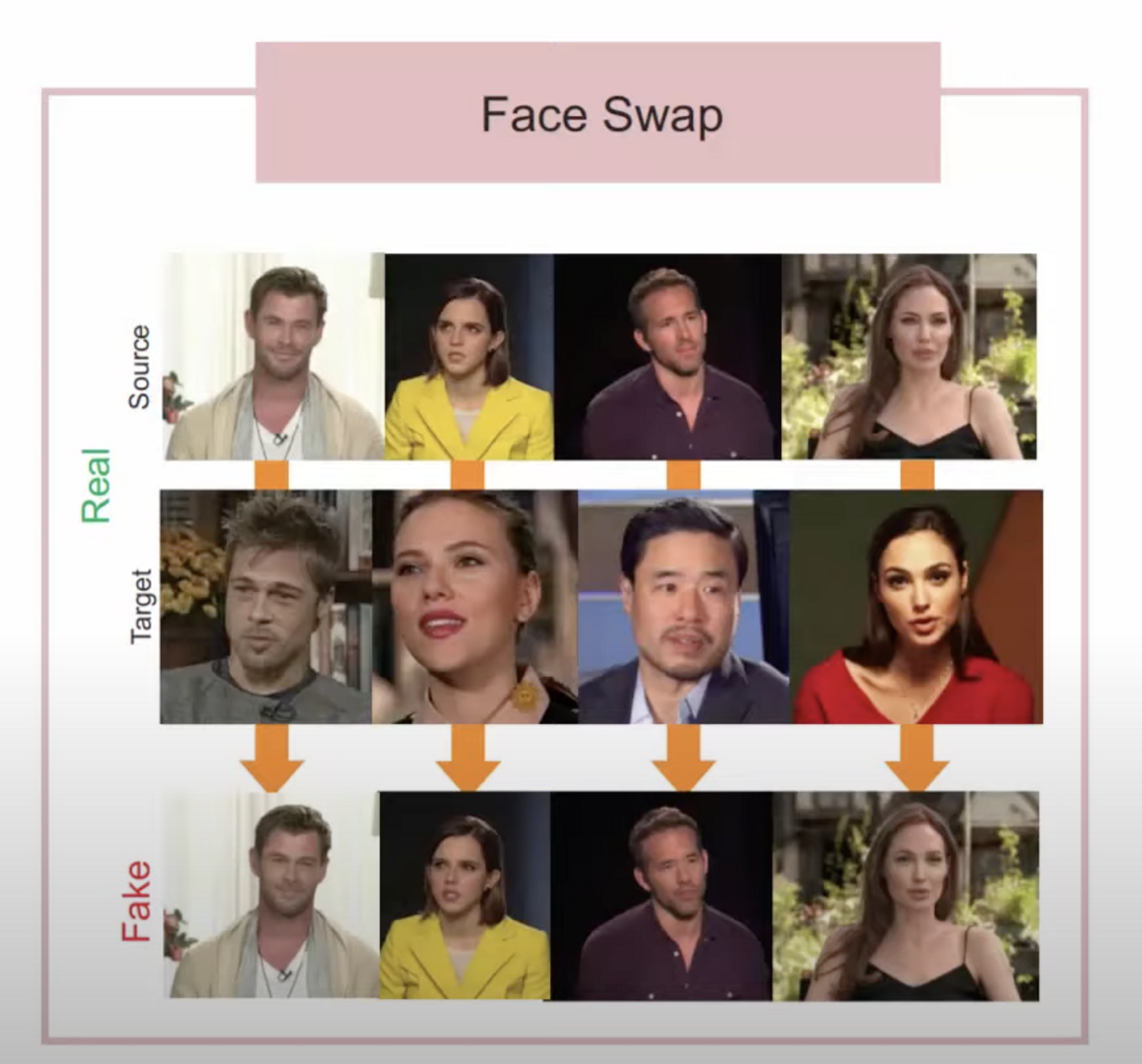
Type 4) Face Swap
-
Replacing the face of one person with the face of another person
-
Source : reference person
-
Target : victim person
-
서로 다른 사람의 얼굴을 switching 하는 기법
-
Face Swap 은 특정 사람의 얼굴을 다른 사람이 등장하는 비디오에 그 얼굴부분에 삽입을 하는 방식 몸은 그대로 인데, 얼굴 부분만 바꾸는 것.
