
우아한테크코스에서는 팀 프로젝트를 진행중입니다. 그 중 이번 5차 데모 데이의 백엔드 요구 사항으로 다음과 같은 부분이 있었습니다.
- 서비스에서 사용하는 쿼리를 정리하고, 각 쿼리에서 사용하는 인덱스 설정
- 서비스에서 사용하는 모든 조회 쿼리와 테이블에 설정한 인덱스 공유
- 인덱스를 설정할 수 없는 쿼리가 있는 경우, 인덱스를 설정할 수 없는 이유 공유
레벨 3 8주동안 열심히 테이블을 설계하고 코드를 작성했지만, 쿼리의 성능과 인덱스에 대한 정리는 하나도 되어 있지 않은 상태였습니다. 무엇보다 어떤 쿼리가 성능이 잘 나오고, 어떤 쿼리가 성능이 잘 나오지 않는지 데이터베이스에 대한 지식이 약하다보니 데이터베이스를 어떻게 튜닝해야 할지도 감이 오지 않았습니다. 인덱스를 설정하라고 하는데, 어떤 컬럼에 인덱스를 적용해야 쿼리가 개선되는지도 판단할 수 없었습니다. 그래서 유의미한 성능 개선을 하기 위해 nGrinder로 성능 테스트를 진행해보기로 했습니다.
쿼리 개선 과정에 대한 이해를 돕기 위해 간단한 ERD를 그려보았습니다.
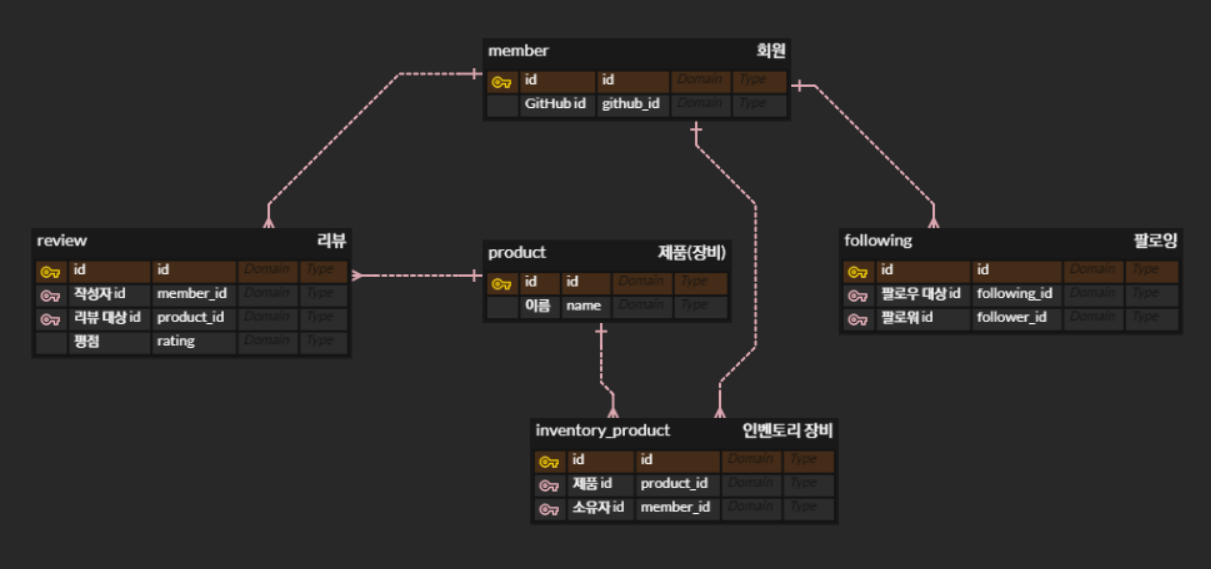
실제 저희 팀의 데이터베이스의 스키마를 쿼리 조회에 필요한 컬럼들만 넣어서 그린 ERD입니다. (실제로는 더 많은 컬럼들이 존재합니다.)
실제 애플리케이션에서 위의 모든 테이블에 대해 삽입 및 조회 쿼리를 날리는 부분이 있으며, 일부 테이블들은 수정 및 삭제 쿼리를 실행하는 부분도 있습니다.
