쿼리 개선기 에서 알 수 있듯이, F12는 데이터베이스 조회 성능을 개선하고자 product 테이블과 member 테이블에 집계 컬럼을 추가하게 되었습니다. 따로 캐시 계층이나 조회용 NoSQL을 두지 않았기 때문에, 통계 정보를 지속적으로 업데이트 하기 위해서 리뷰를 작성하거나 다른 회원을 새로 팔로우 할 때마다 집계 컬럼을 업데이트를 해 주어야 합니다. 전체적으로는 다음과 같은 프로세스로 진행이 되겠네요.
- 리뷰 작성
- 제품 조회 -> 이미 등록한 리뷰가 있는지 조회 -> 리뷰 작성 -> 제품의 통계 정보 업데이트
- 팔로우
- 팔로우 대상 회원 조회 -> 이미 팔로우했는지 조회 -> 팔로잉 정보 추가 -> 회원의 팔로워 수 업데이트
처음 이런 프로세스를 구성할 당시에는 이 과정에서 동시성과 관련된 문제가 발생할 수 있다는 사실을 캐치하지 못하고 넘어갔습니다. 어떤 동시성 문제가 발생할까요?
반정규화로 만들어낸 제품 통계인 리뷰 개수, 리뷰 총점, 평균 리뷰 점수와 회원 통계인 팔로워 수를 업데이트하는 로직은 JPA의 더티 체킹 기능을 통해 이루어집니다. 더티 체킹, 또는 변경 감지란 트랜잭션 커밋 종료 시점 또는 영속성 컨텍스트의 flush가 일어나는 시점에 엔티티의 스냅샷을 비교하여 변경된 컬럼이 있는지 확인하여 변경된 엔티티에 대해 update 쿼리를 실행하는 방식입니다. 직접 쿼리를 작성하지 않고 JPA 기능을 활용하여 최대한 도메인으로 비즈니스 로직을 응집시킬 수 있다는 장점이 있었습니다. 하지만 이 부분 때문에 문제가 발생했습니다.
더티 체킹을 활용하기 위해서는 당연히 기존 엔티티를 데이터베이스로부터 조회해 온 뒤 해당 엔티티의 필드를 수정해주어야 합니다. 그런데 엔티티를 조회해 온 뒤 트랜잭션이 커밋되어 업데이트 쿼리를 실행하는 사이에 다른 트랜잭션이 레코드를 변경한다면 어떻게 될까요?
