
지난 시간에 인덱스를 활용하여 어떻게 하면 쿼리 성능을 개선할 수 있을지 MySQL 콘솔을 통해 실험해가며 알아보았습니다. 그를 통해 개선된 쿼리를 만들어 낼 수 있었죠. 하지만 저희 팀 서비스는 결국 스프링과 JPA를 사용한 웹 애플리케이션이고, 개선된 쿼리를 자바 코드로 풀어내는 것 또한 중요합니다. 그래서 이번 시간에는 개선된 쿼리를 어떻게 웹 애플리케이션 코드에 적용했는지에 대해 알아보도록 하겠습니다.
복잡한 연관관계로 인한 N+1 문제 해결
JPA의 지연 로딩 기능을 사용하거나, 즉시 로딩을 사용하더라도 JPQL을 통한 조회를 할 경우 N+1 문제가 발생합니다.
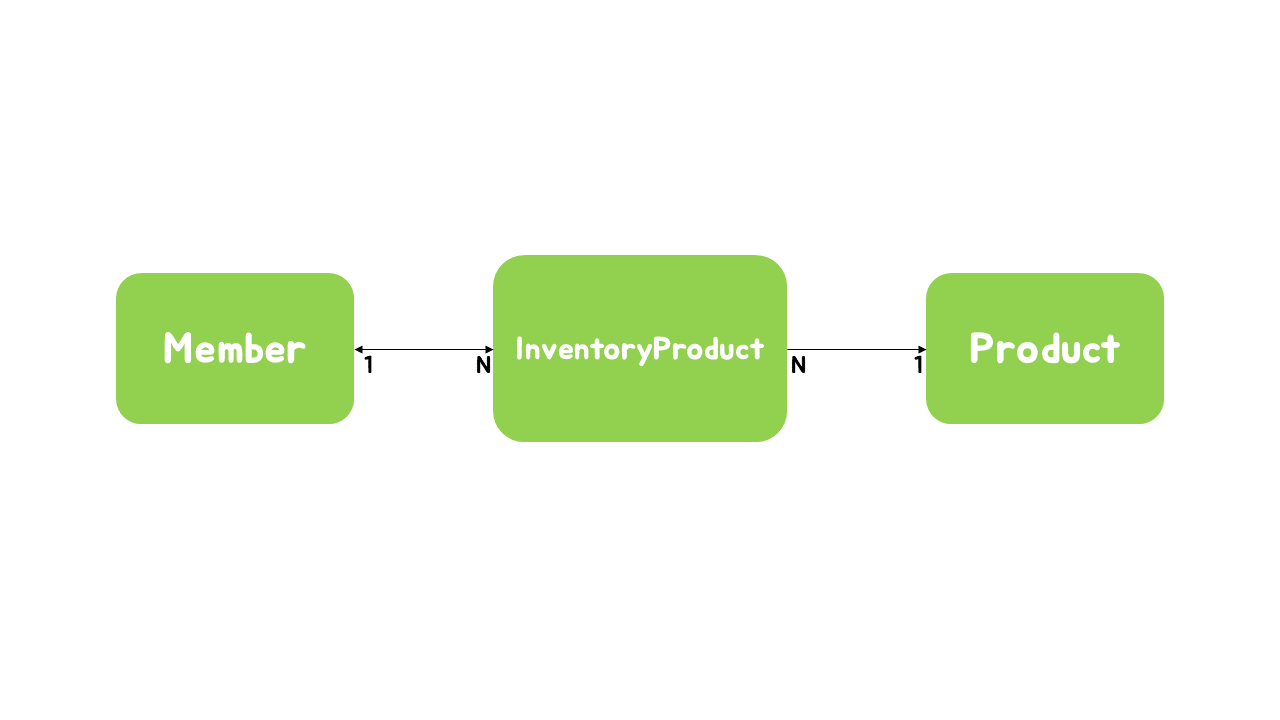
저희 팀의 연관관계 상황입니다. Member 엔티티와 InventoryProduct 엔티티는 Member 쪽이 일, InventoryProduct쪽이 다인 다대일 양방향 매핑이 되어 있습니다. 그리고 InventoryProduct는 Product와는 다대일 단방향 매핑을 하고 있습니다. (Member - Product 다대다 매핑을 일대다, 다대일 관계로 풀어낸 것입니다.)