또한 성능에 영향을 끼칠만한 부분으로, 저희 팀의 애플리케이션은 무한 스크롤 방식의 페이지네이션(Pagination)을 사용하고 있습니다.
성능 테스트 결과: 돌아오지 않는 쿼리
우선 쿼리의 비효율성을 체크하기 위해 성능 테스트를 돌려보았습니다. 유의미한 성능 테스트를 위해서는 적당한 크기의 데이터셋이 있어야 했는데요, 저희 팀은 각 테이블마다 약 20만개씩의 더미 데이터를 삽입하고 테스트를 진행했습니다.
테스트 결과는 처참했습니다.
기본적으로 저희 팀의 페이지네이션 방식의 맹점(offset 방식을 사용) 때문에 뒤쪽 페이지를 조회할수록 조회 성능이 떨어질 것이라는 예상은 하고 있었습니다. 하지만 product 테이블에 대한 조회를 기준으로 동시 접속자 수가 조금만 많게 설정해도 앞 쪽 페이지를 조회할 때도 레이턴시가 발생하고 있었으며, 뒤쪽 페이지를 조회할 때는 10초 가량이 걸리는 경우도 있었습니다.
화룡점정은 회원에 대한 조회였습니다. 테이블의 크기인 20만에 가까운 페이지를 조회할 경우, 회원 테이블에 대한 조회는 요청만 가고 아예 응답이 돌아오지를 않았습니다. 커넥션을 뱉어내지를 않아서 테스트를 돌리고 있던 스프링 서버가 뻗어버리고, 데이터베이스도 뻗어버렸습니다. 난리도 아니었습니다.

제가 보낸 쿼리... 잘 지내고 계신가요...?
풀 스캔, 또 풀 스캔
문제는 테이블 풀 스캔이 너무 빈번하게 이루어진다는 것이었습니다. 이는 저희 팀의 테이블 구조로부터 기인한 것입니다. F12는 목록을 조회할 때 정렬 조건으로 외부 테이블의 조건을 사용해야 합니다. 그런데 그 외부 테이블의 조건이 심지어 집계 함수를 이용한 조건입니다. 예를 들어볼까요?
문제가 되었던 회원 테이블의 경우, 정렬 조건이 팔로워 수입니다. 하지만 회원 테이블의 각각의 row는 본인을 팔로우 하는 회원이 몇 명인지, 즉 본인의 id를 FK following_id로 하는 following 테이블의 row 수가 몇 개인지 알 방법이 없습니다. 때문에 저희는 이 문제를 서브쿼리를 통해서 해결했습니다. JPA에서는 @Formula 어노테이션이 바로 그것이죠.
@Entity
@Table(name = "member")
@EntityListeners(AuditingEntityListener.class)
@Builder
@Getter
public class Member {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "github_id", nullable = false)
private String gitHubId;
@Column(name = "name")
private String name;
@Column(name = "image_url", length = 65535, nullable = false)
private String imageUrl;
@Column(name = "career_level")
@Enumerated(EnumType.STRING)
private CareerLevel careerLevel;
@Column(name = "job_type")
@Enumerated(EnumType.STRING)
private JobType jobType;
@Builder.Default
@Embedded
private InventoryProducts inventoryProducts = new InventoryProducts();
@Formula("(SELECT COUNT(1) FROM following f WHERE f.following_id = id)")
private int followerCount;
...
}SQL로 표현하면 다음과 같습니다.
select *, (select count(1) from following f
where f.following_id = m.id) f_count
from member m order by f_count desc, id desc;id desc는 왜 걸어주나요?
서브쿼리 결과 f_count는 중복도가 높습니다. 때문에 중복이 되지 않는 확실한 정렬 조건을 달아주기 위해 두 번째 정렬 조건으로 id 역순(최신순)을 명시해주었습니다.
그리고 이 쿼리는 mysql 콘솔 상으로도 쿼리 실행이 제대로 되지 않았습니다. 왜냐하면 member 테이블의 하나의 row 당 following 테이블에 대한 count를 가져와야 하기 때문입니다.