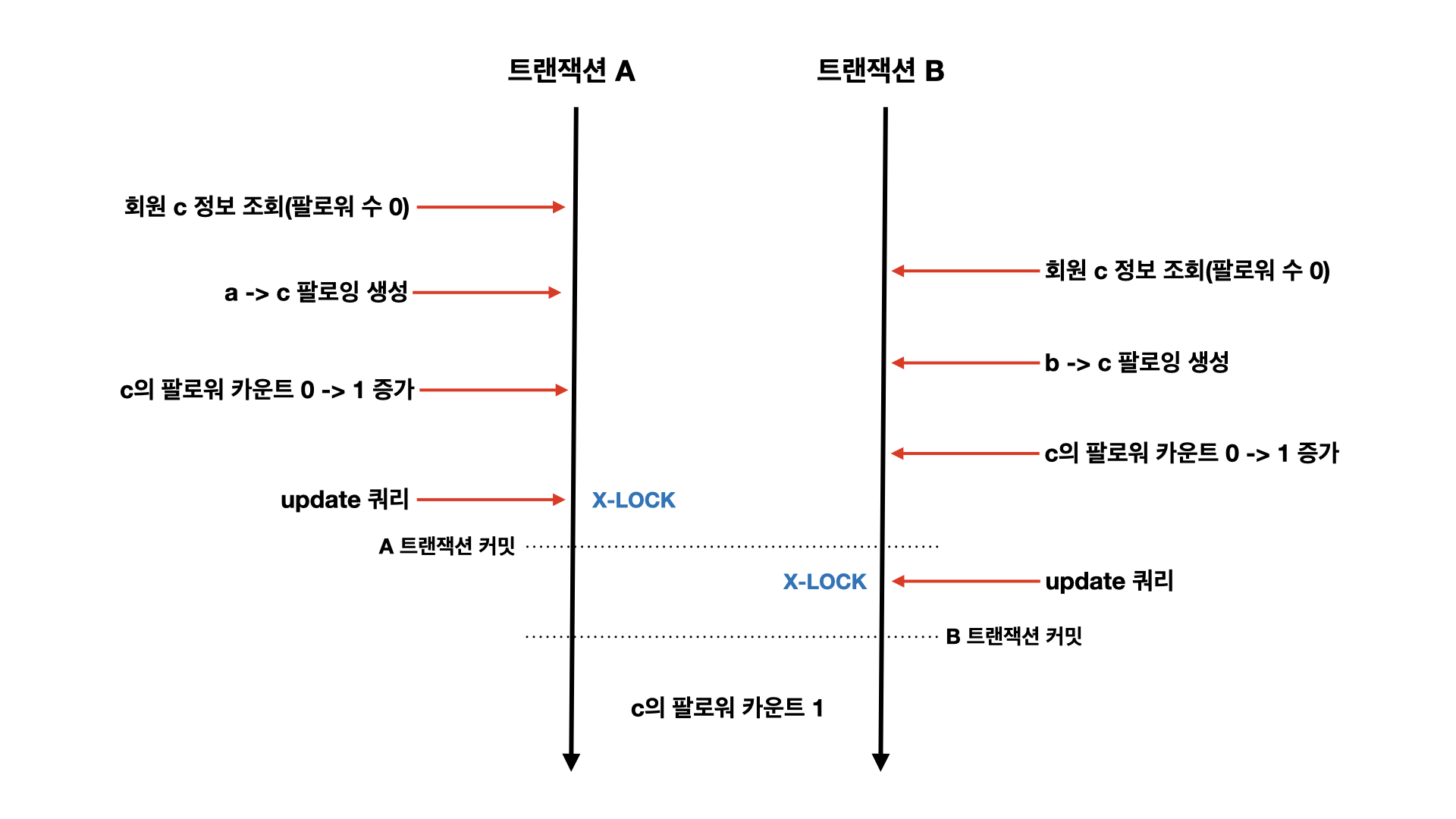
그림과 같은 상황이 발생하게 됩니다. a와 b가 각각 로그인하여 팔로우 메서드를 실행합니다. 트랜잭션에 진입한 이후 c를 데이터베이스에서 조회해오고, 팔로워 수는 0입니다. 그리고 A 트랜잭션이든 B 트랜잭션이든 한 트랜잭션이 로직을 마치고 커밋을 하게 됩니다. c의 팔로워 수는 1로 업데이트 됩니다. 이어서 다른 트랜잭션도 커밋합니다. 처음 조회해 온 엔티티의 팔로워 수를 1 증가시키는 로직이 있으므로, 엔티티의 팔로워 수는 1. 변경 감지로 인해 팔로워 수를 1로 업데이트하는 쿼리가 실행됩니다. 트랜잭션들이 모두 커밋된 후, 실제로 생성된 팔로우 개수는 2개지만 c 회원의 팔로워 수는 1개입니다. 데이터 정합성이 맞지 않게 되는 것이죠.
문제를 해결하기 위한 여러 고민
정합성 문제를 어떻게 해결할 수 있을까요? 여러가지 방법을 생각해보았습니다.
1. 트랜잭션 격리 레벨 조정
가장 높은 트랜잭션 격리 레벨인 Serializable을 사용하면 문제를 해결할 수 있지 않을까요? 하지만 Serializable을 적용할 수는 없었습니다.
Serializable을 사용하면 select 쿼리에 공유락(Shared Lock, S-Lock)이 걸리게 됩니다. 그리고 업데이트 쿼리가 실행될 때 MySQL이 배타락(Exclusive Lock, X-Lock)이 걸리게 됩니다. 공유 락이 걸리니까 다른 트랜잭션이 데이터를 쓰지 못해서 문제를 해결할 수 있다고 생각할 수 있습니다. 하지만 이 경우 데드락 문제가 발생합니다.