-
FaceSwap : https://github.com/deepfakes/faceswap ← 이 라이브러리가 실제로 face swap 을 이용해서 딥페이크를 만드는 방법으로 가장 많이 사용됨
-
DeepFaceLab : https://github.com/iperov/DeepFaceLab ← 이 라이브러리도 최근에 많이 사용
-
Category of Face Swap
- Two different approaches : 두 가지 approaches 가 존재
-
Classical computer graphics-based technipues
: 첫 번째는 전통적으로 컴퓨터 그래픽에 기반하는 기술들이 존재
: 이때는 GPU 기반의 어떤 딥러닝이 사용되지는 않고, 흔히 알려져 있는 컴퓨터 그래픽을 이용해서 Face Swap 을 할 때의 유형이라고 생각하면 됨
-
Deep learning-based techniques (DeepFakes)
: 두 번째는 흔히 딥페이크라고 알려져 있는 딥러닝 기반으로 동작하는 Face Swap 기술들을 말함 : 이러한 기술 또한 아래의 두가지로 나뉨 (동빈나 기준) - Few-shot : generally based-on 'DL-based Face Reconstruction' : 이 경우에는 내가 어떤 비디오에 삽입하고자 하는 그 피해자의 이미지가 있다고 했을때, 그 이미지를 몇 장만, 조금만 가지고 있을 때의 Face Swap 기술 의미 → 더 현실적인 상황, 피해자의 사진을 많이 못 얻은 어택 유형이기도 함. - Multi-shot : generally based-on Auto-Encoder (i.g., **DeepFakes, DeepFaceLab**) : 이 경우에는 피해자의 사진을 여러 장 가지고 있을 때 사용할 수 있는 기법, 흔히 컴퓨터에 GPU 가 달려있고, 또한 딥러닝으로 학습을 시킬 수 있는 여건이 갖추어져 있으면서 피해자의 사진을 여러 장 가질 수 있는 경우에 주로 사용되는 유형임. → 더 성능이 좋음.
-
일반적인 Face Swapping 어플리케이션 같은 경우에는 Classical computer graphics-based 와 Few-shot 이 가장 많이 사용됨. 왜냐하면 휴대폰의 성능이 충분하지 않는 등의 문제가 있으므로
-
반면에, 보다 더 전문가 환경에서 Deep Learning-based 와 Multi-shot 이 많이 이용됨
-
DeepFake
- A deep learning-based technipue able to create fake images / videos : 딥러닝 기반의 기술을 이용해서 fake 이미지, 비디오를 만드는 기법
- Swapping the face of a person in an image or video by the face of another person
- Reddit user named "deepfakes" claimed in late 2017 to have developed ML algorithm : 어원
- For transposing celebrity faces into porn videos
- Privacy concerns : fake news, hoaxes, and financial fraud : 개인정보 침해 우려, 금융 사기 등
- 스턴트맨이 액션을 취한 다음, 그 스턴트맨의 얼굴에 실제 배우 얼굴을 합성하는 방식으로 이용을 하면 딥페이크를 좋은 쪽으로 사용하는 등의 좋은 예시
AutoEncoder