그런데 의문점이 있었습니다. product 테이블 역시 똑같은 방법으로 정렬을 하고 있었는데, product에 대한 조회 요청은 오래 걸리긴 해도 응답이 오기는 왔다는 것이죠. 그래서 실행 계획을 찾아봤습니다. product에 대한 조회 쿼리는 다음과 같습니다.
select *, (select count(1) from review r where r.product_id = p.id) r_count
from product p order by r_count desc, id desc;이제 두 쿼리의 실행 계획을 비교해보도록 하겠습니다.


key, rows, Extra 부분을 유심히 봐주세요. product 조회 쿼리는 메인쿼리에서는 인덱스를 타지 못하지만(order by 조건이 서브쿼리이기 때문에 인덱스 적용이 불가) 서브쿼리에서는 FK를 통해 인덱스를 타게 됩니다. 때문에 기껏해야(?) 20만여 row만 조회하면 되는 것이죠. 하지만 member 조회 쿼리는 그렇지 않습니다. 저희 팀은 following 테이블과 member 테이블의 의존성을 끊어 주는(간접 참조) 형태로 설계했었는데요, 때문에 FK가 걸려 있지 않았습니다. 그래서 인덱스가 자동으로 설정되지 않았고, 서브쿼리조차 인덱스를 타지 못하게 되는 것입니다.
때문에 member 조회 쿼리는 최대 20만 x 20만 = 400억 row를 조회해야 하는 쿼리가 나오는 것입니다. (지금은 20만짜리 테이블이지만 만약 100만 x 100만 테이블이면 1조를 조회해야 합니다!)
그래서 follwing 테이블의 following_id에 인덱스를 걸고 다시 조회해봤습니다.

서브쿼리에서 인덱스를 타게 됩니다. 한결 편안해집니다. 현재 row 수에서 최악의 페이징 효율을 가정하고, limit 191527, 10을 걸고 쿼리를 실행시켜 보겠습니다.
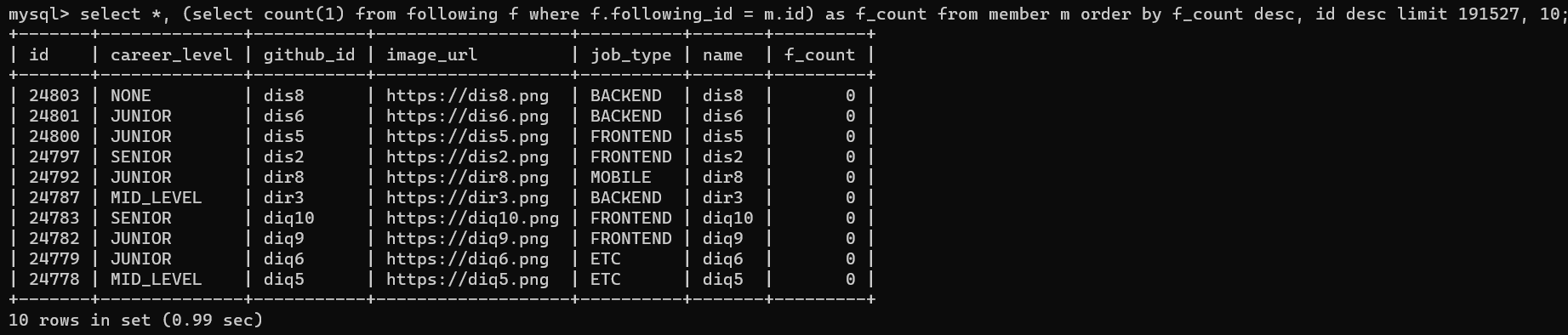
기존에 응답도 돌아오지 않던 쿼리가 0.99초 만에 완료되었습니다.
이제 1차적으로 하염없이 응답을 기다리는 상황은 해결하게 되었습니다.
정규화에 집착하지 않기
하지만 아직 만족스럽지 않습니다. 20만정도 테이블 크기에도 쿼리 실행만 1초씩 걸리는데, HTTP 요청 왔다갔다하고 애플리케이션 내부 로직 처리하고 하면 여전히 메인쿼리는 테이블 풀 스캔을 해야 합니다. 메인쿼리에서 인덱스를 걸 수는 없을까 하고 생각해봤지만, 결국 페이지네이션에 쓰이는 정렬 조건이 외부 테이블을 집계 함수로 연산해 온 서브쿼리이기 때문에 적절한 인덱스를 태울 수 없겠다는 결론이 나왔습니다.