이 상황에서 Member를 조회한다면 어떻게 될까요? 지연 로딩이 걸려있기 때문에 InventoryProduct를 조회하기 위해 N+1 쿼리가 발생할 것입니다. 그런데 InventoryProduct를 뷰로 보내주기 위해서는 마찬가지로 Product의 정보를 필요로 합니다. 때문에 Member를 조회하는 하나의 쿼리에 2N+1개의 쿼리가 발생하게 됩니다.
N+1 문제를 해결하는 가장 대표적인 방법으로는 fetch join이 있습니다. 하지만 저희 팀은 페이징을 사용하고 있기 때문에 일대다 상황에서 fetch join을 사용할 수 없는 문제를 안고 있습니다.
참고
DB에서 1과 N을 조인하면 그 결과가 N이 되기 때문에 row 수가 뒤틀려서 페이징이 불가능해집니다. 때문에
@OneToMany에서는 fetch join을 사용할 경우 애플리케이션으로 데이터를 전부 읽어온 뒤에 애플리케이션 단에서 페이징을 하게 되는 이슈가 있습니다.
때문에 일종의 임시방편으로 Member - InventoryProduct는 @BatchSize를 이용하여 in 쿼리를 이용해 조회하고, InventoryProduct - Product는 둘 사이의 연관관계를 즉시 로딩으로 설정하여 해결했습니다.
하지만 기본적으로 특별한 이유가 있지 않은 이상 엔티티 간의 연관관계는 지연 로딩으로 이루어져 있는 것이 좋습니다. 그런데 지연 로딩으로 바꿀 경우 InventoryProduct - Product에 fetch join을 적용해야 했는데, Member의 BatchSize와 함께 사용하기가 곤란합니다. 때문에 InventoryProduct - Product를 지연 로딩으로 바꾸기 위해 코드 개선이 필요했습니다.
해결 아이디어: @BatchSize를 직접 구현하자
@BatchSize를 사용하게 되면 여러 개의 프록시 객체를 조회하기 위해 in 쿼리를 사용해서 묶습니다. 따라서 BatchSize의 구현을 애플리케이션 코드로 대체하기만 하면 됐는데요, InventoryProduct - Product 관계에서 fetch join을 사용하기 위해 BatchSize 대신 in 쿼리를 이용한 조립을 애플리케이션에서 직접 해주기로 결정했습니다.
public MemberPageResponse findByContains(@Nullable final Long loggedInId,
final MemberSearchRequest memberSearchRequest, final Pageable pageable) {
final Slice<Member> slice = findBySearchConditions(memberSearchRequest, pageable);
setInventoryProductsToMembers(slice);
if (isNotLoggedIn(loggedInId)) {
return MemberPageResponse.ofByFollowingCondition(slice, false);
}
final List<Following> followings = followingRepository.findByFollowerIdAndFollowingIdIn(loggedInId,
extractMemberIds(slice.getContent()));
return MemberPageResponse.of(slice, followings);
}
// findBySearchConditions는 여기에 중요한 로직이 아니라 생략했습니다.
private void setInventoryProductsToMembers(final Slice<Member> slice) {
final List<InventoryProduct> mixedInventoryProducts = inventoryProductRepository.findWithProductByMembers(
slice.getContent());
for (Member member : slice.getContent()) {
final List<InventoryProduct> memberInventoryProducts = mixedInventoryProducts.stream()
.filter(it -> it.getMember().isSameId(member.getId()))
.collect(Collectors.toList());
member.updateInventoryProducts(memberInventoryProducts);
}
}우선 조회 조건에 따라 Member의 리스트를 가져옵니다. 그 뒤 Member 안에 있는 InventoryProduct들의 프록시, 즉 PersistenceBag을 초기화해줘야 하는데요, 이 작업을 Member가 가진 InventoryProduct들을 fetch join을 사용하여 전부 가져온 뒤, 각각의 Member에 맞게 조립해주는 과정을 거쳐줍니다.
이렇게 하면 Member 조회 쿼리 하나, InventoryProduct - Product 조회 쿼리 하나, 이렇게 두 개의 쿼리만 가지고 세 테이블간의 관계를 풀어낼 수 있습니다.