- A DNN architecture used to learn a representation in an unsupervised manner : AutoEncoder 은 딥러닝 아키텍쳐 중 하나임. 그것도 unsupervised manner 로 어떠한 reprsentation(= feature, 특징) 을 익힐 수 있는 딥러닝 기술 중 하나. : 우리는 이미지를 대상으로 해서 AutoEncoder 을 많이 사용함.
- Encoder : input x → feature z
- Decoder : feature z → output x'
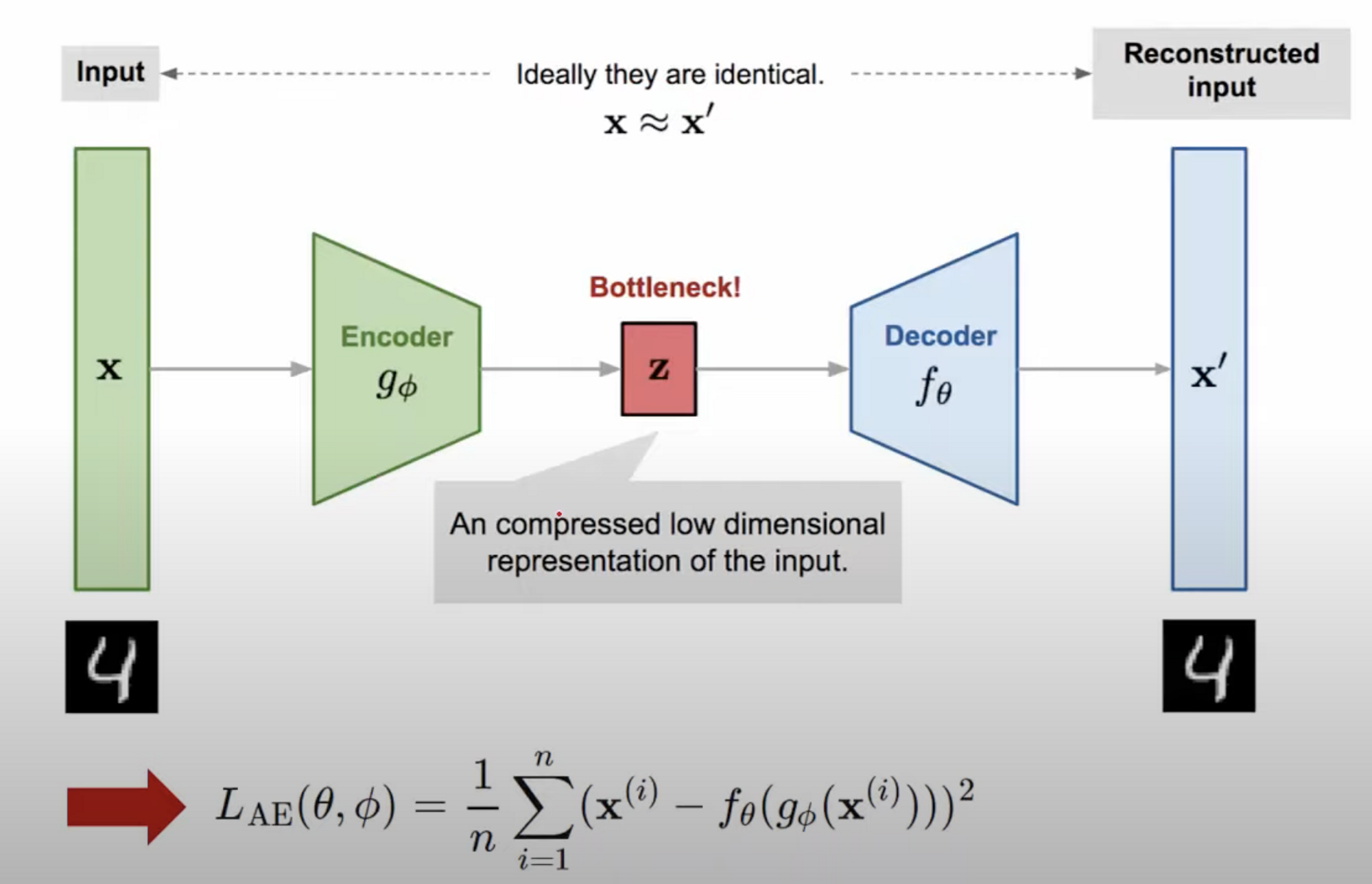
- 예를 들어, 사람의 눈, 코, 입의 위치, 크기, 모양 등 사람에게 존재하는 feature 들을 잘 learning 할 수 있도록 하는 것이 autoEncoder 의 특징.
- AutoEncoder 의 작동은 Encoder 와 Decoder 파트로 나누어짐
- Encoder 어떤 input 의 입력을 받아서 feature z 값을 내뱉도록 만들어지고
- Decoder 은 그 feature z 값을 받아서 다시 원본 ouput 값을 내뱉도록 만듦
- 사진처럼 input 에 4라는 숫자가 들어왔다면, 상대적으로 작은 차원의 공간에 해당 feature 정보들이 압축이 되었다가 다시 Decoder 을 거쳐서 다시 원본 이미지가 나오도록 트레이닝 시키는 것
- 위의 예시에서는 input 이 MNIST 이므로 28*28 의 demesion 을 가질 건데, Bottleneck 같은 경우에는 32 ~ 2 차원으로 설정할 수 있음. 그래서 저렇게 설정하면 상대적으로 layer demension 이 작기 때문에 bottleneck 부분에는 상대적으로 주요 feature 가 잘 압축이 되어서 저장된다는 특징이 있음.
- 이런 식으로 neural network 를 형성하면 input 값과 output 값이 동일하도록 학습을 시키는 과정만으로도 중간 레이어에서 각 이미지에 대한 feature 을 적절히 잘 추출할 수 있도록 만들어짐.
- 따라서 LOSS 함수 같은 경우에는 해당 이미지를 encoder 넣었다가, decoder 에 넣은 결과가 원본 이미지랑 유사하게 바뀌도록 loss 함수를 구성하고, low dimesional representation 을 잘 learning 할 수 있게 되므로 전반적으로 이미지에 대한 feature 을 잘 학습할 수 있게 되는 것.
DeepFakes 1) Extraction (OpenCV) 19:55
- AutoEncoder 을 이용해서 어떻게 fake video, 딥페이크 영상을 만들 수 있는 걸까요? → 이에 대해서 설명하기 위해서 실제로 딥페이크, 그 중에서도 여러 장의 이미지를 이용해서 학습을 시키는 그 대표적인 딥페이크 유형에서 실제로 딥페이크 비디오가 어떻게 만들어지는지에 대해서 설명 할 것. → 첫 번째 단계는 Extraction 임. 그냥 추출인데, 이미지에서 사람의 얼굴 부분을 추출하겠다는 것. → 여기서 말하는 Extraction 같은 경우에는 학습을 위해서 얼굴 이미지를 추출하는 것이라고 볼 수 있음 또한, optionally alignments file 이나 mask file 등을 만들 수 있음 → alignments file 같은 경우에는 흔히 68개의 랜드마크로 구성된 형태(아래 사진 왼쪽 부분)로서, 특정한 얼굴이 있을 때, 그 얼굴에서 주요 랜드마크의 위치가 어디인지를 기록해놓고 있는 파일을 의미함. 특히, OpenCV 와 같은 라이브러리를 이용하게 되면 이런 alignments 정보 또한, 잘 찾아서 랜드마크 정보 또한 파일로서 만들어주곤 함. → 첫 번재 단계인 Extraction 단계에서는 이런 역할을 수행함. → 또, 추가적으로 이런 랜드마크 파일을 이용해서 학습 과정이나 converting 과정에서 도움을 얻을 수 있음.