결국 최대한 데이터베이스 정규화를 한 것이 조회 성능의 부담으로 다가오는 것인데요, 이 상황에서 인덱스를 활용하고 서브쿼리를 제거하여 조회 성능을 개선하려면 어쩔 수 없이 정렬 조건으로 쓰이는 product의 리뷰 개수, product의 평균 평점, member의 follower 수를 각각의 테이블에 추가해줘야 하는 상황입니다. 그리고 이 컬럼들은 삽입, 수정, 삭제 과정에서 다시 계산하여 수정이 들어가야 하죠. 조회 성능은 올라가지만 그 외의 삽입, 수정, 삭제 성능은 필연적으로 저하됩니다.
하지만 저희 서비스가 어디에 더 중점을 두고 있느냐를 생각해봤을 때, 삽입, 수정, 삭제 보다는 조회 쪽이 더 빈번하게 일어나고 있는 서비스라는 생각이 들어 데이터베이스 정규화를 어느 정도 포기하기로 결정했습니다.
정규화를 포기하고 member 테이블에 follower_count가 들어가면 follower_count를 기준으로 정렬을 할 수 있으므로 인덱스를 걸어주도록 하겠습니다.
여기서 잠깐
MySQL 8.0 버전부터는 역방향 인덱스를 생성할 수 있습니다. 조회 시 항상 follower_count가 많은 순으로 조회 할 예정이기 때문에 (follower_count desc, id desc)로 인덱스를 생성해주도록 하겠습니다.
그리고 조회를 member 테이블만 가지고 해보도록 하겠습니다. 먼저 실행 계획을 확인합니다.
select * from member order by follower_count desc limit 191527, 100);
index를 사용할 것이라는 예상과는 다르게 filesort를 사용합니다. 하지만 이는 자연스러운 것으로, 어차피 테이블 풀 스캔에 가깝게 조회해야 하기 때문에 인덱스를 사용하지 않는 것입니다. (인덱스를 사용하면 성능이 더 떨어집니다.) offset 방식의 페이지네이션의 허점이죠. 하지만 실제 성능은 개선됩니다.
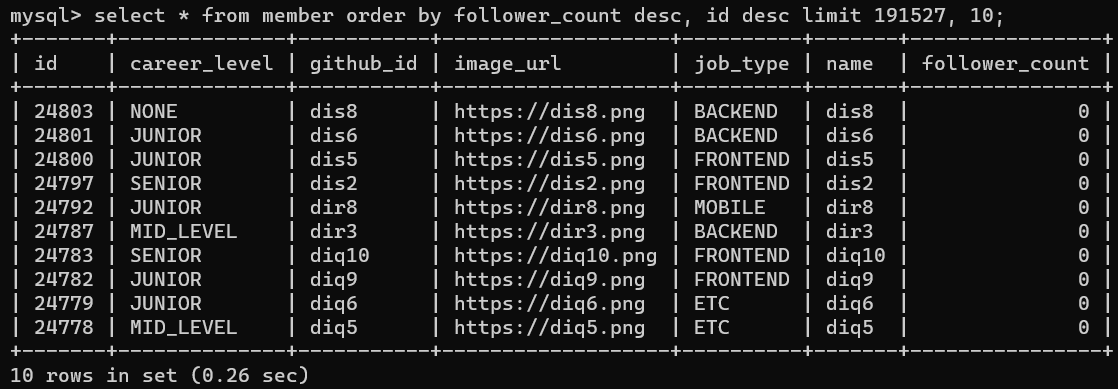
서브쿼리를 사용하지 않기 때문에 풀 스캔을 하더라도 성능이 더 개선됩니다. 1초 가량이 걸리던 쿼리가 0.26초까지 개선되는 것을 볼 수 있습니다.
커버링 인덱스를 통해 페이징 개선하기
하지만 데이터 수가 더 많아지면 점점 더 성능이 안좋아질 것입니다. offset 페이징의 문제로 현재의 조회 쿼리는 인덱스를 제대로 사용하지 못하고 있습니다. (실행 계획에서 Extra에 Using fileSort가 나오는 것을 볼 수 있습니다.)