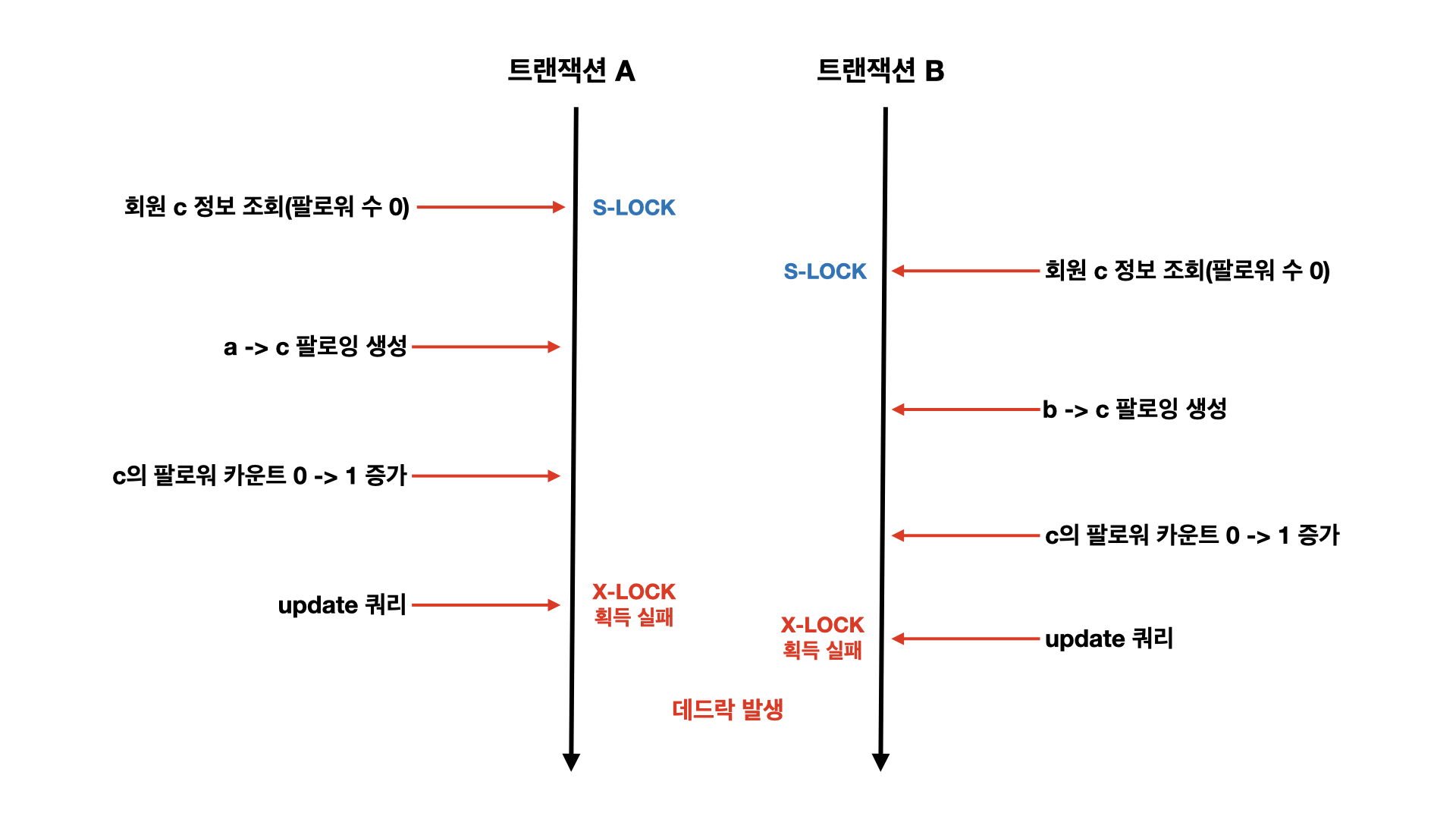
그림에서 보이는 것처럼 Serializable로 인해 A, B 트랜잭션 각각 c 회원에 대한 공유락을 획득합니다. 공유락끼리는 호환이 되기 때문에, A 트랜잭션이 공유락을 얻었더라도 B 트랜잭션이 공유락을 얻을 수 있습니다. 때문에 이후 로직이 진행됩니다. 문제는 A 트랜잭션을 커밋하기 위해 더티 체킹을 통해 update 쿼리가 실행될 때 발생합니다. c에 대한 업데이트 쿼리를 실행하기 위해서는 A 트랜잭션이 배타락을 얻어야 합니다. 그런데 B 트랜잭션이 공유락을 가지고 있습니다. 때문에 A 트랜잭션은 대기 상태로 들어가게 됩니다.