- To generate a set of faces, and optionally on alignments file and mask, for training
- To generate an alignments file and mask for converting your final frames

- 그래서 실제로 Target Video 와 Source Video 가 있을 때, 이러한 video 를 이용해서 Extraction 을 수행하게 되면 다음과 같이 각각의 비디오에서 각각의 프레임 단위로 얼굴 부분만 잘 찾아서 파일 형태로 저장해준다는 것이 특징임. 그래서 비디오 같은 경우는 일반적으로 30초 이상으로 구성해서 1000 장 이상의 이미지를 추출할 수 있도록 하는 것이 일반적
DeepFakes 2) Training(TensorFlow) → 가장 중요
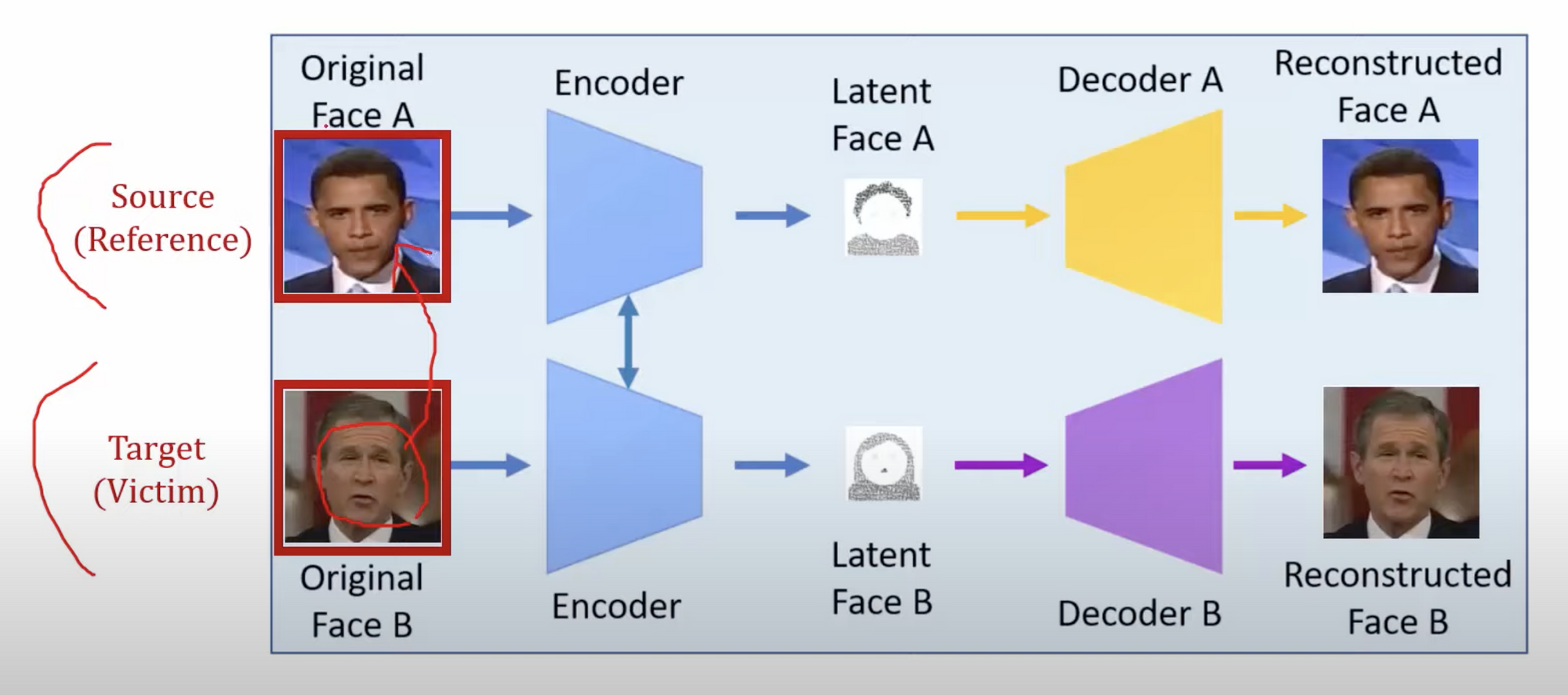
- 실제로 딥페이크가 어떤 아키텍쳐로 학습을 시켜서 피해자의 얼굴에 있는 아이덴테티를 잘 학습을 시키는지에 대해서 말할 것. 일반적으로 지금 존재하는 딥페이스 랩이나 페이스 스왑같은 라이브러리들은 tensorflow 기반으로 동작을 하고 있음. AutoEncoder 을 살짝 변형하여 사용한다는 것이 특징
- AutoEncoder 를 그대로 쓰는 것이 아니라 Encoder 부분을 공유하도록 함. 그래서 Encoder 파트에서 학습이 되는 feature 같은 경우에는 두 비디오에서 공유되고 있는 feature 가 학습이 되는 것임. : Normally similar features : eyes, nose, mouth, postions
- Decoder 파트 : Identity features: size of mouth, shape of eyes : Decoder 은 각각의 비디오마다 구분되어 있기 때문에 실질적으로 Identity features 들을 학습하는 것임.