그렇다면 no offset 방식을 사용하면 안될까요? 안타깝게도 저희 서비스는 그럴 수 없습니다. 저희 서비스의 정렬 조건은 다음과 같습니다.
- member: 팔로워 수
- product: 리뷰 개수
- product: 평점 평균
- review: 최신순
여기서 review의 경우 id를 활용하면 no offset 페이징이 가능합니다. 하지만 다른 조건들은 조건의 중복으로 인해 불가능합니다. 100번째 row까지 읽었다고 하면, 101번째 row가 어떤 row인지 알 수 있을까요?
예를 들어, following_count 기준으로 정렬을 해서 100번째 row까지 읽었다고 합시다. 그리고 100번째 row의 following_count 값은 10입니다. 하지만 101번째 row의 값이 11이라는 보장이 없습니다. 때문에 where following_count > 11과 같은 방식의 페이징은 사용할 수 없게 됩니다.
하지만 페이징 성능을 좀 더 개선해보고 싶어 이것 저것 찾아보던 도중, 이동욱 님의 블로그를 통해 커버링 인덱스의 존재를 알게 되었습니다.
기본적으로 MySQL은 id를 클러스터 인덱스로 가지고 있습니다. 이는 id 값으로 데이터의 실제 위치에 접근할 수 있음을 의미합니다. (클러스터 인덱스가 곧 물리적 정렬을 의미하기 때문입니다.) 반면 넌클러스터 인덱스의 경우 데이터 블록의 위치를 모르고 대신 클러스터 인덱스를 알고 있습니다.
이로 인해 조회 시 두 가지 경우의 수가 발생합니다.
- select 쿼리에 포함된 컬럼(where, order by, group by 등에 들어가는 모든 컬럼을 포함) 중 인덱스에 포함되지 않은 컬럼이 있는 경우
-> 넌클러스터 인덱스에 있는 클러스터 인덱스 값을 찾아 해당 값으로 데이터 row에 직접 접근 - select 쿼리에 포함된 컬럼이 모두 인덱스에 포함된 경우
-> 넌클러스터 인덱스로 모든 컬럼을 찾을 수 있으므로 데이터 row에 직접 접근하지 않음
커버링 인덱스는 바로 2번의 경우, 즉 쿼리의 모든 컬럼을 인덱스로 조회할 수 있는 경우를 의미합니다. 다시 말하자면 쿼리를 충족하는데 필요한 모든 컬럼을 가지는 인덱스를 커버링 인덱스라고 합니다. 기본적으로 인덱스 탐색이 데이터 테이블 접근보다 빠릅니다. 커버링 인덱스를 이용한 페이징은 이를 십분 활용하는 방식이라고 보시면 되겠습니다.
쿼리는 다음과 같습니다.
select * from member m
join (select id from member order by
follower_count desc,
id desc limit 191527, 10)
temp on temp.id = m.id;join 절 안쪽을 주목해주세요. select id from member order by follower_count desc, id desc limit 191527, 10에서 필요한 컬럼은 id, follower_count 입니다. 그리고 이 두 컬럼은 복합 인덱스(follower_count desc, id_desc)로 묶여있습니다. 이 때 순서와 desc도 중요한데요, order by 에 인덱스를 사용하기 위해서는 순서와 desc가 맞아야 합니다. 그래서 정렬 조건에 사용하기 위해 follower_count desc, id_desc로 인덱스를 묶었습니다.
다시 본론으로 돌아와서, order by에 인덱스를 인덱스 풀 스캔 방식으로 사용할 수 있습니다. 인덱스 풀 스캔으로 정렬을 한 뒤, id 값만 가져오기 때문에 실제 데이터에 접근하지도 않고 id 10개만 가져오게 됩니다. 반면 메인쿼리인 select * from member m은 인덱스 외의 컬럼이 필요하므로 데이터 접근이 필요한데요, join 쪽 서브쿼리의 결과로 id 10개만 가져와 조인하기 때문에 딱 10번의 데이터만 접근해도 됩니다. 또한 가져오는 값이 id, 즉 클러스터 인덱스기 때문에 주소를 검색하는 추가 작업 없이 데이터 테이블에 바로 접근할 수 있습니다.