참고로 fetch join 메서드는 다음과 같습니다.
@Query("select i from InventoryProduct i join fetch i.product where i.member IN :members")
List<InventoryProduct> findWithProductByMembers(List<Member> members);QueryDSL로 커버링 인덱스를 통한 페이징 구현하기
다음은 커버링 인덱스입니다. 전 편에서 많은 데이터의 정렬 및 페이징을 커버링 인덱스를 통해 개선하는 쿼리를 살펴보았습니다. 이 쿼리를 JdbcTemplate를 활용해 네이티브 쿼리로 사용하는 것도 좋겠지만, 저희 팀은 이미 QueryDSL을 사용하고 있었고, QueryDSL이 주는 장점인 컴파일 시점의 문법 오류 체크, 자동 완성, 코드 재사용 등을 포기하고 싶지 않아 QueryDSL을 이용해 커버링 인덱스 페이징을 구현하기로 결정했습니다. 성능은 네이티브 쿼리를 사용하는 쪽이 조금 더 빠릅니다.
QueryDSL을 사용해 페이징 쿼리를 작성하려고 하니 문제가 있습니다. 작성해야 하는 MySQL 쿼리를 다시 한 번 확인해보겠습니다.
select * from member m
join (select id from member order by
follower_count desc,
id desc limit 191527, 10)
temp on temp.id = m.id;의도하는 쿼리를 작성하려면 from 절에 서브쿼리를 사용해야 합니다. 하지만 JPQL은 from 절에 서브쿼리를 지원하지 않습니다. 따라서 서브쿼리 / 메인쿼리로 나눠서 두 번의 쿼리를 실행시킨 뒤 결과를 조합해야 합니다.
먼저 서브쿼리를 QueryDSL로 만들어보도록 하겠습니다.
final List<Long> subQueryResult = jpaQueryFactory.select(member.id)
.from(member)
.offset(pageable.getOffset())
.limit(pageable.getPageSize() + 1)
.orderBy(makeOrderSpecifiers(member, pageable))
.fetch();
final Slice<Long> memberIds = toSlice(pageable, subQueryResult);makeOrderSpecifiers, toSlice는 저희 팀에서 QueryDSL 조회 조건 및 결과를 원하는 형식으로 만들기 위해 제네릭을 사용해 일반화한 유틸 메서드입니다. toSlice는 Spring Data JPA의 Slice 타입을 쓰기 위해 다음 페이지가 있는지 hasNext 값을 구하는 로직이 들어 있고, 여기서 신경써야 할 makeOrderSpecifiers 메서드에는 Pageable로 들어온 Sort 객체를 풀어내는 로직이 들어 있는데요, 위 코드에서는 최종적으로 member.followerCount.desc(), member.id.desc()가 나온다고 보시면 되겠습니다.
조회 결과로 조회 대상의 id가 리스트로 나오게 됩니다. 그 뒤 해당 id들을 사용해서 실제 select 쿼리를 실행하면 되는데요, 여기서 주의할 점이 하나 있습니다. 만약 서브쿼리의 결과가 빈 값이라면, 즉 조건을 만족하는 id가 아무것도 없다면, 굳이 다시 한 번 select 쿼리를 실행해 줄 필요가 없습니다. 만약 id들이 비어있다면 빈 결과를 바로 return 해주도록 하겠습니다.
if (memberIds.isEmpty()) {
return new SliceImpl<>(Collections.emptyList(), pageable, false);
}이어서 id 리스트가 비어있지 않다면 최종적으로 조회 쿼리를 실행하도록 하겠습니다.
final List<Member> mainQueryResult = jpaQueryFactory.selectFrom(member)
.where(member.id.in(memberIds.getContent()))
.orderBy(makeOrderSpecifiers(member, pageable))
.fetch();
return new SliceImpl<>(mainQueryResult, pageable, memberIds.hasNext());이 때 메인쿼리에도 orderBy가 들어가는 것에 의문을 품으실 수 있는데요, 만약 MySQL 상에서 실행시켰던 한 줄 짜리 쿼리를 실행했다면 서브쿼리에서 정렬한 결과대로 조회가 되어 메인쿼리에서는 따로 정렬할 필요가 없었을텐데요, 하지만 위 코드처럼 쿼리를 두 개로 나눠서 사용하게 될 경우 두 번째 쿼리에는 where ~ in ~ 절만 있기 때문에 조회 결과가 의도한 대로 정렬되지 않게 됩니다. 때문에 orderBy를 한 번 더 걸어서 순서를 맞춰주도록 하는 코드입니다.