- Latent Face 부분에는 Identity features 은 제외되고, 외곽이나 눈코입의 위치들만 시각화 됨
DeepFakes 3) Converting (Tensorflow)
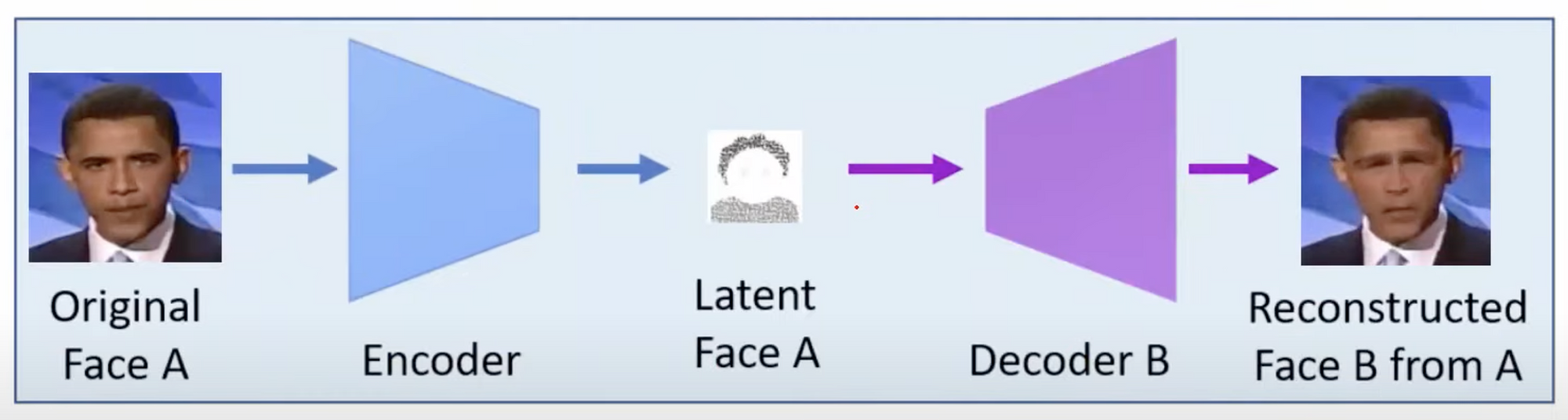
- 이 단계에서는 이전에 학습을 했던 Encoder 와 Decoder 을 사용함.
- 이때 Decoder 은 피해자(victim) 의 비디오를 가지고 converting 함.
- 원본 사진에서 Latent 를 거치면서 눈코입의 위치같은 것들을 확인할 수 있게 하고, 그러한 위치에 피해자(victim) 의 identity 를 삽입할 수 있도록 Decoder 파트를 넣어놓는 것
DeepFakes : Additional Information