실제 쿼리를 실행시켜 보겠습니다. 먼저 실행 계획입니다.

첫 번째 row는 메인쿼리, 두 번째 row는 조인, 세 번째 row는 서브쿼리입니다. 3번째 row를 보시면 idx_follower_count라는 인덱스 키를 사용하여 type = index, Extra = Using index 결과가 나왔습니다. 즉, 서브쿼리에서는 인덱스 풀 스캔을 사용합니다. 조인 + 서브쿼리의 결과로 id 10개가 나올테니 서브쿼리에서 인덱스 풀 스캔을 사용하면 제대로 계획이 되었다고 볼 수 있습니다. 이제 실행 계획이 아닌 실제로 실행을 시켜보겠습니다.
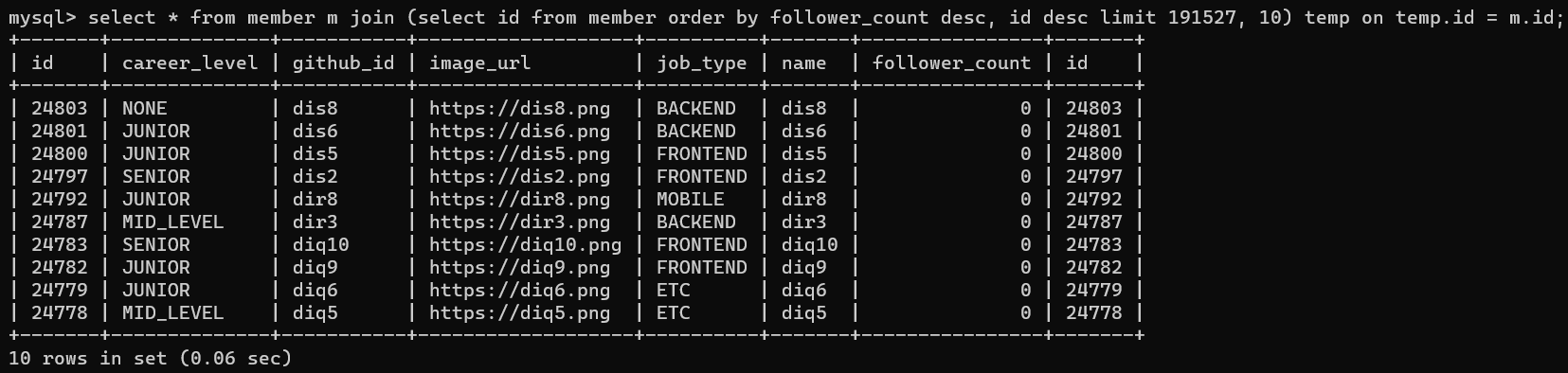
쿼리를 실행하는데 0.06초가 걸렸습니다. 반정규화를 하기 전 0.99초, 커버링 인덱스를 적용하기 전인 0.25초에 비해 압도적으로 쿼리 실행 시간이 빨라진 것을 볼 수 있습니다.
정리하자면 커버링 인덱스를 이용한 페이징 방식은 인덱스만 읽는 것은 빠르다. 테이블을 읽는 것은 느리다. 그러니까 페이징은 인덱스만 읽어서 처리하고 테이블을 최대한 적게 읽자.라는 아이디어입니다. 당연히 no offset 방식을 사용하는 것보다는 느릴 수 밖에 없지만, 저희 팀 같이 no offset 방식을 사용할 수 없는 경우에 충분히 효율적으로 쿼리를 튜닝할 수 있는 방법인 것 같습니다.
애플리케이션 코드는 하나도 건드리지 않고, 데이터베이스 이론을 공부하고 실행 계획, 그리고 실제 실행 시간 측정만 하면서 온갖 경우의 수를 다 체크하고 인덱스를 구상하는 것 만으로도 여간 힘든 것이 아니었습니다. 학교 다닐때 데이터베이스 수업 좀 듣지 그랬냐
다음 시간에는 이런 쿼리 개선을 실제 JPA 코드로 구현하여 애플리케이션을 완성하는 과정에 대해서 알아보도록 하겠습니다.
참고자료



오겡끼데스까 잘 보고 갑니다.