이제 B 트랜잭션 쪽도 커밋을 하기 위해 업데이트 쿼리를 실행합니다. 그런데 아까 A 트랜잭션이 배타락을 얻기 위해 커밋하지 않고 대기하고 있기 때문에, 공유락을 아직 가지고 있습니다. 그래서 B 트랜잭션도 배타락을 얻기 위해 대기합니다. A, B 트랜잭션 모두 배타락을 얻기 위해 서로 다른 트랜잭션이 커밋되기만을 기다리는 상황입니다. 즉, 데드락에 빠집니다. 데드락에 대한 예외 처리 등을 통해 어찌 저찌 해결할 수는 있겠지만, 사실상 격리 레벨 조정으로는 문제를 해결할 수 없습니다.
2. 비관적 락
비관적 락을 사용하는 방법도 있습니다. 회원 조회 메서드에 비관적 락을 걸어주게 되면 회원 조회 시 배타락을 얻게 됩니다. 때문에 A 트랜잭션에서 비관적 락으로 c 회원을 조회해오게 되면, A 트랜잭션이 끝날 때 까지 다른 트랜잭션들은 배타락도, 공유락도 얻어올 수 없습니다. 한번에 한 트랜잭션만 락을 얻을 수 있으므로 정합성 문제도, 데드락 문제도 해결됩니다.

단, 이렇게 할 경우 대기 시간이 발생합니다. 그림에서 보시는 것처럼 트랜잭션의 시작이 배타락을 얻는 조회이기 때문에 각각의 트랜잭션들은 먼저 시작된 트랜잭션이 커밋 또는 롤백될 때까지 로직을 실행하지 못하고 대기 상태에 빠지게 됩니다. 게다가 비즈니스 로직 상 트랜잭션 시작 시점부터 배타락을 걸어버리기 때문에, 사실상 트랜잭션 하나가 통으로 락을 잡아먹는 것과 다름없는 상황이 됩니다. 정합성을 확실하게 맞출 수는 있지만, 동시에 접근하는 트랜잭션이 많아지면 많아질수록 API 콜의 대기 시간은 늘어나게 됩니다.
또한 데이터베이스 자체적으로 애플리케이션은 모르는 이런 저런 락을 걸기 때문에, 애플리케이션 레벨에서 명시적으로 락을 거는 것은 어떤 부작용을 가지고 올 지 모릅니다. 특히나 저희처럼 이제서야 막 트랜잭션과 락에 대해 공부한다면 더더욱 그렇습니다. 이런 상황에 대해 질문드렸던 우아한테크코스 코치님들이나 현업에 계신 선배 크루들께서도 비관적 락은 최대한 기피한다는 말씀을 주셨습니다.