- A sane number of images to use is anywhere between 1,000 and 10,000 : 1000 장에서 10000장의 사진만 있으면 가능함. (약 30초 동영상 = 1000장)
- You want as many different angles, expressions and lighting conditions as possible : 다양한 각도, 조명 정보가 다양하게 구성된 것이 더 결과물이 좋음
- The puality of training data should be of high quality (sharp and detailed)
- The original model can take anywhere from 12-48 hours to train on a Nvidia GTX 1080 : Nvidia GTX 1080 으로 하루 정도의 시간이 걸림. 코랩에서 무료로 제공되는 걸로 하루 정도 학습해도 괜찮은 퀄리티가 나옴
- Original model : 64px input, 64px output
Category of DeepFakes Detection
- A binary classification task to classify between authentic videos and tampered ones
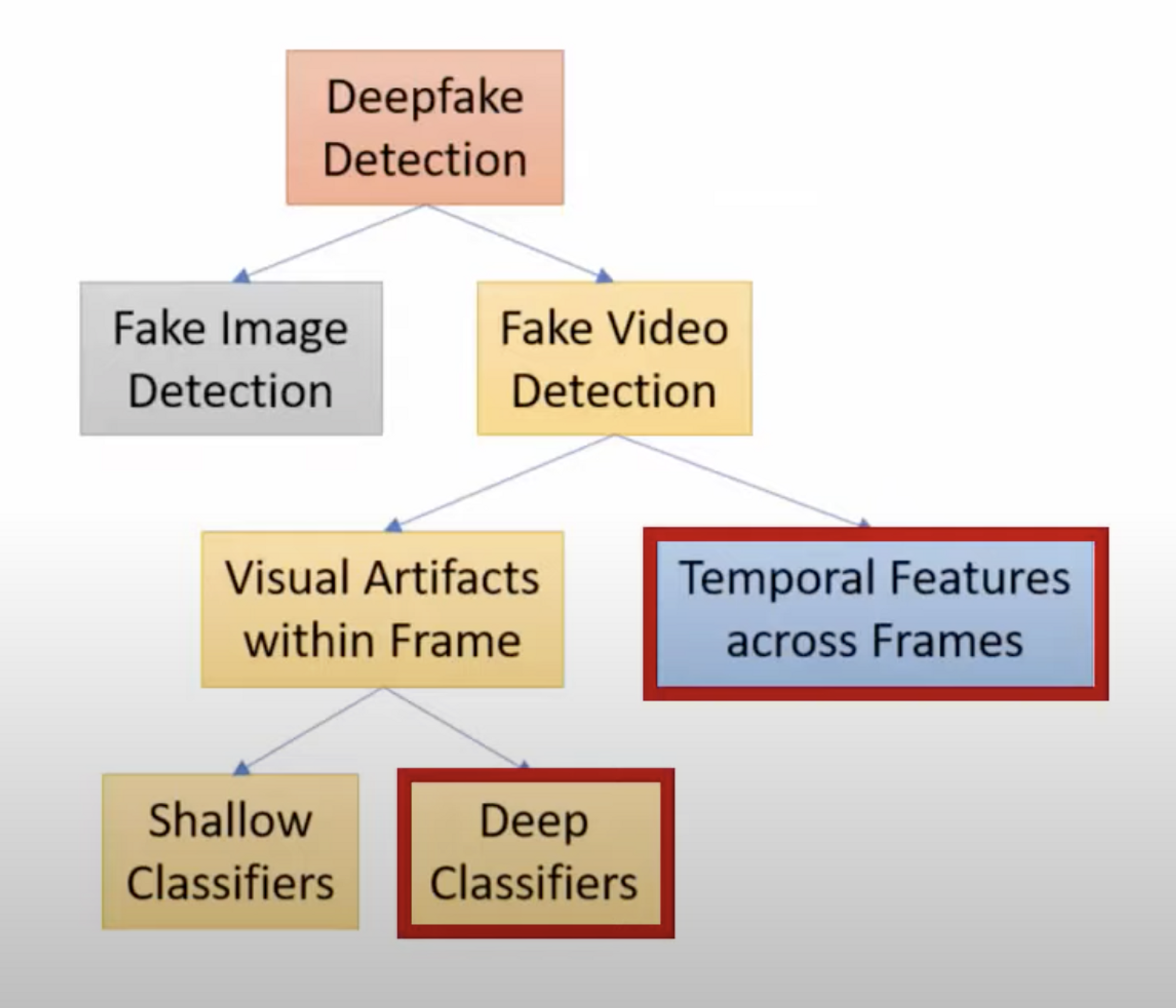
- 프레임 간의 연결이 자연스럽지 않은 특징들을 발견하여 밝혀내는 것 : Temporal Features across Frames
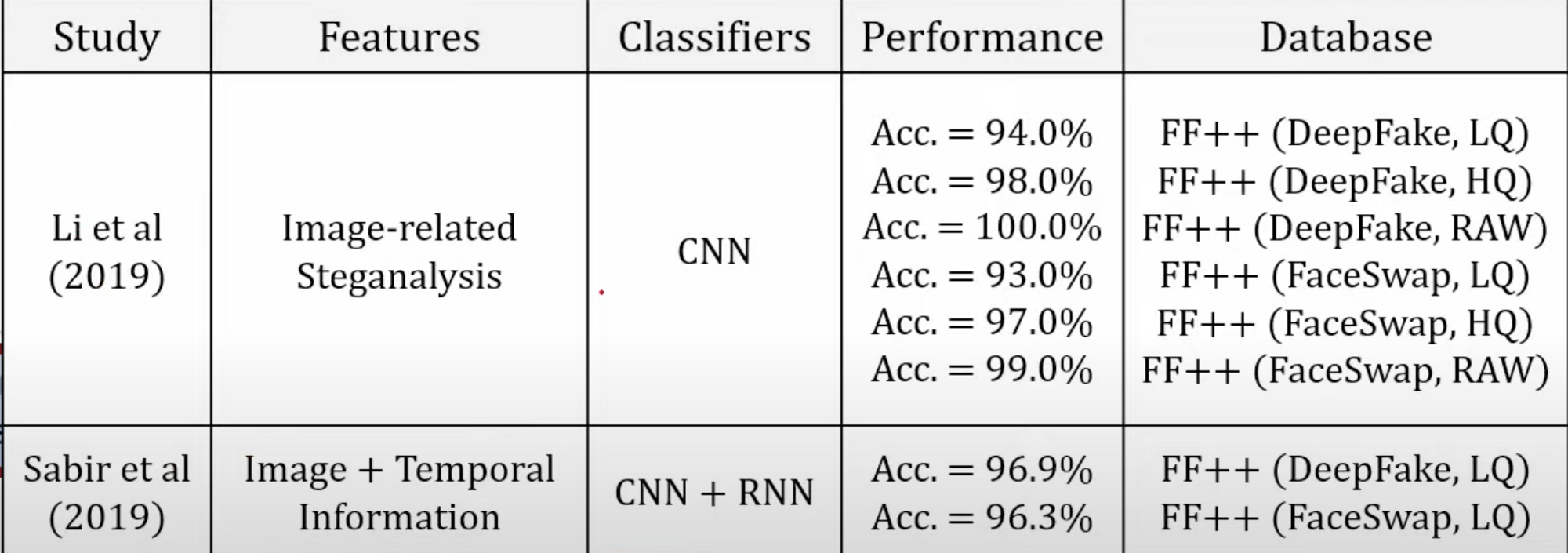
- 위의 두 논문이 가장 일반적인 탐지 논문임.
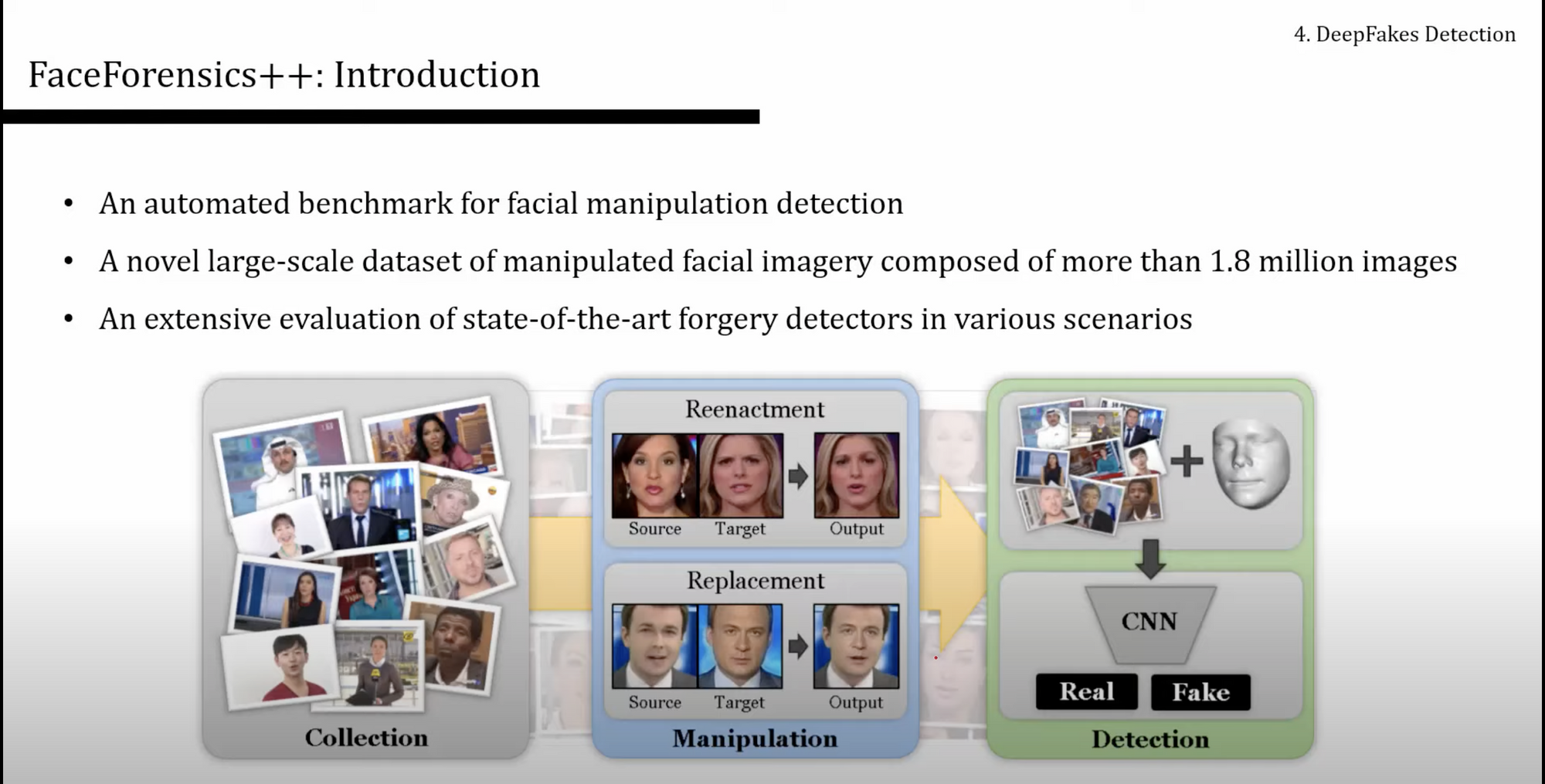
- FaceForensics++ 은 명확하고, 사용하기 좋은 논문임. 데이터셋도 제공할 뿐만 아니라 벤치마크까지 제공하는 것.