테스트 코드를 통해 쿼리가 의도한대로 잘 나가는지 확인해보도록 하겠습니다.
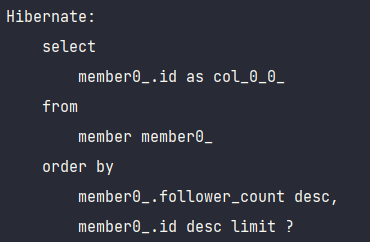
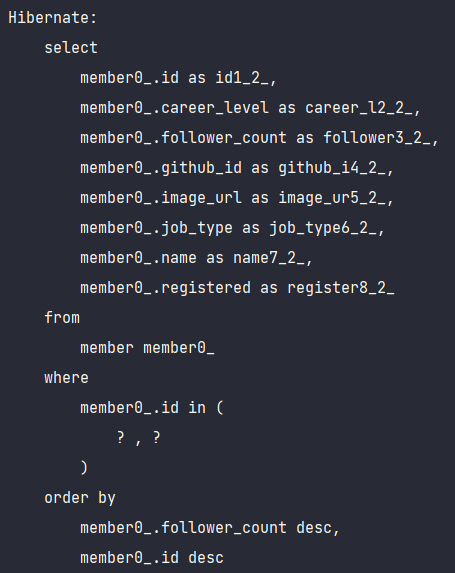
의도한 대로 id만 가져오는 쿼리가 하나 나간 뒤, 해당 id들을 in 절에 넣어 엔티티를 조회하는 쿼리가 실행되는 것을 확인할 수 있습니다.
쿼리 개선 과정의 한계
지금까지 이전 시간에 알아봤던 쿼리 개선 과정을 JPA와 QueryDSL을 활용한 애플리케이션 코드로 옮기는 과정을 살펴보았습니다.완벽하게 쿼리를 개선하지는 못했지만, 성능 상으로도 유의미한 결과를 얻을 수 있었고, 무엇보다 인덱스에 대해 잘 이해하지 못하던 제가 인덱스를 어느 정도 이해할 수 있었던 좋은 경험이었다고 생각합니다.
지난 시간과 이번 시간을 통해 쿼리 성능을 대단히 개선할 수 있었지만, 개선하지 못한 쿼리들도 많이 남아 있습니다. 가장 대표적으로 검색어가 들어간 조회 쿼리입니다.
현재 검색 방식을 like %XXX% 형태로 하고 있는데요, 때문에 인덱스를 타지 못하는 상황입니다. 실제 성능 테스트 과정에서도 검색어가 들어간 요청만 많은 시간이 소요되는 것을 확인할 수 있었습니다. FULL TEXT INDEX를 고려해보기도 했는데, product 테이블에 대한 검색 같은 경우, 워낙 검색 대상의 이름이 길기도 하고, 검색어를 길게 할 때 오히려 검색 속도가 더 나오지 않는 문제도 있었습니다. 때문에 다시 원래대로 like 검색을 사용했는데요, 검색에 대해서는 조금 더 알아보고 어떻게 하면 효율적인 검색이 이루어질 수 있을지 고민해 볼 필요가 있을 것 같습니다.
또한 where이 걸리는 쿼리의 경우 그냥 where에만 인덱스를 걸고 사용했는데요, 때문에 오히려 필터가 걸리는 쿼리가 필터 없는 페이징보다 더 느린 이상한 결과가 나오기도 했습니다. 여기도 커버링 인덱스를 조회하고 싶었지만, where에 걸리는 부분까지 함께 새로운 복합 인덱스로 만들어야 해서 인덱스가 너무 많아지는 것 같아 포기했습니다.
그래서 인덱스 외에도 조회 성능을 좀 더 개선할 방법을 찾아보려고 합니다. 지금 생각하기로는 DB Replication, 캐시 서버 등의 키워드들이 떠오르고 있습니다. 학습이 부족한 만큼, 다양한 주제로 좀 더 학습해봐야겠다는 생각이 듭니다.
참고자료