이 두가지 이유로 비관적 락은 기각되었습니다.
3. 낙관적 락
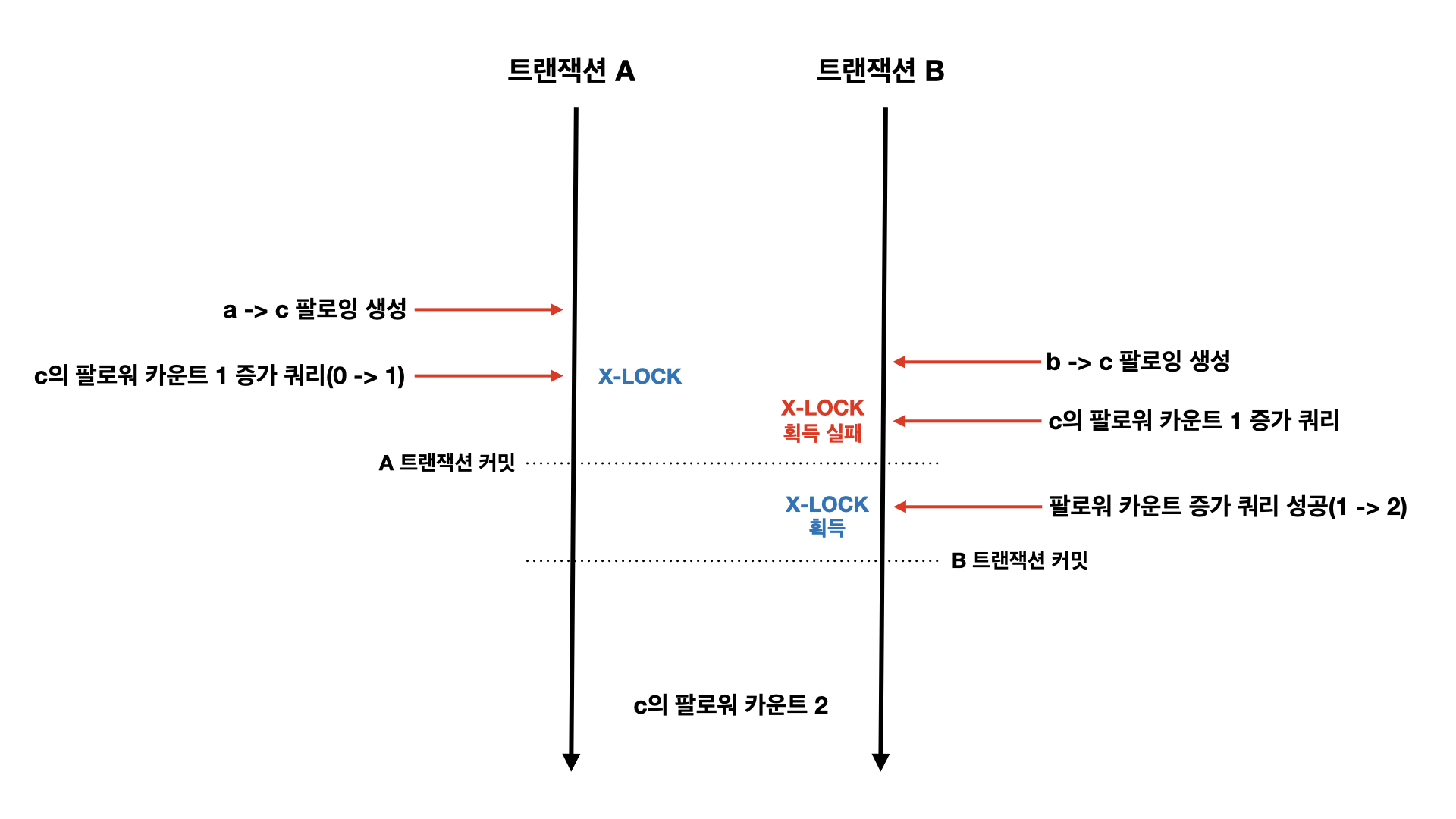
비관적 락 대신 낙관적 락을 사용하면 어떨까요? 데드락 문제도 발생하지 않고, 비관적 락 방식처럼 레코드에 락을 걸어버리지도 않으니 괜찮지 않을까요? 게다가 JPA를 사용하기 때문에 낙관적 락을 편하게 구현할 수도 있습니다. 하지만 낙관적 락은 정합성을 지키기 위해 비즈니스 로직을 희생해야 하는 문제가 있습니다.

낙관적 락을 활용하게 되면 버전 정보를 활용해서 버전이 일치하는 경우에만 커밋을 하고, 일치하지 않는 경우에는 롤백 처리를 하게 됩니다. 이 경우 위 그림처럼 실제로 생성되는 팔로잉은 a -> c 하나기 때문에 팔로워 카운트가 1만 증가되어도 정합성에 문제는 생기지 않습니다. 하지만 b -> c 팔로잉 로직이 팔로워 카운트 정합성을 맞추는 로직의 실패 때문에 실패하는 상황이 생기게 됩니다.
팔로잉 생성과 팔로워 카운트 정합성을 맞추는 로직의 트랜잭션을 분리하면 되지 않냐고요? 그러면 다시 팔로워 카운트 정합성이 맞지 않는 상황이 발생하게 됩니다.
4. 더티 체킹을 대신 쿼리 직접 실행
마지막 방법은 더티 체킹을 포기하고 레코드 자체의 값을 통해 통계를 계산해 주는 방법입니다. 도메인 값을 변경하지 않고 서비스 레이어에서 직접 레포지토리의 메서드를 호출해줘야 하기 때문에 도메인에서 최대한 모든 로직을 처리하는 것은 불가능해지지만, 정합성을 맞출 수는 있습니다. 이는 앞서 설명했던 대로 update 쿼리를 실행할 때 데이터베이스 자체적으로 배타락을 걸어주는 덕분입니다.