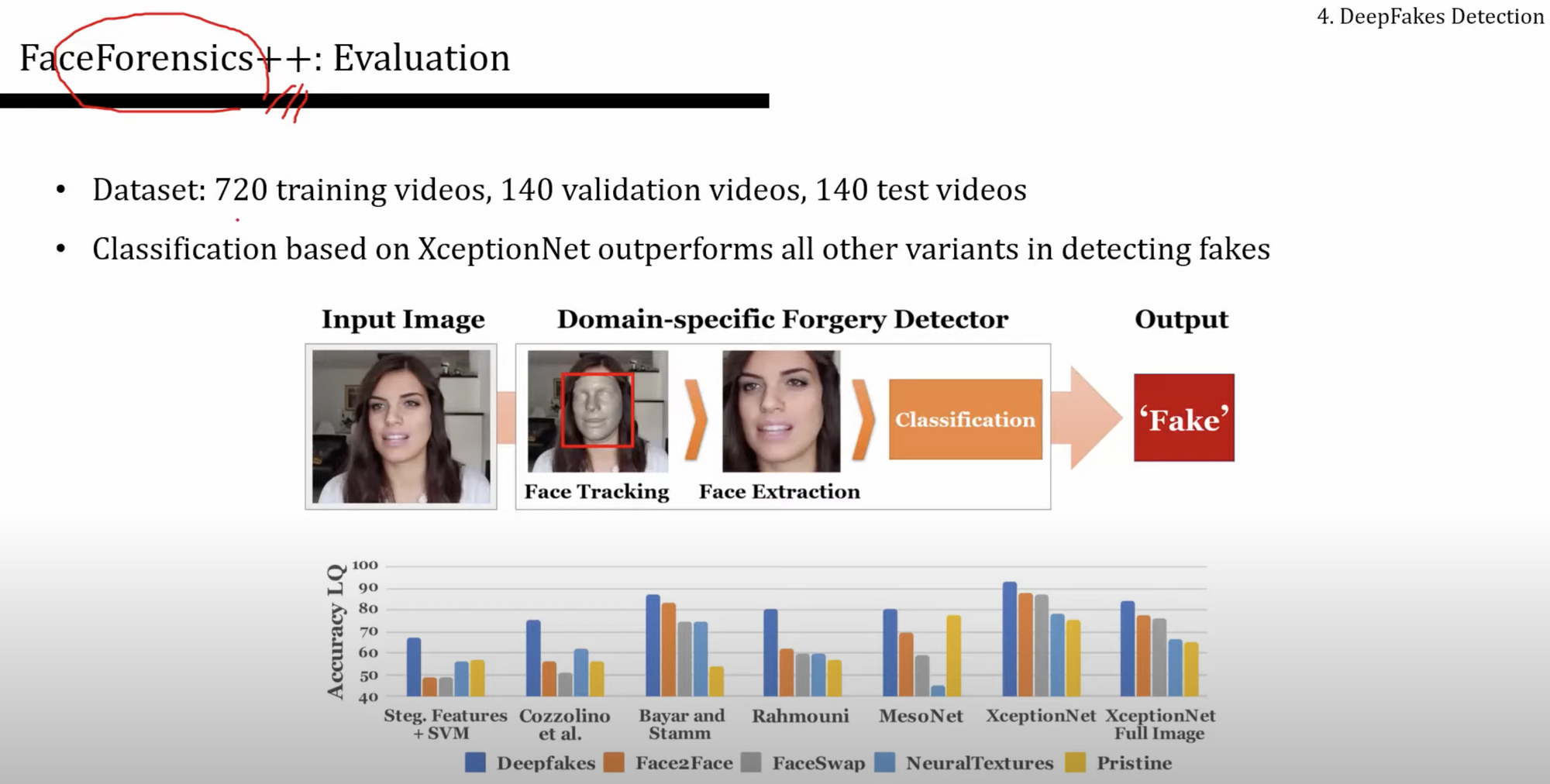
출처 : 동빈나 유튜브, https://www.youtube.com/watch?v=O9UmjWZL3KQ