@Modifying(clearAutomatically = true, flushAutomatically = true)
@Query(value = "update Member m set m.followerCount = m.followerCount + 1 where m.id = :followingMemberId")
void increaseFollowerCount(Long followingMemberId);현재 저장된 회원의 팔로워 카운트 값에 +1을 해주는 JPQL입니다. 이렇게 자기 자신의 값을 이용하여 계산하게 해줄 경우, 팔로우 개수를 count 쿼리를 사용해 계산하는 것보다 훨씬 빠르며 배타락 덕분에 데이터 정합성도 보장할 수 있습니다. 그림에서 보시는 것처럼 먼저 실행된 트랜잭션이 update 쿼리를 마치고 커밋 또는 롤백 할 때까지 락 획득을 위해 대기하고 있기 때문입니다. 이 경우 회원 c의 레코드에 공유락이나 배타락을 걸어주는 다른 서비스 로직이 있지 않는 한 데드락 문제도 피할 수 있습니다.
위의 세 가지 방법들과 비교해보았을 때, JPA의 더티 체킹 기능을 포기하여 덜 객체 지향적인 코드가 되고, 도메인의 로직이 바깥으로 이동하기 때문에(서비스와 레포지토리로 분산됨) 비대한 서비스 코드를 만들 수 있다는 점. 그리고 서비스 레이어를 모킹하고 있는 F12의 테스트 코드 특성 상 테스트로 서비스 로직을 완벽하게 테스트하기 어렵다는 점을 단점으로 꼽을 수 있습니다. 하지만 락을 최소화하면서 정합성을 가장 확실하게 보장할 수 있는 방법이기 때문에 저희 팀은 이 방법을 통해 동시성으로 인한 정합성 문제를 해결하기로 결정했습니다.
여기서 잠깐 코드 레벨로 들어가보면, 특정 데이터베이스에 종속되는 것을 막기 위해 최대한 JPQL 문법을 사용하도록 고민을 많이 했는데요, 다행히도 JPQL이 지원하는 문법만으로 문제를 해결할 수 있어서 네이티브 쿼리를 사용하지 않을 수 있었습니다.
이 때 주의할 점이 있었는데요, 많은 분들이 아시다시피 JPQL은 실행 전 영속성 컨텍스트를 flush 합니다. 즉, 쓰기 지연 저장소에 저장되어 있던 쿼리들이 실행된다는 의미인데요, 쓰기 지연 저장소에 저장된 모든 쿼리를 실행시키는 것이 아니라는 점에 주의해야 합니다. 위의 코드로 예를 들어보겠습니다. JPQL은 update Member m set m.followerCount = m.followerCount + 1 where m.id = :followingMemberId" 입니다. 이 쿼리는 Member에 대해서만 관련이 있는 쿼리입니다. 때문에 쓰기 지연 저장소에서 Member에 대한 쿼리만 실행되게 됩니다.
보통 @Modifying이 들어가는 메서드, 즉 JPQL을 직접 작성하고 실행하는 메서드를 사용할 경우, 영속성 컨텍스트와 데이터베이스의 정합성이 맞지 않는 문제를 해결하기 위해 clearAutomatically = true 옵션을 걸어 영속성 컨텍스트를 아예 초기화 해버립니다. 그런데 지금 상황에서 이렇게 할 경우, 쓰기 지연 저장소에 저장된 쿼리 중 Member에 대한 쿼리를 제외한 다른 쿼리들이 실행되지 못하고 유실되게 됩니다.
예를 들어 팔로잉 객체의 식별자 생성 전략이 IDENTITY가 아니어서 insert 쿼리가 쓰기 지연 된다든가, 언팔로우 하는 상황이서어 팔로잉에 대한 delete 쿼리가 쓰기 지연 저장소에 저장되는 경우 insert / delete 쿼리는 영속성 컨텍스트 초기화에 의해 유실되고 팔로워 카운트만 변화하는 상황이 발생할 수 있습니다. 때문에 어떤 엔티티에 관련된 쿼리인지 상관 없이 쓰기 지연 저장소의 모든 쿼리를 실행시켜줘야 하고, flushAutomatically = true 옵션을 넣어주어 이 문제를 해결했습니다.
번외. 배치 스케줄을 통해 나중에 정합성 맞추기
아예 실시간 정합성은 신경쓰지 않고 나중에 스케줄러와 배치 업데이트 쿼리를 활용하여 정합성을 맞추는 방법도 있습니다. 저희 팀도 처음에는 이 방법을 생각했습니다. 동시성 문제가 아주 빈번하게 발생하지는 않을 것이라는 생각을 하기도 했고(실제로 서비스 환경에서 직접 문제를 터뜨려보기가 여간 힘든 일이 아니었습니다.), 당시에는 락 vs 스케줄러로 고민을 하고 있었을 때였는데 락으로 인한 문제를 겪는 것 보다는 정합성이 안맞는 시간이 잠깐 존재하는 것이 낫다는 판단을 했었습니다.
특히 리뷰에 대한 제품 통계가 아닌, 회원의 팔로워 수 관련 로직에서는 더 그렇게 생각했습니다. 저희 팀은 비즈니스 규칙으로 팔로워 수는 보여주지만 누가 팔로우하고 있는지는 보여주지 않기 때문에, 팔로워 수가 정확히 몇 개가 변했는지 실시간으로는 크게 중요하지 않고 나중에 정합성을 맞춰주어도 되는 상황이라고 생각했습니다. 그래서 기존 방식대로 JPA 더티 체킹 사용 + 일정 시간마다 스케줄러로 정합성 맞추는 쿼리 실행 조합의 코드를 실제로 작성까지 했는데요, 락에 대해서 좀 더 공부하던 도중 이 방식이 굉장히 비효율적인 방식이라는 것을 깨닫고 지금의 방법으로 수정했습니다.
왜 비효율적인 방식이라 생각했냐면, 도메인 로직을 사용하여 카운트를 증가시키고 더티 체킹으로 업데이트 하는 과정에서 update 쿼리로 인한 배타락이 걸리기 때문에 계산 쿼리를 직접 실행해주는 것과 배타락이 걸리는 시간에서는 큰 차이가 없는 반면 데이터의 실시간 정합성은 맞지 않기 때문입니다. 이 방식이 효율적이려면 애초에 팔로워 카운트에 대한 update 쿼리가 실행되지 않아야 합니다. 그래야 락을 최소화할 수 있습니다. 문제는 이럴 경우 모든 리뷰 작성 / 수정 / 삭제, 팔로우 / 언팔로우 로직마다 정합성이 안맞는 시간이 존재한다는 것입니다. 인스타그램처럼 팔로워가 엄청 많아 K단위로 보여줘 +1이 큰 의미가 없는 경우라면 모를까, 저희의 서비스에는 맞지 않는 상황이라고 느꼈습니다.
물론 update 쿼리를 실행하지 않고도 사용자에게 보여주는 카운트는 올릴 수도 있습니다. 적절한 캐시 레이어를 사용하면 됩니다. 캐시에 팔로워 카운트를 실시간으로 동기화시켜놓고, 주기적으로 데이터베이스에 반영하는 방식으로 사용하면 되겠다는 생각을 했습니다. 하지만 현재 저희 팀의 상황 상 캐시를 구축하기 위한 시간적 비용을 감당할 상황이 아니기 때문에 캐시를 적용하여 데이터 정합성을 맞추는 방식은 기각되었습니다.
추후 개선하고 싶은 점
어느 정도 해결되기는 했지만 아직 개선하고 싶은 문제점이 남아있습니다. 정합성을 맞추기 위해 서비스 로직이 비대해졌다는 것입니다. 당장에 구현할 능력은 부족하여 추후 개선점으로 남기지만, 구상해 본 바는 다음과 같습니다.
- 이벤트 발행을 통해 서비스에서 팔로워 카운트 업데이트 로직 분리
- 이 경우 트랜잭션이 분리되므로 정합성이 안맞는 경우가 발생할 수 있음
- 이런 경우는 매우 드물기 때문에 이 부분만 배치 스케줄러를 사용해도 좋을 듯
- 팔로워 카운트를 저장하는 캐시 레이어 도입
- 매 팔로우 / 언팔로우마다 카운트 업데이트를 위해 데이터베이스에 한 번 더 접근해야 하는데, 인 메모리 I/O는 디스크 I/O보다 빠르므로 I/O 시간을 감소시킬 수 있음
이런 부분들에 대해서 어떻게 하면 더 효율적인 방식을 도입할 수 있을지 좀 더 고민해보면서 점차 나은 성능과 구조를 보여주는 프로젝트를 만들 수 있도록 개선해나가는 것도 재밌을 것 같습니다.


항상 좋은 글 감사합니다!